Dieser Artikel untersucht einige weniger bekannte Funktionen und Einschränkungen des Abfrageoptimierers und erläutert die Gründe für die extrem schlechte Hash-Join-Leistung in einem bestimmten Fall.
Beispieldaten
Das folgende Beispielskript zur Datenerstellung basiert auf einer vorhandenen Zahlentabelle. Wenn Sie noch keines davon haben, kann das folgende Skript verwendet werden, um eines effizient zu erstellen. Die resultierende Tabelle enthält eine einzelne Integer-Spalte mit Zahlen von eins bis zu einer Million:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
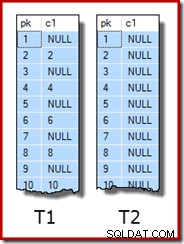
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Die Beispieldaten selbst bestehen aus zwei Tabellen, T1 und T2. Beide haben eine sequenzielle Ganzzahl-Primärschlüsselspalte mit dem Namen pk und eine zweite Nullable-Spalte mit dem Namen c1. Tabelle T1 hat 600.000 Zeilen, wobei Zeilen mit gerader Nummer denselben Wert für c1 haben wie die Spalte pk und Zeilen mit ungerader Nummer null sind. Tabelle c2 hat 32.000 Zeilen, wobei Spalte c1 in jeder Zeile NULL ist. Das folgende Skript erstellt und füllt diese Tabellen:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Die ersten zehn Zeilen mit Beispieldaten in jeder Tabelle sehen folgendermaßen aus:
Verbinden der beiden Tische
Bei diesem ersten Test werden die beiden Tabellen in Spalte c1 (nicht in der pk-Spalte) verknüpft und der pk-Wert aus Tabelle T1 für Zeilen zurückgegeben, die verknüpft werden:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Die Abfrage gibt tatsächlich keine Zeilen zurück, da Spalte c1 in allen Zeilen der Tabelle T2 NULL ist, sodass keine Zeile mit dem Gleichheits-Join-Prädikat übereinstimmen kann. Das mag seltsam klingen, aber ich bin mir sicher, dass es auf einer echten Produktionsabfrage basiert (zur leichteren Diskussion stark vereinfacht).
Beachten Sie, dass dieses leere Ergebnis nicht von der Einstellung von ANSI_NULLS abhängt, da dies nur steuert, wie Vergleiche mit einem Nullliteral oder einer Nullvariablen behandelt werden. Bei Spaltenvergleichen weist ein Gleichheitsprädikat immer Nullen zurück.
Der Ausführungsplan für diese einfache Verknüpfungsabfrage weist einige interessante Funktionen auf. Wir werden uns zuerst den Plan vor der Ausführung ('geschätzt') im SQL Sentry Plan Explorer ansehen:
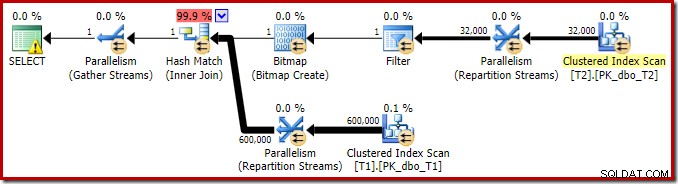
Die Warnung auf dem SELECT-Symbol beschwert sich nur über einen fehlenden Index in Tabelle T1 für Spalte c1 (mit pk als eingeschlossener Spalte). Der Indexvorschlag ist hier irrelevant.
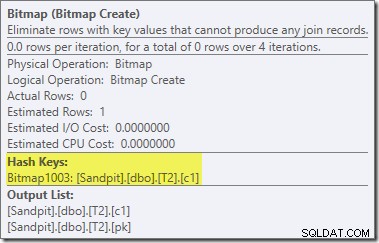
Das erste wirklich interessante Element in diesem Plan ist der Filter:
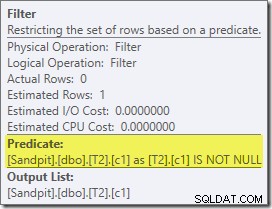
Dieses IS NOT NULL-Prädikat erscheint nicht in der Quellabfrage, obwohl es impliziert ist im Join-Prädikat wie zuvor erwähnt. Es ist interessant, dass er als expliziter zusätzlicher Operator herausgebrochen und vor die Join-Operation gestellt wurde. Beachten Sie, dass die Abfrage auch ohne den Filter immer noch korrekte Ergebnisse liefern würde – der Join selbst würde die Nullen immer noch ablehnen.
