Ein unterstützender Index kann möglicherweise dazu beitragen, die Notwendigkeit einer expliziten Sortierung im Abfrageplan zu vermeiden, wenn T-SQL-Abfragen mit Fensterfunktionen optimiert werden. Durch einen unterstützenden Index Ich meine eine mit den Fensterpartitionierungs- und Sortierelementen als Indexschlüssel und den Rest der Spalten, die in der Abfrage erscheinen, als die im Index enthaltenen Spalten. Ich bezeichne ein solches Indizierungsmuster oft als POC index als Akronym für Partitionierung , Bestellung, und bedecken . Wenn ein Partitionierungs- oder Ordnungselement nicht in der Fensterfunktion erscheint, lassen Sie diesen Teil natürlich aus der Indexdefinition weg.
Aber was ist mit Abfragen, die mehrere Fensterfunktionen mit unterschiedlichen Sortieranforderungen beinhalten? Was ist ähnlich, wenn andere Elemente in der Abfrage neben Fensterfunktionen auch das Anordnen von Eingabedaten gemäß der Reihenfolge im Plan erfordern, z. B. eine ORDER BY-Klausel für die Präsentation? Dies kann dazu führen, dass verschiedene Teile des Plans die Eingabedaten in unterschiedlicher Reihenfolge verarbeiten müssen.
Unter solchen Umständen akzeptieren Sie in der Regel, dass eine explizite Sortierung im Plan unvermeidlich ist. Möglicherweise stellen Sie fest, dass die syntaktische Anordnung von Ausdrücken in der Abfrage wie viele beeinflussen kann explizite Sortieroperatoren bekommt man im Plan. Indem Sie einige grundlegende Tipps befolgen, können Sie manchmal die Anzahl der expliziten Sortieroperatoren reduzieren, was sich natürlich stark auf die Leistung der Abfrage auswirken kann.
Umgebung für Demos
In meinen Beispielen verwende ich die Beispieldatenbank PerformanceV5. Sie können den Quellcode zum Erstellen und Befüllen dieser Datenbank hier herunterladen.
Ich habe alle Beispiele auf SQL Server 2019 Developer ausgeführt, wo der Batchmodus im Rowstore verfügbar ist.
In diesem Artikel möchte ich mich auf Tipps konzentrieren, die mit dem Potenzial der Berechnung der Fensterfunktion im Plan zu tun haben, sich auf geordnete Eingabedaten zu verlassen, ohne dass eine zusätzliche explizite Sortieraktivität im Plan erforderlich ist. Dies ist relevant, wenn der Optimierer eine serielle oder parallele Behandlung von Fensterfunktionen im Zeilenmodus und einen seriellen Window-Aggregate-Operator im Stapelmodus verwendet.
SQL Server unterstützt derzeit keine effiziente Kombination einer parallelen reihenfolgeerhaltenden Eingabe vor einem parallelen Window Aggregate-Operator im Batchmodus. Um also einen parallelen Batchmodus-Window-Aggregate-Operator zu verwenden, muss der Optimierer einen parallelen Sortieroperator im parallelen Batchmodus einfügen, selbst wenn die Eingabe bereits vorbestellt ist.
Der Einfachheit halber können Sie bei allen in diesem Artikel gezeigten Beispielen Parallelität verhindern. Um dies zu erreichen, ohne allen Abfragen einen Hinweis hinzufügen zu müssen und ohne eine serverweite Konfigurationsoption festzulegen, können Sie die datenbankbezogene Konfigurationsoption MAXDOP festlegen zu 1 , etwa so:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Denken Sie daran, es auf 0 zurückzusetzen, nachdem Sie die Beispiele in diesem Artikel getestet haben. Ich werde dich am Ende daran erinnern.
Alternativ können Sie die Parallelität auf Sitzungsebene mit dem undokumentierten DBCC OPTIMIZER_WHATIF verhindern Befehl, etwa so:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
Um die Option zurückzusetzen, wenn Sie fertig sind, rufen Sie sie erneut mit dem Wert 0 als Anzahl der CPUs auf.
