Sie haben wahrscheinlich einige dieser Fehler gemacht, als Sie Ihre Karriere als Datenbankdesigner begonnen haben. Vielleicht stellen Sie sie immer noch her, oder Sie werden in Zukunft welche herstellen. Wir können die Zeit nicht zurückdrehen und Ihnen helfen, Ihre Fehler rückgängig zu machen, aber wir können Sie vor einigen zukünftigen (oder gegenwärtigen) Kopfschmerzen bewahren.
Das Lesen dieses Artikels kann Ihnen viele Stunden ersparen, die Sie mit der Behebung von Design- und Codeproblemen verbringen, also lassen Sie uns eintauchen. Ich habe die Liste der Fehler in zwei Hauptgruppen unterteilt:diejenigen, die nicht technisch sind in der Natur und solche, die rein technisch sind . Diese beiden Gruppen sind ein wichtiger Bestandteil des Datenbankdesigns.
Wenn Sie keine technischen Fähigkeiten haben, wissen Sie natürlich nicht, wie man etwas macht. Es ist nicht überraschend, diese Fehler in der Liste zu sehen. Aber nicht-technische Fähigkeiten? Die Leute mögen sie vergessen, aber diese Fähigkeiten sind auch ein sehr wichtiger Teil des Designprozesses. Sie werten Ihren Code auf und setzen die Technologie in Beziehung zu dem realen Problem, das Sie lösen müssen.
Beginnen wir also zuerst mit den nicht technischen Problemen und gehen dann zu den technischen über.
Nichttechnische Fehler beim Datenbankdesign
#1 Schlechte Planung
Dies ist definitiv ein nicht technisches Problem, aber es ist ein großes und häufiges Problem. Wir alle freuen uns, wenn ein neues Projekt beginnt und alles sieht gut aus. Am Anfang ist das Projekt noch ein unbeschriebenes Blatt und Sie und Ihr Kunde freuen sich darauf, an etwas zu arbeiten, das Ihnen beiden eine bessere Zukunft schafft. Das ist alles großartig, und eine großartige Zukunft wird wahrscheinlich das Endergebnis sein. Aber trotzdem müssen wir konzentriert bleiben. Dies ist der Teil des Projekts, in dem wir entscheidende Fehler machen können.
Bevor Sie sich hinsetzen, um ein Datenmodell zu zeichnen, müssen Sie sicher sein, dass:
- Sie wissen genau, was Ihr Kunde tut (d. h. seine Geschäftspläne in Bezug auf dieses Projekt und auch sein Gesamtbild) und was er mit diesem Projekt jetzt und in Zukunft erreichen möchte.
- Sie verstehen den Geschäftsprozess und sind bei Bedarf bereit, Vorschläge zu machen, um ihn zu vereinfachen und zu verbessern (z. B. zur Steigerung der Effizienz und des Einkommens, zur Reduzierung von Kosten und Arbeitszeiten usw.).
- Sie verstehen den Datenfluss im Unternehmen des Kunden. Im Idealfall wüssten Sie jedes Detail:wer mit den Daten arbeitet, wer Änderungen vornimmt, welche Berichte benötigt werden, wann und warum das alles passiert.
- Sie können die Sprache/Terminologie verwenden, die Ihr Kunde verwendet. Während Sie vielleicht ein Experte auf ihrem Gebiet sind oder nicht, ist Ihr Kunde es definitiv. Bitten Sie sie, zu erklären, was Sie nicht verstehen. Und wenn Sie dem Kunden technische Details erklären, verwenden Sie Sprache und Terminologie, die er versteht.
- Sie wissen, welche Technologien Sie verwenden werden, von der Datenbank-Engine und Programmiersprachen bis hin zu anderen Tools. Wofür Sie sich entscheiden, hängt eng mit dem Problem zusammen, das Sie lösen werden, aber es ist wichtig, die Präferenzen des Kunden und seine aktuelle IT-Infrastruktur einzubeziehen.
Während der Planungsphase sollten Sie Antworten auf diese Fragen erhalten:
- Welche Tabellen werden die zentralen Tabellen in Ihrem Modell sein? Sie werden wahrscheinlich einige davon haben, während die anderen Tabellen einige der üblichen sein werden (z. B. user_account, role). Vergessen Sie nicht Wörterbücher und Beziehungen zwischen Tabellen.
