In diesem dritten Teil von Benchmarking Managed PostgreSQL Cloud Solutions , habe ich das kostenlose Kontingent der GCP von Google genutzt. Es war eine lohnende Erfahrung, und als Systemadministrator, der die meiste Zeit an der Konsole verbringt, konnte ich die Gelegenheit nicht verpassen, Cloud Shell auszuprobieren, eine der Konsolenfunktionen, die Google von dem mir vertrauteren Cloud-Anbieter unterscheidet , Amazon Web Services.
Um es kurz zusammenzufassen:In Teil 1 habe ich mir die verfügbaren Benchmark-Tools angesehen und erklärt, warum ich mich für das AWS-Benchmark-Verfahren für Aurora entschieden habe. Ich habe auch Amazon Aurora für PostgreSQL Version 10.6 einem Benchmarking unterzogen. In Teil 2 habe ich AWS RDS für PostgreSQL Version 11.1 überprüft.
Während dieser Runde werden die auf dem AWS-Benchmark-Verfahren für Aurora basierenden Tests mit Google Cloud SQL für PostgreSQL 9.6 durchgeführt, da sich die Version 11.1 noch in der Beta-Phase befindet.
Cloud-Instanzen
Voraussetzungen
Wie in den beiden vorherigen Artikeln erwähnt, habe ich mich dafür entschieden, die PostgreSQL-Einstellungen auf ihren Cloud-GUC-Standardwerten zu belassen, es sei denn, sie verhindern die Ausführung von Tests (siehe weiter unten). Erinnern Sie sich an frühere Artikel, dass die Annahme war, dass der Cloud-Anbieter die Datenbankinstanz standardmäßig konfiguriert haben sollte, um eine angemessene Leistung zu bieten.
Der AWS pgbench-Timing-Patch für PostgreSQL 9.6.5 wurde sauber auf die Google Cloud-Version von PostgreSQL 9.6.10 angewendet.
Anhand der Informationen, die Google in seinem Blog Google Cloud for AWS Professionals veröffentlicht hat, habe ich die Spezifikationen für den Client und die Zielinstanzen in Bezug auf die Compute-, Speicher- und Netzwerkkomponenten abgeglichen. Beispielsweise wird das Google Cloud-Äquivalent von AWS Enhanced Networking erreicht, indem der Rechenknoten basierend auf der Formel dimensioniert wird:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Beim Einrichten der Zieldatenbankinstanz erlaubt Google Cloud ähnlich wie AWS keine Replikate, jedoch wird der Speicher im Ruhezustand verschlüsselt und es gibt keine Option, ihn zu deaktivieren.
