Von Zeit zu Zeit stellen Sie möglicherweise fest, dass ein oder mehrere Joins in einem Ausführungsplan mit StarJoinInfo kommentiert sind Struktur. Das offizielle Showplan-Schema hat Folgendes über dieses Planelement zu sagen (zum Vergrößern anklicken):
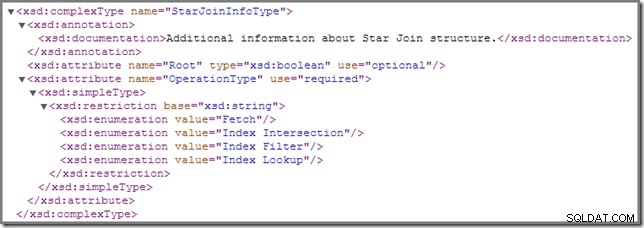
Die dort gezeigte Inline-Dokumentation ("zusätzliche Informationen zur Star-Join-Struktur ") ist nicht allzu aufschlussreich, obwohl die anderen Details ziemlich faszinierend sind – wir werden uns diese im Detail ansehen.
Wenn Sie Ihre bevorzugte Suchmaschine mit Begriffen wie „SQL Server Star Join Optimization“ nach weiteren Informationen fragen, werden Sie wahrscheinlich Ergebnisse sehen, die optimierte Bitmap-Filter beschreiben. Dies ist ein separates Feature nur für Unternehmen, das in SQL Server 2008 eingeführt wurde und nichts mit StarJoinInfo zu tun hat Struktur überhaupt.
Optimierungen für selektive Sternabfragen
Das Vorhandensein von StarJoinInfo gibt an, dass SQL Server eine Optimierung aus einer Reihe von Optimierungen angewendet hat, die auf selektive Sternschemaabfragen abzielen. Diese Optimierungen sind ab SQL Server 2005 in allen Editionen (nicht nur Enterprise) verfügbar. Beachten Sie, dass selektiv bezieht sich hier auf die Anzahl der aus der Faktentabelle abgerufenen Zeilen. Die Kombination von Dimensionsprädikaten in einer Abfrage kann immer noch selektiv sein, selbst wenn ihre einzelnen Prädikate eine große Anzahl von Zeilen qualifizieren.
Gewöhnlicher Indexschnittpunkt
Der Abfrageoptimierer kann in Betracht ziehen, mehrere nicht gruppierte Indizes zu kombinieren, wenn kein geeigneter einzelner Index vorhanden ist, wie die folgende AdventureWorks-Abfrage zeigt:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
Der Optimierer bestimmt, dass das Kombinieren von zwei Nonclustered-Indizes (einer auf SalesPersonID und die andere auf CustomerID ) ist der billigste Weg, um diese Abfrage zu erfüllen (es gibt keinen Index für beide Spalten):
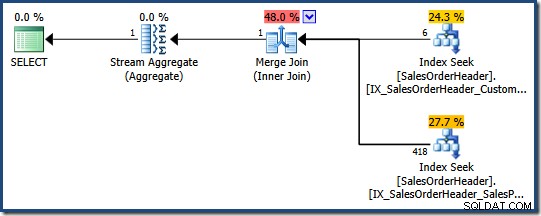
Jede Indexsuche gibt den gruppierten Indexschlüssel für Zeilen zurück, die das Prädikat passieren. Der Join stimmt mit den zurückgegebenen Schlüsseln überein, um sicherzustellen, dass nur Zeilen übereinstimmen, die mit beidem übereinstimmen Prädikate werden weitergegeben.
Wenn die Tabelle ein Heap wäre, würde jede Suche Heap Row Identifiers (RIDs) anstelle von Clustered-Index-Schlüsseln zurückgeben, aber die Gesamtstrategie ist die gleiche:Finde Zeilen-Identifier für jedes Prädikat und vergleiche sie dann.