Der Filter ist auch aus anderen Gründen neugierig. Es hat geschätzte Kosten von genau null (obwohl erwartet wird, dass es auf 32.000 Zeilen arbeitet), und es wurde nicht als Restprädikat in den Clustered Index Scan gedrückt. Der Optimierer ist normalerweise sehr daran interessiert, dies zu tun.
Diese beiden Dinge werden durch die Tatsache erklärt, dass dieser Filter in einer Neufassung nach der Optimierung eingeführt wird. Nachdem der Abfrageoptimierer seine kostenbasierte Verarbeitung abgeschlossen hat, gibt es eine relativ kleine Anzahl von Umschreibungen mit festem Plan, die berücksichtigt werden. Einer von ihnen ist für die Einführung des Filters verantwortlich.
Wir können die Ausgabe der kostenbasierten Planauswahl (vor dem Umschreiben) mit den undokumentierten Trace-Flags 8607 und dem vertrauten 3604 sehen, um die Textausgabe an die Konsole zu leiten (Nachrichten-Tab in SSMS):
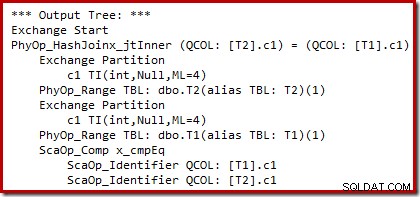
Der Ausgabebaum zeigt einen Hash-Join, zwei Scans und einige Parallelitäts-(Austausch-)Operatoren. Es gibt keinen nullabweisenden Filter für die Spalte c1 der Tabelle T2.
Die spezielle Umschreibung nach der Optimierung betrachtet ausschließlich die Build-Eingabe eines Hash-Joins. Abhängig von seiner Bewertung der Situation kann es einen expliziten Filter hinzufügen, um Zeilen abzulehnen, die im Join-Schlüssel null sind. Die Auswirkung des Filters auf die geschätzte Zeilenanzahl wird ebenfalls in den Ausführungsplan geschrieben, aber da die kostenbasierte Optimierung bereits abgeschlossen ist, werden keine Kosten für den Filter berechnet. Falls es nicht offensichtlich ist, dass die Berechnung der Kosten eine Zeitverschwendung ist, wenn alle kostenbasierten Entscheidungen bereits getroffen wurden.
Der Filter verbleibt direkt auf der Build-Eingabe und wird nicht in den Clustered Index Scan verschoben, da die Hauptoptimierungsaktivität abgeschlossen ist. Die Neuschreibungen nach der Optimierung sind praktisch Last-Minute-Optimierungen an einem abgeschlossenen Ausführungsplan.
Eine zweite und ziemlich separate Umschreibung nach der Optimierung ist für den Bitmap-Operator im endgültigen Plan verantwortlich (Sie haben vielleicht bemerkt, dass er auch in der 8607-Ausgabe fehlte):
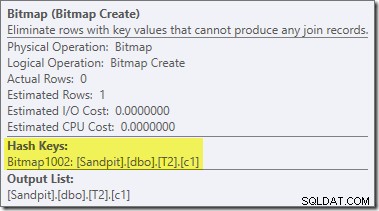
Dieser Operator hat außerdem geschätzte Nullkosten für E/A und CPU. Die andere Sache, die es als einen Operator identifiziert, der durch eine späte Optimierung eingeführt wurde (und nicht während der kostenbasierten Optimierung), ist, dass sein Name Bitmap gefolgt von einer Zahl ist. Es gibt andere Arten von Bitmaps, die während der kostenbasierten Optimierung eingeführt werden, wie wir etwas später sehen werden.
Das Wichtigste an dieser Bitmap ist vorerst, dass sie c1-Werte aufzeichnet, die während der Erstellungsphase des Hash-Joins gesehen wurden. Die fertige Bitmap wird auf die Sondenseite des Joins geschoben, wenn der Hash von der Erstellungsphase in die Sondenphase übergeht. Die Bitmap wird verwendet, um eine frühe Semi-Join-Reduktion durchzuführen, wodurch Zeilen von der Sondenseite eliminiert werden, die möglicherweise nicht verbunden werden können. Wenn Sie weitere Einzelheiten dazu benötigen, lesen Sie bitte meinen vorherigen Artikel zu diesem Thema.
