Für jede neue Datenbank, die in SQL Server erstellt wird, ist der Standardwert für die Option Statistik automatisch aktualisieren aktiviert . Ich vermute, dass die meisten DBAs die Option aktiviert lassen, da sie es dem Optimierer ermöglicht, Statistiken automatisch zu aktualisieren, wenn sie ungültig gemacht werden, und es wird im Allgemeinen empfohlen, sie aktiviert zu lassen. Statistiken werden auch aktualisiert, wenn Indizes neu erstellt werden, und obwohl es nicht ungewöhnlich ist, dass Statistiken über die Option zur automatischen Aktualisierung von Statistiken und durch Indexneuerstellungen gut verwaltet werden, kann es für einen DBA von Zeit zu Zeit erforderlich sein, einen regelmäßigen Job zum Aktualisieren von a einzurichten Statistik oder Satz von Statistiken.
Die benutzerdefinierte Verwaltung von Statistiken umfasst häufig den Befehl UPDATE STATISTICS, der ziemlich harmlos erscheint. Es kann für alle Statistiken für eine Tabelle oder indizierte Ansicht oder für eine bestimmte Statistik ausgeführt werden. Es kann die Standardstichprobe verwendet werden, eine bestimmte Stichprobenrate oder Anzahl der Zeilen für die Stichprobe kann angegeben werden, oder Sie können denselben Stichprobenwert verwenden, der zuvor verwendet wurde. Wenn Statistiken für eine Tabelle oder indizierte Sicht aktualisiert werden, können Sie wählen, ob Sie alle Statistiken, nur Indexstatistiken oder nur Spaltenstatistiken aktualisieren möchten. Und schließlich können Sie die Option zum automatischen Aktualisieren von Statistiken für eine Statistik deaktivieren.
Für die meisten DBAs ist das wann die größte Überlegung um die UPDATE STATISTICS-Anweisung auszuführen. Aber DBAs entscheiden auch bewusst oder unbewusst über die Stichprobengröße für die Aktualisierung. Die ausgewählte Stichprobengröße kann sich auf die Leistung der eigentlichen Aktualisierung sowie auf die Leistung von Abfragen auswirken.
Die Auswirkungen der Stichprobengröße verstehen
Die standardmäßige Stichprobengröße für UPDATE STATISTICS stammt von einem nichtlinearen Algorithmus, und die Stichprobengröße nimmt ab, wenn die Tabellengröße größer wird, wie Joe Sack in seinem Beitrag Auto-Update Stats Default Sampling Test gezeigt hat. In einigen Fällen ist die Stichprobengröße möglicherweise nicht groß genug, um genügend interessante Informationen zu erfassen, oder richtig Informationen für das Statistikhistogramm, wie von Conor Cunningham in seinem Post zu Statistik-Stichprobenraten angegeben. Wenn die Standardstichprobe kein gutes Histogramm erstellt, können DBAs wählen, Statistiken mit einer höheren Abtastrate zu aktualisieren, bis hin zu einem FULLSCAN (alle Zeilen in der Tabelle oder indizierten Ansicht werden gescannt). Aber wie Conor in seinem Beitrag erwähnte, ist das Scannen von mehr Zeilen mit Kosten verbunden, und der DBA steht vor der Herausforderung, zu entscheiden, ob er einen FULLSCAN ausführen soll, um zu versuchen, das „bestmögliche“ Histogramm zu erstellen, oder einen kleineren Prozentsatz abzutasten, um die Auswirkungen auf die Leistung zu minimieren das Update.
Um zu verstehen, wann ein Beispiel länger dauert als ein FULLSCAN, habe ich die folgenden Anweisungen mit Kopien der SalesOrderDetail-Tabelle ausgeführt, die mit dem Skript von Jonathan Kehayias vergrößert wurden:
| Anweisungs-ID | UPDATE STATISTICS-Anweisung |
|---|---|
| 1 | AKTUALISIEREN SIE STATISTIKEN [Verkäufe].[SalesOrderDetailEnlarged] WITH FULLSCAN; |
| 2 | STATISTIKEN AKTUALISIEREN [Verkäufe].[SalesOrderDetailEnlarged]; |
| 3 | STATISTIKEN AKTUALISIEREN [Verkäufe].[SalesOrderDetailEnlarged] MIT PROBE 10 PROZENT; |
| 4 | STATISTIKEN AKTUALISIEREN [Verkäufe].[SalesOrderDetailEnlarged] MIT PROBE 25 PROZENT; |
| 5 | STATISTIKEN AKTUALISIEREN [Verkäufe].[SalesOrderDetailEnlarged] MIT PROBE 50 PROZENT; |
| 6 | STATISTIK AKTUALISIEREN [Verkäufe].[SalesOrderDetailEnlarged] MIT PROBE 75 PROZENT; |
Ich hatte drei Kopien der SalesOrderDetailEnlarged-Tabelle mit den folgenden Merkmalen*:
| Zeilenzahl | Seitenzahl | MAXDOP | Max. Arbeitsspeicher | Speicherung | Maschine |
|---|---|---|---|---|---|
| 23.899.449 | 363.284 | 4 | 8 GB | SSD_1 | Laptop |
| 607.312.902 | 7.757.200 | 16 | 54 GB | SSD_2 | Testserver |
| 607.312.902 | 7.757.200 | 16 | 54 GB | 15K | Testserver |
*Weitere Details zur Hardware finden Sie am Ende dieses Beitrags.