Wenn Sie alle Beispiele in diesem Artikel mit deaktiviertem Parallelismus ausprobiert haben, empfehle ich, den Parallelismus zu aktivieren und alle Beispiele erneut auszuprobieren, um zu sehen, was sich ändert.
Tipp 1 und 2
Bevor ich mit den Tipps beginne, sehen wir uns zunächst ein einfaches Beispiel mit einer Fensterfunktion an, die von einem supp class="border indent shadow orting index.
profitieren sollBetrachten Sie die folgende Abfrage, die ich als Abfrage 1 bezeichnen werde:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Machen Sie sich keine Sorgen darüber, dass das Beispiel erfunden ist. Es gibt keinen guten geschäftlichen Grund, eine laufende Summe von Bestell-IDs zu berechnen – diese Tabelle hat eine anständige Größe mit 1 MM-Zeilen, und ich wollte ein einfaches Beispiel mit einer gängigen Fensterfunktion zeigen, z. B. einer, die eine laufende Summenberechnung anwendet.
Nach dem POC-Indizierungsschema erstellen Sie den folgenden Index zur Unterstützung der Abfrage:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Der Plan für diese Abfrage ist in Abbildung 1 dargestellt.
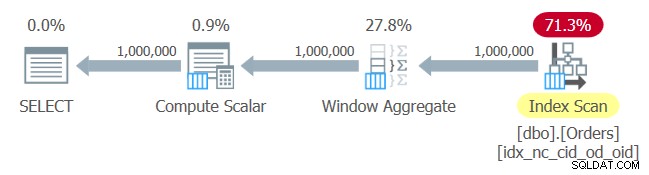 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Keine Überraschungen hier. Der Plan wendet einen Scan der Indexreihenfolge des soeben erstellten Index an und stellt die geordneten Daten dem Window Aggregate-Operator bereit, ohne dass eine explizite Sortierung erforderlich ist.
Betrachten Sie als Nächstes die folgende Abfrage, die mehrere Fensterfunktionen mit unterschiedlichen Sortieranforderungen sowie eine ORDER BY-Klausel für die Präsentation umfasst:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Ich werde diese Abfrage als Abfrage 2 bezeichnen. Der Plan für diese Abfrage ist in Abbildung 2 dargestellt.
 Abbildung 2:Plan für Abfrage 2
Abbildung 2:Plan für Abfrage 2
Beachten Sie, dass der Plan vier Sort-Operatoren enthält.
Wenn Sie die verschiedenen Fensterfunktionen und Präsentationsanordnungsanforderungen analysieren, werden Sie feststellen, dass es drei verschiedene Anordnungsanforderungen gibt:
- Kunden-ID, Bestelldatum, Bestell-ID
- Bestell-ID
- custid, orderid
Da einer von ihnen (der erste in der Liste oben) von dem Index unterstützt werden kann, den Sie zuvor erstellt haben, würden Sie erwarten, dass nur zwei Sortierungen im Plan angezeigt werden. Also, warum hat der Plan vier Sorten? Es sieht so aus, als würde SQL Server nicht versuchen, zu anspruchsvoll zu sein, indem er die Verarbeitungsreihenfolge der Funktionen im Plan neu anordnet, um Sortierungen zu minimieren. Es verarbeitet die Funktionen im Plan in der Reihenfolge, in der sie in der Abfrage erscheinen. Das gilt zumindest für das erste Auftreten jedes eindeutigen Bestellbedarfs, aber ich werde darauf in Kürze näher eingehen.
Sie können die Notwendigkeit einiger Sorten im Plan beseitigen, indem Sie die folgenden zwei einfachen Verfahren anwenden:
Tipp 1:Wenn Sie einen Index haben, um einige der Fensterfunktionen in der Abfrage zu unterstützen, geben Sie diese zuerst an.
Tipp 2:Wenn die Abfrage Fensterfunktionen mit demselben Sortierbedarf wie die Präsentationsreihenfolge in der Abfrage umfasst, geben Sie diese Funktionen zuletzt an.
