[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]
Das Halloween-Problem kann eine Reihe wichtiger Auswirkungen auf Ausführungspläne haben. In diesem letzten Teil der Serie sehen wir uns die Tricks an, die der Optimierer anwenden kann, um das Halloween-Problem zu vermeiden, wenn er Pläne für Abfragen kompiliert, die Daten hinzufügen, ändern oder löschen.
Hintergrund
Im Laufe der Jahre wurde eine Reihe von Ansätzen versucht, um das Halloween-Problem zu vermeiden. Eine frühe Technik bestand darin, einfach das Erstellen von Ausführungsplänen zu vermeiden, die das Lesen und Schreiben in Schlüssel desselben Index beinhalteten. Dies war aus Performance-Sicht nicht sehr erfolgreich, nicht zuletzt, weil es oft bedeutete, die Basistabelle zu scannen, anstatt einen selektiven Nonclustered-Index zu verwenden, um die zu ändernden Zeilen zu finden.
Ein zweiter Ansatz bestand darin, die Lese- und Schreibphasen einer Aktualisierungsabfrage vollständig zu trennen, indem zunächst alle Zeilen gesucht wurden, die für die Änderung geeignet sind, sie irgendwo gespeichert und erst dann mit der Durchführung der Änderungen begonnen wurden. In SQL Server diese vollständige Phasentrennung wird erreicht, indem der jetzt bekannte Eager Table Spool auf der Eingabeseite des Aktualisierungsoperators platziert wird:
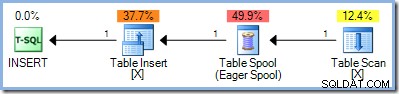
Die Spule liest alle Zeilen von ihrer Eingabe und speichert sie in einer versteckten tempdb Arbeitstisch. Die Seiten dieser Arbeitstabelle können im Arbeitsspeicher verbleiben oder physischen Speicherplatz benötigen, wenn die Menge der Zeilen groß ist oder der Server unter Arbeitsspeicherdruck steht.
Eine vollständige Phasentrennung kann weniger als ideal sein, da wir im Allgemeinen so viel wie möglich des Plans als Pipeline ausführen möchten, in der jede Zeile vollständig verarbeitet wird, bevor mit der nächsten fortgefahren wird. Pipelining hat viele Vorteile, einschließlich der Vermeidung der Notwendigkeit einer temporären Speicherung und der nur einmaligen Berührung jeder Zeile.
Der SQL Server-Optimierer
SQL Server geht viel weiter als die beiden bisher beschriebenen Techniken, obwohl er natürlich beide als Optionen enthält. Der SQL Server-Abfrageoptimierer erkennt Abfragen, die Halloween-Schutz erfordern, und bestimmt wie viel Schutz erforderlich ist und kostenbasiert verwendet wird Analyse, um die günstigste Methode zur Bereitstellung dieses Schutzes zu finden.
