Vor ein paar Tagen war die Veröffentlichung einer neuen Version von ClusterControl, der 1.7.2, in der wir mehrere neue Funktionen sehen können, eine der wichtigsten ist die Unterstützung für TimescaleDB.
TimescaleDB ist eine Open-Source-Zeitreihendatenbank, die für schnelle Aufnahme und komplexe Abfragen optimiert ist und vollständiges SQL unterstützt. Es basiert auf PostgreSQL und bietet das Beste aus NoSQL- und relationalen Welten für Zeitreihendaten. TimescaleDB unterstützt die Streaming-Replikation als primäre Replikationsmethode, die in einer Einrichtung mit hoher Verfügbarkeit verwendet werden kann. PostgreSQL verfügt jedoch nicht über ein automatisches Failover, was in einer Produktionsumgebung mit hoher Verfügbarkeit ein Problem darstellt. Manuelles Failover bedeutet normalerweise, dass ein Mensch per Pager angerufen wird und einen Computer finden, sich bei den Systemen anmelden und verstehen muss, was vor sich geht, bevor Failover-Verfahren eingeleitet werden. Dies führt zu einer langen Ausfallzeit. Glücklicherweise gibt es eine Möglichkeit, Failover mit ClusterControl zu automatisieren, das jetzt TimescaleDB unterstützt.
In diesem Blog erfahren Sie, wie Sie mithilfe von ClusterControl mit nur wenigen Klicks ein repliziertes TimescaleDB-Setup mit automatischem Failover bereitstellen. Wir werden auch sehen, wie man einen einzelnen Datenbankendpunkt für Anwendungen über HAProxy hinzufügt. Als Voraussetzung sollten Sie die Version 1.7.2 von ClusterControl auf einem dedizierten Host oder einer VM installieren.
TimescaleDB bereitstellen
Um eine Neuinstallation von TimescaleDB von ClusterControl aus durchzuführen, wählen Sie einfach die Option „Deploy“ und folgen Sie den angezeigten Anweisungen. Beachten Sie, dass Sie, wenn Sie bereits eine TimescaleDB-Instanz ausführen, stattdessen „Vorhandenen Server/Datenbank importieren“ auswählen müssen.
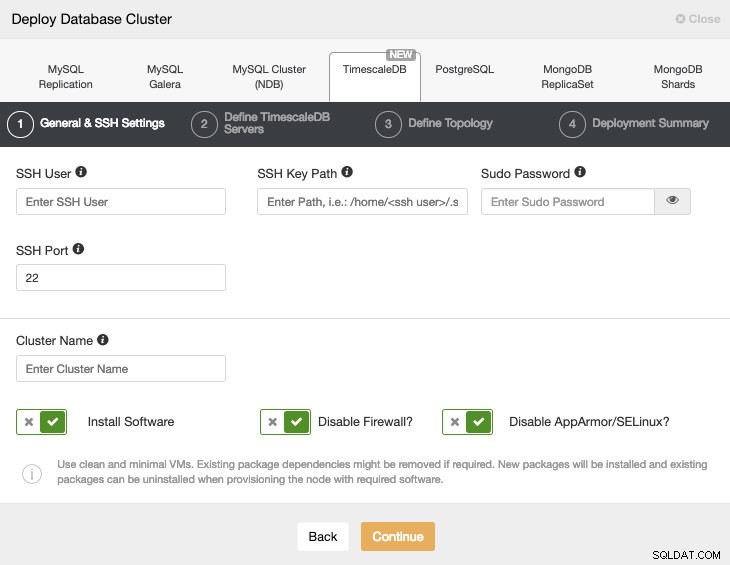
Bei der Auswahl von TimescaleDB müssen wir Benutzer, Schlüssel oder Passwort und Port angeben, um eine SSH-Verbindung zu unseren TimescaleDB-Hosts herzustellen. Wir brauchen auch einen Namen für unseren neuen Cluster und wenn wir möchten, dass ClusterControl die entsprechende Software und Konfigurationen für uns installiert.
