In den vorherigen Blogs haben meine Kollegen und ich Ihnen gezeigt, wie Sie die Leistung überwachen, Cluster verwalten und bereitstellen, Sicherungen ausführen und sogar automatisches Failover für TimescaleDB aktivieren können.
In diesem Blog zeigen wir Ihnen, wie Sie Ihre einzelne TimescaleDB-Instanz in nur wenigen einfachen Schritten zu einem Multi-Node-Cluster skalieren können.
Wir beginnen mit einem gemeinsamen Setup, einer Single-Node-Instanz, die auf CentosOS läuft. Der Knoten ist in Betrieb und wird bereits von ClusterControl überwacht und verwaltet.
Wenn Sie erfahren möchten, wie Sie Ihre TimescaleDB-Instanz bereitstellen oder importieren, lesen Sie den von meinem Kollegen Sebastian Insausti verfassten Blog „How to Easy Deploy TimescaleDB.“
Das Setup sieht wie folgt aus...
 ClusterControl:Einzelinstanz-TimescaleDB
ClusterControl:Einzelinstanz-TimescaleDB Es handelt sich also um eine einzelne Produktionsinstanz, die wir ohne Ausfallzeit in einen Cluster umwandeln möchten. Unser Hauptziel ist es, Anwendungslesevorgänge auf andere Maschinen zu skalieren, mit der Option, sie als Staging-HA-Server zu verwenden, wenn ein Serverabsturz geschrieben wird.
Mehr Knoten sollten auch die Ausfallzeit der Anwendungswartung reduzieren. Wie das Patchen, das im rollenden Neustartmodus angewendet wird – ein Knoten wird gleichzeitig gepatcht, während andere Knoten Datenbankverbindungen bedienen.
Die letzte Anforderung besteht darin, eine einzelne Adresse für unseren neuen Cluster zu erstellen, damit unsere neuen Knoten für die Anwendung von einem Ort aus sichtbar sind.

Wir können unseren Aktionsplan in zwei Hauptschritte zusammenfassen:
- Hinzufügen eines Replikats
- Installieren und konfigurieren Sie Haproxy
Hinzufügen eines Replikats
Wenn wir zu den Cluster-Aktionen gehen und „Add Replication Slave“ auswählen, können wir entweder ein neues Replikat von Grund auf neu erstellen oder eine vorhandene TimescaleDB-Datenbank als Replikat hinzufügen.
 ClusterControl:Replikations-Slave hinzufügen
ClusterControl:Replikations-Slave hinzufügen 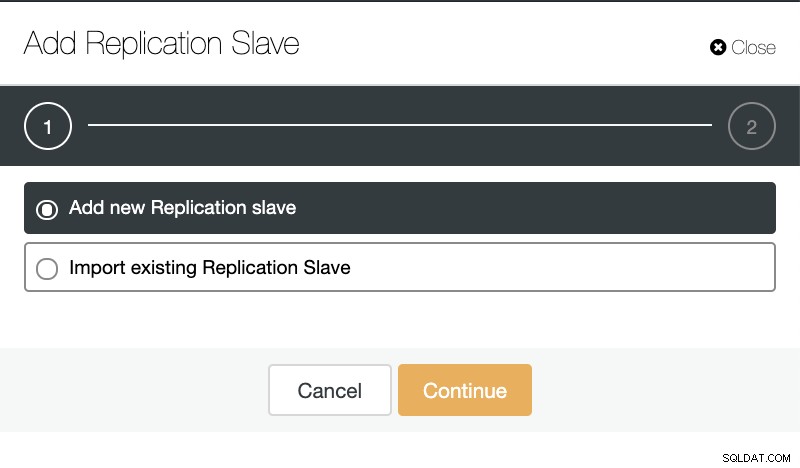 ClusterControl:Neuen Replikations-Slave hinzufügen, bestehenden Replikations-Slave importieren
ClusterControl:Neuen Replikations-Slave hinzufügen, bestehenden Replikations-Slave importieren Wie Sie im unteren Bild sehen können, müssen wir nur unseren Master-Server auswählen, die IP-Adresse für unseren neuen Slave-Server und den Datenbank-Port eingeben.