Der einfachste Weg, diesen Aspekt des Halloween-Problems zu verstehen, besteht darin, sich einige Beispiele anzusehen. In den folgenden Abschnitten besteht die Aufgabe darin, einer bestehenden Tabelle einen Zahlenbereich hinzuzufügen – aber nur Zahlen, die noch nicht existieren:
CREATE TABLE dbo.Test
(
pk integer NOT NULL,
CONSTRAINT PK_Test
PRIMARY KEY CLUSTERED (pk)
); 5 Reihen
Das erste Beispiel verarbeitet einen Zahlenbereich von 1 bis einschließlich 5:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 5
AND NOT EXISTS
(
SELECT NULL
FROM dbo.Test AS t
WHERE t.pk = Num.n
); Da diese Abfrage aus den Schlüsseln desselben Index in der Testtabelle liest und in diese schreibt, erfordert der Ausführungsplan Halloween-Schutz. In diesem Fall verwendet der Optimierer eine vollständige Phasentrennung mit einer Eager Table Spool:
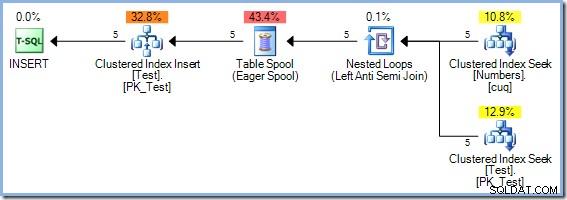
50 Zeilen
Mit jetzt fünf Zeilen in der Testtabelle führen wir dieselbe Abfrage erneut aus und ändern dabei WHERE -Klausel, um die Zahlen von 1 bis einschließlich 50 zu verarbeiten :
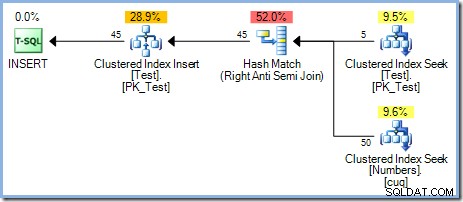
Dieser Plan bietet korrekten Schutz gegen das Halloween-Problem, enthält jedoch keine Eager Table Spool. Der Optimierer erkennt, dass der Hash-Match-Join-Operator seine Build-Eingabe blockiert; Alle Zeilen werden in eine Hash-Tabelle eingelesen, bevor der Operator den Abgleichprozess unter Verwendung von Zeilen aus der Sondeneingabe startet. Infolgedessen bietet dieser Plan natürlich eine Phasentrennung (nur für den Testtisch) ohne die Notwendigkeit einer Spule.
Der Optimierer entschied sich aus Kostengründen für einen Hash-Match-Join-Plan gegenüber dem Nested-Loops-Join, der im 5-Zeilen-Plan zu sehen ist. Der 50-Zeilen-Hash-Match-Plan hat geschätzte Gesamtkosten von 0,0347345 Einheiten. Wir können den zuvor verwendeten Plan mit verschachtelten Schleifen mit einem Hinweis erzwingen, warum der Optimierer keine verschachtelten Schleifen ausgewählt hat:
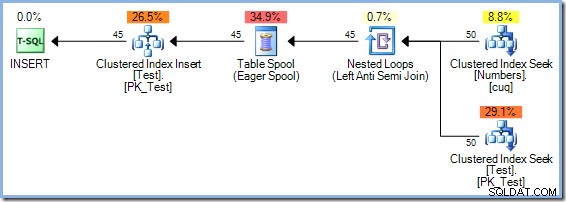
Dieser Plan hat geschätzte Kosten von 0,0379063 Einheiten einschließlich der Spule, etwas mehr als der Hash-Match-Plan.
500 Zeilen
Mit jetzt 50 Zeilen in der Testtabelle erweitern wir den Zahlenbereich weiter auf 500 :
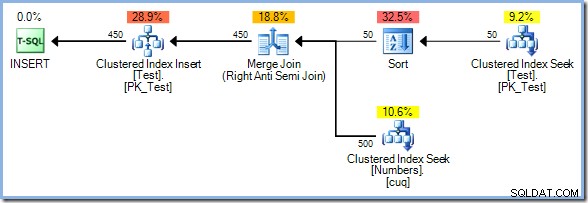
Dieses Mal wählt der Optimierer einen Merge Join, und wieder gibt es keinen Eager Table Spool. Der Sort-Operator sorgt in diesem Plan für die notwendige Phasentrennung. Es verbraucht seine Eingabe vollständig, bevor es die erste Zeile zurückgibt (die Sortierung kann nicht wissen, welche Zeile zuerst sortiert wird, bis alle Zeilen gesehen wurden). Der Optimierer entschied, dass die Sortierung 50 ist Zeilen aus der Testtabelle wären billiger als 450 Zeilen direkt vor dem Aktualisierungsoperator.
Der Plan Sort plus Merge Join hat geschätzte Kosten von 0,0362708 Einheiten. Die Planalternativen Hash Match und Nested Loops liegen bei 0,0385677 Einheiten und 0,112433 Einheiten.
