Ein Datenbankmanagementsystem ist der Tresor der Informationen. Wir werden versuchen, das Datenbankverwaltungssystem so zu gestalten, dass die Datenbank gut verwaltet bleibt und die Zwecke erfüllt.
In diesem Artikel werden wir das Entwerfen und Verwalten großer Datenbanksysteme erörtern. Wir werden mehrere Konstitutionen verwenden, die Datenbanktechnologien, Speicherung, Datenverteilung, Serverressourcen, Architekturmuster und einige andere umfassen.
Vorzugsweise sollten wir nach einer großen Datenbank im Telco-Bereich, E-Commerce-Plattformen, Versicherungsbereich, Bankensystem, Gesundheitswesen, Energiesystem usw. suchen. Wir müssen einige Parameter berücksichtigen, bevor wir die richtige Datenbanktechnologie auswählen. d. h. Verkehr, TPS (Transaktionen pro Sekunde), geschätzter Speicherplatz pro Tag, HA und DR.
Entwurf einer großen Datenbank
Beim Aufbau unserer Datenbank müssen wir auf einige Parameter achten, da es oft sehr problematisch ist, die Datenbank durch einen Ersatz zu ersetzen. Betrachten wir sie jetzt.
Datenbanktechnologie
Datenbanktechnologie ist der primäre Faktor. Wenn Sie sich für das richtige Datenbankverwaltungssystem entscheiden, wird es Ihrem Unternehmen helfen, effizient und mühelos zu laufen.
Es gibt verschiedene Datenbanktechnologien mit vielen Funktionen. Beim Arbeiten mit Open-Source-Datenbanktechnologien erhalten Sie jedoch möglicherweise keinen Zugriff auf einige explizite Funktionen vordefinierter Lösungen. Enterprise-Datenbanktechnologien wie Microsoft SQL Server, Oracle usw. würden sie bereitstellen.
Viele Unternehmensdatenbanktechnologien implementieren HA (High Availability), DR (Disaster Recovery), Spiegelung, Datenreplikation, sekundäre Read Replica und wesentlich bequemere und fertig konfigurierbare Geschäftslösungen. Sie können in Open-Source-Datenbanken vorhanden sein oder auch nicht.
Es gibt viele viele Gründe. Zum Beispiel stellen wir manchmal fest, dass die bestehende Architektur gestört wird, weil die oben genannten Faktoren nicht so funktionieren, wie wir sie brauchen.
Speicherung
Der Speicher wirkt sich drastisch auf die Leistung der Unternehmenslösung aus. Unternehmenslösungen erfordern erstklassigen Speicher oder SSD mit einer bestimmten Menge an IOPS. Ist es jedoch so? On-Premises oder Cloud, Speichergröße und -typ bestimmen die Infrastrukturkosten.
Bei der Betrachtung der Speicherleistung müssen wir auf die Art der Daten und das Verhalten der Datenverarbeitung achten. Wir müssen uns für die Speicherauswahl entsprechend den Daten des Benutzers und deren Verarbeitung entscheiden. Wenn der Benutzer mehrere Datenbanken verwenden wird, müssen wir die Speicherauswahl gegenüber dem SAN für verschiedene Datenbanken für die Datentypen und das Datenverarbeitungsverhalten bereitstellen.
Der Datenbankingenieur bietet einen besseren Rückblick auf die Berechnung der erforderlichen IOPS für die verschiedenen Datenbanken, wenn die Benutzer überhaupt keinen Premium-Speicher benötigen.
Datenverteilung
Die meisten neueren Datenbanktechnologien (SQL oder NoSQL) bieten Partitionierungs- oder Sharding-Funktionen.
- Partition verteilt Daten im Dateisystem neu, die auf dem Partitionsschlüssel basieren.
- Sharding verteilt Informationen über die Datenbankknoten und die Daten werden auf demselben oder einem anderen Computer gespeichert.
Grundsätzlich benötigt nicht jeder Datenbankdienst oder jede Datenbanktabelle die Datenpartitionierungs-/Sharding-Funktionen. Sie müssen nur auf Datenbanken angewendet werden, die größere Objekte enthalten. Dadurch wird die Leistung verbessert.
Server-Assets
Unterschiedliche Maschinen erfordern unterschiedliche Arten und Größen von Arbeitsspeicher und CPU. Sie müssen die Assets auf Hardwareebene wie Speicher, Prozessor usw. berücksichtigen. Beispielsweise benötigt ein Computer, der größere Datenbanken oder mehrere Datenbanken verarbeiten muss, mehr Speicher und CPUs. Daher ist die Qualität von Speicher und Prozessor von Bedeutung. Es wird verschiedene auf dem Markt erhältliche Prozessortypen mit unterschiedlichen CPU-Caches verarbeiten.