Manueller Star-Join-Index-Schnittpunkt
Dieselbe Idee kann auf Abfragen erweitert werden, die Zeilen aus einer Faktentabelle auswählen, indem Prädikate verwendet werden, die auf Dimensionstabellen angewendet werden. Um zu sehen, wie das funktioniert, betrachten Sie die folgende Abfrage (unter Verwendung der Contoso BI-Beispieldatenbank), um den Gesamtumsatz für MP3-Player zu finden, die in Contoso-Filialen mit genau 50 Mitarbeitern verkauft wurden:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Zum Vergleich mit späteren Bemühungen erzeugt diese (sehr selektive) Abfrage einen Abfrageplan wie den folgenden (zum Erweitern klicken):
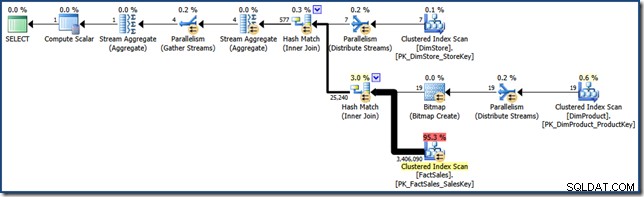
Dieser Ausführungsplan hat geschätzte Kosten von knapp über 15,6 Einheiten . Es verfügt über eine parallele Ausführung mit einem vollständigen Scan der Faktentabelle (allerdings mit angewendetem Bitmap-Filter).
Die Faktentabellen in dieser Beispieldatenbank enthalten standardmäßig keine Nonclustered-Indizes für die Fremdschlüssel der Faktentabelle, daher müssen wir ein paar hinzufügen:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Wenn diese Indizes vorhanden sind, können wir beginnen zu sehen, wie die Indexüberschneidung zur Verbesserung der Effizienz verwendet werden kann. Der erste Schritt besteht darin, Faktentabellen-Zeilenbezeichner für jedes einzelne Prädikat zu finden. Die folgenden Abfragen wenden ein einzelnes Dimensionsprädikat an und verbinden sich dann wieder mit der Faktentabelle, um Zeilenbezeichner (Clustered-Index-Schlüssel der Faktentabelle) zu finden:
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Die Abfragepläne zeigen einen Scan der kleinen Dimensionstabelle, gefolgt von Suchvorgängen unter Verwendung des nicht gruppierten Index der Faktentabelle, um Zeilenbezeichner zu finden (denken Sie daran, dass nicht gruppierte Indizes immer den Gruppierungsschlüssel oder die Heap-RID der Basistabelle enthalten):
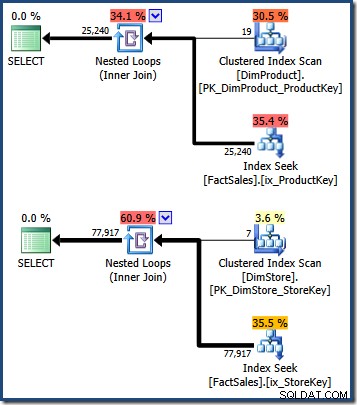
Die Schnittmenge dieser beiden Gruppen von gruppierten Indexschlüsseln für Faktentabellen identifiziert die Zeilen, die von der ursprünglichen Abfrage zurückgegeben werden sollten. Sobald wir diese Zeilenbezeichner haben, müssen wir nur den Verkaufsbetrag in jeder Faktentabellenzeile nachschlagen und die Summe berechnen.
Manuelle Index-Kreuzungsabfrage
Wenn man all das in einer Abfrage zusammenfasst, ergibt sich Folgendes:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
Der FORCESEEK hint ist da, um sicherzustellen, dass wir Point-Lookups für die Faktentabelle erhalten. Ohne dies entscheidet sich der Optimierer dafür, die Faktentabelle zu scannen, was genau das ist, was wir vermeiden möchten. Der MAXDOP 1 Der Hinweis hilft nur, den endgültigen Plan für Anzeigezwecke auf einer ziemlich vernünftigen Größe zu halten (klicken Sie, um ihn in voller Größe zu sehen):
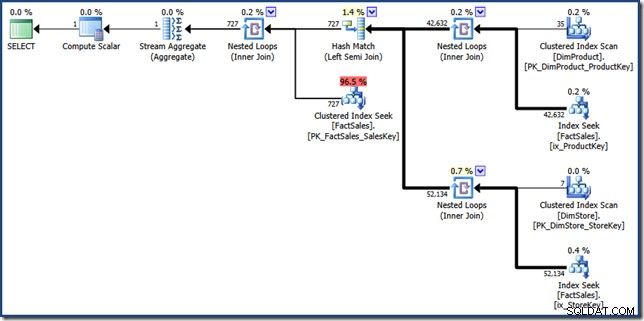
Die Bestandteile des manuellen Index-Kreuzungsplans sind recht einfach zu identifizieren. Die beiden Nonclustered-Index-Lookups für Faktentabellen auf der rechten Seite erzeugen die zwei Sätze von Faktentabellen-Zeilenkennungen. Der Hash-Join findet die Schnittmenge dieser beiden Mengen. Die Clustered-Index-Suche in der Faktentabelle findet die Verkaufsbeträge für diese Zeilenkennungen. Schließlich berechnet das Stream Aggregate den Gesamtbetrag.