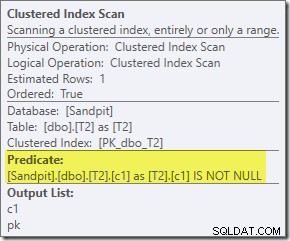
Der zweite Effekt der Bitmap ist beim sondenseitigen Clustered Index Scan zu sehen:
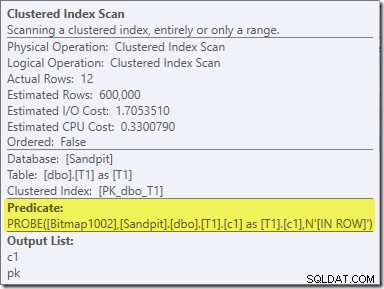
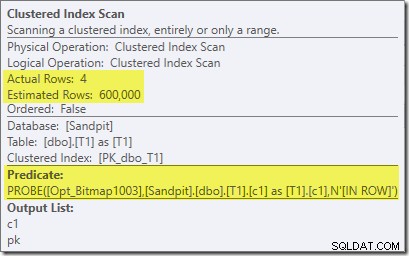
Der obige Screenshot zeigt die vollständige Bitmap, die als Teil des Clustered Index Scan auf Tabelle T1 überprüft wird. Da die Quellspalte eine Ganzzahl ist (ein Bigint würde auch funktionieren), wird die Bitmap-Prüfung ganz in die Speicher-Engine geschoben (wie durch das Qualifikationsmerkmal „INROW“ angezeigt), anstatt vom Abfrageprozessor geprüft zu werden. Allgemeiner kann die Bitmap von der Vermittlung abwärts auf jeden Operator auf der Sondenseite angewendet werden. Wie weit der Abfrageprozessor die Bitmap verschieben kann, hängt vom Typ der Spalte und der Version von SQL Server ab.
Um die Analyse der Hauptmerkmale dieses Ausführungsplans zu vervollständigen, müssen wir uns den Plan nach der Ausführung („tatsächlich“) ansehen:
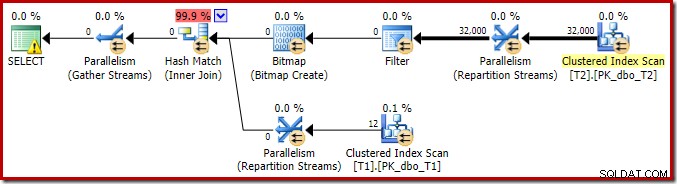
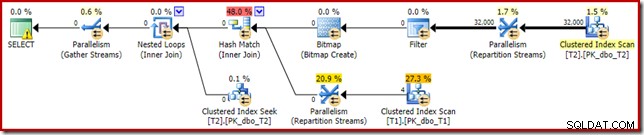
Das erste, was auffällt, ist die Verteilung der Zeilen über die Threads zwischen dem T2-Scan und dem Repartition Streams-Austausch direkt darüber. Bei einem Testlauf sah ich die folgende Verteilung auf einem System mit vier logischen Prozessoren:
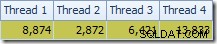
Die Verteilung ist nicht besonders gleichmäßig, wie es oft bei einem parallelen Scan auf einer relativ kleinen Anzahl von Zeilen der Fall ist, aber immerhin haben alle Threads etwas Arbeit erhalten. Die Thread-Verteilung zwischen demselben Austausch von Repartition Streams und dem Filter ist sehr unterschiedlich:
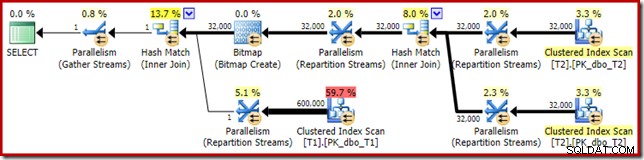
Dies zeigt, dass alle 32.000 Zeilen aus Tabelle T2 von einem einzigen Thread verarbeitet wurden. Um zu sehen, warum, müssen wir uns die Austauscheigenschaften ansehen:

Dieser Austausch muss, wie der auf der Sondenseite des Hash-Joins, sicherstellen, dass Zeilen mit denselben Join-Schlüsselwerten in derselben Instanz des Hash-Joins landen. Bei DOP 4 gibt es vier Hash-Joins, jeder mit seiner eigenen Hash-Tabelle. Für korrekte Ergebnisse müssen aufbauseitige Zeilen und probeseitige Zeilen mit denselben Join-Schlüsseln denselben Hash-Join erreichen; andernfalls könnten wir eine Zeile auf der Sondenseite mit der falschen Hash-Tabelle vergleichen.