- Welche Namen werden für Tabellen im Modell verwendet? Denken Sie daran, die Terminologie ähnlich derjenigen zu halten, die der Client derzeit verwendet.
- Welche Regeln gelten beim Benennen von Tabellen und anderen Objekten? (Siehe Punkt 4 zu Namenskonventionen.)
- Wie lange wird das gesamte Projekt dauern? Dies ist wichtig, sowohl für Ihren Zeitplan als auch für den Zeitplan des Kunden.
Erst wenn Sie all diese Antworten haben, sind Sie bereit, eine erste Lösung des Problems zu teilen. Diese Lösung muss keine vollständige Bewerbung sein – vielleicht ein kurzes Dokument oder sogar ein paar Sätze in der Sprache des Unternehmens des Kunden.
Gute Planung ist nicht spezifisch für die Datenmodellierung; Es ist auf fast jedes IT-Projekt (und Nicht-IT-Projekt) anwendbar. Überspringen ist nur eine Option, wenn 1) Sie ein wirklich kleines Projekt haben; 2) die Aufgaben und Ziele klar sind und 3) Sie es sehr eilig haben. Ein historisches Beispiel sind die Startingenieure von Sputnik 1, die den Technikern, die ihn zusammenbauten, mündliche Anweisungen gaben. Das Projekt war in Eile wegen der Nachricht, dass die USA planten, bald einen eigenen Satelliten zu starten – aber ich denke, Sie werden es nicht so eilig haben.
#2 Unzureichende Kommunikation mit Kunden und Entwicklern
Wenn Sie mit dem Designprozess der Datenbank beginnen, werden Sie wahrscheinlich die meisten Hauptanforderungen verstehen. Einige sind unabhängig vom Geschäft sehr verbreitet, z. Benutzerrollen und Status. Andererseits sind einige Tabellen in Ihrem Modell ziemlich spezifisch. Wenn Sie beispielsweise ein Modell für ein Taxiunternehmen erstellen, haben Sie Tabellen für Fahrzeuge, Fahrer, Kunden usw.
Dennoch wird zu Beginn eines Projekts nicht alles offensichtlich sein. Möglicherweise missverstehen Sie einige Anforderungen, der Kunde fügt möglicherweise einige neue Funktionen hinzu, Sie sehen etwas, das anders gemacht werden könnte, der Prozess kann sich ändern usw. All dies führt zu Änderungen im Modell. Die meisten Änderungen erfordern das Hinzufügen neuer Tabellen, aber manchmal werden Sie Tabellen entfernen oder ändern. Wenn Sie bereits mit dem Schreiben von Code begonnen haben, der diese Tabellen verwendet, müssen Sie diesen Code ebenfalls neu schreiben.
Um den Zeitaufwand für unerwartete Änderungen zu reduzieren, sollten Sie:
- Sprechen Sie mit Entwicklern und Kunden und haben Sie keine Angst, wichtige geschäftliche Fragen zu stellen. Wenn Sie denken, dass Sie bereit sind, zu beginnen, fragen Sie sich:Ist Situation X in unserer Datenbank abgedeckt? Der Client macht derzeit Y auf diese Weise; Erwarten wir in naher Zukunft eine Änderung? Sobald wir sicher sind, dass unser Modell in der Lage ist, alles, was wir brauchen, auf die richtige Weise zu speichern, können wir mit dem Codieren beginnen.
- Wenn Sie vor einer größeren Änderung in Ihrem Design stehen und bereits viel Code geschrieben haben, sollten Sie nicht nach einer schnellen Lösung suchen. Machen Sie es so, wie es hätte gemacht werden sollen, egal in welcher aktuellen Situation. Eine schnelle Lösung könnte jetzt etwas Zeit sparen und würde wahrscheinlich eine Weile gut funktionieren, aber es kann später zu einem echten Albtraum werden.
- Wenn Sie der Meinung sind, dass etwas jetzt in Ordnung ist, aber später zu einem Problem werden könnte, ignorieren Sie es nicht. Analysieren Sie diesen Bereich und implementieren Sie Änderungen, wenn sie die Qualität und Leistung des Systems verbessern. Es wird einige Zeit kosten, aber Sie werden ein besseres Produkt liefern und viel besser schlafen.