Schließlich müssen sich der Client und die Zielinstanzen in derselben Verfügbarkeitszone befinden, um die beste Netzwerkleistung zu erzielen.
Kunde
Die Client-Instance-Spezifikationen, die der AWS-Instance am nächsten kommen, sind:
- vCPU:32 (16 Kerne x 2 Threads/Kern)
- RAM:208 GiB (maximal für die Instanz mit 32 vCPUs)
- Speicher:Nichtflüchtiger Compute Engine-Speicher
- Netzwerk:16 Gbit/s (max. [32 vCPUs x 2 Gbit/s/vCPU] und 16 Gbit/s)
Instanzdetails nach der Initialisierung:
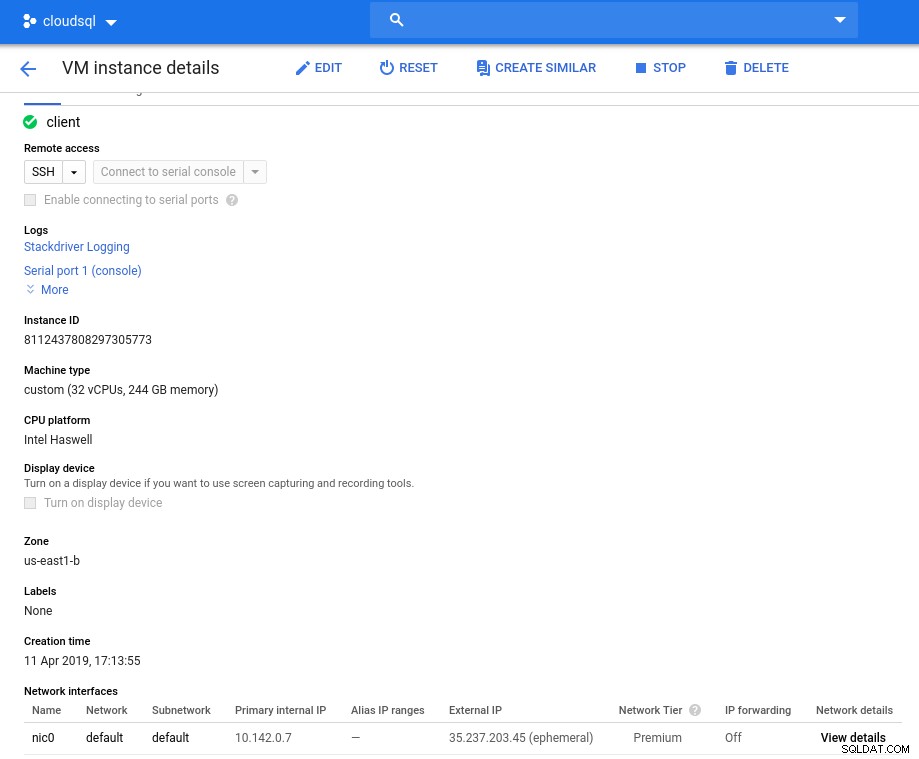 Clientinstanz:Compute und Netzwerk
Clientinstanz:Compute und Netzwerk Hinweis:Instanzen sind standardmäßig auf 24 vCPUs beschränkt. Der technische Support von Google muss die Erhöhung des Kontingents auf 32 vCPUs pro Instanz genehmigen.

Während solche Anfragen in der Regel innerhalb von zwei Werktagen bearbeitet werden, muss ich den Google-Supportdiensten dafür danken, dass sie meine Anfrage in nur zwei Stunden bearbeitet haben.
Für Neugierige:Die Formel für die Netzwerkgeschwindigkeit basiert auf der Compute-Engine-Dokumentation, auf die in diesem GCP-Blog verwiesen wird.
DB-Cluster
Unten sind die Spezifikationen der Datenbankinstanz:
- vCPU:8
- RAM:52 GiB (maximal)
- Speicher:144 MB/s, 9.000 IOPS
- Netzwerk:2.000 MB/s
Beachten Sie, dass der maximal verfügbare Arbeitsspeicher für eine Instanz mit 8 vCPUs 52 GiB beträgt. Durch Auswahl einer größeren Instanz (mehr vCPUs) kann mehr Arbeitsspeicher zugewiesen werden:
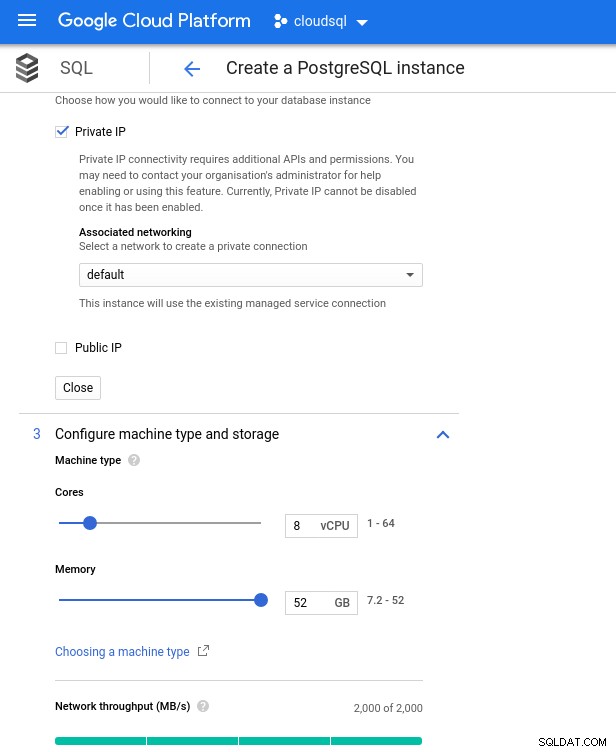 Datenbank-CPU- und Speichergröße
Datenbank-CPU- und Speichergröße Während Google SQL den zugrunde liegenden Speicher automatisch erweitern kann, was übrigens eine wirklich coole Funktion ist, habe ich mich entschieden, die Option zu deaktivieren, um mit dem AWS-Funktionssatz konsistent zu sein und eine potenzielle I/O-Auswirkung während des Größenänderungsvorgangs zu vermeiden. („potenziell“, weil es überhaupt keine negativen Auswirkungen haben sollte, aber meiner Erfahrung nach erhöht die Größenänderung jeder Art von zugrunde liegendem Speicher die E/A, selbst wenn für ein paar Sekunden).