In einem parallelen Plan im Zeilenmodus erreicht SQL Server dies, indem beide Eingaben neu partitioniert werden, indem dieselbe Hashfunktion für die Join-Spalten verwendet wird. Im vorliegenden Fall befindet sich der Join in Spalte c1, sodass die Eingaben über Threads verteilt werden, indem eine Hash-Funktion (Partitionierungstyp:Hash) auf die Join-Schlüsselspalte (c1) angewendet wird. Das Problem hierbei ist, dass Spalte c1 nur einen einzigen Wert – null – in Tabelle T2 enthält, sodass alle 32.000 Zeilen denselben Hashwert erhalten, sodass alle im selben Thread landen.
Die gute Nachricht ist, dass all dies für diese Abfrage nicht wirklich wichtig ist. Der Rewrite-Filter nach der Optimierung eliminiert alle Zeilen, bevor sehr viel Arbeit erledigt ist. Auf meinem Laptop wird die obige Abfrage in etwa 70 ms ausgeführt (was wie erwartet keine Ergebnisse liefert). .
Drei Tische verbinden
Für den zweiten Test fügen wir einen zusätzlichen Join von Tabelle T2 zu sich selbst auf ihrem Primärschlüssel hinzu:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Dies ändert nicht die logischen Ergebnisse der Abfrage, aber es ändert den Ausführungsplan:
Wie erwartet hat der Self-Join der Tabelle T2 auf ihrem Primärschlüssel keine Auswirkung auf die Anzahl der Zeilen, die aus dieser Tabelle qualifiziert sind:
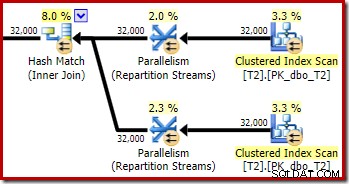
Auch die Verteilung der Zeilen auf die Threads ist in diesem Planabschnitt gut. Bei den Scans ist es ähnlich wie zuvor, da der parallele Scan Zeilen nach Bedarf auf Threads verteilt. Die Austauschpartitionierung basiert auf einem Hash des Join-Schlüssels, der diesmal die pk-Spalte ist. Angesichts der Bandbreite unterschiedlicher pk-Werte ist die resultierende Thread-Verteilung auch sehr gleichmäßig:
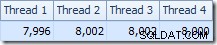
Im interessanteren Abschnitt des geschätzten Plans gibt es einige Unterschiede zum Zwei-Tabellen-Test:

Auch hier leitet der Build-seitige Austausch alle Zeilen an denselben Thread weiter, da c1 der Join-Schlüssel und damit die Partitionierungsspalte für den Repartition Streams-Austausch ist (denken Sie daran, dass c1 für alle Zeilen in Tabelle T2 null ist). P>
Es gibt zwei weitere wichtige Unterschiede in diesem Abschnitt des Plans im Vergleich zum vorherigen Test. Erstens gibt es keinen Filter zum Entfernen von null-c1-Zeilen von der Erstellungsseite des Hash-Joins. Die Erklärung dafür hängt mit dem zweiten Unterschied zusammen – die Bitmap hat sich geändert, obwohl es aus dem obigen Bild nicht ersichtlich ist:
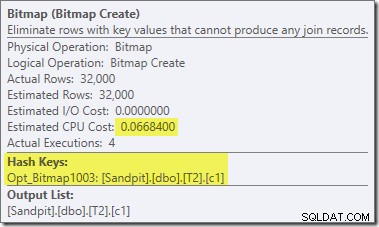
Dies ist eine Opt_Bitmap, keine Bitmap. Der Unterschied besteht darin, dass diese Bitmap während der kostenbasierten Optimierung eingeführt wurde, nicht durch eine Umschreibung in letzter Minute. Der Mechanismus, der optimierte Bitmaps berücksichtigt, ist mit der Verarbeitung von Star-Join-Abfragen verbunden. Die Star-Join-Logik erfordert mindestens drei verknüpfte Tabellen, was erklärt, warum eine optimierte Bitmap wurde im Join-Beispiel mit zwei Tabellen nicht berücksichtigt.
