Einer der häufigsten Begriffe, der in Diskussionen über die Leistungsoptimierung von SQL Server auftaucht, ist Wartestatistiken . Dies reicht weit zurück, sogar vor diesem Microsoft-Dokument von 2006, „SQL Server 2005 Waits and Queues.“
Wartezeiten sind absolut nicht alles, und diese Methode ist nicht die einzige Möglichkeit, eine Instanz zu optimieren, ganz zu schweigen von einer einzelnen Abfrage. Tatsächlich sind Wartezeiten oft nutzlos, wenn Sie nur die Abfrage haben, die sie erlitten hat, und keinen umgebenden Kontext, besonders lange danach. Dies liegt daran, dass das, worauf eine Abfrage wartet, häufig nicht die Schuld dieser Abfrage ist . Wie bei allem gibt es Ausnahmen, aber wenn Sie ein Tool oder Skript nur auswählen, weil es diese sehr spezifische Funktionalität bietet, denke ich, dass Sie sich selbst einen schlechten Dienst erweisen. Ich neige dazu, einem Ratschlag zu folgen, den Paul Randal mir vor einiger Zeit gegeben hat:
…im Allgemeinen empfehle ich, mit ganzen Instanzwartezeiten zu beginnen. Ich würde nie anfangen Fehlerbehebung durch Betrachten einzelner Abfragewartezeiten.
Gelegentlich, ja, möchten Sie vielleicht tiefer in eine einzelne Abfrage eintauchen und sehen, worauf sie wartet; Tatsächlich hat Microsoft kürzlich Wartestatistiken auf Abfrageebene zu Showplan hinzugefügt, um bei dieser Analyse zu helfen. Aber diese Zahlen helfen Ihnen normalerweise nicht dabei, die Leistung Ihrer Instanz als Ganzes zu optimieren, es sei denn, sie helfen dabei, auf etwas hinzuweisen, das sich zufällig auch auf Ihre gesamte Arbeitslast auswirkt. Wenn Sie eine Abfrage von gestern sehen, die 5 Minuten lang lief, und feststellen, dass ihr Wartetyp LCK_M_S war , was willst du jetzt dagegen tun? Wie wollen Sie herausfinden, was die Abfrage tatsächlich blockiert und diesen Wartetyp verursacht hat? Es könnte durch eine Transaktion verursacht worden sein, die aus einem anderen Grund nicht festgeschrieben wurde, aber Sie können das nicht sehen, wenn Sie den Zustand des gesamten Systems nicht sehen können und sich nur auf einzelne Abfragen und die Wartezeiten konzentrieren, die sie erfahren haben.
Jason Hall (@SQLSaurus) erwähnte nebenbei etwas, das auch für mich interessant war. Er sagte, wenn Wartestatistiken auf Abfrageebene ein so wichtiger Teil der Optimierungsbemühungen gewesen wären, wäre diese Methodik von Anfang an in den Abfragespeicher integriert worden. Es wurde kürzlich hinzugefügt (in SQL Server 2017). Aber Sie erhalten immer noch keine Wartestatistiken pro Ausführung; Sie erhalten Durchschnittswerte über die Zeit, wie die Abfragestatistiken und Verfahrensstatistiken, die Sie in DMVs sehen. Daher können plötzliche Anomalien auf der Grundlage anderer Metriken erkennbar sein, die pro Abfrageausführung erfasst werden, aber nicht auf der Grundlage der Durchschnittswerte der Wartezeiten, die über alle gezogen werden Hinrichtungen. Sie können den Bereich, über den Wartezeiten aggregiert werden, anpassen, aber auf stark ausgelasteten Systemen ist dies möglicherweise immer noch nicht granular genug, um das zu tun, was Sie Ihrer Meinung nach für Sie tun werden.
Der Zweck dieses Beitrags ist es, einige der häufigsten Arten von Wartezeiten zu diskutieren, die wir in unserem Kundenstamm sehen, und welche Art von Maßnahmen Sie ergreifen können (und nicht sollten), wenn sie auftreten. Wir haben eine Datenbank mit anonymen Wartestatistiken, die wir seit geraumer Zeit von unseren Cloud Sync-Kunden sammeln, und seit Mai 2017 zeigen wir allen, wie diese in der SQLskills Waits Library aussehen.
Paul spricht über den Grund hinter der Bibliothek und auch über unsere Integration mit diesem kostenlosen Service. Grundsätzlich schlagen Sie einen Wartetyp nach, den Sie erleben oder auf den Sie neugierig sind, und er erklärt, was er bedeutet und was Sie dagegen tun können. Wir ergänzen diese qualitativen Informationen mit einem Diagramm, das zeigt, wie weit verbreitet die aktuelle Wartezeit in unserer Benutzerbasis ist, und vergleichen dies mit allen anderen Wartezeittypen, die wir sehen, sodass Sie schnell erkennen können, ob Sie es mit einem gemeinsamen Wartetyp oder etwas mehr zu tun haben exotisch. (Denken Sie daran, dass SQL Sentry nicht die gutartigen, Hintergrund- und Warteschlangenwartezeiten enthält, die zu Lärm führen und die die meisten Skripts da draußen herausfiltern, wie WAITFOR oder LAZYWRITER_SLEEP – dies sind einfach keine Ursachen für Leistungsprobleme.)