Etwas Seltsames an der Sortierung
Wenn Sie diese Beispiele selbst ausgeführt haben, ist Ihnen vielleicht etwas Seltsames an diesem letzten Beispiel aufgefallen, insbesondere wenn Sie sich die Tooltips des Plan-Explorers für die Testtabellensuche und die Sortierung angesehen haben:
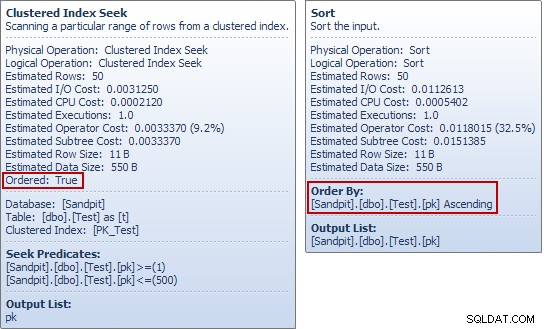
Der Suchvorgang erzeugt eine geordnete Stream von pk Werte, was bringt es also, unmittelbar danach nach derselben Spalte zu sortieren? Um diese (sehr vernünftige) Frage zu beantworten, betrachten wir zunächst nur SELECT Teil von INSERT Abfrage:
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
ORDER BY
Num.n;
Diese Abfrage erzeugt den folgenden Ausführungsplan (mit oder ohne ORDER BY Ich habe hinzugefügt, um bestimmte technische Einwände auszuräumen, die Sie möglicherweise haben):
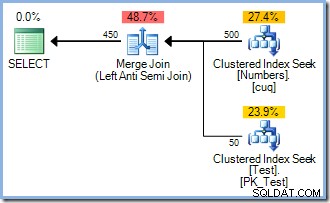
Beachten Sie das Fehlen eines Sort-Operators. Warum also wurde INSERT planen Sie eine Sortierung ein? Einfach, um das Halloween-Problem zu vermeiden. Der Optimierer hat berücksichtigt, dass eine redundante Sortierung durchgeführt wird (mit seiner eingebauten Phasentrennung) war der billigste Weg, um die Abfrage auszuführen und korrekte Ergebnisse zu garantieren. Clever.
Halloween-Schutzstufen und Eigenschaften
Der SQL Server-Optimierer verfügt über spezielle Funktionen, die es ihm ermöglichen, die an jedem Punkt im Abfrageplan erforderliche Ebene des Halloween-Schutzes (HP) und die detaillierten Auswirkungen der einzelnen Operatoren abzuschätzen. Diese zusätzlichen Funktionen sind in dasselbe Eigenschafts-Framework integriert, das der Optimierer verwendet, um Hunderte anderer wichtiger Informationen während seiner Suchaktivitäten zu verfolgen.
Jeder Operator hat eine erforderliche HP Eigentum und ein geliefert HP-Eigentum. Das erforderliche -Eigenschaft gibt die HP-Stufe an, die an diesem Punkt im Baum für korrekte Ergebnisse benötigt wird. Die geliefert Die Eigenschaft spiegelt die vom aktuellen Betreiber bereitgestellten HP und die kumulative wider HP-Effekte, die von seinem Unterbaum bereitgestellt werden.
Der Optimierer enthält Logik, um zu bestimmen, wie sich jeder physische Operator (z. B. ein Rechenskalar) auf das HP-Niveau auswirkt. Durch die Untersuchung einer breiten Palette von Planalternativen und die Ablehnung von Plänen, bei denen die gelieferten HP geringer als die erforderlichen HP beim Aktualisierungsoperator sind, hat der Optimierer eine flexible Möglichkeit, korrekte, effiziente Pläne zu finden, die nicht immer einen Eager Table Spool erfordern. P>
Planen Sie Änderungen für den Halloween-Schutz
Wir haben gesehen, wie der Optimierer im vorherigen Merge Join-Beispiel eine redundante Sortierung für den Halloween-Schutz hinzugefügt hat. Wie können wir sicher sein, dass dies effizienter ist als eine einfache Eager Table Spool? Und woher wissen wir, welche Funktionen eines Update-Plans nur für den Halloween-Schutz vorhanden sind?