Wenn Sie diese Tipps befolgen, ordnen Sie die Darstellungsreihenfolge der Fensterfunktionen in der Abfrage wie folgt neu:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Ich werde diese Abfrage als Abfrage 3 bezeichnen. Der Plan für diese Abfrage ist in Abbildung 3 dargestellt.
 Abbildung 3:Plan für Abfrage 3
Abbildung 3:Plan für Abfrage 3
Wie Sie sehen können, hat der Plan jetzt nur noch zwei Arten.
Tipp 3
SQL Server versucht nicht, die Verarbeitungsreihenfolge von Fensterfunktionen zu ausgefeilt neu zu ordnen, um Sortierungen im Plan zu minimieren. Es ist jedoch zu einer bestimmten einfachen Umordnung fähig. Es scannt die Fensterfunktionen basierend auf der Erscheinungsreihenfolge in der Abfrage und jedes Mal, wenn es einen neuen eindeutigen Ordnungsbedarf erkennt, sucht es nach zusätzlichen Fensterfunktionen mit demselben Ordnungsbedarf und gruppiert sie, wenn es diese findet, zusammen mit dem ersten Auftreten. In einigen Fällen kann es sogar denselben Operator verwenden, um mehrere Fensterfunktionen zu berechnen.
Betrachten Sie die folgende Abfrage als Beispiel:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Ich werde diese Abfrage als Abfrage 4 bezeichnen. Der Plan für diese Abfrage ist in Abbildung 4 dargestellt.
 Abbildung 4:Plan für Abfrage 4
Abbildung 4:Plan für Abfrage 4
Fensterfunktionen mit denselben Sortieranforderungen werden in der Abfrage nicht gruppiert. Allerdings sind noch immer nur zwei Sorten im Plan. Denn was in Bezug auf die Verarbeitungsreihenfolge im Plan zählt, ist das erste Auftreten jedes eindeutigen Ordnungsbedarfs. Das führt mich zum dritten Tipp.
Tipp 3:Achten Sie darauf, die Tipps 1 und 2 beim ersten Auftreten jedes einzelnen Bestellbedarfs zu befolgen. Nachfolgende Vorkommen desselben Ordnungsbedarfs, selbst wenn sie nicht benachbart sind, werden identifiziert und zusammen mit dem ersten gruppiert.
Tipps 4 und 5
Angenommen, Sie möchten Spalten, die sich aus Berechnungen im Fenster ergeben, in einer bestimmten Reihenfolge von links nach rechts in der Ausgabe zurückgeben. Aber was ist, wenn die Reihenfolge nicht mit der Reihenfolge übereinstimmt, die Sortierungen im Plan minimiert?
Angenommen, Sie möchten dasselbe Ergebnis wie das von Abfrage 2 in Bezug auf die Spaltenreihenfolge von links nach rechts in der Ausgabe (Spaltenreihenfolge:andere Spalten, Summe2, Summe1, Summe3), aber Sie hätten lieber die gleichen Plan wie den für Abfrage 3 (Spaltenreihenfolge:other cols, sum1, sum3, sum2), der zwei statt vier Sortierungen hat.
Das ist durchaus machbar, wenn Sie mit dem vierten Tipp vertraut sind.
Tipp 4:Die oben genannten Empfehlungen gelten für die Darstellungsreihenfolge von Fensterfunktionen im Code, auch wenn sie sich innerhalb eines benannten Tabellenausdrucks wie einem CTE oder einer Ansicht befinden, und selbst wenn die äußere Abfrage die Spalten in einer anderen Reihenfolge als in der zurückgibt benannter Tabellenausdruck. Wenn Sie also Spalten in einer bestimmten Reihenfolge in der Ausgabe zurückgeben müssen und diese von der optimalen Reihenfolge in Bezug auf die Minimierung von Sortierungen im Plan abweicht, befolgen Sie die Tipps zur Darstellungsreihenfolge innerhalb eines benannten Tabellenausdrucks und geben Sie die Spalten zurück in der äußeren Abfrage in der gewünschten Ausgabereihenfolge.