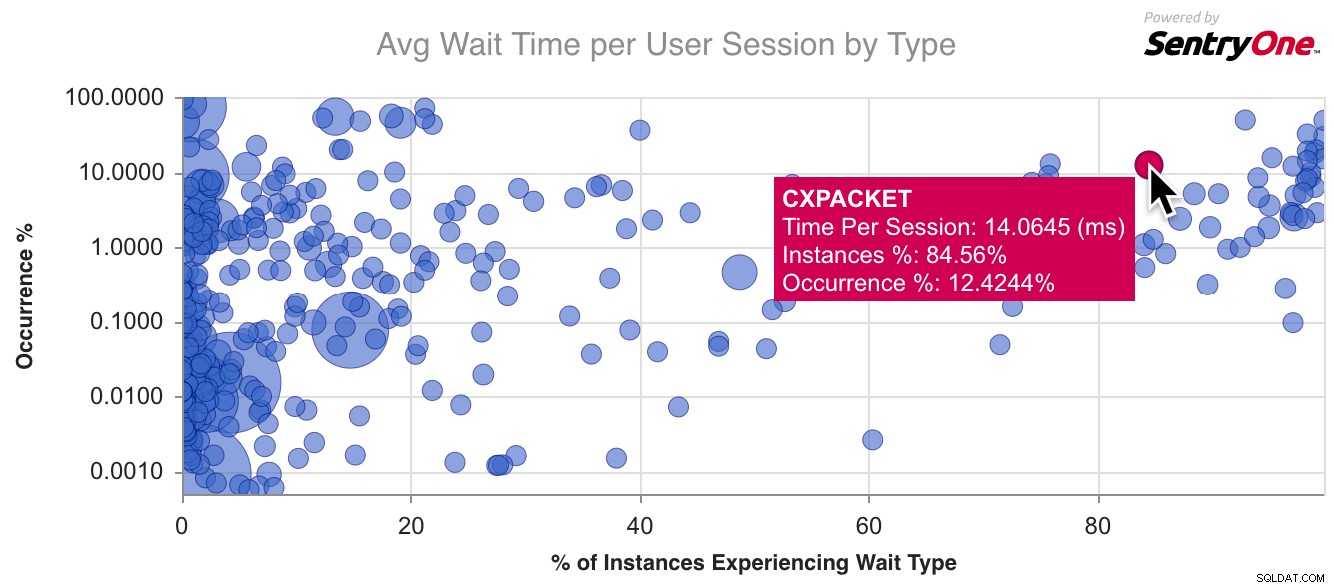
Hier ist ein Beispieldiagramm für CXPACKET , der häufigste Wartetyp da draußen:
Ich fing an, ein wenig weiter zu gehen, indem ich einige der häufigeren Wartetypen abbildete und einige der Eigenschaften notierte, die sie gemeinsam hatten. Übersetzt in Fragen, die ein Tuner möglicherweise zu einem Wartetyp hat, den er erlebt:
- Kann der Wartetyp auf Abfrageebene gelöst werden?
- Wirkt sich das Hauptsymptom des Wartens wahrscheinlich auf andere Abfragen aus?
- Benötigen Sie wahrscheinlich weitere Informationen außerhalb des Kontexts einer einzelnen Abfrage und der aufgetretenen Wartetypen, um das Problem zu "lösen"?
Als ich anfing, diesen Beitrag zu schreiben, war mein Ziel, die häufigsten Wartetypen zusammenzufassen und dann damit zu beginnen, Notizen über sie zu machen, die sich auf die oben genannten Fragen beziehen. Jason holte die gebräuchlichsten aus der Bibliothek, und dann zeichnete ich ein paar Hühnerkratzer auf ein Whiteboard, das ich später ein wenig aufräumte. Diese anfängliche Recherche führte zu einem Vortrag, den Jason auf der letzten TechOutbound SQL Cruise in Alaska hielt. Es ist mir irgendwie peinlich, dass er einen Vortrag zusammengestellt hat, Monate bevor ich diesen Beitrag beenden konnte, also machen wir einfach weiter. Hier sind die Top-Wartezeiten, die wir sehen (die weitgehend mit Pauls Umfrage aus dem Jahr 2014 übereinstimmen), meine Antworten auf die obigen Fragen und einige Kommentare dazu:
Um mit den Links in der Tabelle unten zu interagieren, besuchen Sie diese Seite bitte auf einem größeren Bildschirm.
