Einer der in Books Online erwähnten Anwendungsfälle für gefilterte Indizes betrifft eine Spalte, die hauptsächlich NULL enthält Werte. Die Idee ist, einen gefilterten Index zu erstellen, der die NULLs ausschließt , was zu einem kleineren nicht gruppierten Index führt, der weniger Wartung erfordert als der entsprechende ungefilterte Index. Eine weitere beliebte Verwendung gefilterter Indizes ist das Filtern von NULLs von einem UNIQUE Index, der das Verhalten angibt, das Benutzer anderer Datenbank-Engines von einem standardmäßigen UNIQUE erwarten könnten Index oder Einschränkung:Eindeutigkeit wird nur für Nicht-NULL erzwungen Werte.
Leider hat der Abfrageoptimierer Einschränkungen, wenn es um gefilterte Indizes geht. Dieser Beitrag befasst sich mit einigen weniger bekannten Beispielen.
Beispieltabellen
Wir werden zwei Tabellen (A &B) verwenden, die die gleiche Struktur haben:einen geclusterten Ersatz-Primärschlüssel, einen meist-NULL Spalte, die eindeutig ist (ohne Berücksichtigung von NULLs ) und eine Füllspalte, die die anderen Spalten darstellt, die sich möglicherweise in einer echten Tabelle befinden.
Die interessierende Spalte ist meistens NULL eine, die ich als SPARSE deklariert habe . Die Sparse-Option ist nicht erforderlich, ich füge sie nur hinzu, weil ich nicht viel Gelegenheit habe, sie zu verwenden. In jedem Fall SPARSE ist wahrscheinlich in vielen Szenarien sinnvoll, in denen erwartet wird, dass die Spaltendaten hauptsächlich NULL sind . Wenn Sie möchten, können Sie das Sparse-Attribut aus den Beispielen entfernen.
CREATE TABLE dbo.TableA( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x);
Jede Tabelle enthält die Zahlen von 1 bis 2.000 in der Datenspalte mit zusätzlichen 40.000 Zeilen, in denen die Datenspalte NULL ist :
-- Zahlen 1 - 2.000INSERT dbo.TableA WITH (TABLOCKX) (data)SELECT TOP (2000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))FROM sys.columns AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER() OVER (ORDER BY (SELECT NULL)); - NULLsINSERT TOP (40000) dbo.TableA WITH (TABLOCKX) (data)SELECT CONVERT(bigint, NULL)FROM sys.columns AS cCROSS JOIN sys.columns AS c2; -- Kopieren Sie in TableBINSERT dbo.TableB WITH (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
Beide Tische erhalten einen UNIQUE gefilterter Index für die 2.000 Nicht-NULL Datenwerte:
ERSTELLE EINZIGARTIGEN, NICHT EINGESCHLOSSENEN INDEX uqAON dbo.TableA (data) WO data NICHT NULL IST; CREATE UNIQUE NONCLUSTERED INDEX uqBON dbo.TableB (data) WHERE data NOT NULL;
Die Ausgabe von DBCC SHOW_STATISTICS fasst die Situation zusammen:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER;DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

Beispielabfrage
Die folgende Abfrage führt eine einfache Verknüpfung der beiden Tabellen durch – stellen Sie sich vor, die Tabellen befinden sich in einer Art Eltern-Kind-Beziehung und viele der Fremdschlüssel sind NULL. Irgendetwas in dieser Richtung sowieso.
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
Standardausführungsplan
Bei SQL Server in seiner Standardkonfiguration wählt der Optimierer einen Ausführungsplan mit einem Join mit parallelen verschachtelten Schleifen:
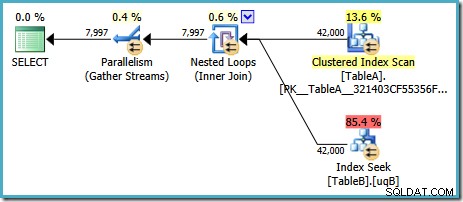
Dieser Plan hat geschätzte Kosten von 7,7768 Magic Optimizer Units™.