Diese optimierte Bitmap hat geschätzte CPU-Kosten ungleich Null und wirkt sich direkt auf den vom Optimierer gewählten Gesamtplan aus. Seine Auswirkung auf die sondenseitige Kardinalitätsschätzung ist beim Repartition Streams-Operator zu sehen:
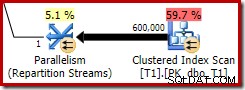
Beachten Sie, dass der Kardinalitätseffekt beim Austausch zu sehen ist, obwohl die Bitmap schließlich ganz nach unten in die Speicher-Engine ('INROW') geschoben wird, genau wie wir es im ersten Test gesehen haben (aber beachten Sie jetzt die Opt_Bitmap-Referenz):
Der (tatsächliche) Plan nach der Ausführung sieht wie folgt aus:
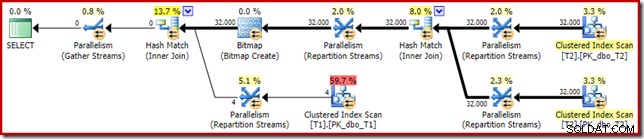
Die vorhergesagte Wirksamkeit der optimierten Bitmap bedeutet, dass das separate Umschreiben nach der Optimierung für den Nullfilter nicht angewendet wird. Ich persönlich halte das für unglücklich, da das frühzeitige Eliminieren der Nullen mit einem Filter die Notwendigkeit zunichte machen würde, die Bitmap zu erstellen, die Hash-Tabellen zu füllen und den Bitmap-erweiterten Scan der Tabelle T1 durchzuführen. Nichtsdestotrotz entscheidet der Optimierer anders und es gibt in diesem Fall einfach keine Diskussion darüber.
Trotz des zusätzlichen Self-Join von Tabelle T2 und der zusätzlichen Arbeit, die mit dem fehlenden Filter verbunden ist, erzeugt dieser Ausführungsplan immer noch das erwartete Ergebnis (keine Zeilen) in kurzer Zeit. Eine typische Ausführung auf meinem Laptop dauert etwa 200 ms .
Datentyp ändern
Für diesen dritten Test ändern wir den Datentyp der Spalte c1 in beiden Tabellen von Integer in Dezimal. Diese Wahl ist nichts Besonderes; Derselbe Effekt kann bei jedem numerischen Typ beobachtet werden, der nicht Integer oder Bigint ist.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Wiederverwendung der Three-Join-Join-Abfrage:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Der geschätzte Ausführungsplan kommt mir sehr bekannt vor:
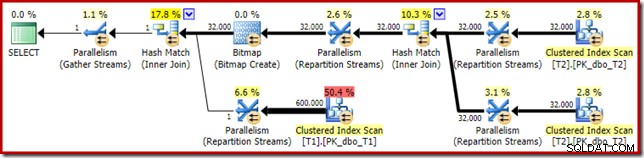
Abgesehen davon, dass die optimierte Bitmap aufgrund der Änderung des Datentyps nicht mehr 'INROW' von der Speicher-Engine angewendet werden kann, ist der Ausführungsplan im Wesentlichen identisch. Die folgende Aufnahme zeigt die Änderung der Scaneigenschaften:
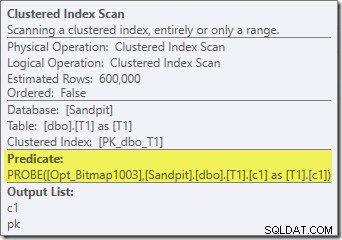
Leider wird die Leistung ziemlich dramatisch beeinträchtigt. Diese Abfrage wird nicht in 70 ms oder 200 ms ausgeführt, sondern in etwa 20 Minuten . In dem Test, der zu folgendem Post-Execution-Plan führte, betrug die Laufzeit tatsächlich 22 Minuten und 29 Sekunden:

Der offensichtlichste Unterschied besteht darin, dass der Clustered Index Scan auf Tabelle T1 300.000 Zeilen zurückgibt, selbst nachdem der optimierte Bitmap-Filter angewendet wurde. Das macht Sinn, da die Bitmap auf Zeilen aufgebaut ist, die nur Nullen in der Spalte c1 enthalten. Die Bitmap entfernt Nicht-Null-Zeilen aus dem T1-Scan und lässt nur die 300.000 Zeilen mit Nullwerten für c1 übrig. Denken Sie daran, dass die Hälfte der Zeilen in T1 null sind.
