Die Datenverwaltungsplattform IRI Voracity (und das darin enthaltene Datenmaskierungsprodukt IRI FieldShield) ermöglichen es Ihnen jetzt, Datenklassen und -gruppen basierend auf Ihren Geschäftsglossaren oder Domänenontologien automatisch zu definieren und Transformationsregeln auf diese Klassen über mehrere Datenquellen und Felder hinweg anzuwenden. In diesem Artikel werde ich zeigen, wie Schutzregeln auf Feldebene auf eine Datenklassenbibliothek angewendet werden.
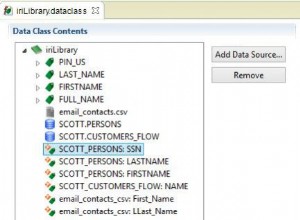
Wir werden die in meinem ersten Artikel zur Datenklassifizierung in IRI Workbench erstellte Datenklassenbibliothek für Voracity und FieldShield verwenden. Hier ist die Datenklassenbibliothek, die verwendet wird:

Sie können sehen, dass ich eine CSV-Datei und zwei Oracle-Tabellen verwendet habe. In diesem Regelbeispiel transformiere ich nur Daten in den beiden Tabellen.
Mit dem FieldShield Multi Table Protection Job Wizard wähle ich ODBC als Extraktor, nichts für den Loader (also die Ausgabe ist eine Flatfile) und die beiden oben genannten Tabellen. Auf der Seite „Feldänderungsregeln“ klicke ich auf „Erstellen“, um eine neue Maskierungsfunktionsregel für mein SSN-Feld als solche hinzuzufügen:

Ich füge dann einen Regelabgleicher hinzu, indem ich die PIN_US-Datenklasse verwende, die ich in meiner Bibliothek habe:

Ich kann so viele Matcher hinzufügen, wie ich möchte, indem ich UND/ODER-Logik verwende. Bitte beachten Sie, dass UND Vorrang hat. Der Operator des letzten Regelabgleichers wird in der Logik nicht verwendet.

Ich erstelle eine weitere Maskierungsregel mit dem vordefinierten Whole Field und der Datengruppe NAMES als Matcher. Wenn Sie auf die Schaltfläche Test klicken, wird angezeigt, dass drei Feldübereinstimmungen gefunden wurden. Da die Datenklassengruppe NAMES die Datenklassen FIRSTNAME, LAST_NAME und FULL_NAME enthält, ist dies die korrekte Ausgabe basierend auf der obigen Datenklassenbibliothek. Es gibt drei Karten mit einem Typ NAME in ihrer Datenklasse. Klassen und Gruppen werden mit Symbolen im Matcher-Details-Dialog und auf den Einstellungsseiten unterschieden.

Wenn Sie auf Weiter klicken, wird der Zusammenfassungsbildschirm angezeigt, der die Felder enthält, auf die eine Regel angewendet wird.

Wenn Sie auf Fertig stellen klicken, wird ein Ordner mit den darin enthaltenen Auftragsergebnissen erstellt.
Hier sind die beiden Jobskripte (eines für jede Tabelle), die die angewendeten Regeln in den Ausgabeabschnitten zeigen. Vier Felder wurden auf zwei verschiedene Arten maskiert:Namen werden vollständig maskiert, und bei Sozialversicherungsnummern sind nur die ersten fünf Ziffern maskiert, wobei die Bindestriche übersprungen werden.

Wenn diese Jobs allein oder als Teil eines Jobs ausgeführt werden, erzeugen sie folgende Ergebnisse:

Durch die Verwendung von Datenklassen als Regelabgleicher können Sie eine größere Anzahl von Feldern mit weniger Schritten auswählen. In diesem Beispiel habe ich vier Felder in zwei Tabellen mit nur zwei Regeln maskiert.
Wenn Sie weitere Informationen wünschen oder Feedback zur Verwendung der Datenklassifizierung und/oder der Anwendung von Regeln geben möchten, wenden Sie sich bitte an voracity@iri.com.