Manchmal stoßen wir während unseres Laufs als DBAs auf mindestens eine Tabelle, die mit doppelten Datensätzen geladen ist. Selbst wenn die Tabelle einen Primärschlüssel hat (in den meisten Fällen einen automatisch inkrementellen), können die restlichen Felder doppelte Werte haben.
SQL Server bietet jedoch viele Möglichkeiten, diese doppelten Datensätze zu entfernen (z. B. die Verwendung von CTEs, der SQL-Rangfunktion, Unterabfragen mit Gruppieren nach usw.).
Ich erinnere mich, dass ich einmal während eines Interviews gefragt wurde, wie man doppelte Datensätze in einer Tabelle löscht, während nur einer von jedem übrig bleibt. Damals konnte ich nicht antworten, aber ich war sehr neugierig. Nachdem ich ein wenig recherchiert hatte, fand ich viele Optionen, um dieses Problem zu lösen.
Jetzt, Jahre später, bin ich hier, um Ihnen eine gespeicherte Prozedur vorzustellen, die darauf abzielt, die Frage „Wie lösche ich doppelte Datensätze in einer SQL-Tabelle?“ zu beantworten. Jeder DBA kann es einfach verwenden, um etwas Haushalt zu machen, ohne sich zu viele Gedanken zu machen.
Gespeicherte Prozedur erstellen:Erste Überlegungen
Das von Ihnen verwendete Konto muss über ausreichende Berechtigungen verfügen, um eine gespeicherte Prozedur in der beabsichtigten Datenbank zu erstellen.
Das Konto, das diese gespeicherte Prozedur ausführt, muss über ausreichende Berechtigungen verfügen, um die SELECT- und DELETE-Operationen für die Zieldatenbanktabelle auszuführen.
Diese gespeicherte Prozedur ist für Datenbanktabellen gedacht, für die kein Primärschlüssel (und keine UNIQUE-Einschränkung) definiert ist. Wenn Ihre Tabelle jedoch über einen Primärschlüssel verfügt, berücksichtigt die gespeicherte Prozedur diese Felder nicht. Es wird die Suche und Löschung basierend auf den restlichen Feldern durchführen (in diesem Fall also sehr vorsichtig sein).
So verwenden Sie gespeicherte Prozeduren in SQL
Kopieren Sie den in diesem Artikel verfügbaren SP T-SQL-Code und fügen Sie ihn ein. Der SP erwartet 3 Parameter:
@schemaName – ggf. der Name des Datenbanktabellenschemas. Wenn nicht – verwenden Sie dbo .
@tableName – Name der Datenbanktabelle, in der die doppelten Werte gespeichert sind.
@displayOnly – wenn auf 1 gesetzt , werden die tatsächlichen doppelten Datensätze nicht gelöscht , sondern nur angezeigt (falls vorhanden). Standardmäßig ist dieser Wert auf 0 gesetzt was bedeutet, dass die tatsächliche Löschung erfolgt falls Duplikate vorhanden sind.
SQL Server Stored Procedure Ausführungstests
Um die gespeicherte Prozedur zu demonstrieren, habe ich zwei verschiedene Tabellen erstellt – eine ohne Primärschlüssel und eine mit Primärschlüssel. Ich habe einige Dummy-Datensätze in diese Tabellen eingefügt. Lassen Sie uns überprüfen, welche Ergebnisse ich vor/nach dem Ausführen der gespeicherten Prozedur erhalte.
SQL-Tabelle mit Primärschlüssel
CREATE TABLE [dbo].[test](
[column1] [varchar](16) NOT NULL,
[column2] [varchar](16) NOT NULL,
[column3] [varchar](16) NOT NULL,
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED
(
[column1] ASC,
[column2] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SQL Stored Procedure Beispieldatensätze
INSERT INTO test VALUES('A','A',1),('A','B',1),('A','C',1),('B','A',2),('B','B',3),('B','C',4)
Gespeicherte Prozedur nur mit Anzeige ausführen
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'test',@displayOnly = 1
Da Spalte1 und Spalte2 den Primärschlüssel bilden, werden die Duplikate anhand der Nicht-Primärschlüssel-Spalten ausgewertet, in diesem Fall Spalte3. Das Ergebnis ist korrekt.
Gespeicherte Prozedur ohne Anzeige ausführen
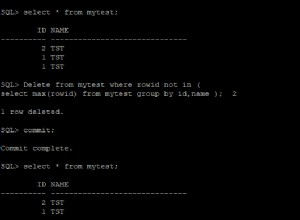
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'test',@displayOnly = 0
Die doppelten Datensätze sind verschwunden.
Sie müssen bei diesem Ansatz jedoch vorsichtig sein, da das erste Vorkommen des Datensatzes derjenige ist, der geschnitten wird. Wenn Sie also aus irgendeinem Grund die Löschung eines ganz bestimmten Datensatzes benötigen, müssen Sie Ihren speziellen Fall separat angehen.
SQL Tabelle ohne Primärschlüssel
CREATE TABLE [dbo].[duplicates](
[column1] [varchar](16) NOT NULL,
[column2] [varchar](16) NOT NULL,
[column3] [varchar](16) NOT NULL
) ON [PRIMARY]
GO
SQL Stored Procedure Beispieldatensätze
INSERT INTO duplicates VALUES
('John','Smith','Y'),
('John','Smith','Y'),
('John','Smith','N'),
('Peter','Parker','N'),
('Bruce','Wayne','Y'),
('Steve','Rogers','Y'),
('Steve','Rogers','Y'),
('Tony','Stark','N')