Dieser Abfrageplan führt relativ wenige Suchen in den nicht gruppierten und gruppierten Indizes der Faktentabelle durch. Wenn die Abfrage selektiv genug ist, könnte dies eine billigere Ausführungsstrategie sein, als die Faktentabelle vollständig zu scannen. Die Contoso BI-Beispieldatenbank ist mit nur 3,4 Millionen Zeilen in der Verkaufsfaktentabelle relativ klein. Bei größeren Faktentabellen kann der Unterschied zwischen einem vollständigen Scan und einigen hundert Suchvorgängen sehr groß sein. Leider führt die manuelle Umschreibung zu einigen schwerwiegenden Kardinalitätsfehlern, was zu einem Plan mit geschätzten Kosten von 46,5 Einheiten führt .
Automatischer Star-Join-Index-Schnittpunkt mit Lookups
Glücklicherweise müssen wir nicht entscheiden, ob die von uns geschriebene Abfrage selektiv genug ist, um diese manuelle Umschreibung zu rechtfertigen. Die Sternverknüpfungsoptimierungen für selektive Abfragen bedeuten, dass der Abfrageoptimierer diese Option für uns untersuchen kann, indem er die benutzerfreundlichere ursprüngliche Abfragesyntax verwendet:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Der Optimierer erstellt den folgenden Ausführungsplan mit geschätzten Kosten von 1,64 Einheiten (zum Vergrößern anklicken):
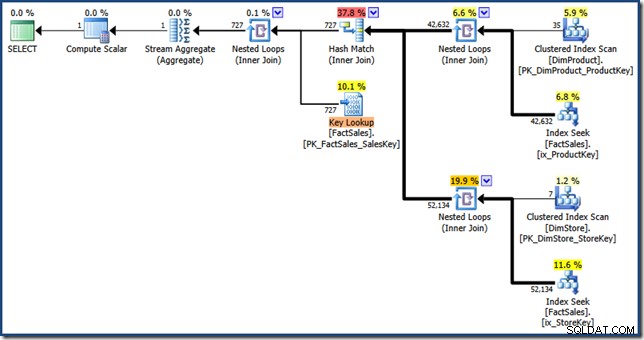
Die Unterschiede zwischen diesem Plan und der manuellen Version sind:Der Indexschnittpunkt ist ein innerer Join anstelle eines Semi-Joins; und die Clustered-Index-Suche wird als Schlüsselsuche statt als Clustered-Index-Suche angezeigt. Auf die Gefahr hin, den Punkt zu vertiefen:Wenn die Faktentabelle ein Haufen wäre, wäre die Schlüsselsuche eine RID-Suche.
Die StarJoinInfo-Eigenschaften
Die Joins in diesem Plan haben alle eine StarJoinInfo Struktur. Um es anzuzeigen, klicken Sie auf einen Join-Iterator und sehen Sie im Fenster „SSMS-Eigenschaften“ nach. Klicken Sie auf den Pfeil links neben StarJoinInfo -Element zum Erweitern des Knotens.