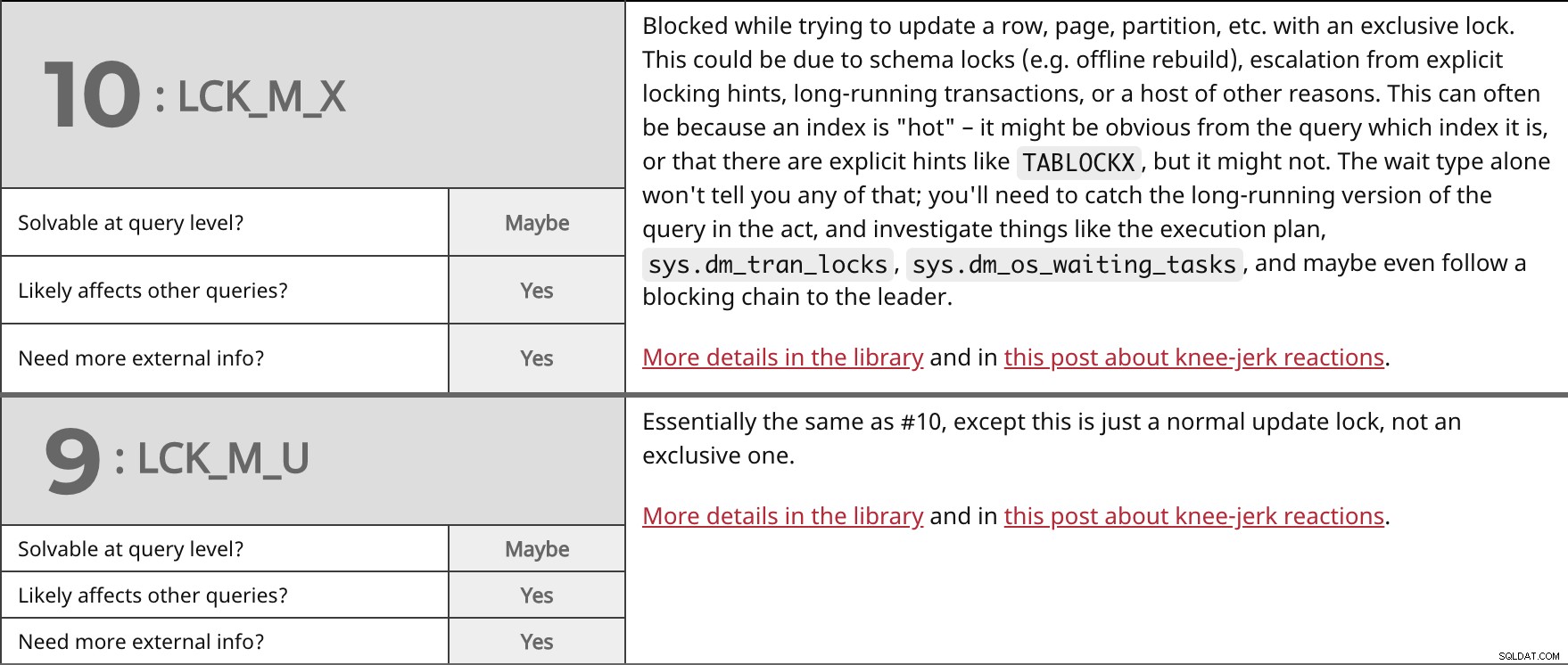
Blockiert beim Versuch, eine Zeile, Seite, Partition usw. mit einer exklusiven Sperre zu aktualisieren. Dies kann auf Schemasperren (z. B. Offline-Neuaufbau), eine Eskalation durch explizite Sperrhinweise, lang andauernde Transaktionen oder eine Vielzahl anderer Gründe zurückzuführen sein. Dies kann oft daran liegen, dass ein Index "heiß" ist – es kann aus der Abfrage ersichtlich sein, um welchen Index es sich handelt, oder dass es explizite Hinweise wie TABLOCKX gibt , aber vielleicht nicht. Der Wartetyp allein wird Ihnen nichts davon sagen; Sie müssen die lange laufende Version der Abfrage auf frischer Tat erwischen und Dinge wie den Ausführungsplan sys.dm_tran_locks untersuchen , sys.dm_os_waiting_tasks , und vielleicht sogar einer Blockierungskette zum Anführer folgen. Weitere Details in der Bibliothek und in diesem Beitrag über reflexartige Reaktionen. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Ja | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
|
Im Wesentlichen dasselbe wie #10, außer dass dies nur eine normale Update-Sperre ist, keine exklusive. Weitere Details in der Bibliothek und in diesem Beitrag über reflexartige Reaktionen. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Ja | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
|
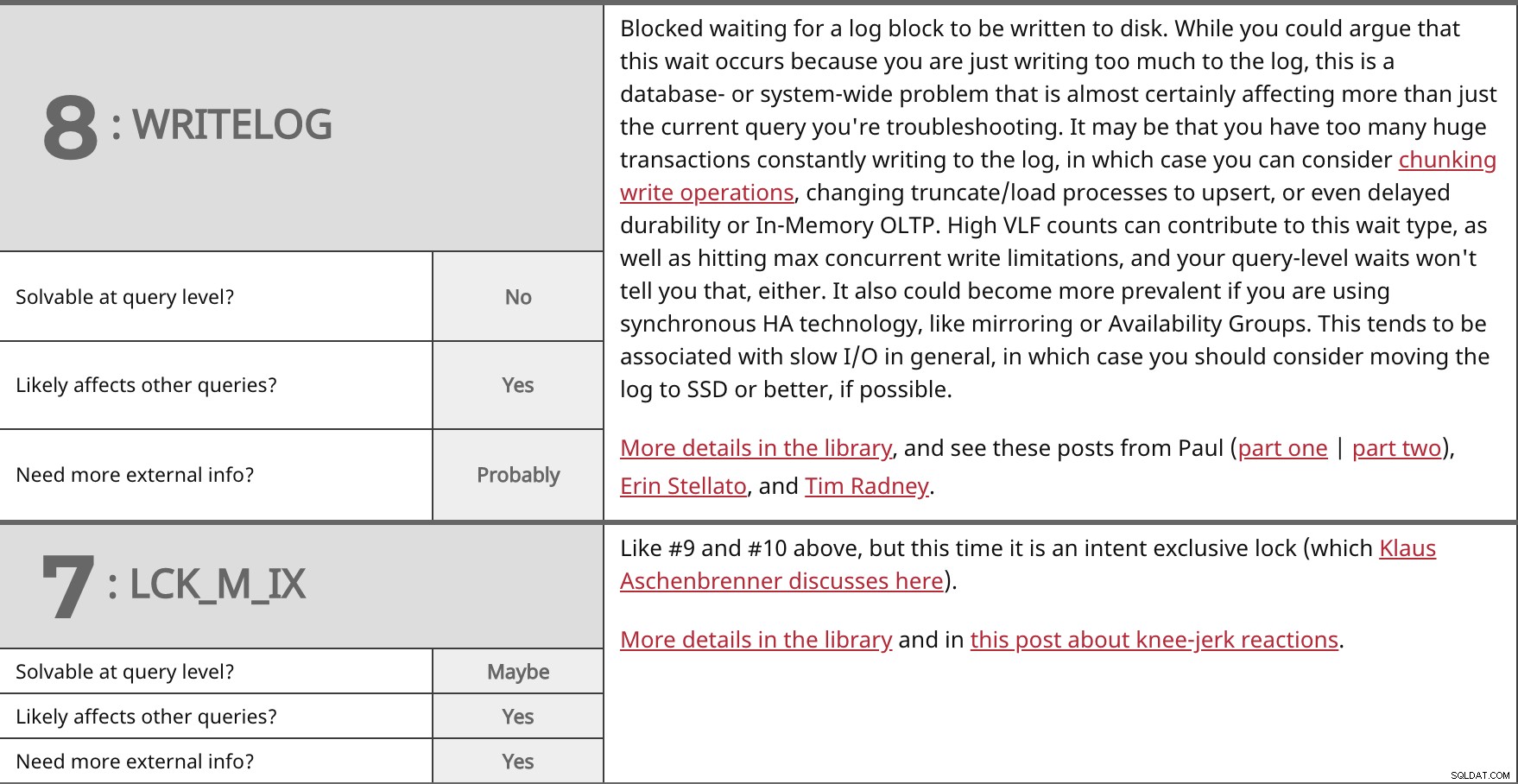
Blockiertes Warten darauf, dass ein Protokollblock auf die Festplatte geschrieben wird. Während Sie argumentieren könnten, dass diese Wartezeit auftritt, weil Sie einfach zu viel in das Protokoll schreiben, ist dies ein datenbank- oder systemweites Problem, das mit ziemlicher Sicherheit mehr als nur die aktuelle Abfrage betrifft, die Sie beheben. Es kann sein, dass Sie zu viele große Transaktionen haben, die ständig in das Protokoll schreiben. In diesem Fall