Oft stoßen wir auf Probleme, die uns vielleicht gar nicht bewusst sind. Auf die Auslastung und die Rolle des CPU-Cache der Hardware haben wir nicht geachtet. Bei größeren Datenbanksystemen ist es jedoch entscheidend für die Auswahl und Erfüllung der Hardwareanforderungen.
Architekturmuster
Beim Datenbankdesign spielt das Architekturmuster immer eine vorbildliche Rolle. Früher wurden Datenbanksysteme extrem monolithisch konzipiert. Jetzt verwenden wir Micro-Service-basiert oder Hybrid (monolithisch + Micro).
Die Leistung, Erweiterbarkeit und Null-Ausfallzeit hängen sehr stark vom Architekturmuster und dem Datenbankdesign ab. Jede Anwendung könnte eine separate Datenbank haben, und alle Datenbanken könnten lose miteinander gekoppelt sein. Falls eine Anwendung oder Datenbank ausfällt, wird ein anderer Teil des Produkts nicht beeinträchtigt. Alle Microservices wären unabhängig und lose gekoppelt.
Mikrodienst
Das folgende Diagramm erläutert, wie alle Anwendungen mit Hilfe ihrer Datenbanken bereitgestellt und kommuniziert werden, die gleichzeitig lose gekoppelt sind. Wir können die Daten mit T-SQL manipulieren. Die Informationen werden von verschiedenen Anwendungen gesammelt oder gesammelt, und der Client kann auf die Daten zugreifen. Siehe das Diagramm mit der Anzahl der skalierten Anwendungen und der integrierten Datenbank.
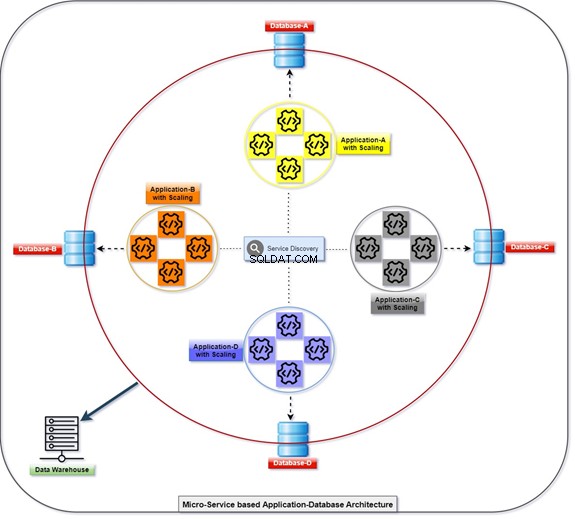
Monolithisch
Welches RDBMS sollten wir verwenden? Es könnte Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB oder jede andere Datenbank sein. Der herkömmliche Umgang mit allen Tabellen oder Objekten, die in einer oder mehreren Datenbanken auf einem einzigen Server verwaltet werden, wird als monolithisch bezeichnet.
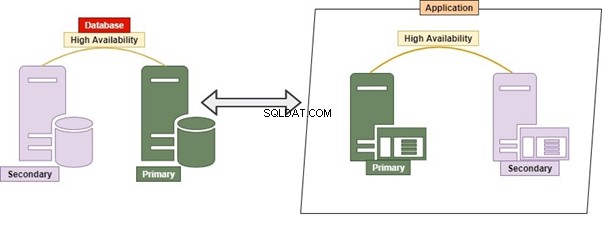
Hybrid
Hybrid ist eine Permutation von Monolithic und Micro Service. Es ist eine ziemlich gängige Praxis, da es zahlreiche Anwendungen, zahlreiche Datenbanken und Datenbankserver ermöglicht. Zahlreiche Datenbanken und Datenbankserver konnten eng miteinander gekoppelt werden.
Zum Beispiel Abfragen mit JOINs zwischen Tabellen, die zu zwei oder mehr Datenbanken auf demselben oder einem anderen Datenbankserver gehören. Fernabfrage zum Abrufen/Manipulieren von Daten mit einem anderen Datenbankserver.