Beide Fragen können (natürlich in einer Testumgebung) mit dem undokumentierten Trace-Flag 8692 beantwortet werden , was den Optimierer dazu zwingt, einen Eager Table Spool für den Halloween-Schutz zu verwenden. Denken Sie daran, dass der Merge Join-Plan mit der redundanten Sortierung geschätzte Kosten von 0,0362708 hatte magische Optimierungseinheiten. Wir können das mit der Eager Table Spool-Alternative vergleichen, indem wir die Abfrage mit aktiviertem Trace-Flag 8692 neu kompilieren:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
OPTION (QUERYTRACEON 8692);
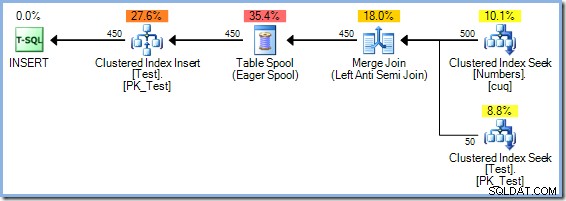
Der Eager Spool-Plan hat geschätzte Kosten von 0,0378719 Einheiten (ab 0,0362708 mit der redundanten Sortierung). Die hier gezeigten Kostenunterschiede sind aufgrund der Trivialität der Aufgabe und der geringen Größe der Zeilen nicht sehr signifikant. Reale Update-Abfragen mit komplexen Bäumen und größeren Zeilenzahlen führen oft zu Plänen, die viel effizienter sind, dank der Fähigkeit des SQL Server-Optimierers, gründlich über den Halloween-Schutz nachzudenken.
Andere Nicht-Spool-Optionen
Die optimale Positionierung eines blockierenden Operators innerhalb eines Plans ist nicht die einzige Strategie, die dem Optimierer offensteht, um die Kosten für die Bereitstellung von Schutz gegen das Halloween-Problem zu minimieren. Es kann auch über den Bereich der verarbeiteten Werte schlussfolgern, wie das folgende Beispiel zeigt:
CREATE TABLE #Test
(
pk integer IDENTITY PRIMARY KEY,
some_value integer
);
CREATE INDEX i ON #Test (some_value);
-- Pretend the table has lots of data in it
UPDATE STATISTICS #Test
WITH ROWCOUNT = 123456, PAGECOUNT = 1234;
UPDATE #Test
SET some_value = 10
WHERE some_value = 5; Der Ausführungsplan zeigt keine Notwendigkeit für Halloween-Schutz, obwohl wir aus den Schlüsseln eines gemeinsamen Indexes lesen und diese aktualisieren:
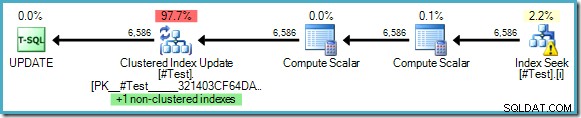
Der Optimierer kann sehen, dass die Änderung von „some_value“ von 5 auf 10 niemals dazu führen könnte, dass eine aktualisierte Zeile ein zweites Mal von der Indexsuche gesehen wird (die nur nach Zeilen sucht, in denen some_value 5 ist). Diese Argumentation ist nur möglich, wenn Literalwerte in der Abfrage verwendet werden oder wenn die Abfrage OPTION (RECOMPILE) angibt , wodurch der Optimierer die Werte der Parameter für einen einmaligen Ausführungsplan ermitteln kann.