können Sie in Betracht ziehen, Schreibvorgänge aufzuteilen, Kürzungs-/Ladeprozesse in Upsert umzuwandeln oder sogar Dauerhaftigkeit oder In-Memory-OLTP zu verzögern. Hohe VLF-Zählungen können zu diesem Wartetyp beitragen und die maximalen gleichzeitigen Schreibbeschränkungen erreichen, und Ihre Wartezeiten auf Abfrageebene werden Ihnen das auch nicht sagen. Es könnte auch häufiger auftreten, wenn Sie synchrone HA-Technologie wie Spiegelung oder Verfügbarkeitsgruppen verwenden. Dies ist im Allgemeinen mit langsamer E/A verbunden, in diesem Fall sollten Sie erwägen, das Protokoll nach Möglichkeit auf SSD oder besser zu verschieben. Weitere Details in der Bibliothek und diese Posts von Paul (Teil eins | Teil zwei), Erin Stellato und Tim Radney. | ||
| Auf Abfrageebene lösbar? | Nein | |
| Ja | ||
| Benötigen Sie weitere externe Informationen? | Wahrscheinlich | |
|
Wie Nr. 9 und Nr. 10 oben, aber diesmal ist es eine absichtliche exklusive Sperre (die Klaus Aschenbrenner hier bespricht). Weitere Details in der Bibliothek und in diesem Beitrag über reflexartige Reaktionen. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Ja | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
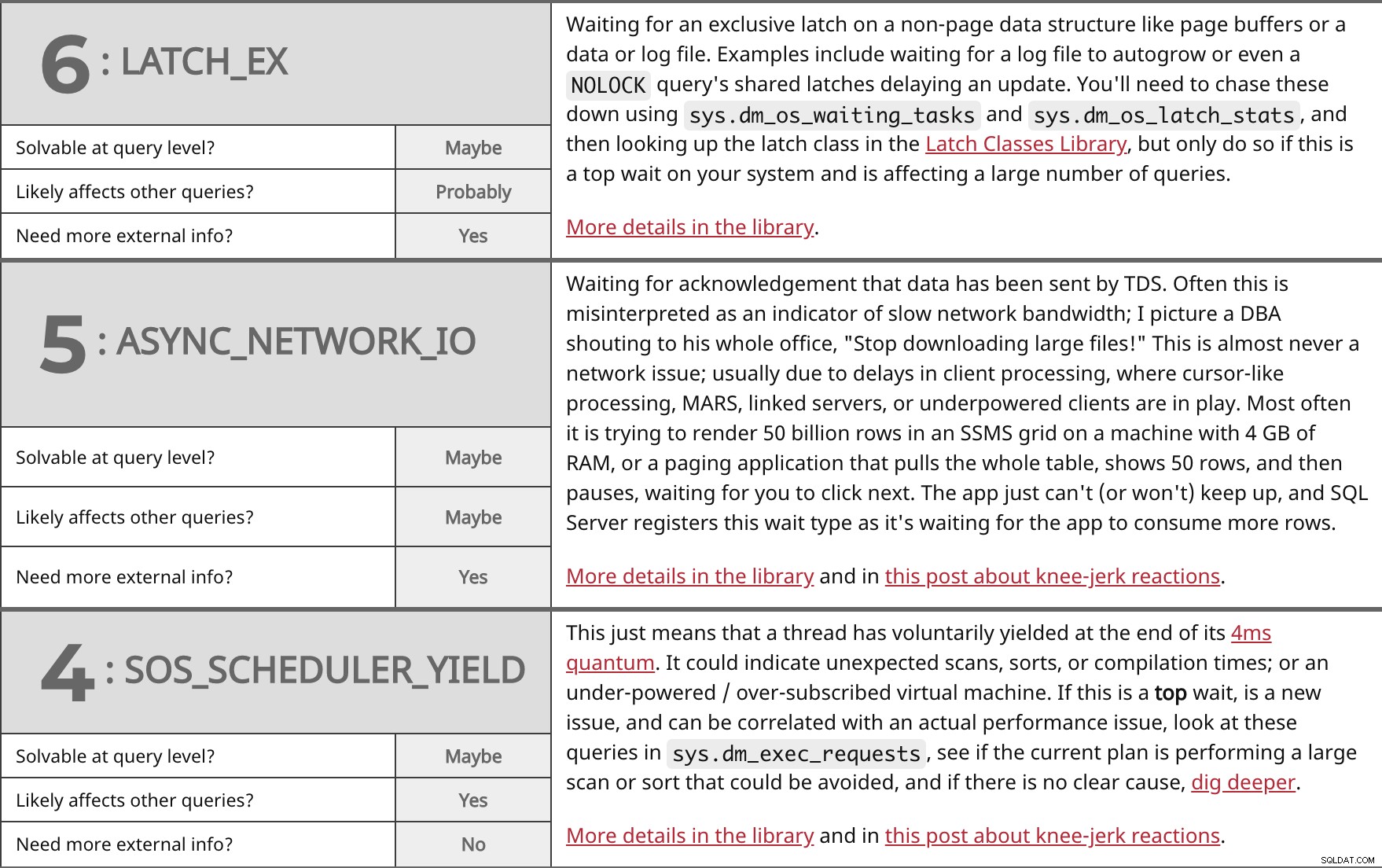
Warten auf einen exklusiven Latch für eine Nicht-Seiten-Datenstruktur wie Seitenpuffer oder eine Daten- oder Protokolldatei. Beispiele hierfür sind das Warten auf die automatische Vergrößerung einer Protokolldatei oder sogar ein NOLOCK gemeinsame Latches der Abfrage, die eine Aktualisierung verzögern. Sie müssen diese mithilfe von sys.dm_os_waiting_tasks aufspüren und sys.dm_os_latch_stats , und suchen Sie dann die Latch-Klasse in der Latch-Klassenbibliothek nach, aber tun Sie dies nur, wenn dies eine Top-Wartezeit auf Ihrem System ist und eine große Anzahl von Abfragen betrifft. Weitere Details in der Bibliothek. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Wahrscheinlich | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