Trotzdem scheint es seltsam, dass das Verbinden von 32.000 Zeilen mit 300.000 Zeilen über 20 Minuten dauern sollte. Falls Sie sich wundern, ein CPU-Kern wurde für die gesamte Ausführung auf 100 % festgelegt. Die Erklärung für diese schlechte Leistung und extreme Ressourcennutzung baut auf einigen Ideen auf, die wir zuvor untersucht haben:
Wir wissen zum Beispiel bereits, dass trotz der parallelen Ausführungssymbole alle Zeilen von T2 auf demselben Thread landen. Zur Erinnerung:Der parallele Hash-Join im Zeilenmodus erfordert eine Neupartitionierung der Join-Spalten (c1). Alle Zeilen von T2 haben denselben Wert – null – in Spalte c1, sodass alle Zeilen auf demselben Thread landen. In ähnlicher Weise haben alle Zeilen von T1, die den Bitmap-Filter passieren, auch Null in Spalte c1, sodass sie auch in denselben Thread neu partitioniert werden. Dies erklärt, warum ein einzelner Kern die ganze Arbeit erledigt.
Es mag immer noch unangemessen erscheinen, dass das Hash-Verbinden von 32.000 Zeilen mit 300.000 Zeilen 20 Minuten dauern sollte, insbesondere da die Join-Spalten auf beiden Seiten null sind und sowieso nicht verbunden werden. Um dies zu verstehen, müssen wir darüber nachdenken, wie dieser Hash-Join funktioniert.
Die Build-Eingabe (die 32.000 Zeilen) erstellt eine Hash-Tabelle unter Verwendung der Join-Spalte c1. Da jede Build-seitige Zeile denselben Wert (Null) für die Join-Spalte c1 enthält, bedeutet dies, dass alle 32.000 Zeilen im selben Hash-Bucket landen. Wenn der Hash-Join auf die Suche nach Übereinstimmungen umschaltet, hasht jede Zeile auf der Prüfseite mit einer c1-Nullspalte ebenfalls in denselben Bucket. Der Hash-Join muss dann alle 32.000 Einträge in diesem Bucket auf Übereinstimmung prüfen.
Die Überprüfung der 300.000 Sondenreihen ergibt 32.000 Vergleiche, die 300.000 Mal durchgeführt werden. Dies ist der schlimmste Fall für einen Hash-Join:Alle Build-Seitenreihen werden in denselben Bucket gehasht, was im Wesentlichen zu einem kartesischen Produkt führt. Dies erklärt die lange Ausführungszeit und die konstante Prozessorauslastung von 100 %, da der Hash der langen Hash-Bucket-Kette folgt.
Diese schlechte Leistung erklärt, warum das Umschreiben nach der Optimierung zum Eliminieren von Nullen in der Build-Eingabe für einen Hash-Join vorhanden ist. Leider wurde der Filter in diesem Fall nicht angewendet.
Problemumgehungen
Der Optimierer wählt diese Planform, weil er fälschlicherweise davon ausgeht, dass die optimierte Bitmap alle Zeilen aus Tabelle T1 herausfiltern wird. Obwohl diese Schätzung bei den Repartition Streams anstelle des Clustered Index Scan angezeigt wird, ist dies immer noch die Grundlage der Entscheidung. Zur Erinnerung hier noch einmal der relevante Abschnitt des Vorabausführungsplans:
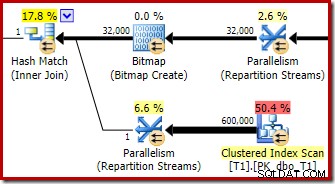
Wenn dies eine korrekte Schätzung wäre, würde es überhaupt keine Zeit dauern, den Hash-Join zu verarbeiten. Es ist bedauerlich, dass die Selektivitätsschätzung für die optimierte Bitmap so falsch ist, wenn der Datentyp keine einfache Ganzzahl oder Bigint ist. Es scheint, dass eine Bitmap, die auf einem Integer- oder Bigint-Schlüssel basiert, auch Nullzeilen herausfiltern kann, die nicht verknüpft werden können. Wenn dies tatsächlich der Fall ist, ist dies ein Hauptgrund dafür, Integer- oder Bigint-Join-Spalten zu bevorzugen.
Die folgenden Problemumgehungen basieren größtenteils auf der Idee, die problematischen optimierten Bitmaps zu beseitigen.
Serienausführung
Eine Möglichkeit zu verhindern, dass optimierte Bitmaps berücksichtigt werden, besteht darin, einen nicht parallelen Plan zu fordern. Zeilenmodus-Bitmap-Operatoren (optimiert oder anderweitig) werden nur in parallelen Plänen angezeigt:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Diese Abfrage wird unter Verwendung einer etwas anderen Syntax mit einem FORCE ORDER-Hinweis ausgedrückt, um eine Planform zu erzeugen, die leichter mit den vorherigen parallelen Plänen vergleichbar ist. Das wesentliche Feature ist der MAXDOP 1 Hint.