Bitte überprüfen Sie die ClusterControl-Benutzeranforderungen für diese Aufgabe hier.
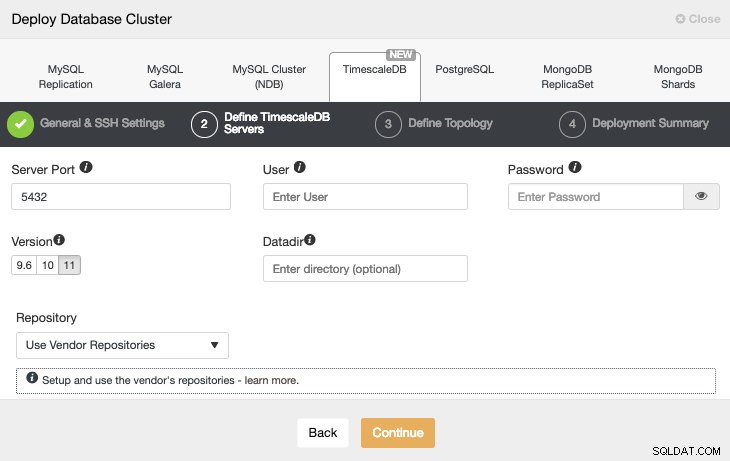
Nach dem Einrichten der SSH-Zugangsinformationen müssen wir den Datenbankbenutzer, die Version und das Datadir (optional) definieren. Wir können auch angeben, welches Repository verwendet werden soll.
Im nächsten Schritt müssen wir unsere Server zu dem Cluster hinzufügen, den wir erstellen werden.
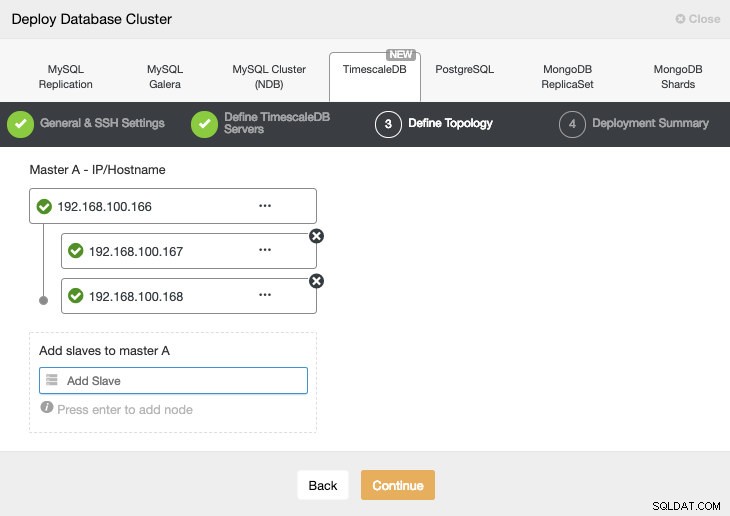
Beim Hinzufügen unserer Server können wir die IP oder den Hostnamen eingeben.
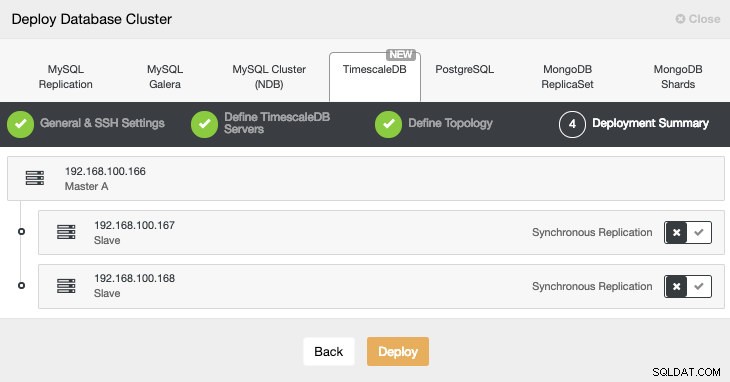
Im letzten Schritt können wir wählen, ob unsere Replikation synchron oder asynchron sein soll.