|
Warten auf Bestätigung, dass Daten von TDS gesendet wurden. Oft wird dies als Indikator für langsame Netzwerkbandbreite fehlinterpretiert; Ich stelle mir einen DBA vor, der in sein ganzes Büro ruft:„Hören Sie auf, große Dateien herunterzuladen!“ Dies ist fast nie ein Netzwerkproblem; normalerweise aufgrund von Verzögerungen bei der Client-Verarbeitung, wo Cursor-ähnliche Verarbeitung, MARS, Verbindungsserver oder Clients mit geringer Leistung im Spiel sind. Meistens wird versucht, 50 Milliarden Zeilen in einem SSMS-Raster auf einem Computer mit 4 GB RAM oder einer Paging-Anwendung zu rendern, die die gesamte Tabelle abruft, 50 Zeilen anzeigt und dann anhält und darauf wartet, dass Sie auf „Weiter“ klicken. Die App kann (oder will) einfach nicht mithalten, und SQL Server registriert diesen Wartetyp, da er darauf wartet, dass die App mehr Zeilen verbraucht. Weitere Details in der Bibliothek und in diesem Beitrag über reflexartige Reaktionen. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Vielleicht | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
Das bedeutet nur, dass ein Thread am Ende seines 4ms-Quantums freiwillig nachgegeben hat. Es könnte auf unerwartete Scans, Sortierungen oder Kompilierungszeiten hinweisen; oder eine zu schwache/überbuchte virtuelle Maschine. Wenn das ein Top ist warten, ist ein neues Problem und kann mit einem tatsächlichen Leistungsproblem korreliert werden, sehen Sie sich diese Abfragen in sys.dm_exec_requests an , prüfen Sie, ob der aktuelle Plan einen umfangreichen Scan oder Sortiervorgang durchführt, der vermieden werden könnte, und gehen Sie tiefer, wenn es keine eindeutige Ursache gibt. Weitere Details in der Bibliothek und in diesem Beitrag über reflexartige Reaktionen. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Ja | ||