Wenn Sie versuchen, Änderungen an Ihrem Datenmodell zu vermeiden, wenn Sie ein potenzielles Problem sehen – oder wenn Sie sich für eine schnelle Lösung entscheiden, anstatt es richtig zu machen – werden Sie früher oder später dafür bezahlen.
Bleiben Sie auch während des gesamten Projekts mit Ihrem Kunden und den Entwicklern in Kontakt. Überprüfen Sie immer, ob seit Ihrer letzten Diskussion Änderungen vorgenommen wurden.
#3 Schlechte oder fehlende Dokumentation
Für die meisten von uns steht die Dokumentation am Ende des Projekts. Wenn wir gut organisiert sind, haben wir unterwegs wahrscheinlich alles dokumentiert und müssen nur noch alles zusammenfassen. Aber ehrlich gesagt ist das normalerweise nicht der Fall. Das Schreiben der Dokumentation erfolgt unmittelbar vor Abschluss des Projekts – und unmittelbar nachdem wir mit diesem Datenmodell fertig sind!
Der Preis für ein schlecht dokumentiertes Projekt kann ziemlich hoch sein, ein paar Mal höher als der Preis, den wir zahlen, um alles ordnungsgemäß zu dokumentieren. Stellen Sie sich vor, Sie finden einige Monate nach Abschluss des Projekts einen Fehler. Weil Sie nicht richtig dokumentiert haben, wissen Sie nicht, wo Sie anfangen sollen.
Vergessen Sie bei der Arbeit nicht, Kommentare zu schreiben. Erklären Sie alles, was einer zusätzlichen Erklärung bedarf, und schreiben Sie grundsätzlich alles auf, von dem Sie glauben, dass es eines Tages nützlich sein wird. Sie wissen nie, ob oder wann Sie diese zusätzlichen Informationen benötigen.
Technische Fehler beim Datenbankdesign
#4 Keine Namenskonvention verwenden
Sie wissen nie genau, wie lange ein Projekt dauern wird und ob mehr als eine Person am Datenmodell arbeiten wird. Es gibt einen Punkt, an dem Sie dem Datenmodell wirklich nahe sind, aber noch nicht damit begonnen haben, es zu zeichnen. In diesem Fall sollten Sie entscheiden, wie Sie Objekte in Ihrem Modell, in der Datenbank und in der allgemeinen Anwendung benennen. Vor dem Modellieren sollten Sie Folgendes wissen:
- Sind Tabellennamen Singular oder Plural?
- Werden wir Tabellen anhand von Namen gruppieren? (Z. B. enthalten alle kundenbezogenen Tabellen „client_“, alle aufgabenbezogenen Tabellen „task_“ usw.)
- Werden wir Groß- und Kleinbuchstaben oder nur Kleinbuchstaben verwenden?
- Welchen Namen werden wir für die ID-Spalten verwenden? (Höchstwahrscheinlich wird es „id“ sein.)
- Wie werden wir Fremdschlüssel benennen? (Höchstwahrscheinlich „id_“ und der Name der referenzierten Tabelle.)
Vergleichen Sie einen Teil eines Modells, der keine Namenskonventionen verwendet, mit demselben Teil, der Namenskonventionen verwendet, wie unten gezeigt:
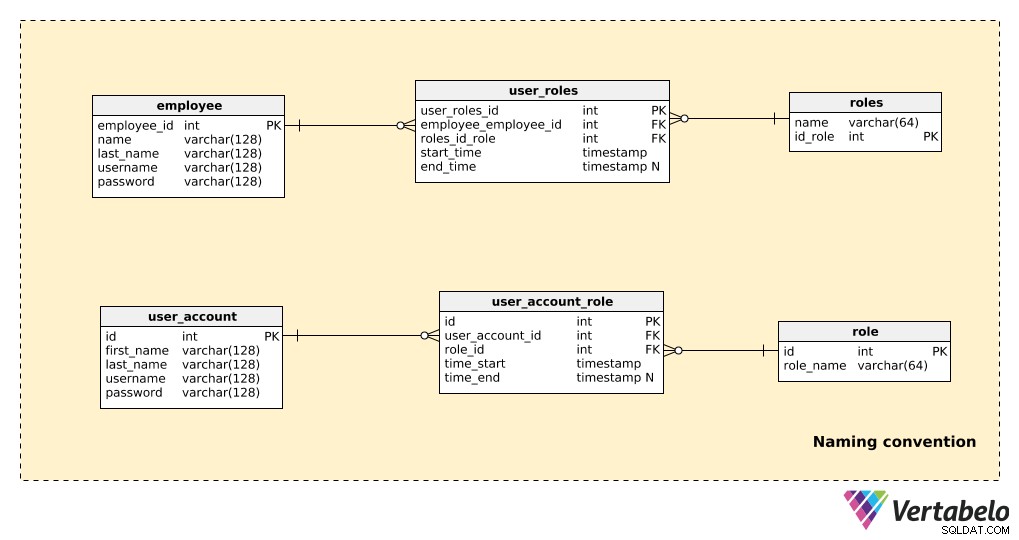
Hier gibt es nur wenige Tabellen, aber es ist immer noch ziemlich offensichtlich, welches Modell einfacher zu lesen ist. Beachten Sie Folgendes:
- Beide Modelle „funktionieren“, also technisch gibt es keine Probleme.