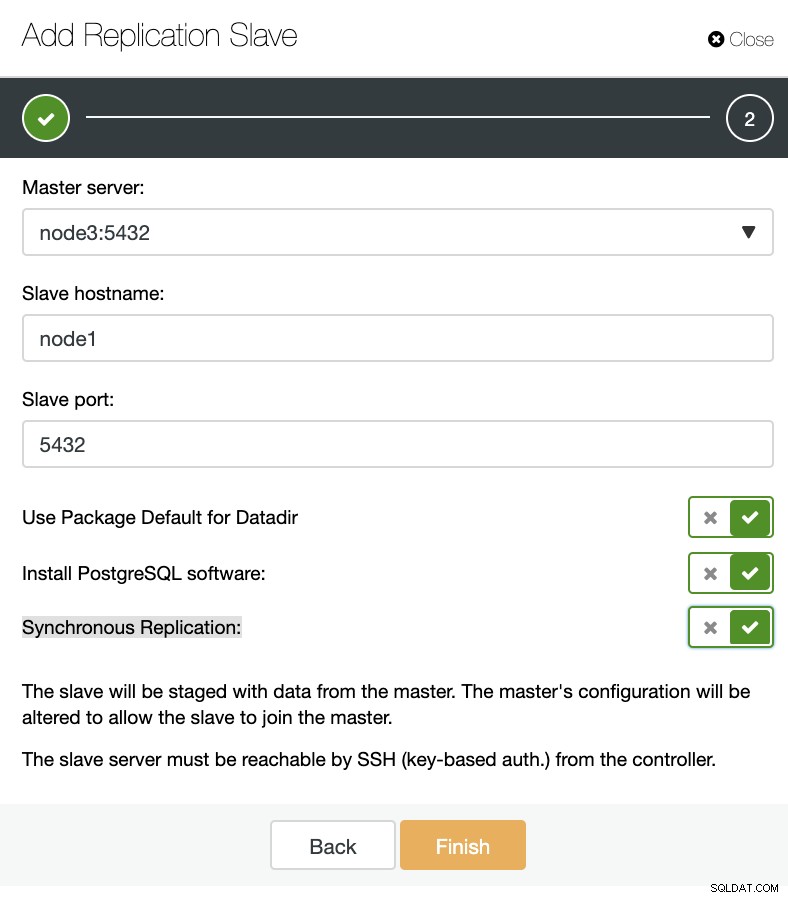 ClusterControl:Replikations-Slave hinzufügen
ClusterControl:Replikations-Slave hinzufügen Dann können wir wählen, ob ClusterControl die Software für uns installieren soll und ob der Replikations-Slave synchron oder asynchron sein soll. Wenn Sie einen bestehenden Slave-Server importieren, können Sie die Importoption wie folgt verwenden:
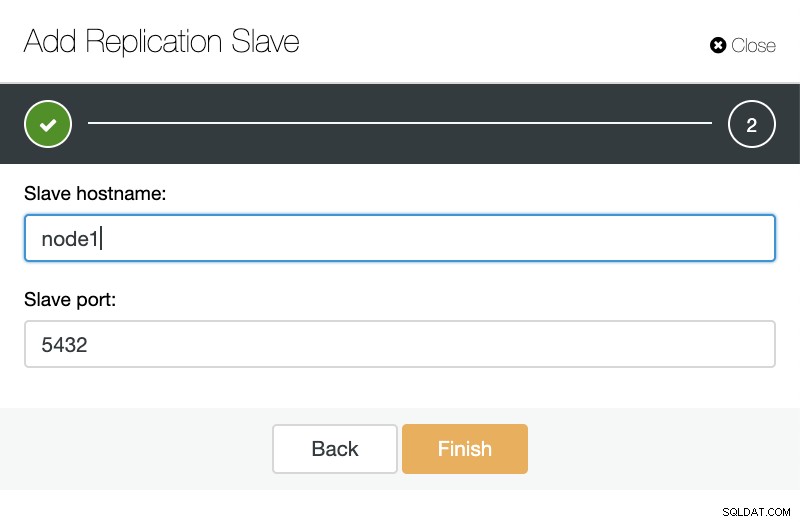 ClusterControl:Replikations-Slave für TimescaleDB importieren
ClusterControl:Replikations-Slave für TimescaleDB importieren In beiden Fällen können wir so viele Replikate hinzufügen, wie wir möchten. In unserem Beispielfall fügen wir zwei Knoten hinzu. CusterControl erstellt einen internen Job und erledigt alle erforderlichen Schritte einzeln.
 ClusterControl:Read Replica hinzufügen
ClusterControl:Read Replica hinzufügen Hinzufügen eines Load Balancers zu TimescaleDB
An diesem Punkt werden unsere Daten auf mehrere Knoten oder Rechenzentren verteilt, wenn Sie sich dafür entschieden haben, Replikations-Slave-Knoten an einem anderen Standort hinzuzufügen. Der Cluster wird mit zwei zusätzlichen Read Replica-Knoten hochskaliert.