| Benötigen Sie weitere externe Informationen? | Nein | |
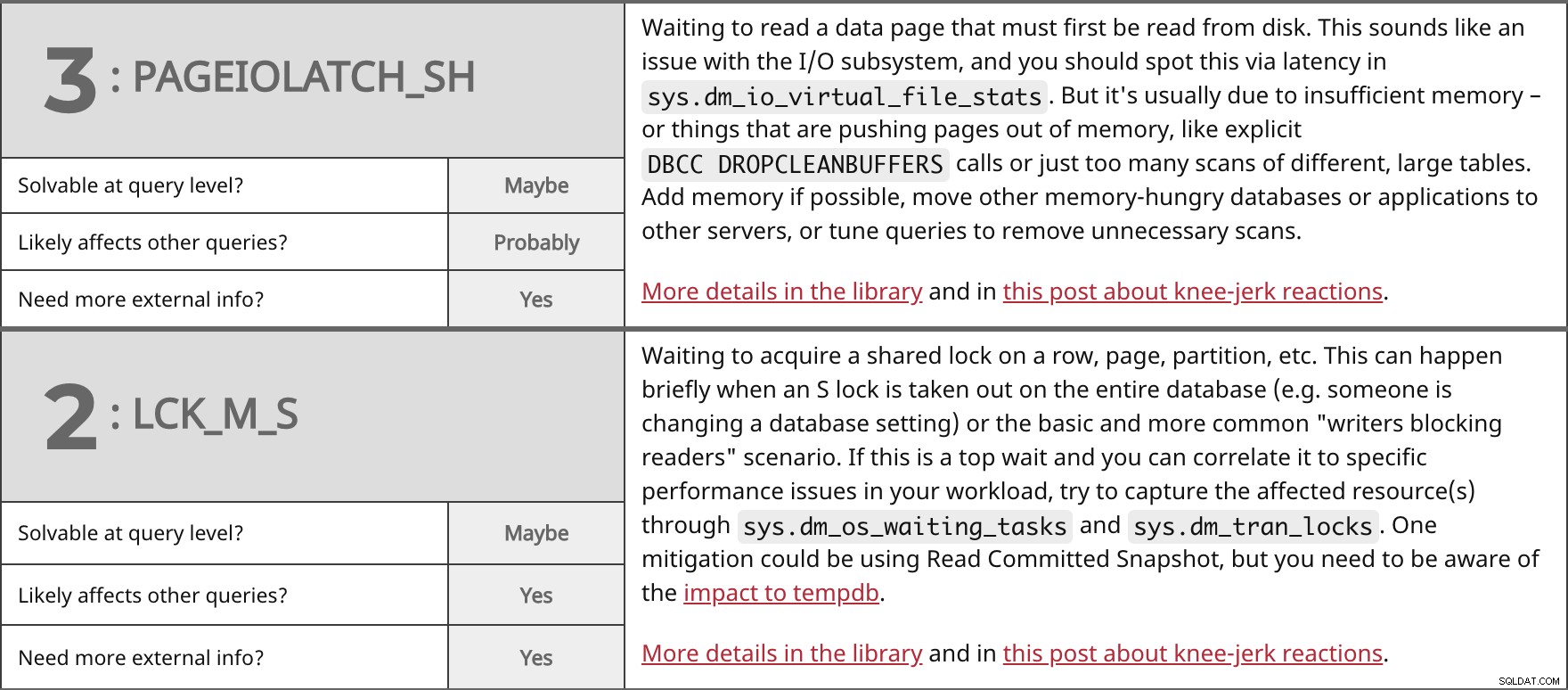
Warten auf das Lesen einer Datenseite, die zuerst von der Festplatte gelesen werden muss. Das klingt nach einem Problem mit dem E/A-Subsystem, und Sie sollten dies anhand der Latenz in sys.dm_io_virtual_file_stats erkennen . Aber es liegt normalerweise an unzureichendem Speicher – oder an Dingen, die Seiten aus dem Speicher drängen, wie explizite DBCC DROPCLEANBUFFERS Anrufe oder einfach zu viele Scans verschiedener, großer Tabellen. Fügen Sie nach Möglichkeit Speicher hinzu, verschieben Sie andere speicherhungrige Datenbanken oder Anwendungen auf andere Server oder optimieren Sie Abfragen, um unnötige Scans zu entfernen. Weitere Details in der Bibliothek und in diesem Beitrag über reflexartige Reaktionen. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Wahrscheinlich | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
Warten auf den Erwerb einer gemeinsamen Sperre für eine Zeile, Seite, Partition usw. Dies kann kurzzeitig passieren, wenn eine S-Sperre für die gesamte Datenbank aufgehoben wird (z. B. jemand ändert eine Datenbankeinstellung) oder das grundlegende und häufigere Szenario „Schreiber blockieren Leser“. Wenn dies eine Top-Wartezeit ist und Sie sie mit bestimmten Leistungsproblemen in Ihrer Arbeitslast in Beziehung setzen können, versuchen Sie, die betroffene(n) Ressource(n) über sys.dm_os_waiting_tasks zu erfassen und sys.dm_tran_locks . Eine Abhilfe könnte die Verwendung von Read Committed Snapshot sein, aber Sie müssen sich der Auswirkungen auf tempdb bewusst sein. Weitere Details in der Bibliothek und in diesem Beitrag über reflexartige Reaktionen. | ||