Selbst bei Literalwerten in der Abfrage kann der Optimierer daran gehindert werden, diese Logik anzuwenden, wenn die Datenbankoption FORCED PARAMETERIZATION ist ON . In diesem Fall werden die Literalwerte in der Abfrage durch Parameter ersetzt, und der Optimierer kann nicht mehr sicher sein, dass der Halloween-Schutz nicht erforderlich ist (oder nicht erforderlich sein wird, wenn der Plan mit anderen Parameterwerten wiederverwendet wird):

Falls Sie sich fragen, was passiert, wenn FORCED PARAMETERIZATION aktiviert ist und die Abfrage gibt OPTION (RECOMPILE) an , lautet die Antwort, dass der Optimierer einen Plan für die geschnüffelten Werte erstellt und so die Optimierung anwenden kann. Wie immer mit OPTION (RECOMPILE) , wird der Abfrageplan mit bestimmten Werten nicht zur Wiederverwendung zwischengespeichert.
Oben
Dieses letzte Beispiel zeigt, wie die Top Betreiber kann die Notwendigkeit des Halloween-Schutzes entfernen:
UPDATE TOP (1) t SET some_value += 1 FROM #Test AS t WHERE some_value <= 10;

Es ist kein Schutz erforderlich, da wir nur eine Zeile aktualisieren. Der aktualisierte Wert kann von der Indexsuche nicht angetroffen werden, da die Verarbeitungspipeline stoppt, sobald die erste Zeile aktualisiert wird. Auch diese Optimierung kann nur angewendet werden, wenn im TOP ein konstanter Literalwert verwendet wird , oder wenn eine Variable, die den Wert „1“ zurückgibt, mit OPTION (RECOMPILE) geschnüffelt wird .
Wenn wir den TOP (1) ändern in der Abfrage zu einem TOP (2) , wählt der Optimierer einen Clustered Index Scan anstelle von Index Seek:

Wir aktualisieren die Schlüssel des Clustered-Index nicht, daher erfordert dieser Plan keinen Halloween-Schutz. Erzwingen der Verwendung des Nonclustered-Index mit einem Hinweis im TOP (2) Abfrage macht die Kosten des Schutzes deutlich:

Der Optimierer schätzte, dass der Clustered Index Scan billiger wäre als dieser Plan (mit seinem zusätzlichen Halloween-Schutz).
Odds and Ends
Es gibt noch ein paar andere Punkte, die ich über Halloween Protection ansprechen möchte, die bisher keinen natürlichen Platz in der Serie gefunden haben. Die erste ist die Frage des Halloween-Schutzes, wenn eine Isolationsstufe für die Zeilenversionierung verwendet wird.
Zeilenversionierung
SQL Server bietet zwei Isolationsstufen, READ COMMITTED SNAPSHOT und SNAPSHOT ISOLATION die einen Versionsspeicher in tempdb verwenden um eine konsistente Ansicht der Datenbank auf Anweisungs- oder Transaktionsebene bereitzustellen. SQL Server könnte Halloween Protection unter diesen Isolationsstufen vollständig vermeiden, da der Versionsspeicher Daten bereitstellen kann, die von Änderungen, die die aktuell ausgeführte Anweisung möglicherweise bisher vorgenommen hat, unbeeinflusst bleiben. Diese Idee ist derzeit nicht in einer veröffentlichten Version von SQL Server implementiert, obwohl Microsoft ein Patent eingereicht hat, das beschreibt, wie dies funktionieren würde, also wird diese Technologie vielleicht in eine zukünftige Version integriert.
Heaps und weitergeleitete Datensätze
Wenn Sie mit den Interna von Heap-Strukturen vertraut sind, fragen Sie sich vielleicht, ob ein bestimmtes Halloween-Problem auftreten kann, wenn weitergeleitete Datensätze in einer Heap-Tabelle generiert werden. Falls dies neu für Sie ist, wird ein Heap-Datensatz weitergeleitet, wenn eine vorhandene Zeile so aktualisiert wird, dass sie nicht mehr auf die ursprüngliche Datenseite passt. Die Engine hinterlässt einen Weiterleitungs-Stub und verschiebt den erweiterten Datensatz auf eine andere Seite.