Denken Sie daran, dass die AWS-Datenbankinstanz durch einen optimierten EBS-Speicher gesichert wurde, der maximal Folgendes bereitstellte:
- 1.700 Mbit/s Bandbreite
- Durchsatz von 212,5 MB/s
- 12.000 IOPS
Bei Google Cloud erreichen wir eine ähnliche Konfiguration, indem wir die Anzahl der vCPUs (siehe oben) und die Speicherkapazität anpassen:
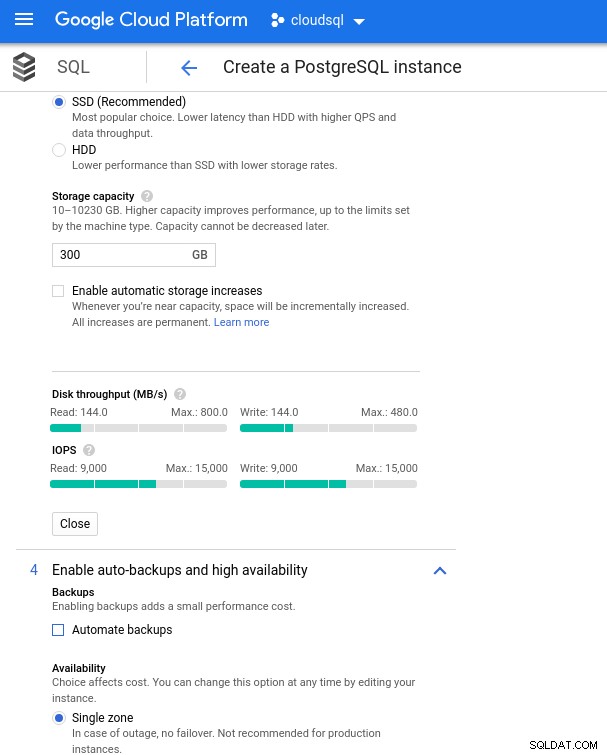 Datenbankspeicherkonfiguration und Sicherungseinstellungen
Datenbankspeicherkonfiguration und Sicherungseinstellungen Benchmarks ausführen
Einrichtung
Installieren Sie als Nächstes die Benchmark-Tools pgbench und sysbench, indem Sie den Anweisungen im Amazon-Handbuch folgen, das an die PostgreSQL-Version 9.6.10 angepasst ist.