Die Nonclustered-Faktentabellen-Joins auf der rechten Seite des Plans sind vom Optimierer erstellte Index-Lookups:
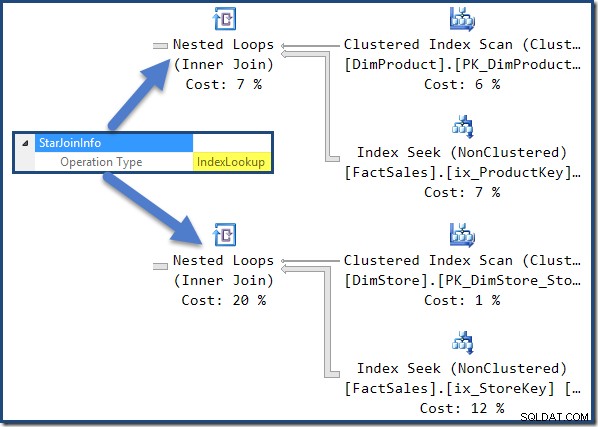
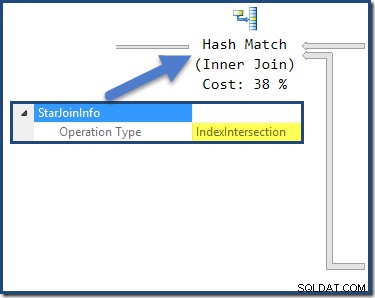
Der Hash-Join hat eine StarJoinInfo Struktur, die zeigt, dass sie einen Indexschnitt durchführt (wieder vom Optimierer hergestellt):
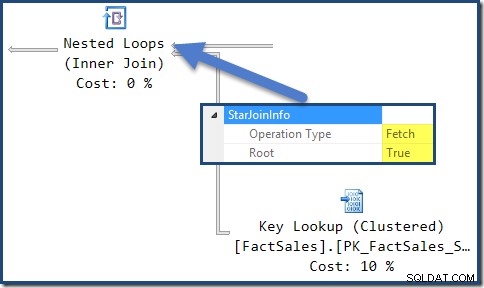
Die StarJoinInfo für den Nested-Loops-Join ganz links zeigt, dass er generiert wurde, um Faktentabellenzeilen nach Zeilenkennung abzurufen. Es befindet sich an der Wurzel des vom Optimierer generierten Sternverknüpfungs-Unterbaums:
Kartesische Produkte und mehrspaltige Indexsuche
Die als Teil der Star-Join-Optimierungen betrachteten Indexschnittpläne sind nützlich für selektive Faktentabellenabfragen, bei denen einspaltige Nonclustered-Indizes für Faktentabellen-Fremdschlüssel vorhanden sind (eine gängige Entwurfspraxis).
Manchmal ist es auch sinnvoll, für häufig abgefragte Kombinationen mehrspaltige Indizes auf Faktentabellen-Fremdschlüsseln zu erstellen. Die integrierten selektiven Star-Abfrageoptimierungen enthalten auch für dieses Szenario eine Neufassung. Um zu sehen, wie das funktioniert, fügen Sie der Faktentabelle den folgenden mehrspaltigen Index hinzu:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Kompilieren Sie die Testabfrage erneut:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Der Abfrageplan enthält keine Indexüberschneidung mehr (zum Vergrößern anklicken):
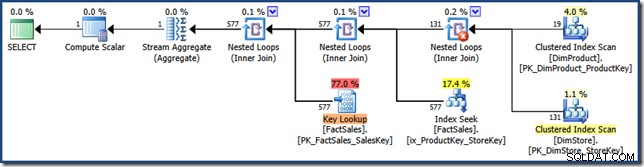
Die hier gewählte Strategie besteht darin, jedes Prädikat auf die Dimensionstabellen anzuwenden, das kartesische Produkt der Ergebnisse zu nehmen und damit in beiden Schlüsseln des mehrspaltigen Index zu suchen. Der Abfrageplan führt dann eine Schlüsselsuche in der Faktentabelle durch, wobei Zeilenbezeichner genau wie zuvor gesehen verwendet werden.
Der Abfrageplan ist besonders interessant, da er drei oft als schlechte Dinge betrachtete Funktionen (vollständige Scans, kartesische Produkte und Schlüsselsuchen) in einer Optimierung der Leistung kombiniert . Dies ist eine gültige Strategie, wenn erwartet wird, dass das Produkt der beiden Dimensionen sehr klein ist.