Gespeicherte Prozedur nur mit Anzeige ausführen
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'duplicates',@displayOnly = 1
Die Ausgabe ist korrekt, das sind die doppelten Datensätze in der Tabelle.
Gespeicherte Prozedur ohne Anzeige ausführen
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'duplicates',@displayOnly = 0
Die gespeicherte Prozedur hat wie erwartet funktioniert und die Duplikate wurden erfolgreich bereinigt.
Sonderfälle für diese gespeicherte Prozedur in SQL
Wenn das Schema oder die Tabelle, die Sie angeben, nicht in Ihrer Datenbank vorhanden ist, werden Sie von der gespeicherten Prozedur benachrichtigt, und das Skript beendet seine Ausführung.

Wenn Sie den Schemanamen leer lassen, benachrichtigt Sie das Skript und beendet seine Ausführung.

Wenn Sie den Tabellennamen leer lassen, benachrichtigt Sie das Skript und beendet seine Ausführung.

Wenn Sie die gespeicherte Prozedur für eine Tabelle ausführen, die keine Duplikate enthält, und das @displayOnly-Bit aktivieren , erhalten Sie eine leere Ergebnismenge.

Gespeicherte SQL Server-Prozedur:Vollständiger Code
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author : Alejandro Cobar
-- Create date: 2021-06-01
-- Description: SP to delete duplicate rows in a table
-- =============================================
CREATE PROCEDURE DBA_DeleteDuplicates
@schemaName VARCHAR(128),
@tableName VARCHAR(128),
@displayOnly BIT = 0
AS
BEGIN
SET NOCOUNT ON;
IF LEN(@schemaName) = 0
BEGIN
PRINT 'You must specify the schema of the table!'
RETURN
END
IF LEN(@tableName) = 0
BEGIN
PRINT 'You must specify the name of the table!'
RETURN
END
IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = @schemaName AND TABLE_NAME = @tableName)
BEGIN
DECLARE @pkColumnName VARCHAR(128);
DECLARE @columnName VARCHAR(128);
DECLARE @sqlCommand VARCHAR(MAX);
DECLARE @columnsList VARCHAR(MAX);
DECLARE @pkColumnsList VARCHAR(MAX);
DECLARE @pkColumns TABLE(pkColumn VARCHAR(128));
DECLARE @limit INT;
INSERT INTO @pkColumns
SELECT K.COLUMN_NAME
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS C
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE AS K ON C.TABLE_NAME = K.TABLE_NAME AND C.CONSTRAINT_SCHEMA = K.CONSTRAINT_SCHEMA
WHERE C.CONSTRAINT_TYPE = 'PRIMARY KEY'
AND C.CONSTRAINT_SCHEMA = @schemaName AND C.TABLE_NAME = @tableName
IF((SELECT COUNT(*) FROM @pkColumns) > 0)
BEGIN
DECLARE pk_cursor CURSOR FOR
SELECT * FROM @pkColumns
OPEN pk_cursor
FETCH NEXT FROM pk_cursor INTO @pkColumnName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @pkColumnsList = CONCAT(@pkColumnsList,'',@pkColumnName,',')
FETCH NEXT FROM pk_cursor INTO @pkColumnName
END
CLOSE pk_cursor
DEALLOCATE pk_cursor
SET @pkColumnsList = SUBSTRING(@pkColumnsList,1,LEN(@pkColumnsList)-1)
END
DECLARE columns_cursor CURSOR FOR