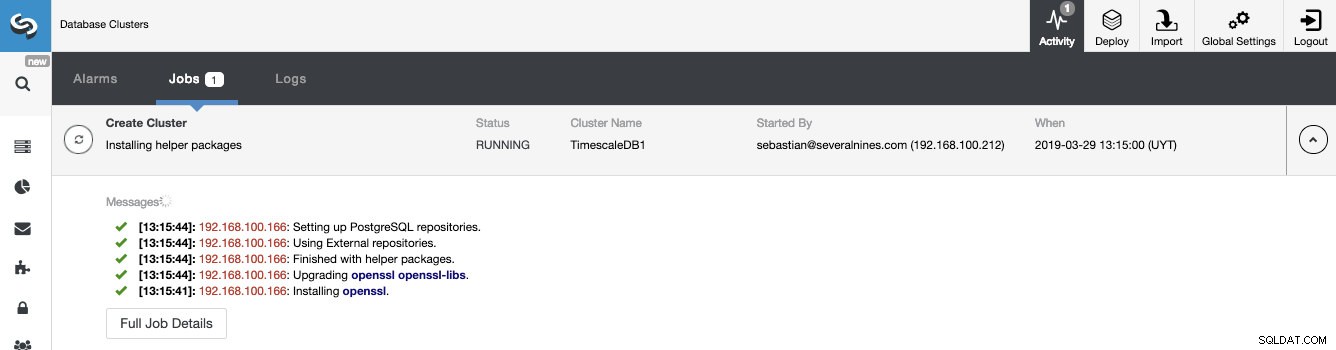
Wir können den Status der Erstellung unseres neuen Clusters über den Aktivitätsmonitor von ClusterControl überwachen.
Sobald die Aufgabe abgeschlossen ist, können wir unseren neuen TimescaleDB-Cluster im Hauptbildschirm von ClusterControl sehen.

Sobald wir unseren Cluster erstellt haben, können wir mehrere Aufgaben darauf ausführen, wie z. B. das Hinzufügen eines Load Balancer (HAProxy) oder eines neuen Replikats.
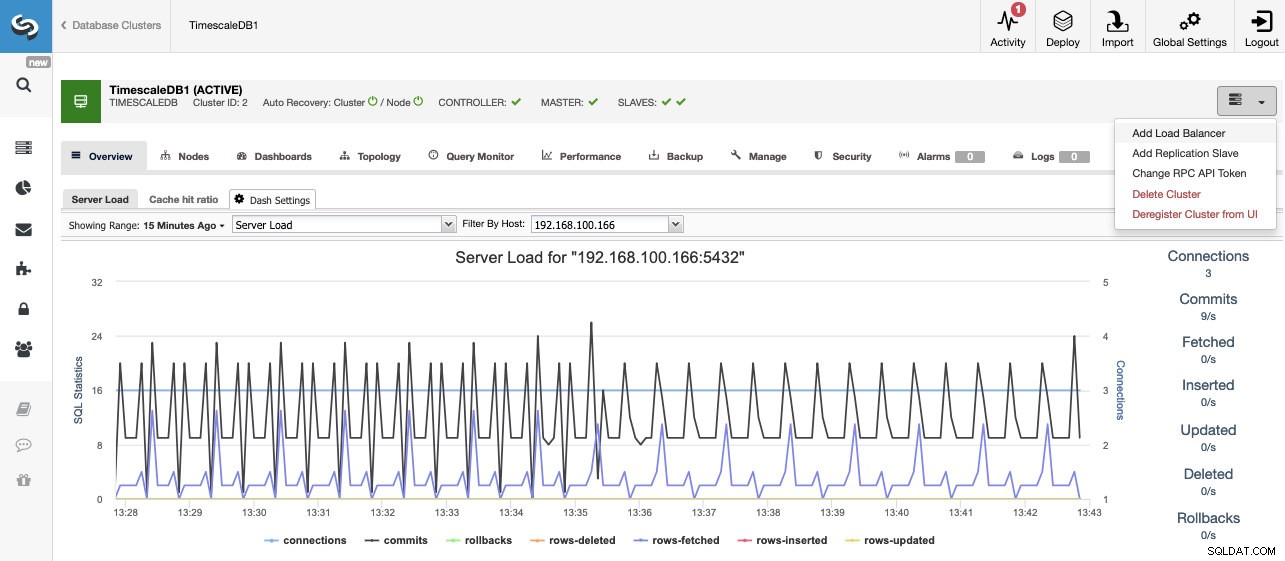
Skalierende ZeitskalaDB