Initialisieren Sie die PostgreSQL-Umgebungsvariablen in .bashrc und legen Sie die Pfade zu PostgreSQL-Binärdateien und -Bibliotheken fest:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libPreflight-Checkliste:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)Und wir sind startklar:
pgbench
Initialisieren Sie die pgbench-Datenbank.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…und einige Minuten später:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Wie wir es jetzt gewohnt sind, muss die Datenbankgröße 160 GB betragen. Lassen Sie uns das überprüfen:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Wenn alle Vorbereitungen abgeschlossen sind, starten Sie den Lese-/Schreibtest:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsHoppla! Was ist das Maximum?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Während AWS also max_connections groß genug einstellt, da ich auf dieses Problem nicht gestoßen bin, erfordert Google Cloud eine kleine Optimierung ... Zurück zur Cloud-Konsole, aktualisieren Sie den Datenbankparameter, warten Sie ein paar Minuten und prüfen Sie dann:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Beim Neustart des Tests scheint alles einwandfrei zu funktionieren:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...aber es gibt noch einen Haken. Ich war überrascht, als ich versuchte, eine neue psql-Sitzung zu öffnen, um die Anzahl der Verbindungen zu zählen:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsKönnte es sein, dass superuser_reserved_connections nicht auf der Standardeinstellung ist?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Das ist die Voreinstellung, was könnte es dann noch sein?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! Ein weiterer Stoß von max_connections kümmert sich darum, aber es erforderte, dass ich den pgbench-Test neu starte. Und das ist die Geschichte hinter dem offensichtlichen doppelten Lauf in den Grafiken unten.