Die folgende Abfrage, die ich als Abfrage 5 bezeichnen werde, veranschaulicht diese Technik:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Der Plan für diese Abfrage ist in Abbildung 5 dargestellt.
 Abbildung 5:Plan für Abfrage 5
Abbildung 5:Plan für Abfrage 5
Sie erhalten immer noch nur zwei Sortierungen im Plan, obwohl die Spaltenreihenfolge in der Ausgabe lautet:other cols, sum2, sum1, sum3, wie in Abfrage 2.
Eine Einschränkung bei diesem Trick mit dem benannten Tabellenausdruck besteht darin, dass Ihre Spalten im Tabellenausdruck, wenn sie nicht von der äußeren Abfrage referenziert werden, aus dem Plan ausgeschlossen werden und daher nicht zählen.
Betrachten Sie die folgende Abfrage, die ich als Abfrage 6 bezeichnen werde:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Hier werden alle Tabellenausdrucksspalten von der äußeren Abfrage referenziert, sodass die Optimierung basierend auf dem ersten eindeutigen Vorkommen jedes Sortierbedarfs innerhalb des Tabellenausdrucks erfolgt:
- max1:custid, orderdate, orderid
- max3:Bestell-ID
- max2:custid, orderid
Dies führt zu einem Plan mit nur zwei Sortierungen, wie in Abbildung 6 gezeigt.
 Abbildung 6:Plan für Abfrage 6
Abbildung 6:Plan für Abfrage 6
Ändern Sie jetzt nur die äußere Abfrage, indem Sie die Verweise auf max2, max1, max3, avg2, avg1 und avg3 entfernen, etwa so:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Ich werde diese Abfrage als Abfrage 7 bezeichnen. Die Berechnungen von max1, max3, max2, avg1, avg3 und avg2 im Tabellenausdruck sind für die äußere Abfrage irrelevant, sodass sie ausgeschlossen werden. Die verbleibenden Berechnungen mit Fensterfunktionen im Tabellenausdruck, die für die äußere Abfrage relevant sind, sind die von sum2, sum1 und sum3. Leider erscheinen sie im Tabellenausdruck nicht in optimaler Reihenfolge im Hinblick auf die Minimierung von Sortierungen. Wie Sie im Plan für diese Abfrage in Abbildung 7 sehen können, gibt es vier Arten.
 Abbildung 7:Plan für Abfrage 7
Abbildung 7:Plan für Abfrage 7
Wenn Sie denken, dass es unwahrscheinlich ist, dass Sie Spalten in der inneren Abfrage haben, auf die Sie in der äußeren Abfrage nicht verweisen, denken Sie an Ansichten. Jedes Mal, wenn Sie eine Ansicht abfragen, interessieren Sie sich möglicherweise für eine andere Teilmenge der Spalten. Vor diesem Hintergrund könnte der fünfte Tipp helfen, Sortierungen im Plan zu reduzieren.
Tipp 5:Gruppieren Sie in der inneren Abfrage eines benannten Tabellenausdrucks wie einem CTE oder einer Ansicht alle Fensterfunktionen mit denselben Anordnungsanforderungen und befolgen Sie die Tipps 1 und 2 in der Reihenfolge der Funktionsgruppen.
Der folgende Code implementiert eine Ansicht basierend auf dieser Empfehlung:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Fragen Sie nun die Ansicht ab und fordern Sie nur die Ergebnisspalten sum2, sum1 und sum3 in dieser Reihenfolge an:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Ich werde diese Abfrage als Abfrage 8 bezeichnen. Sie erhalten den in Abbildung 8 gezeigten Plan mit nur zwei Sortierungen.
 Abbildung 8:Plan für Abfrage 8
Abbildung 8:Plan für Abfrage 8
Tipp 6
Wenn Sie eine Abfrage mit mehreren Fensterfunktionen mit mehreren unterschiedlichen Sortieranforderungen haben, ist die allgemeine Weisheit, dass Sie nur eine davon mit vorgeordneten Daten über einen Index unterstützen können. Dies ist sogar dann der Fall, wenn alle Fensterfunktionen entsprechende unterstützende Indizes haben.