Ein Problem kann auftreten, wenn ein Plan, der einen Heap-Scan enthält, einen Datensatz so aktualisiert, dass er weitergeleitet wird. Der Heap-Scan trifft möglicherweise erneut auf die Zeile, wenn die Scan-Position die Seite mit dem weitergeleiteten Datensatz erreicht. In SQL Server wird dieses Problem vermieden, da die Speicher-Engine garantiert, Weiterleitungszeigern immer sofort zu folgen. Wenn der Scan auf einen weitergeleiteten Datensatz stößt, wird er ignoriert. Mit diesem Schutz muss sich der Abfrageoptimierer nicht um dieses Szenario kümmern.
SCHEMABINDING- und T-SQL-Skalarfunktionen
Es gibt sehr wenige Fälle, in denen die Verwendung einer T-SQL-Skalarfunktion eine gute Idee ist, aber wenn Sie eine verwenden müssen, sollten Sie sich der wichtigen Auswirkungen bewusst sein, die sie in Bezug auf den Halloween-Schutz haben kann. Es sei denn, eine Skalarfunktion wird mit dem SCHEMABINDING deklariert Option, geht SQL Server davon aus, dass die Funktion auf Tabellen zugreift. Betrachten Sie zur Veranschaulichung die folgende einfache T-SQL-Skalarfunktion:
CREATE FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
AS
BEGIN
RETURN @value;
END;
Diese Funktion greift auf keine Tabellen zu; Tatsächlich tut es nichts, außer den ihm übergebenen Parameterwert zurückzugeben. Sehen Sie sich nun das folgende INSERT an Abfrage:
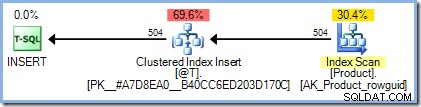
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT p.ProductID FROM AdventureWorks2012.Production.Product AS p;
Der Ausführungsplan ist genau so, wie wir es erwarten würden, ohne Halloween-Schutz:
Das Hinzufügen unserer Do-Nothing-Funktion hat jedoch einen dramatischen Effekt:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID) FROM AdventureWorks2012.Production.Product AS p;

Der Ausführungsplan enthält jetzt eine Eager Table Spool zum Halloween-Schutz. SQL Server geht davon aus, dass die Funktion auf Daten zugreift, wozu auch das erneute Lesen aus der Product-Tabelle gehören kann. Wie Sie sich vielleicht erinnern, ein INSERT Plan, der einen Verweis auf die Zieltabelle auf der Leseseite des Plans enthält, erfordert vollständigen Halloween-Schutz, und soweit der Optimierer weiß, könnte dies hier der Fall sein.
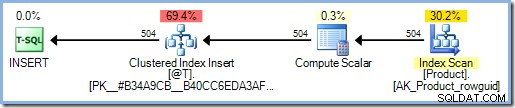
Hinzufügen des SCHEMABINDING Option zur Funktionsdefinition bedeutet, dass SQL Server den Hauptteil der Funktion untersucht, um festzustellen, auf welche Tabellen zugegriffen wird. Es findet keinen solchen Zugriff und fügt daher keinen Halloween-Schutz hinzu:
ALTER FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
RETURN @value;
END;
GO
DECLARE @T AS TABLE (ProductID int PRIMARY KEY);
INSERT @T (ProductID)
SELECT p.ProductID
FROM AdventureWorks2012.Production.Product AS p;
Dieses Problem mit skalaren T-SQL-Funktionen betrifft alle Aktualisierungsabfragen – INSERT , UPDATE , DELETE und MERGE . Zu wissen, wann Sie auf dieses Problem stoßen, wird dadurch erschwert, dass unnötiger Halloween-Schutz nicht immer als extra Eager Table Spool angezeigt wird und skalare Funktionsaufrufe beispielsweise in Ansichten oder berechneten Spaltendefinitionen versteckt sein können.
[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]