Und schließlich sind die Ergebnisse in:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Befüllen Sie die Datenbank:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareAusgabe:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Führen Sie nun den Test durch:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runUnd die Ergebnisse:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Benchmark-Metriken
Das PostgreSQL-Plug-in für Stackdriver wurde am 28. Februar 2019 eingestellt. Obwohl Google Blue Medora empfiehlt, habe ich mich für die Zwecke dieses Artikels entschieden, auf die Erstellung eines Kontos zu verzichten und mich auf verfügbare Stackdriver-Metriken zu verlassen.
- CPU-Auslastung:
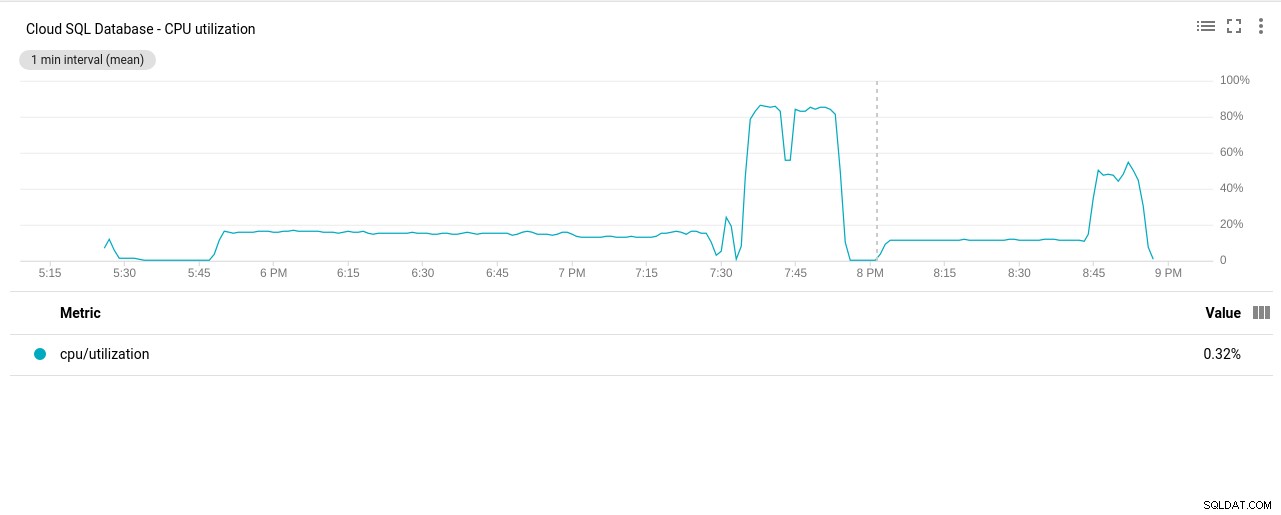 Fotoautor Google Cloud SQL:CPU-Auslastung von PostgreSQL
Fotoautor Google Cloud SQL:CPU-Auslastung von PostgreSQL - Festplatten-Lese-/Schreibvorgänge:
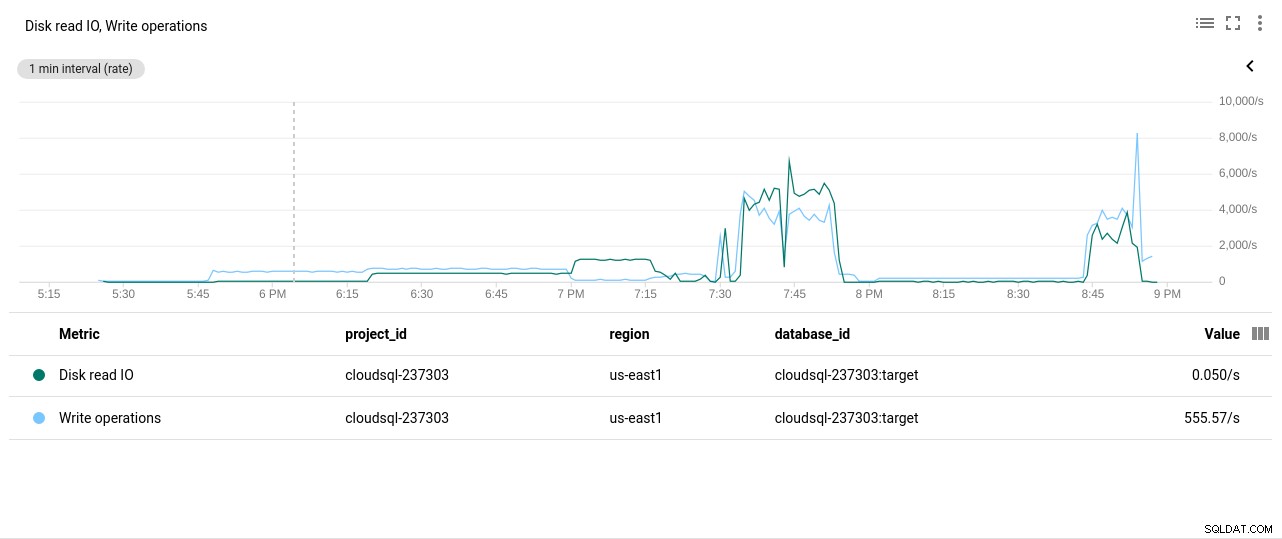 Fotoautor Google Cloud SQL:PostgreSQL Disk Read/Write operations