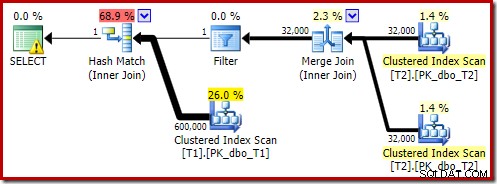
Dieser geschätzte Plan zeigt, dass der Rewrite-Filter nach der Optimierung wiederhergestellt wird:
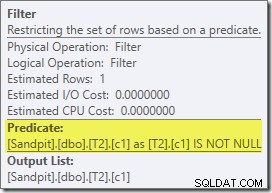
Die Post-Execution-Version des Plans zeigt, dass alle Zeilen aus der Build-Eingabe herausgefiltert werden, was bedeutet, dass der Probe-Side-Scan insgesamt übersprungen werden kann:
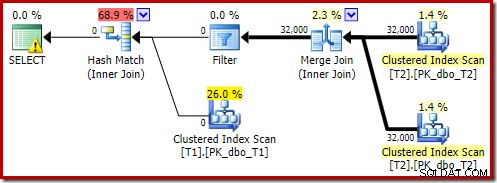
Wie zu erwarten, wird diese Version der Abfrage sehr schnell ausgeführt – bei mir im Durchschnitt etwa 20 ms. Wir können einen ähnlichen Effekt ohne den Hinweis FORCE ORDER und das Umschreiben der Abfrage erzielen:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
Der Optimierer wählt in diesem Fall eine andere Planform, wobei der Filter direkt über dem Scan von T2 platziert wird:
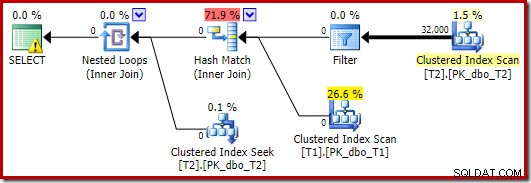
Dies wird sogar noch schneller ausgeführt – in etwa 10 ms – als man erwarten würde. Dies wäre natürlich keine gute Wahl, wenn die Anzahl der vorhandenen (und verbindbaren) Zeilen viel größer wäre.
Optimierte Bitmaps deaktivieren
Es gibt keinen Abfragehinweis zum Deaktivieren optimierter Bitmaps, aber wir können den gleichen Effekt erzielen, indem wir ein paar undokumentierte Trace-Flags verwenden. Wie immer gilt dies nur für den Zinswert; Sie würden diese niemals in einem realen System oder einer Anwendung verwenden wollen:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Der resultierende Ausführungsplan lautet:
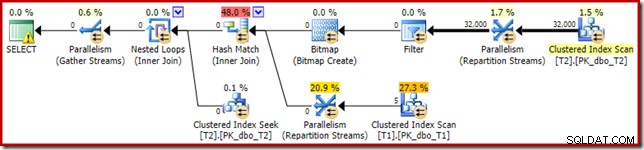
Die Bitmap dort ist eine nach der Optimierung neu geschriebene Bitmap, keine optimierte Bitmap:
Beachten Sie die Nullkostenschätzungen und den Bitmap-Namen (anstelle von Opt_Bitmap). ohne eine optimierte Bitmap, um die Kostenschätzungen zu verzerren, wird das Neuschreiben nach der Optimierung aktiviert, um einen nullzurückweisenden Filter einzuschließen. Dieser Ausführungsplan wird in etwa 70 ms ausgeführt .