Wenn wir zu den Cluster-Aktionen gehen und „Add Replication Slave“ auswählen, können wir entweder ein neues Replikat von Grund auf neu erstellen oder eine vorhandene TimescaleDB-Datenbank als Replikat hinzufügen.
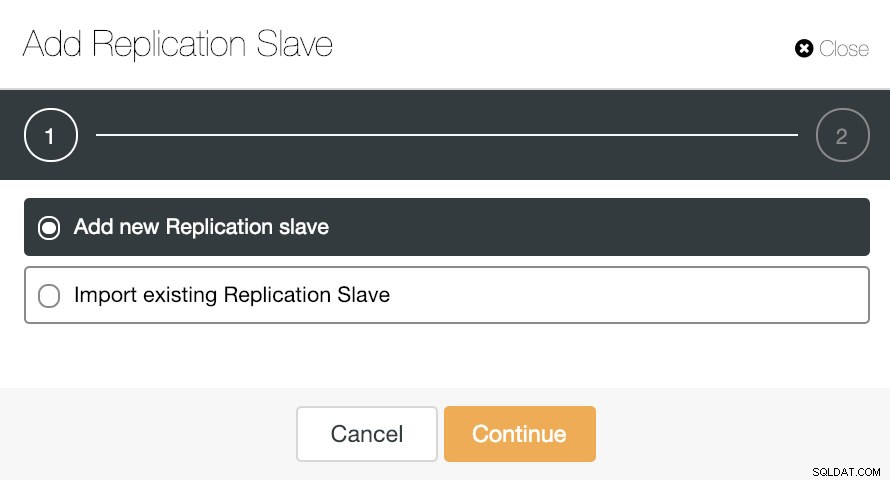
Mal sehen, wie das Hinzufügen eines neuen Replikations-Slaves eine wirklich einfache Aufgabe sein kann.
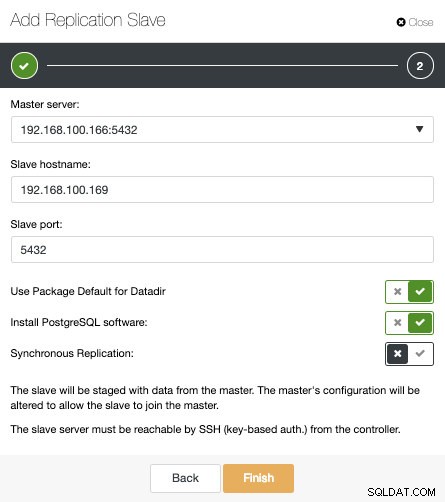
Wie Sie im Bild sehen können, müssen wir nur unseren Master-Server auswählen, die IP-Adresse für unseren neuen Slave-Server und den Datenbank-Port eingeben. Dann können wir wählen, ob ClusterControl die Software für uns installieren soll und ob der Replikations-Slave synchron oder asynchron sein soll.