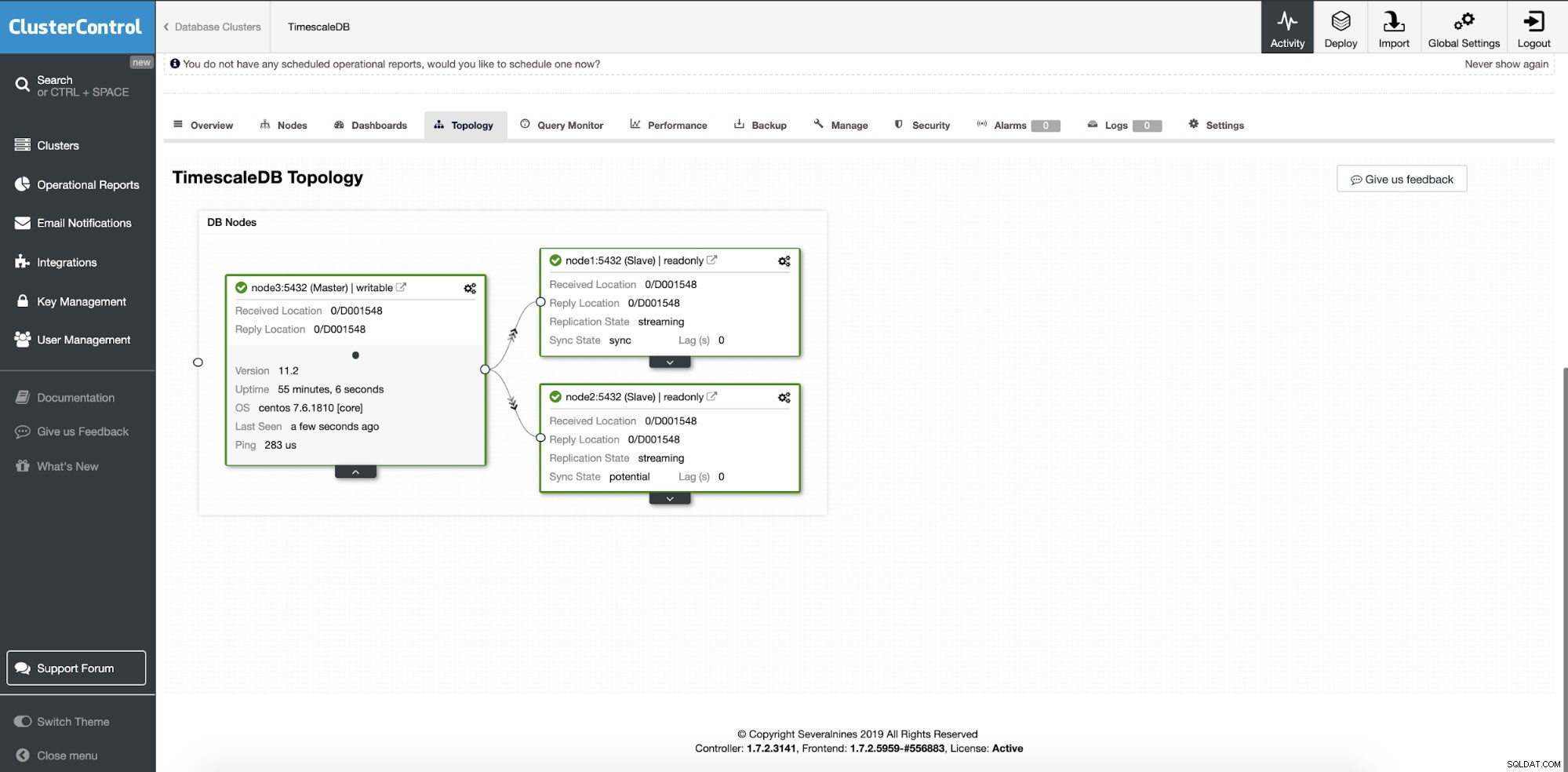 ClusterControl:Zwei Knoten hinzugefügt
ClusterControl:Zwei Knoten hinzugefügt Die Frage ist, woher weiß die Anwendung, auf welchen Datenbankknoten sie zugreifen soll? Wir werden HAProxy und verschiedene Ports für Schreib- und Lesevorgänge verwenden.
Wählen Sie aus dem TimescaleDB-Cluster im Kontextmenü Load Balancer hinzufügen.

Jetzt müssen wir den Standort des Servers angeben, auf dem Haproxy installiert werden soll, welche Richtlinie wir für Datenbankverbindungen verwenden möchten und welche Knoten an der Haproxy-Konfiguration teilnehmen.