| Auf Abfrageebene lösbar? | Vielleicht | |
| Ja | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
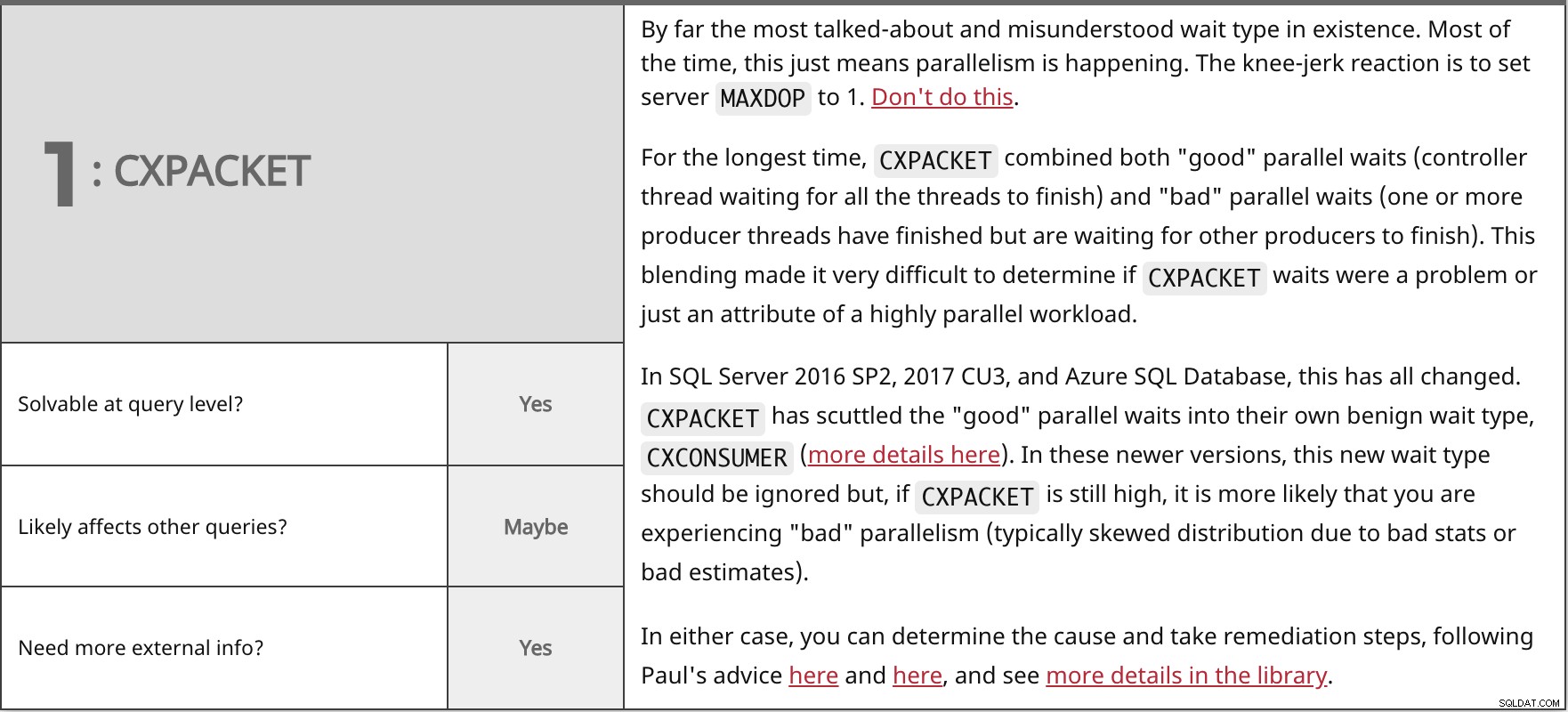
Bei weitem der am meisten diskutierte und missverstandene Wartetyp, den es gibt. Meistens bedeutet dies nur, dass Parallelität stattfindet. Die reflexartige Reaktion besteht darin, den Server MAXDOP zu setzen zu 1. Tun Sie dies nicht.
Für die längste Zeit
In SQL Server 2016 SP2, 2017 CU3 und Azure SQL Database hat sich das alles geändert. In beiden Fällen können Sie die Ursache ermitteln und Abhilfemaßnahmen ergreifen, indem Sie Pauls Rat hier und hier befolgen, und weitere Details in der Bibliothek einsehen. | ||
| Auf Abfrageebene lösbar? | Ja | |
| Vielleicht | ||
| Benötigen Sie weitere externe Informationen? | Ja | |
Zusammenfassung
In den meisten dieser Fälle ist es besser, Wartezeiten auf Instanzebene zu betrachten und sich nur auf Abfrageebene zu konzentrieren, wenn Sie bestimmte Abfragen beheben, die unabhängig vom Wartetyp Leistungsprobleme aufweisen. Dies sind Dinge, die aus anderen Gründen auftauchen, wie z. B. lange Dauer, hohe CPU-Leistung oder hohe E/A, und nicht durch einfachere Dinge erklärt werden können (z. B. ein Clustered-Index-Scan, wenn Sie eine Suche erwartet haben).
Jagen Sie auch auf Instanzebene nicht jedem Wait hinterher, der zum Top Wait auf Ihrem System wird – Sie werden es IMMER tun Haben Sie ein Top-Warte, und Sie werden nie aufhören können, es zu jagen. Stellen Sie sicher, dass Sie harmlose Wartezeiten ignorieren (Paul führt eine Liste) und sich nur Gedanken über Wartezeiten machen, die Sie mit einem tatsächlichen Leistungsproblem in Verbindung bringen können, das Sie erleben. Wenn CXPACKET Wartezeiten sind hoch, na und? Gibt es noch andere Symptome, abgesehen davon, dass diese Zahl "hoch" ist oder ganz oben auf der Liste steht?