Fotoautor Google Cloud SQL:PostgreSQL Disk Read/Write operations - Netzwerk gesendete/empfangene Bytes:
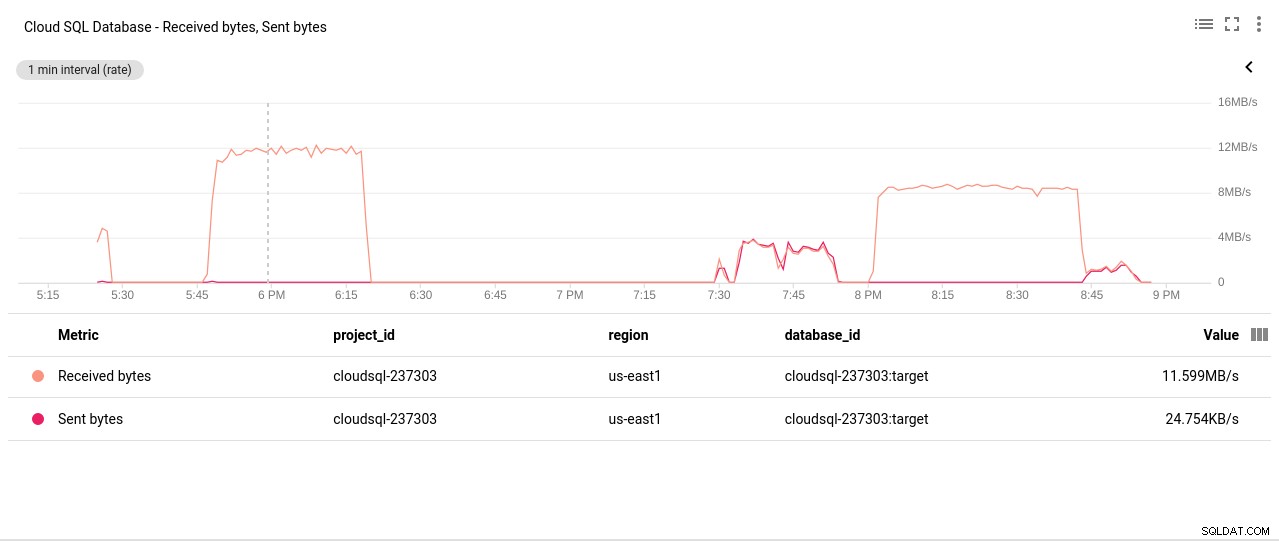 Fotoautor Google Cloud SQL:Gesendete/Empfangene Bytes vom PostgreSQL-Netzwerk
Fotoautor Google Cloud SQL:Gesendete/Empfangene Bytes vom PostgreSQL-Netzwerk - Anzahl der PostgreSQL-Verbindungen:
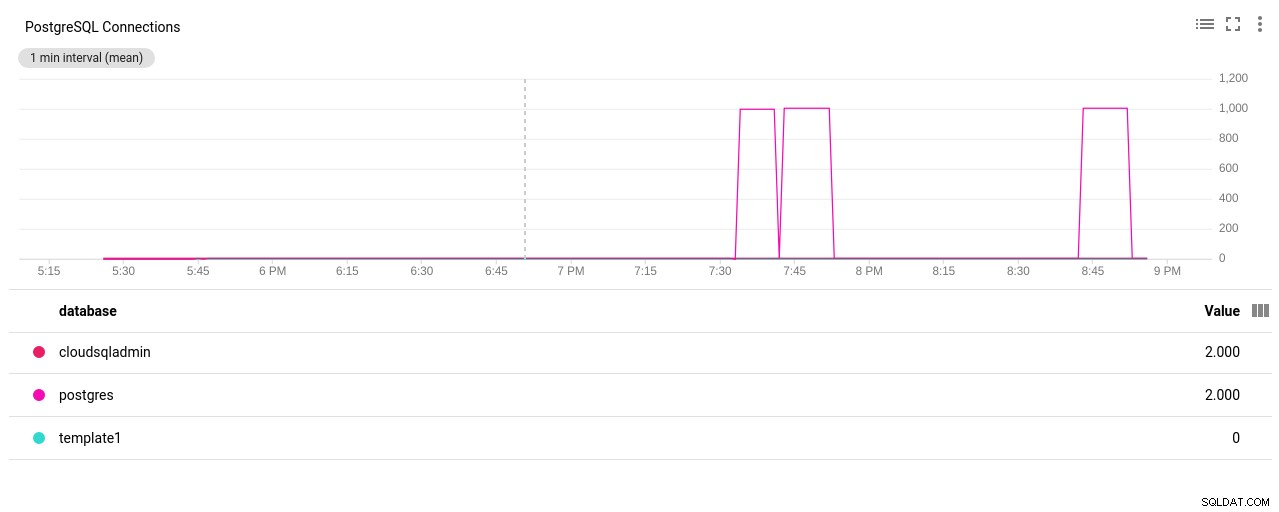 Fotoautor Google Cloud SQL:PostgreSQL Connections Count
Fotoautor Google Cloud SQL:PostgreSQL Connections Count
Benchmark-Ergebnisse
pgbench-Initialisierung
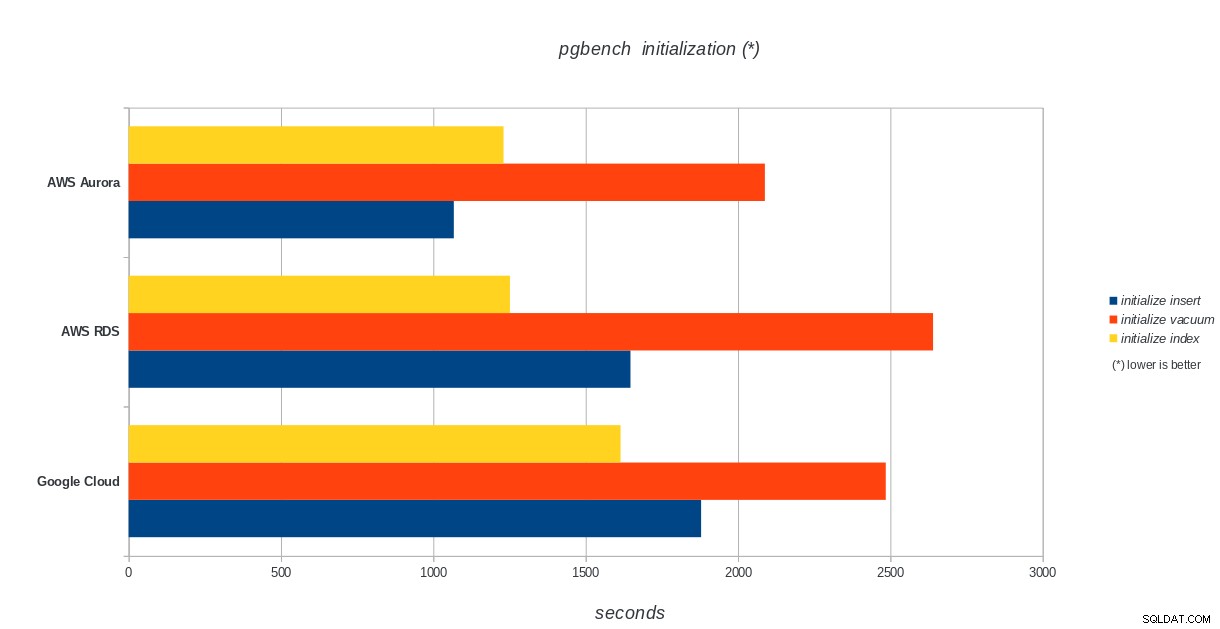 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL-pgbench-Initialisierungsergebnisse
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL-pgbench-Initialisierungsergebnisse pgbench ausführen
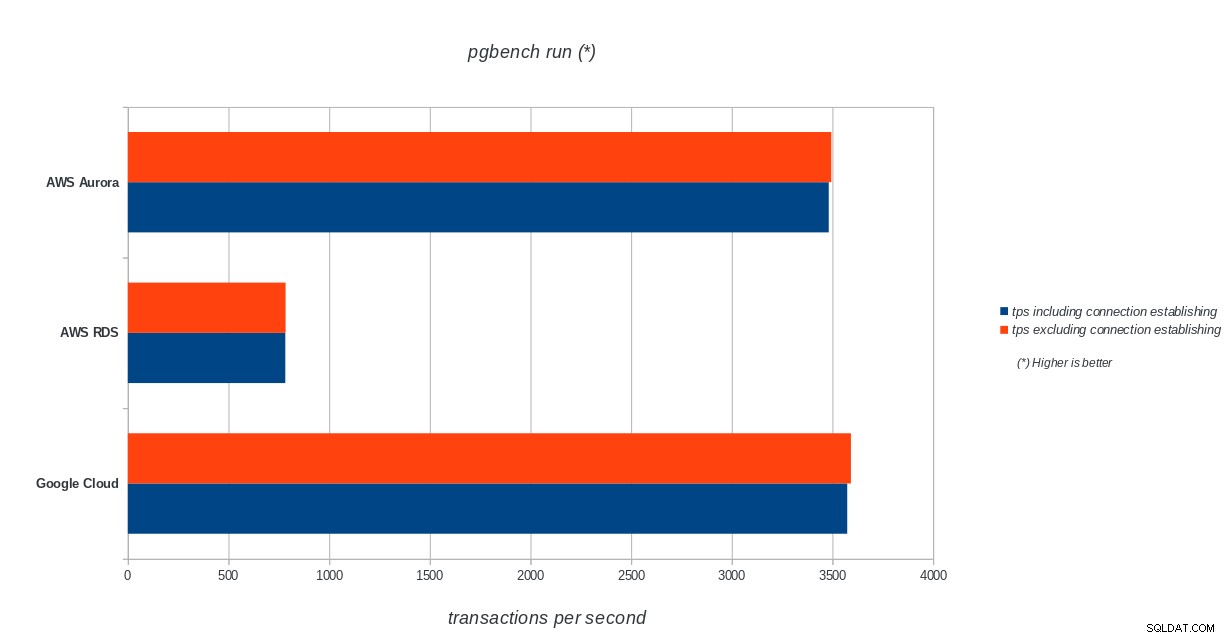 AWS Aurora, AWS RDS, Google Cloud SQL:Ergebnisse der PostgreSQL-pgbench-Ausführung
AWS Aurora, AWS RDS, Google Cloud SQL:Ergebnisse der PostgreSQL-pgbench-Ausführung sysbench