SELECT COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = @schemaName AND TABLE_NAME = @tableName AND COLUMN_NAME NOT IN (SELECT pkColumn FROM @pkColumns)
ORDER BY ORDINAL_POSITION;
OPEN columns_cursor
FETCH NEXT FROM columns_cursor INTO @columnName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @columnsList = CONCAT(@columnsList,'',@columnName,',')
FETCH NEXT FROM columns_cursor INTO @columnName
END
CLOSE columns_cursor
DEALLOCATE columns_cursor
SET @columnsList = SUBSTRING(@columnsList,1,LEN(@columnsList)-1)
IF((SELECT COUNT(*) FROM @pkColumns) > 0)
BEGIN
IF(CHARINDEX(',',@columnsList) = 0)
SET @limit = LEN(@columnsList)+1
ELSE
SET @limit = CHARINDEX(',',@columnsList)
SET @sqlCommand = CONCAT('WITH CTE (',@columnsList,',DuplicateCount',')
AS (SELECT ',@columnsList,',',
'ROW_NUMBER() OVER(PARTITION BY ',@columnsList,' ',
'ORDER BY ',SUBSTRING(@columnsList,1,@limit-1),') AS DuplicateCount
FROM [',@schemaName,'].[',@tableName,'])
')
IF @displayOnly = 0
SET @sqlCommand = CONCAT(@sqlCommand,'DELETE FROM CTE WHERE DuplicateCount > 1;')
IF @displayOnly = 1
SET @sqlCommand = CONCAT(@sqlCommand,'SELECT ',@columnsList,',MAX(DuplicateCount) AS DuplicateCount FROM CTE WHERE DuplicateCount > 1 GROUP BY ',@columnsList)
END
ELSE
BEGIN
SET @sqlCommand = CONCAT('WITH CTE (',@columnsList,',DuplicateCount',')
AS (SELECT ',@columnsList,',',
'ROW_NUMBER() OVER(PARTITION BY ',@columnsList,' ',
'ORDER BY ',SUBSTRING(@columnsList,1,CHARINDEX(',',@columnsList)-1),') AS DuplicateCount
FROM [',@schemaName,'].[',@tableName,'])
')
IF @displayOnly = 0
SET @sqlCommand = CONCAT(@sqlCommand,'DELETE FROM CTE WHERE DuplicateCount > 1;')
IF @displayOnly = 1
SET @sqlCommand = CONCAT(@sqlCommand,'SELECT * FROM CTE WHERE DuplicateCount > 1;')
END
EXEC (@sqlCommand)
END
ELSE
BEGIN
PRINT 'Table doesn't exist within this database!'
RETURN
END
END
GO
Schlussfolgerung
Wenn Sie nicht wissen, wie Sie doppelte Datensätze in einer SQL-Tabelle löschen können, sind Tools wie dieses hilfreich für Sie. Jeder DBA kann prüfen, ob es Datenbanktabellen gibt, die keine Primärschlüssel (oder eindeutige Beschränkungen) für sie haben, die im Laufe der Zeit einen Haufen unnötiger Datensätze ansammeln könnten (möglicherweise Speicherplatz verschwenden). Einfach die gespeicherte Prozedur einstecken und wiedergeben, und schon kann es losgehen.
Sie können noch etwas weiter gehen und einen Benachrichtigungsmechanismus bauen, der Sie benachrichtigt, wenn es Duplikate für eine bestimmte Tabelle gibt (nachdem Sie natürlich ein wenig Automatisierung mit diesem Tool implementiert haben), was sehr praktisch ist.
Wie bei allem, was mit DBA-Aufgaben zu tun hat, stellen Sie sicher, dass Sie immer alles in einer Sandbox-Umgebung testen, bevor Sie den Auslöser in der Produktion betätigen. Und wenn Sie das tun, stellen Sie sicher, dass Sie eine Sicherungskopie der Tabelle haben, auf die Sie sich konzentrieren.