Lassen Sie mich das demonstrieren. Erinnern Sie sich an die frühere Erstellung des Index idx_nc_cid_od_oid, der Fensterfunktionen unterstützen kann, die die Daten benötigen, die nach custid, orderdate, orderid geordnet sind, wie z. B. der folgende Ausdruck:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Angenommen, Sie benötigen zusätzlich zu dieser Fensterfunktion auch die folgende Fensterfunktion in derselben Abfrage:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Diese Fensterfunktion würde von folgendem Index profitieren:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
Die folgende Abfrage, die ich als Abfrage 9 bezeichnen werde, ruft beide Fensterfunktionen auf:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Der Plan für diese Abfrage ist in Abbildung 9 dargestellt.
 Abbildung 9:Plan für Abfrage 9
Abbildung 9:Plan für Abfrage 9
Ich erhalte die folgenden Zeitstatistiken für diese Abfrage auf meinem Computer, wobei die Ergebnisse in SSMS verworfen werden:
CPU time = 3234 ms, elapsed time = 3354 ms.
Wie bereits erläutert, scannt SQL Server die Fensterausdrücke in der Reihenfolge ihres Erscheinens in der Abfrage und stellt fest, dass es den ersten mit einem geordneten Scan des Indexes idx_nc_cid_od_oid unterstützen kann. Aber dann fügt es dem Plan einen Sort-Operator hinzu, um die Daten so zu ordnen, wie es die zweite Fensterfunktion benötigt. Das bedeutet, dass der Plan eine N log N-Skalierung hat. Die Verwendung des Index idx_nc_cid_oid zur Unterstützung der zweiten Fensterfunktion wird nicht berücksichtigt. Sie denken wahrscheinlich, dass dies nicht möglich ist, aber versuchen Sie, ein wenig um die Ecke zu denken. Könnten Sie nicht jede der Fensterfunktionen basierend auf ihrer jeweiligen Indexreihenfolge berechnen und dann die Ergebnisse zusammenfügen? Theoretisch können Sie das, und abhängig von der Größe der Daten, der Verfügbarkeit der Indizierung und anderen verfügbaren Ressourcen könnte die Join-Version manchmal besser abschneiden. SQL Server berücksichtigt diesen Ansatz nicht, aber Sie können ihn sicherlich implementieren, indem Sie den Join selbst schreiben, etwa so:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Ich werde diese Abfrage als Abfrage 10 bezeichnen. Der Plan für diese Abfrage ist in Abbildung 10 dargestellt.
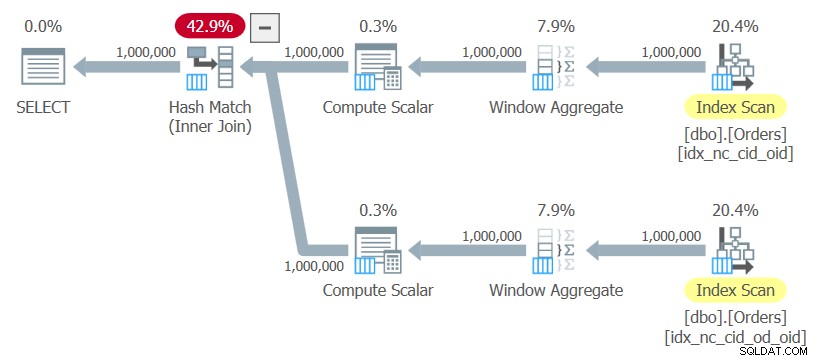 Abbildung 10:Plan für Abfrage 10
Abbildung 10:Plan für Abfrage 10
Der Plan verwendet geordnete Scans der beiden Indizes ohne jegliche explizite Sortierung, berechnet die Fensterfunktionen und verwendet einen Hash-Join, um die Ergebnisse zu verbinden. Dieser Plan skaliert linear im Vergleich zum vorherigen, der eine N-log-N-Skalierung hat.
Ich erhalte die folgenden Zeitstatistiken für diese Abfrage auf meinem Computer (wiederum mit in SSMS verworfenen Ergebnissen):
CPU time = 1000 ms, elapsed time = 1100 ms.