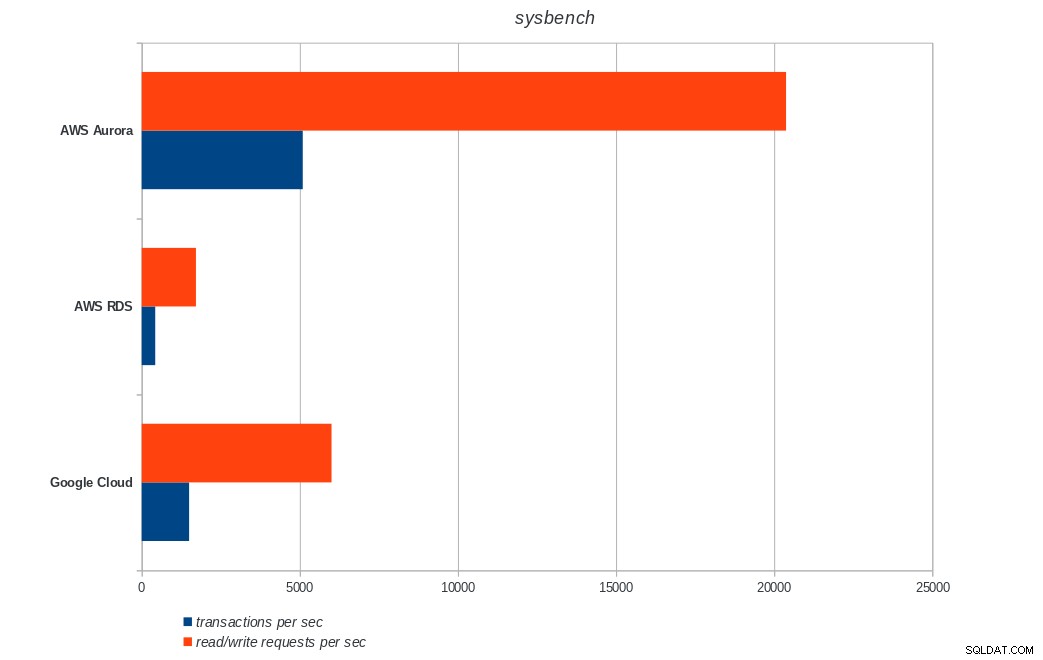 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL-Sysbench-Ergebnisse
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL-Sysbench-Ergebnisse Schlussfolgerung
Amazon Aurora belegt bei schreiblastigen (Sysbench)-Tests mit Abstand den ersten Platz, während es bei den pgbench-Lese-/Schreibtests mit Google Cloud SQL gleichauf liegt. Beim Lasttest (pgbench-Initialisierung) steht Google Cloud SQL an erster Stelle, gefolgt von Amazon RDS. Basierend auf einem flüchtigen Blick auf die Preismodelle für AWS Aurora und Google Cloud SQL würde ich riskieren zu sagen, dass Google Cloud standardmäßig die bessere Wahl für den durchschnittlichen Benutzer ist, während AWS Aurora besser für Hochleistungsumgebungen geeignet ist. Weitere Analysen werden nach Abschluss aller Benchmarks folgen.
Der nächste und letzte Teil dieser Benchmark-Serie wird sich auf Microsoft Azure PostgreSQL beziehen.
Danke fürs Lesen und kommentieren Sie bitte unten, wenn Sie Feedback haben.