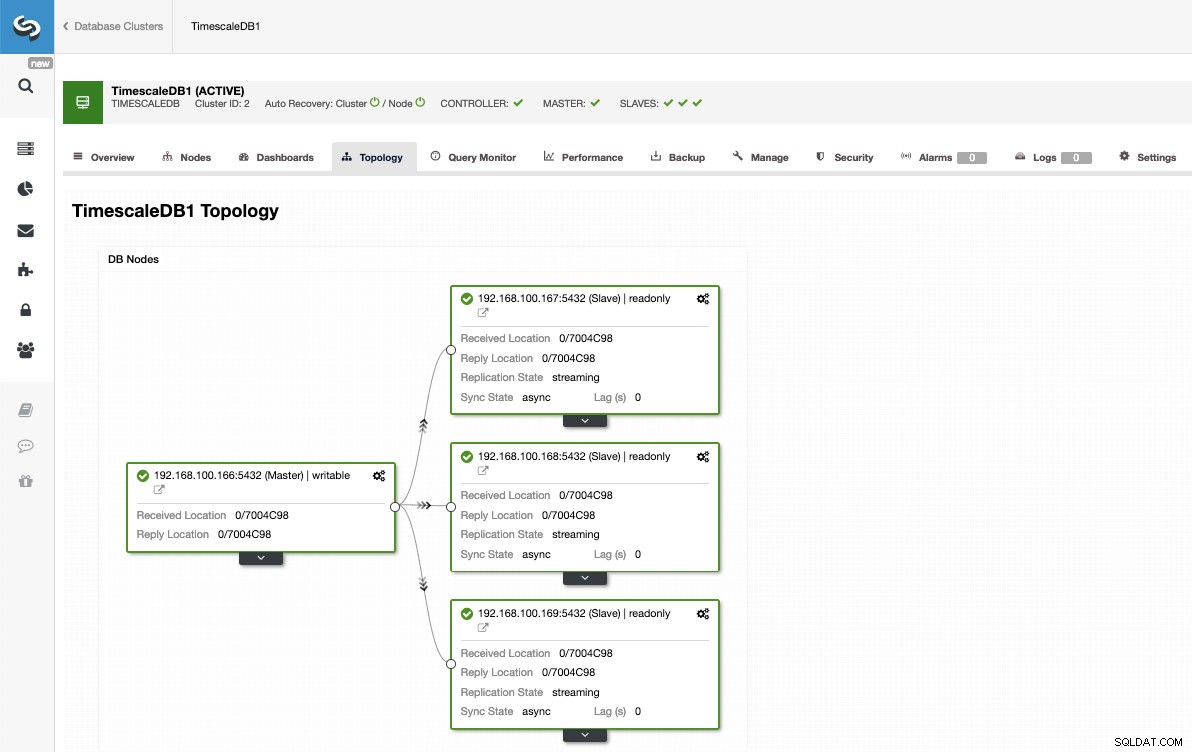
Auf diese Weise können wir beliebig viele Replikate hinzufügen und den Leseverkehr mithilfe eines Lastenausgleichs verteilen, den wir auch mit ClusterControl implementieren können.
Von ClusterControl aus können Sie auch verschiedene Verwaltungsaufgaben wie Neustart des Hosts, Rebuild Replication Slave oder Promote Slave mit einem Klick ausführen.
Schlussfolgerung
Wie wir oben gesehen haben, können Sie TimescaleDB jetzt mithilfe von ClusterControl bereitstellen. Nach der Bereitstellung bietet ClusterControl eine ganze Reihe von Funktionen, von Überwachung, Alarmierung, automatischem Failover, Backup, Point-in-Time-Recovery, Backup-Verifizierung bis hin zur Skalierung von Lesereplikaten. Dies kann Ihnen helfen, TimescaleDB auf benutzerfreundliche und intuitive Weise zu verwalten.