Um es noch einmal zusammenzufassen, hier ist unser sechster Tipp.
Tipp 6:Wenn Sie mehrere Fensterfunktionen mit mehreren unterschiedlichen Sortieranforderungen haben und alle mit Indizes unterstützen können, probieren Sie eine Join-Version aus und vergleichen Sie ihre Leistung mit der Abfrage ohne Join.
Aufräumen
Wenn Sie die Parallelität deaktiviert haben, indem Sie die datenbankweite Konfigurationsoption MAXDOP auf 1 gesetzt haben, aktivieren Sie die Parallelität wieder, indem Sie sie auf 0 setzen:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Wenn Sie die undokumentierte Sitzungsoption DBCC OPTIMIZER_WHATIF mit der CPUs-Option auf 1 verwendet haben, aktivieren Sie die Parallelität erneut, indem Sie sie auf 0 setzen:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Sie können alle Beispiele mit aktiviertem Parallelismus wiederholen, wenn Sie möchten.
Verwenden Sie den folgenden Code, um die neu erstellten Indizes zu bereinigen:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
Und den folgenden Code, um die Ansicht zu entfernen:
DROP VIEW IF EXISTS dbo.MyView;
Befolgen Sie die Tipps, um die Anzahl der Sortierungen zu minimieren
Fensterfunktionen müssen die bestellten Eingabedaten verarbeiten. Die Indizierung kann helfen, das Sortieren im Plan zu eliminieren, aber normalerweise nur für einen bestimmten Sortierbedarf. Abfragen mit mehreren Bestellanforderungen beinhalten normalerweise einige Sortierungen in ihren Plänen. Wenn Sie jedoch bestimmte Tipps befolgen, können Sie die Anzahl der benötigten Sortierungen minimieren. Hier ist eine Zusammenfassung der Tipps, die ich in diesem Artikel erwähnt habe:
- Tipp 1: Wenn Sie einen Index haben, um einige der Fensterfunktionen in der Abfrage zu unterstützen, geben Sie diese zuerst an.
- Tipp 2: Wenn die Abfrage Fensterfunktionen mit demselben Ordnungsbedarf wie die Präsentationsordnung in der Abfrage umfasst, geben Sie diese Funktionen zuletzt an.
- Tipp 3: Achten Sie darauf, die Tipps 1 und 2 für das erste Auftreten jedes einzelnen Bestellbedarfs zu befolgen. Nachfolgende Vorkommen desselben Ordnungsbedarfs, selbst wenn sie nicht benachbart sind, werden identifiziert und zusammen mit dem ersten gruppiert.
- Tipp 4: Die oben genannten Empfehlungen gelten für die Darstellungsreihenfolge von Fensterfunktionen im Code, auch wenn sie sich innerhalb eines benannten Tabellenausdrucks wie einem CTE oder einer Ansicht befinden, und selbst wenn die äußere Abfrage die Spalten in einer anderen Reihenfolge als im benannten Tabellenausdruck zurückgibt. Wenn Sie also Spalten in einer bestimmten Reihenfolge in der Ausgabe zurückgeben müssen und diese von der optimalen Reihenfolge in Bezug auf die Minimierung von Sortierungen im Plan abweicht, befolgen Sie die Tipps zur Darstellungsreihenfolge innerhalb eines benannten Tabellenausdrucks und geben Sie die Spalten zurück in der äußeren Abfrage in der gewünschten Ausgabereihenfolge.
- Tipp 5: Gruppieren Sie in der inneren Abfrage eines benannten Tabellenausdrucks wie einem CTE oder einer Ansicht alle Fensterfunktionen mit denselben Sortieranforderungen und befolgen Sie die Tipps 1 und 2 in der Reihenfolge der Funktionsgruppen.
- Tipp 6: Wenn Sie mehrere Fensterfunktionen mit mehreren unterschiedlichen Sortieranforderungen haben und alle mit Indizes unterstützen können, probieren Sie eine Join-Version aus und vergleichen Sie ihre Leistung mit der Abfrage ohne Join.