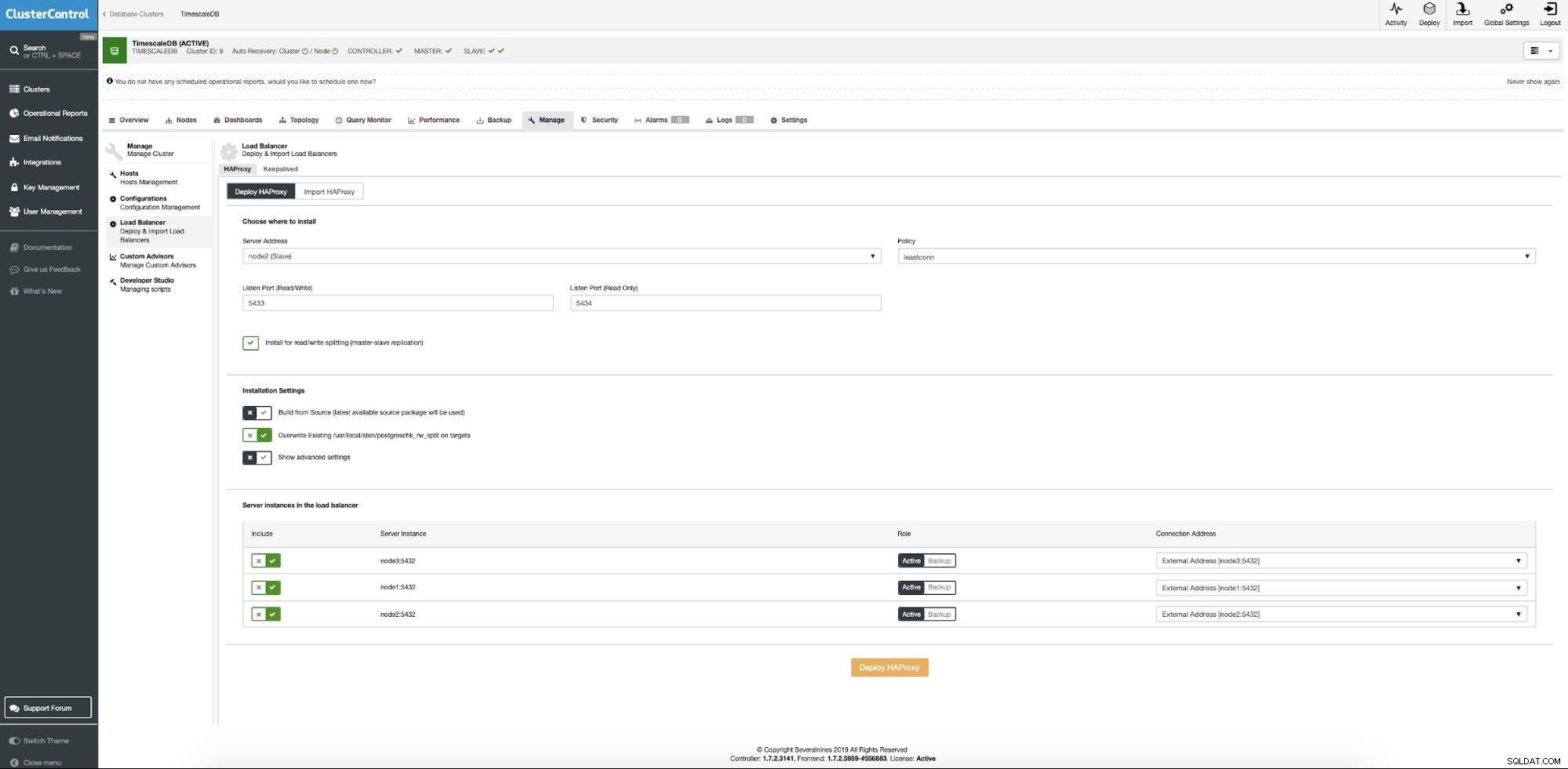
Wenn alles eingestellt ist, drücken Sie die Bereitstellungstaste. Nach ein paar Minuten sollten wir unsere Clusterkonfiguration bereit haben. ClusterControl kümmert sich um alle Voraussetzungen und Konfigurationen für die Bereitstellung des Lastenausgleichs.
Nach einer erfolgreichen Bereitstellung können wir die Topologie unseres neuen Clusters sehen; mit Load Balancing und zusätzlichen Leseknoten. Wenn mehr Knoten an Bord sind, aktiviert ClusterControl automatisch die automatische Wiederherstellung. Auf diese Weise startet der Failover-Vorgang von selbst, wenn der Master-Knoten ausfällt.