- Im Beispiel der Nicht-Namenskonvention (die oberen drei Tabellen) gibt es ein paar Dinge, die die Lesbarkeit erheblich beeinträchtigen:die Verwendung von Singular- und Pluralformen in den Tabellennamen; nicht standardisierte Primärschlüsselnamen (
employees_id,id_role); und Attribute in verschiedenen Tabellen haben denselben Namen (z “ und die „Rollen” Tabellen).
Stellen Sie sich nun das Chaos vor, das wir anrichten würden, wenn unser Modell Hunderte von Tabellen enthalten würde. Vielleicht könnten wir mit einem solchen Modell arbeiten (wenn wir es selbst erstellt hätten), aber wir würden jemandem sehr unglücklich machen, wenn er nach uns daran arbeiten müsste.
Um zukünftige Probleme mit Namen zu vermeiden, verwenden Sie keine SQL-reservierten Wörter, Sonderzeichen oder Leerzeichen darin.
Bevor Sie also mit dem Erstellen von Namen beginnen, erstellen Sie ein einfaches Dokument (vielleicht nur ein paar Seiten lang), das die von Ihnen verwendete Namenskonvention beschreibt. Dies erhöht die Lesbarkeit des gesamten Modells und vereinfacht die zukünftige Arbeit.
Weitere Informationen zu Namenskonventionen finden Sie in diesen beiden Artikeln:
- Namenskonventionen in der Datenbankmodellierung
- Ein nüchterner logischer Blick auf die Namenskonventionen von SQL Server
#5 Normalisierungsprobleme
Die Normalisierung ist ein wesentlicher Bestandteil des Datenbankdesigns. Jede Datenbank sollte auf mindestens 3NF normalisiert werden (Primärschlüssel sind definiert, Spalten sind atomar und es gibt keine sich wiederholenden Gruppen, partiellen Abhängigkeiten oder transitiven Abhängigkeiten). Dadurch wird die Datenduplizierung reduziert und die referenzielle Integrität sichergestellt.
Weitere Informationen zur Normalisierung finden Sie in diesem Artikel. Kurz gesagt, wenn wir über das relationale Datenbankmodell sprechen, sprechen wir über die normalisierte Datenbank. Wenn eine Datenbank nicht normalisiert ist, werden wir auf eine Reihe von Problemen im Zusammenhang mit der Datenintegrität stoßen.
In einigen Fällen möchten wir möglicherweise unsere Datenbank denormalisieren. Wenn Sie dies tun, haben Sie einen wirklich guten Grund. Hier können Sie mehr über die Denormalisierung von Datenbanken lesen.
#6 Verwenden des Entity-Attribute-Value (EAV)-Modells
EAV steht für Entity-Attribute-Value. Diese Struktur kann verwendet werden, um zusätzliche Daten über alles in unserem Modell zu speichern. Schauen wir uns ein Beispiel an.
Angenommen, wir möchten einige zusätzliche Kundenattribute speichern. Der „Kunde “-Tabelle ist unsere Entität, das „attribute “-Tabelle ist offensichtlich unser Attribut, und der „attribute_value ” Tabelle enthält den Wert dieses Attributs für diesen Kunden.