Es gibt jedoch einige seltsame Dinge an diesem Plan. Die Indexsuche verwendet unseren gefilterten Index für Tabelle B, aber die Abfrage wird von einem Clustered Index Scan von Tabelle A gesteuert. Das Join-Prädikat ist ein Gleichheitstest für die Datenspalten, der NULLs (unabhängig von ANSI_NULLS Einstellung). Wir hätten vielleicht gehofft, dass der Optimierer basierend auf dieser Beobachtung einige fortgeschrittene Überlegungen anstellen würde, aber nein. Dieser Plan liest jede Zeile aus Tabelle A (einschließlich der 40.000 NULLs ), führt für jeden eine Suche im gefilterten Index in Tabelle B durch und verlässt sich dabei auf die Tatsache, dass NULL stimmt nicht mit NULL überein darin suchen. Das ist eine enorme Zeitverschwendung.
Das Seltsame ist, dass der Optimierer erkannt haben muss, dass der Join NULLs ablehnt um den gefilterten Index für die Suche in Tabelle B auszuwählen, aber es wurde nicht daran gedacht, NULLs zu filtern aus Tabelle A zuerst – oder noch besser, um einfach die NULL zu scannen -frei gefilterter Index auf Tabelle A. Sie fragen sich vielleicht, ob dies eine kostenbasierte Entscheidung ist, vielleicht sind die Statistiken nicht sehr gut? Vielleicht sollten wir die Verwendung des gefilterten Index mit einem Hinweis erzwingen? Das Hinweisen auf den gefilterten Index in Tabelle A führt nur zu demselben Plan mit umgekehrten Rollen – Scannen von Tabelle B und Suchen in Tabelle A. Das Erzwingen des gefilterten Index für beide Tabellen führt zu Fehler 8622 :Der Abfrageprozessor konnte keinen Abfrageplan erstellen.
Hinzufügen eines NOT NULL-Prädikats
Vermutung, dass die Ursache etwas mit dem impliziten NULL zu tun hat -Ablehnung des Join-Prädikats, fügen wir ein explizites NOT NULL hinzu Prädikat zum ON -Klausel (oder die WHERE Wenn Sie es vorziehen, läuft es hier auf dasselbe hinaus):
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL;
Wir haben NOT NULL hinzugefügt Überprüfen Sie die Spalte von Tabelle A, da der ursprüngliche Plan den gruppierten Index dieser Tabelle gescannt hat, anstatt unseren gefilterten Index zu verwenden (die Suche in Tabelle B war in Ordnung – es wurde der gefilterte Index verwendet). Die neue Abfrage ist semantisch genau die gleiche wie die vorherige, aber der Ausführungsplan ist anders:
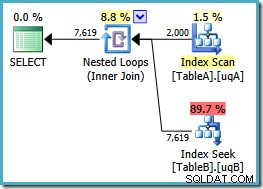
Jetzt haben wir den erhofften Scan des gefilterten Index auf Tabelle A, der 2.000 Nicht-NULL erzeugt Zeilen, um die verschachtelten Schleifensuchen in Tabelle B zu treiben. Beide Tabellen verwenden unsere gefilterten Indizes jetzt offensichtlich optimal:Der neue Plan kostet nur 0,362835 Einheiten (nach unten von 7,7768). Wir können es jedoch besser machen.
Hinzufügen von zwei NOT NULL-Prädikaten
Der redundante NOT NULL Prädikat für Tabelle A wirkte Wunder; Was passiert, wenn wir auch eine für Tabelle B hinzufügen?
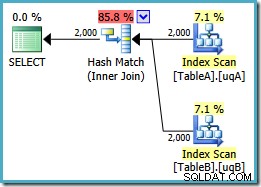
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL UND tb.data IS NOT NULL;
Diese Abfrage ist logisch immer noch die gleiche wie die beiden vorherigen Bemühungen, aber der Ausführungsplan ist wieder anders:
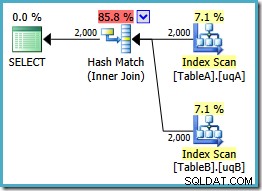
Dieser Plan erstellt eine Hash-Tabelle für die 2.000 Zeilen aus Tabelle A und sucht dann anhand der 2.000 Zeilen aus Tabelle B nach Übereinstimmungen. Die geschätzte Anzahl der zurückgegebenen Zeilen ist viel besser als die vorherigen Plan (haben Sie die Schätzung von 7.619 dort bemerkt?) und die geschätzten Ausführungskosten sind wieder gesunken, von 0,362835 auf 0,0772056 .
Sie könnten versuchen, einen Hash-Join zu erzwingen, indem Sie einen Hinweis auf das Original oder ein einzelnes NOT NULL verwenden Abfragen, aber Sie erhalten nicht den oben gezeigten Low-Cost-Plan. Der Optimierer hat einfach nicht die Fähigkeit, über NULL vollständig nachzudenken -Ablehnungsverhalten des Joins, wie es für unsere gefilterten Indizes ohne beide redundanten Prädikate gilt.