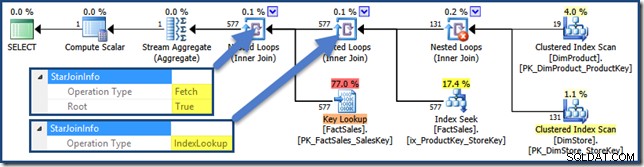
Es gibt keine StarJoinInfo für das kartesische Produkt, aber die anderen Joins enthalten Informationen (zum Vergrößern klicken):
Indexfilter
Um auf das Showplan-Schema zurückzukommen, gibt es noch eine weitere StarJoinInfo Operation, die wir abdecken müssen:
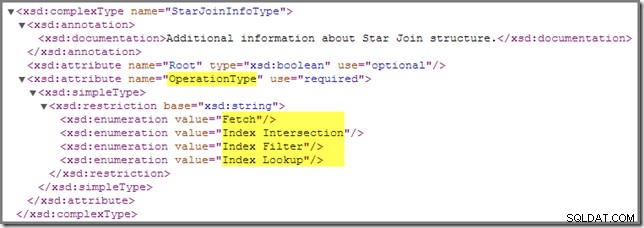
Der Index Filter Der Wert wird bei Joins gesehen, die als selektiv genug angesehen werden, um vor dem Abrufen der Faktentabelle ausgeführt zu werden. Joins, die nicht selektiv genug sind, werden nach dem Abrufen ausgeführt und haben keine StarJoinInfo Struktur.
Um einen Indexfilter mit unserer Testabfrage anzuzeigen, müssen wir der Mischung eine dritte Join-Tabelle hinzufügen, die bisher erstellten Nonclustered-Faktentabellenindizes entfernen und eine neue hinzufügen:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Der Abfrageplan ist jetzt (zum Vergrößern anklicken):
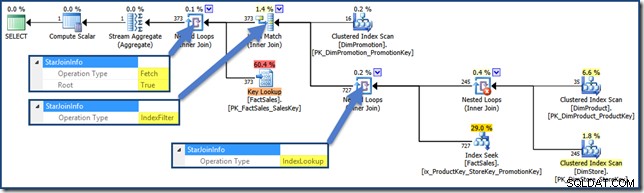
Ein Heap-Index-Intersection-Abfrageplan
Der Vollständigkeit halber ist hier ein Skript zum Erstellen einer Heap-Kopie der Faktentabelle mit den beiden Nonclustered-Indizes, die erforderlich sind, um das Umschreiben des Index-Schnittpunkt-Optimierers zu ermöglichen:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Der Ausführungsplan für diese Abfrage hat die gleichen Funktionen wie zuvor, aber die Indexüberschneidung wird unter Verwendung von RIDs anstelle von gruppierten Indexschlüsseln für Faktentabellen ausgeführt, und der endgültige Abruf ist eine RID-Suche (zum Erweitern klicken):
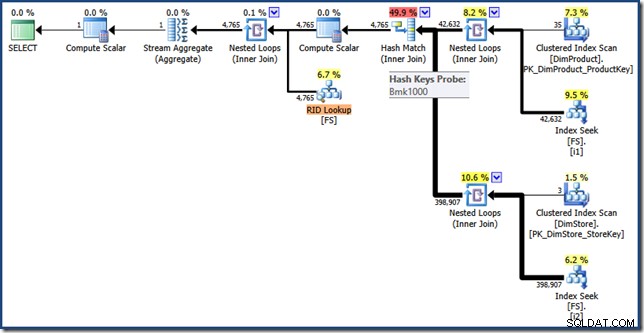
Abschließende Gedanken
Die hier gezeigten Überarbeitungen des Optimierungsprogramms zielen auf Abfragen ab, die eine relativ kleine Anzahl von Zeilen zurückgeben von einem großen Faktentabelle. Diese Umschreibungen sind seit 2005 in allen Editionen von SQL Server verfügbar.
Obwohl sie dazu gedacht sind, selektive Stern- (und Schneeflocken-) Schemaabfragen beim Data Warehousing zu beschleunigen, kann der Optimierer diese Techniken überall dort anwenden, wo er einen geeigneten Satz von Tabellen und Joins erkennt. Die zur Erkennung von Sternabfragen verwendeten Heuristiken sind recht breit gefächert, sodass Sie möglicherweise auf Planformen mit StarJoinInfo stoßen Strukturen in nahezu jeder Art von Datenbank. Jede Tabelle mit angemessener Größe (z. B. 100 Seiten oder mehr) mit Verweisen auf kleinere (dimensionsähnliche) Tabellen ist ein potenzieller Kandidat für diese Optimierungen (beachten Sie, dass explizite Fremdschlüssel nicht sind erforderlich).
Für diejenigen unter Ihnen, die solche Dinge mögen, heißt die Optimierungsregel, die für das Generieren selektiver Star-Join-Muster aus einem logischen n-Tabellen-Join verantwortlich ist, StarJoinToIdxStrategy (Sternverknüpfung zur Indexstrategie).