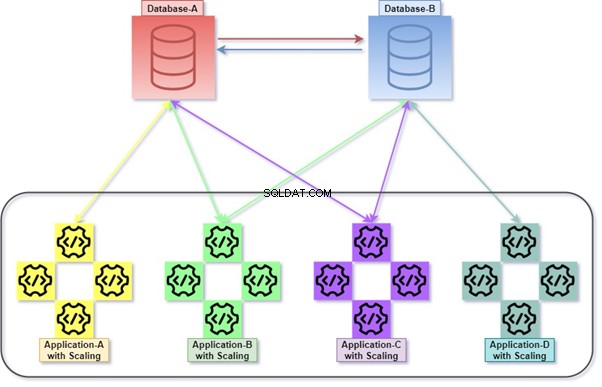
Alles dreht sich um die SQL Server-Architektur. Wir sprechen jedoch über die Datenmanipulation zwischen verschiedenen Tabellen innerhalb derselben Datenbank oder verschiedener Datenbanken, die sich auf demselben Server oder auf verschiedenen Servern befinden können.
Entweder in hybrider oder monolithischer Architektur verwenden wir JOINs zwischen verschiedenen Tabellen innerhalb derselben oder unterschiedlicher Datenbanken. Es ist ziemlich komplex, wenn wir den Kern-Micro-Service-Standards folgen, da die Verteilung der Tabellen zwischen den Datenbankdiensten (Dbas) erfolgen kann.
Unter den Enterprise-Datenbanktechnologien wie Microsoft SQL Server, Oracle usw. könnte der Benutzer die Tabellen der verteilten Datenbank mit Hilfe von Linked Server Joins abfragen. Es ist jedoch nicht in allen Open-Source-Datenbanktechnologien verfügbar. Es ist als Tight-Coupled-Ansatz bekannt, der möglicherweise nicht funktioniert, wenn der entfernte Datenbankdienst nicht verfügbar ist.
Lassen Sie uns nun diskutieren, wie man es lose koppelt. Warum brauchen wir Datenmanipulation zwischen entfernten Datenbanken?
Warum verlangen wir eine Datenmanipulation zwischen entfernten Datenbanken?
Benutzer müssen die Daten von mehr als einem Datenbankdienst abrufen, wenn das System mit Hilfe von Mikro- oder Hybriddiensten entworfen wird. Der gesamte Prozess wird vom Backend aus gesehen, das von der Anwendung manipulierte Datenmengen verarbeiten kann.
Wenn wir uns die datenbankübergreifende Echtzeitabfrage ansehen, verknüpfen wir immer die Master-Entitätstabellen, nicht die Metadatentabellen. Die Haupttabellen sind nicht größer als Metadatentabellen. Für Berichtszwecke verwenden wir immer das Data Warehouse, um alle Informationen zusammenzutragen. Aber das ist nicht einfach für jedes Produkt zu verwalten und zu pflegen. Wenn wir die Unternehmenslösung entwerfen, können wir uns das Lager leisten. Aber für kleine oder mittelgroße Produkte können wir uns das nicht leisten.
Beispielsweise benötigen wir einen Bericht mit den Daten aus mehreren Tabellen, die sich in verschiedenen Datenbanken befinden. Es ist keine leichte Aufgabe, da die Daten mithilfe verschiedener Microservices gesammelt und zur Erstellung des Berichts zusammengeführt werden. Daher müssen die erforderlichen Daten synchronisiert werden.
Was können wir als Standardlösung verwenden um lose gekoppelte Tabellendaten zwischen zwei Datenbanken zu synchronisieren?
Die Tabellenreplikation sollte für eine einfache Datensynchronisierung zwischen mehreren Datenbanken verwendet werden. Das Beispiel ist die Transaktionsreplikation für die Simplex-Datensynchronisierung und die Mergereplikation für die Duplex-Datensynchronisierung, die von SQL Server bereitgestellt werden.
Es gibt einige kostenpflichtige Drittanbieter- und Open-Source-Lösungen, die die Daten zwischen mehreren Datenbanken synchronisieren können. Sogar lose gekoppelte Lösungen mit Hilfe von Nachrichtenwarteschlangen wie der SQL Server-Transaktionsreplikation können von Benutzern selbst entwickelt werden.
Schlussfolgerung
DBAs entwerfen Datenbanken auf ihre Weise. Bei der Architektur der Datenbank und der Auswahl des Datenbankverwaltungssystems müssen viele Aspekte berücksichtigt werden. Wir haben die wichtigsten Faktoren für das Datenbankdesign vorgestellt, insbesondere für die größeren Datenbanken. Bleiben Sie dran für die nächsten Materialien!