Es kommt in erster Linie darauf an, warum Sie die Fehlerbehebung durchführen. Beschwert sich ein einzelner Benutzer über eine einzelne Instanz einer betrügerischen Abfrage? Ist Ihr Server auf den Knien? Etwas dazwischen? Im ersten Fall kann es natürlich nützlich sein, zu wissen, warum eine Abfrage langsam ist, aber es ist ziemlich teuer, alle Wartezeiten zu verfolgen (egal, auf unbestimmte Zeit aufzubewahren), den ganzen Tag, jeden Tag, wenn Sie die Gelegenheit dazu haben später wiederkommen und sie überprüfen möchten. Wenn es sich um ein allgegenwärtiges Problem handelt, das auf diese Abfrage isoliert ist, sollten Sie in der Lage sein, festzustellen, was diese Abfrage langsam macht, indem Sie sie erneut ausführen und den Ausführungsplan, die Kompilierungszeit und andere Laufzeitmetriken erfassen. Wenn es sich um eine einmalige Sache handelte, die letzten Dienstag passiert ist, können Sie das Problem möglicherweise nicht ohne mehr Kontext lösen, unabhängig davon, ob Sie die Wartezeiten für diese einzelne Instanz der Abfrage haben oder nicht. Vielleicht gab es eine Blockierung, aber Sie werden nicht wissen, wodurch, oder vielleicht gab es eine E/A-Spitze, aber Sie müssen dieses Problem separat aufspüren. Der Wait-Typ allein liefert normalerweise einfach nicht genug Informationen, außer bestenfalls einen Zeiger auf etwas anderes.
Natürlich muss ich auch hier meinen Unterhalt verdienen. Unser Flaggschiffprodukt, SQL Sentry, verfolgt einen ganzheitlichen Überwachungsansatz. Wir erfassen instanzweite Wartestatistiken, kategorisieren sie für Sie und stellen sie auf unserem Dashboard grafisch dar:
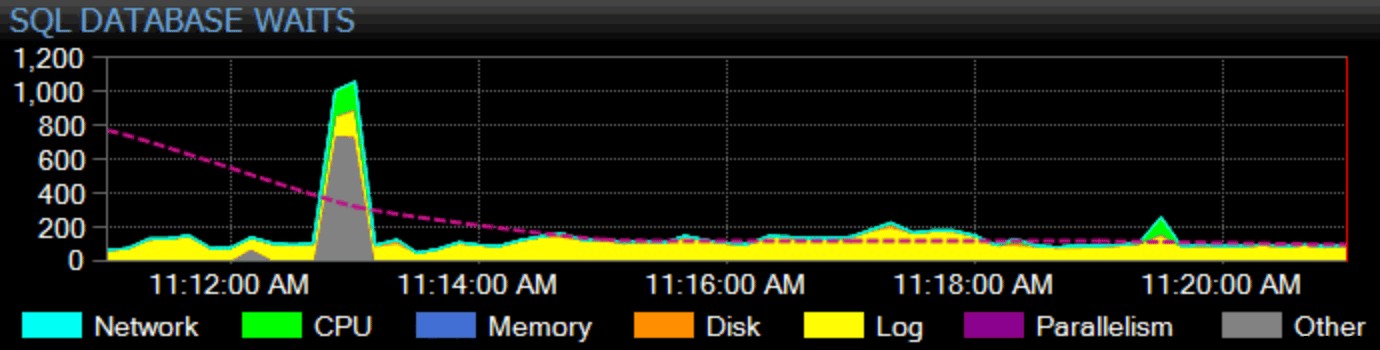
Sie können anpassen, wie jede einzelne Wartezeit kategorisiert wird und ob diese Kategorie überhaupt auf dem Dashboard angezeigt wird oder nicht. Sie können die aktuellen Wartestatistiken mit integrierten oder benutzerdefinierten Baselines vergleichen und sogar Warnungen oder Aktionen einrichten, wenn sie eine definierte Abweichung von der Baseline überschreiten. Und, was vielleicht am wichtigsten ist, Sie können sich einen Datenpunkt aus der Vergangenheit ansehen und das gesamte Dashboard mit diesem Zeitpunkt synchronisieren, sodass Sie den gesamten umgebenden Kontext und alle anderen Situationen erfassen können, die das Problem beeinflusst haben könnten. Wenn Sie granularere Dinge finden, auf die Sie sich konzentrieren müssen, wie Blockierung, hohe Festplattenlatenz oder Abfragen mit hohem I/O oder langer Dauer, können Sie diese Metriken genauer untersuchen und dem Problem ziemlich schnell auf den Grund gehen.
Weitere Informationen sowohl zu allgemeinen Ansätzen für Wartestatistiken als auch zu unserer Lösung im Besonderen finden Sie im Whitepaper von Kevin Kline, Troubleshooting SQL Server Wait Stats, und Sie können ein zweiteiliges Webinar herunterladen, das von Paul Randal, Andy Yun (@SQLBek) präsentiert wird. und Andy Mallon (@AMtwo):
- Teil 1:Fehlerbehebung bei der Leistung mithilfe von Wartestatistiken
- Teil 2:Schnelle Analyse der Wartestatistik mit SentryOne
Und wenn Sie die SentryOne-Plattform ausprobieren möchten, können Sie hier mit einem zeitlich begrenzten Angebot loslegen:
Laden Sie eine kostenlose 15-Tage-Testversion herunter