Davon darf man sich überraschen lassen – auch wenn es nur die Vorstellung ist, dass ein redundantes Prädikat nicht ausreicht (sicherlich, wenn ta.data ist NOT NULL und ta.data =tb.data , folgt daraus tb.data ist auch NOT NULL , oder?)
Noch nicht perfekt
Es ist ein wenig überraschend, dass dort ein Hash beitritt. Wenn Sie mit den Hauptunterschieden zwischen den drei physischen Join-Operatoren vertraut sind, wissen Sie wahrscheinlich, dass Hash-Join ein Spitzenkandidat ist, wobei:
- Vorsortierte Eingabe ist nicht verfügbar
- Die Hash-Build-Eingabe ist kleiner als die Sondeneingabe
- Die Sondeneingabe ist ziemlich groß
Keines dieser Dinge trifft hier zu. Wir gehen davon aus, dass der beste Plan für diese Abfrage und diesen Datensatz ein Merge-Join wäre, bei dem die geordnete Eingabe genutzt wird, die von unseren beiden gefilterten Indizes verfügbar ist. Wir können versuchen, einen Merge-Join anzudeuten und dabei die beiden zusätzlichen ON beizubehalten Klauselprädikate:
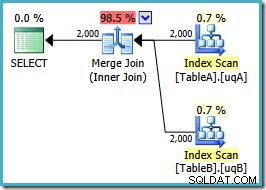
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL AND tb.data IS NOT NULLOPTION (MERGE JOIN);Die Planform ist wie erhofft:
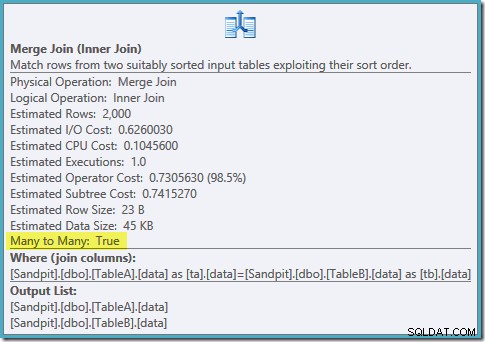
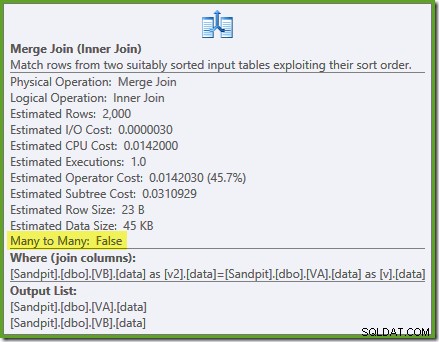
Ein geordneter Scan beider gefilterter Indizes, großartige Kardinalitätsschätzungen, fantastisch. Nur ein kleines Problem:Dieser Ausführungsplan ist viel schlimmer; die geschätzten Kosten sind von 0,0772056 auf 0,741527 gestiegen . Der Grund für den Anstieg der geschätzten Kosten wird durch Überprüfen der Eigenschaften des Merge-Join-Operators aufgedeckt:
Dies ist eine teure Viele-zu-Viele-Verknüpfung, bei der die Ausführungs-Engine Duplikate von der äußeren Eingabe in einer Arbeitstabelle verfolgen und bei Bedarf zurückspulen muss. Duplikate? Wir scannen einen eindeutigen Index! Es stellt sich heraus, dass der Optimierer nicht weiß, dass ein gefilterter eindeutiger Index eindeutige Werte erzeugt (Element hier verbinden). Tatsächlich ist dies eine Eins-zu-Eins-Verknüpfung, aber der Optimierer kostet es, als wäre es eine Viele-zu-Viele-Verbindung, was erklärt, warum er den Hash-Verknüpfungsplan bevorzugt.
Eine alternative Strategie
Es scheint, dass wir hier immer wieder auf Optimierungsbeschränkungen stoßen, wenn wir gefilterte Indizes verwenden (obwohl dies ein hervorgehobener Anwendungsfall in Books Online ist). Was passiert, wenn wir versuchen, stattdessen Ansichten zu verwenden?