Derselbe Ausführungsplan (mit Filter und nicht optimiertem Bitmap) kann auch erzeugt werden, indem die Optimiererregel deaktiviert wird, die für das Generieren von Star-Join-Bitmap-Plänen verantwortlich ist (wieder strikt undokumentiert und nicht für den realen Gebrauch):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Inklusive eines expliziten Filters
Dies ist die einfachste Option, aber man würde nur daran denken, wenn man sich der bisher diskutierten Probleme bewusst ist. Da wir nun wissen, dass wir Nullen aus T2.c1 eliminieren müssen, können wir dies direkt zur Abfrage hinzufügen:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Der resultierende geschätzte Ausführungsplan entspricht vielleicht nicht ganz Ihren Erwartungen:
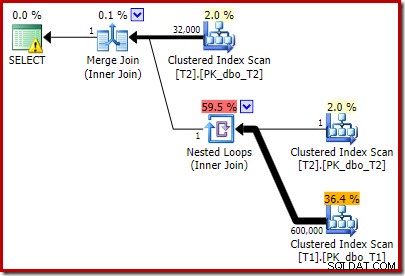
Das zusätzliche Prädikat, das wir hinzugefügt haben, wurde in den mittleren Clustered Index Scan von T2:
verschoben
Der Nachausführungsplan lautet:
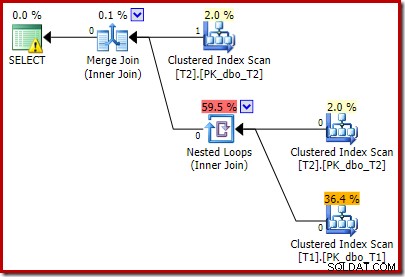
Beachten Sie, dass der Merge Join heruntergefahren wird, nachdem er eine Zeile von seiner oberen Eingabe gelesen hat und dann keine Zeile in seiner unteren Eingabe findet, aufgrund der Wirkung des Prädikats, das wir hinzugefügt haben. Der Clustered-Index-Scan der Tabelle T1 wird überhaupt nie ausgeführt, da der Nested-Loops-Join niemals eine Zeile an seiner treibenden Eingabe erhält. Dieses letzte Abfrageformular wird in ein oder zwei Millisekunden ausgeführt.
Abschließende Gedanken
In diesem Artikel wurden einige weniger bekannte Verhaltensweisen von Abfrageoptimierern untersucht und die Gründe für die extrem schlechte Hash-Join-Leistung in einem bestimmten Fall erläutert.
Es mag verlockend sein zu fragen, warum der Optimierer vor Gleichheitsverknüpfungen nicht routinemäßig nullabweisende Filter hinzufügt. Man kann nur vermuten, dass dies nicht in genügend häufigen Fällen von Vorteil wäre. Es ist nicht zu erwarten, dass die meisten Joins auf viele null =null-Ablehnungen stoßen, und das routinemäßige Hinzufügen von Prädikaten könnte schnell kontraproduktiv werden, insbesondere wenn viele Join-Spalten vorhanden sind. Für die meisten Joins ist das Zurückweisen von Nullen innerhalb des Join-Operators wahrscheinlich eine bessere Option (aus Sicht des Kostenmodells) als das Einführen eines expliziten Filters.
Es scheint, dass Anstrengungen unternommen werden, um zu verhindern, dass sich die schlimmsten Fälle durch die Umschreibung nach der Optimierung manifestieren, die darauf ausgelegt ist, Null-Join-Zeilen abzulehnen, bevor sie die Build-Eingabe eines Hash-Joins erreichen. Es scheint, dass eine unglückliche Wechselwirkung zwischen der Wirkung optimierter Bitmap-Filter und der Anwendung dieser Umschreibung besteht. Es ist auch bedauerlich, dass, wenn dieses Leistungsproblem auftritt, es sehr schwierig ist, es allein anhand des Ausführungsplans zu diagnostizieren.
Im Moment scheint es die beste Option zu sein, sich dieses potenziellen Leistungsproblems mit Hash-Joins für Nullable-Spalten bewusst zu sein und explizite nullabweisende Prädikate (mit einem Kommentar!) hinzuzufügen, um sicherzustellen, dass bei Bedarf ein effizienter Ausführungsplan erstellt wird. Die Verwendung eines MAXDOP 1-Hinweises kann auch einen alternativen Plan mit vorhandenem verräterischem Filter aufdecken.
Als allgemeine Regel gilt, dass Abfragen, die Spalten vom Typ Integer verknüpfen und nach vorhandenen Daten suchen, tendenziell besser zum Optimierermodell und den Fähigkeiten der Ausführungsmaschine passen als die Alternativen.
Danksagungen
Ich möchte SQL_Sasquatch (@sqL_handLe) für seine Erlaubnis danken, auf seinen ursprünglichen Artikel mit einer technischen Analyse zu antworten. Die hier verwendeten Beispieldaten basieren stark auf diesem Artikel.
Ich möchte auch Rob Farley (blog | twitter) für unsere technischen Diskussionen im Laufe der Jahre danken, insbesondere für eine im Januar 2015, in der wir die Auswirkungen von Prädikaten, die zusätzliche Nullen ablehnen, für Equi-Joins diskutiert haben. Rob hat mehrere Male über verwandte Themen geschrieben, unter anderem in Inverse Predicates – schau in beide Richtungen, bevor du kreuzt.