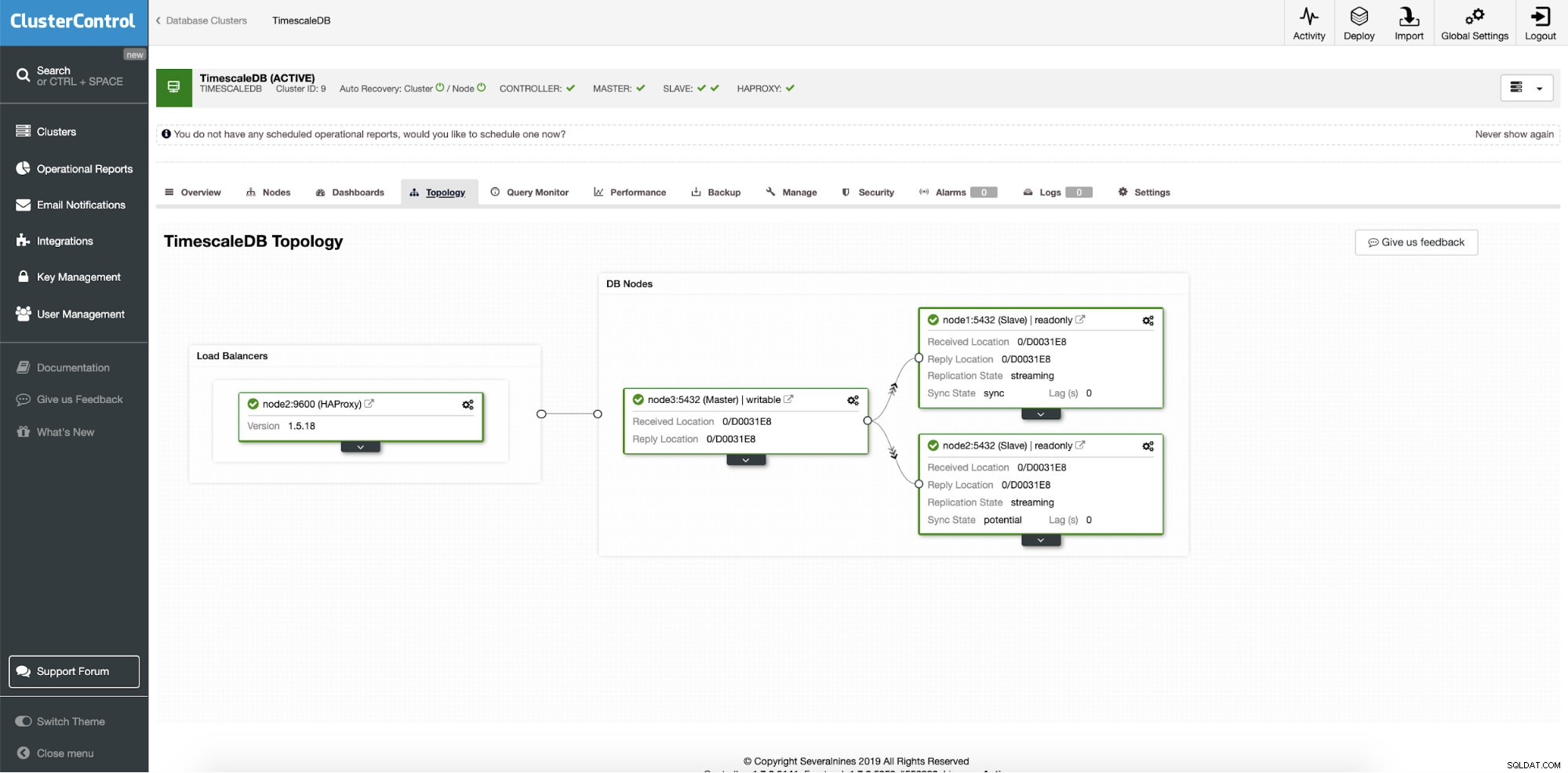 ClusterControl:Endgültige Topologie
ClusterControl:Endgültige Topologie Schlussfolgerung
TimescaleDB ist eine Open-Source-Datenbank, die erfunden wurde, um SQL für Zeitreihendaten skalierbar zu machen. Eine automatisierte Methode zum Erweitern ihres Clusters ist ein Schlüssel zum Erreichen von Leistung und Effizienz. Wie wir oben gesehen haben, können Sie TimescaleDB jetzt einfach mit ClusterControl skalieren.