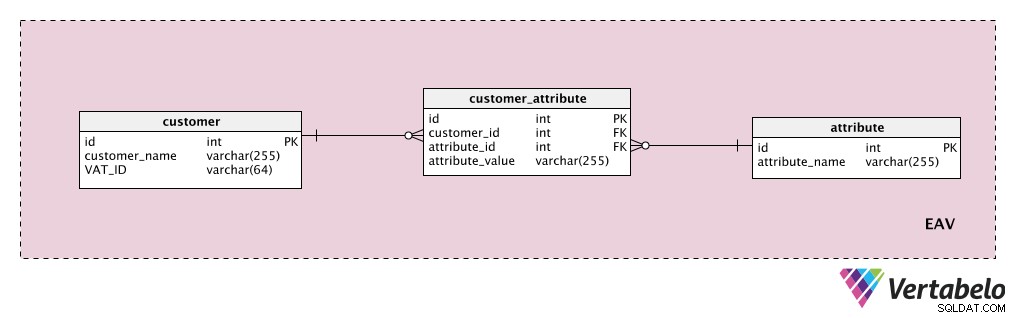
Zuerst fügen wir ein Wörterbuch mit einer Liste aller möglichen Eigenschaften hinzu, die wir einem Kunden zuweisen könnten. Dies ist das „Attribut " Tisch. Es könnte Eigenschaften wie „Kundenwert“, „Kontaktdaten“, „Zusatzinformationen“ etc. enthalten. Das „customer_attribute ”-Tabelle enthält eine Liste aller Attribute mit Werten für jeden Kunden. Für jeden Kunden haben wir nur Datensätze für die Attribute, die er hat, und wir speichern den „attribute_value ” für dieses Attribut.
Das könnte wirklich toll aussehen. Es würde uns ermöglichen, neue Eigenschaften einfach hinzuzufügen (weil wir sie als Werte in „customer_attribute hinzufügen " Tisch). Somit würden wir vermeiden, Änderungen in der Datenbank vorzunehmen. Fast zu schön um wahr zu sein.
Und es ist zu gut. Während das Modell die Daten speichert, die wir benötigen, ist die Arbeit mit solchen Daten viel komplizierter. Und das umfasst fast alles, vom Schreiben einfacher SELECT-Abfragen über das Abrufen aller kundenbezogenen Werte bis hin zum Einfügen, Aktualisieren oder Löschen von Werten.
Kurz gesagt, wir sollten die EAV-Struktur vermeiden. Wenn Sie es verwenden müssen, verwenden Sie es nur, wenn Sie sich zu 100 % sicher sind, dass es wirklich benötigt wird.
#7 Verwendung einer GUID/UUID als Primärschlüssel
Eine GUID (Globally Unique Identifier) ist eine 128-Bit-Zahl, die gemäß den in RFC 4122 definierten Regeln generiert wird. Sie werden manchmal auch als UUIDs (Universally Unique Identifiers) bezeichnet. Der Hauptvorteil einer GUID ist, dass sie einzigartig ist; Die Wahrscheinlichkeit, dass Sie dieselbe GUID zweimal treffen, ist wirklich unwahrscheinlich. Daher scheinen GUIDs ein großartiger Kandidat für die Primärschlüsselspalte zu sein. Aber das ist nicht der Fall.
Eine allgemeine Regel für Primärschlüssel lautet, dass wir eine Integer-Spalte verwenden, bei der die Eigenschaft autoincrement auf „yes“ gesetzt ist. Dadurch werden Daten in sequenzieller Reihenfolge zum Primärschlüssel hinzugefügt und eine optimale Leistung bereitgestellt. Ohne einen sequentiellen Schlüssel oder einen Zeitstempel gibt es keine Möglichkeit zu wissen, welche Daten zuerst eingefügt wurden. Dieses Problem tritt auch auf, wenn wir EINZIGARTIGE reale Werte verwenden (z. B. eine Umsatzsteuer-ID). Obwohl sie EINZIGARTIGE Werte enthalten, sind sie keine guten Primärschlüssel. Verwenden Sie sie stattdessen als alternative Schlüssel.
Eine zusätzliche Anmerkung: Ich ziehe es vor, einspaltige automatisch generierte Integer-Attribute als Primärschlüssel zu verwenden. Es ist definitiv die beste Praxis. Ich empfehle Ihnen, zusammengesetzte Primärschlüssel zu vermeiden.
#8 Unzureichende Indexierung
Indizes sind ein sehr wichtiger Teil der Arbeit mit Datenbanken, aber eine gründliche Erörterung davon würde den Rahmen dieses Artikels sprengen. Glücklicherweise haben wir bereits einige Artikel zu Indizes, in denen Sie mehr erfahren können:- Was ist ein Datenbankindex?