Ansichten verwenden
Die folgenden zwei Ansichten filtern nur die Basistabellen, um die Zeilen anzuzeigen, in denen die Datenspalte
NOT NULList :CREATE VIEW dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableAWHERE data IS NOT NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data IS NOT NULL;Das Umschreiben der ursprünglichen Abfrage zur Verwendung der Ansichten ist trivial:
SELECT v.data, v2.dataFROM dbo.VA AS vJOIN dbo.VB AS v2 ON v.data =v2.data;Denken Sie daran, dass diese Abfrage ursprünglich einen Plan mit parallel verschachtelten Schleifen erzeugte, der 7,7768 kostete Einheiten. Mit den View-Referenzen erhalten wir diesen Ausführungsplan:
Das ist genau derselbe Hash-Join-Plan, den wir mussten, um redundantes
NOT NULLhinzuzufügen Prädikate, die mit den gefilterten Indizes zu erhalten sind (die Kosten betragen 0,0772056 Einheiten wie zuvor). Dies ist zu erwarten, da wir hier im Wesentlichen nur das zusätzlicheNOT NULLverschoben haben Prädikate von der Abfrage zu einer Ansicht.Indizierung der Aufrufe
Wir können auch versuchen, die Ansichten zu materialisieren, indem wir einen eindeutigen gruppierten Index für die pk-Spalte erstellen:
ERSTELLE EINZIGARTIGEN CLUSTERED INDEX cuq ON dbo.VA (pk);ERSTELLE EINZIGARTIGEN CLUSTERED INDEX cuq ON dbo.VB (pk);Jetzt können wir der gefilterten Datenspalte in der indizierten Ansicht eindeutige Nonclustered-Indizes hinzufügen:
EINZIGARTIGEN NICHT EINGESCHLOSSENEN INDEX IX AUF dbo.VA ERSTELLEN (Daten); EINZIGARTIGEN NICHT EINGESCHLOSSENEN INDEX IX AUF dbo.VB ERSTELLEN (Daten);Beachten Sie, dass die Filterung in der Ansicht durchgeführt wird, diese Nonclustered-Indizes selbst werden nicht gefiltert.
Der perfekte Plan
Wir sind jetzt bereit, unsere Abfrage mit
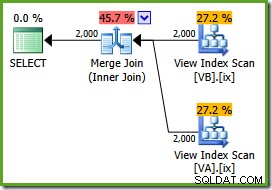
NOEXPANDfür die Ansicht auszuführen Tabellenhinweis:SELECT v.data, v2.dataFROM dbo.VA AS v WITH (NOEXPAND)JOIN dbo.VB AS v2 WITH (NOEXPAND) ON v.data =v2.data;Der Ausführungsplan lautet:
Der Optimierer kann das ungefilterte sehen Nonclustered View-Indizes sind eindeutig, sodass ein Many-to-Many-Merge-Join nicht erforderlich ist. Dieser endgültige Ausführungsplan hat geschätzte Kosten von 0,0310929 Einheiten – sogar niedriger als der Hash-Join-Plan (0,0772056 Einheiten). Dies bestätigt unsere Erwartung, dass ein Merge-Join die niedrigsten geschätzten Kosten für diese Abfrage und diesen Beispieldatensatz haben sollte.
Das
NOEXPANDHinweise werden sogar in der Enterprise Edition benötigt, um sicherzustellen, dass die Eindeutigkeitsgarantie, die von den Ansichtsindizes bereitgestellt wird, vom Optimierer verwendet wird.Zusammenfassung
Dieser Beitrag hebt zwei wichtige Einschränkungen des Optimierers bei gefilterten Indizes hervor:
- Redundante Join-Prädikate können erforderlich sein, um gefilterte Indizes abzugleichen
- Gefilterte eindeutige Indizes liefern dem Optimierer keine Eindeutigkeitsinformationen
In einigen Fällen kann es praktisch sein, die redundanten Prädikate einfach zu jeder Abfrage hinzuzufügen. Die Alternative besteht darin, die gewünschten impliziten Prädikate in einer nicht indizierten Ansicht zu kapseln. Der Hash-Match-Plan in diesem Beitrag war viel besser als der Standardplan, obwohl der Optimierer in der Lage sein sollte, den etwas besseren Merge-Join-Plan zu finden. Manchmal müssen Sie die Ansicht möglicherweise indizieren und NOEXPAND verwenden Hinweise (für Standard Edition-Instanzen ohnehin erforderlich). Unter noch anderen Umständen ist keiner dieser Ansätze geeignet. Tut mir leid :)