- Alles über Indizes:Die Grundlagen
- Alles über Indizes Teil 2:Struktur und Leistung von MySQL-Indizes
Die Kurzversion ist, dass ich empfehle, dass Sie einen Index hinzufügen, wo immer Sie erwarten, dass er benötigt wird. Sie können sie auch hinzufügen, nachdem die Datenbank in Produktion ist, wenn Sie sehen, dass das Hinzufügen von Indizes an einer bestimmten Stelle die Leistung verbessert.
#9 Redundante Daten
Redundante Daten sollten generell in jedem Modell vermieden werden. Es nimmt nicht nur zusätzlichen Speicherplatz ein, sondern erhöht auch die Wahrscheinlichkeit von Datenintegritätsproblemen erheblich. Wenn etwas redundant sein muss, sollten wir darauf achten, dass die Originaldaten und die „Kopie“ immer in einem konsistenten Zustand sind. Tatsächlich gibt es Situationen, in denen redundante Daten wünschenswert sind:
- In einigen Fällen müssen wir einer bestimmten Aktion Priorität zuweisen – und um dies zu erreichen, müssen wir komplexe Berechnungen durchführen. Diese Berechnungen können viele Tabellen verwenden und viele Ressourcen verbrauchen. In solchen Fällen wäre es ratsam, diese Berechnungen außerhalb der Arbeitszeiten durchzuführen (wodurch Leistungsprobleme während der Arbeitszeit vermieden werden). Auf diese Weise könnten wir diesen berechneten Wert speichern und später verwenden, ohne ihn neu berechnen zu müssen. Natürlich ist der Wert überflüssig; Was wir jedoch an Leistung gewinnen, ist deutlich mehr als das, was wir verlieren (etwas Festplattenspeicher).
- Wir können auch einen kleinen Satz von Berichtsdaten in der Datenbank speichern. Am Ende des Tages speichern wir beispielsweise die Anzahl der Anrufe, die wir an diesem Tag getätigt haben, die Anzahl der erfolgreichen Verkäufe usw. Berichtsdaten sollten nur dann auf diese Weise gespeichert werden, wenn wir sie häufig verwenden müssen. Wir werden wieder etwas Festplattenspeicher verlieren, aber wir vermeiden es, Daten neu zu berechnen oder eine Verbindung zur Berichtsdatenbank herzustellen (falls vorhanden).
In den meisten Fällen sollten wir aus folgenden Gründen keine redundanten Daten verwenden:
- Das mehrmalige Speichern derselben Daten in der Datenbank kann die Datenintegrität beeinträchtigen. Wenn Sie den Namen eines Kunden an zwei verschiedenen Orten speichern, sollten Sie alle Änderungen (Einfügen/Aktualisieren/Löschen) an beiden Orten gleichzeitig vornehmen. Dies verkompliziert auch den Code, den Sie benötigen, selbst für die einfachsten Operationen.
- Obwohl wir einige aggregierte Zahlen in unserer Betriebsdatenbank speichern könnten, sollten wir dies nur tun, wenn es wirklich nötig ist. Eine operative Datenbank ist nicht dazu gedacht, Berichtsdaten zu speichern, und das Mischen dieser beiden ist im Allgemeinen eine schlechte Praxis. Jeder, der Berichte erstellt, muss dieselben Ressourcen verwenden wie Benutzer, die an operativen Aufgaben arbeiten; Berichtsabfragen sind in der Regel komplexer und können die Leistung beeinträchtigen. Daher sollten Sie Ihre Betriebsdatenbank und Ihre Berichtsdatenbank trennen.
Jetzt sind Sie an der Reihe, sich zu wiegen
Ich hoffe, dass Ihnen die Lektüre dieses Artikels einige neue Erkenntnisse gebracht hat und Sie dazu ermutigt, Best Practices für die Datenmodellierung zu befolgen. Sie sparen Ihnen etwas Zeit!
Haben Sie eines der in diesem Artikel erwähnten Probleme erlebt? Glaubst du, wir haben etwas Wichtiges verpasst? Oder denken Sie, wir sollten etwas von unserer Liste streichen? Bitte teilen Sie uns dies in den Kommentaren unten mit.