Alle Kopien der Tabelle hatten die folgenden Statistiken, und keine der drei Indexstatistiken enthielt Spalten:
| Statistik | Typ | Spalten im Schlüssel |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Index | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Index | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Index | Produkt-ID |
| user_CarrierTrackingNumber | Spalte | CarrierTrackingNumber |
Ich habe die obigen UPDATE STATISTICS-Anweisungen jeweils viermal mit der SalesOrderDetailEnlarged-Tabelle auf meinem Laptop und jeweils zweimal mit den SalesOrderDetailEnlarged-Tabellen auf dem TestServer ausgeführt. Die Anweisungen wurden jedes Mal in zufälliger Reihenfolge ausgeführt, und der Prozedur-Cache und der Puffer-Cache wurden vor jeder Aktualisierungsanweisung gelöscht. Die Dauer und die tempdb-Nutzung für jeden Satz von Anweisungen (gemittelt) sind in den folgenden Diagrammen dargestellt:
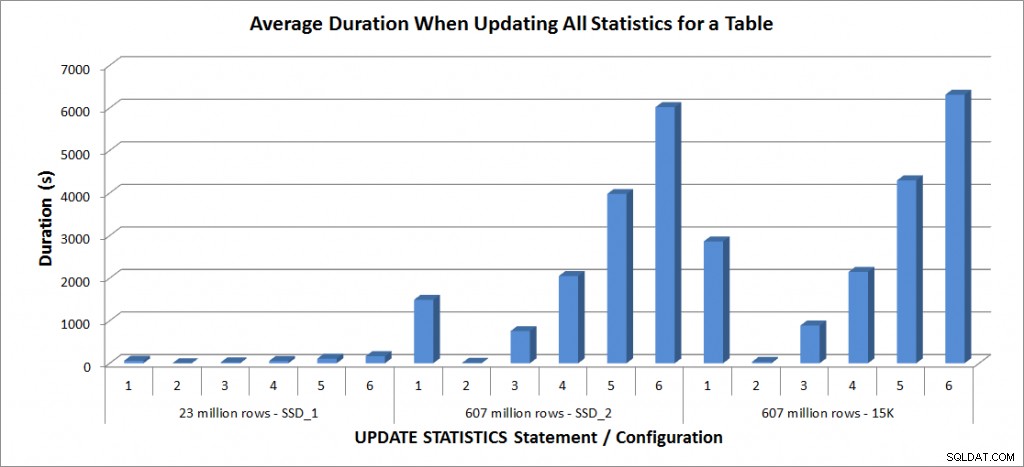
Durchschnittliche Dauer – Aktualisierung aller Statistiken für SalesOrderDetailEnlarged
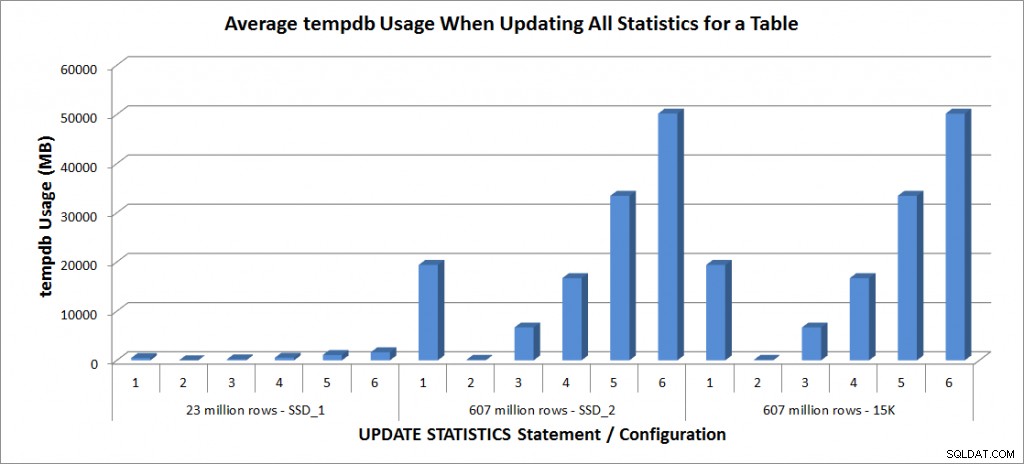
Tempdb-Nutzung – Alle Statistiken für SalesOrderDetailEnlarged aktualisieren
Die Dauern für die Tabelle mit 23 Millionen Zeilen betrugen alle weniger als drei Minuten und werden im nächsten Abschnitt ausführlicher beschrieben. Für die Tabelle auf den SSD_2-Platten dauerte die FULLSCAN-Anweisung 1492 Sekunden (fast 25 Minuten) und die Aktualisierung mit einer Stichprobe von 25 % dauerte 2051 Sekunden (über 34 Minuten). Im Gegensatz dazu dauerte die FULLSCAN-Anweisung auf den 15K-Platten 2864 Sekunden (über 47 Minuten) und die Aktualisierung mit einer Stichprobe von 25 % dauerte 2147 Sekunden (fast 36 Minuten) – weniger als die Zeit für FULLSCAN. Die Aktualisierung mit einer Stichprobe von 50 % dauerte jedoch 4296 Sekunden (mehr als 71 Minuten).
Die Verwendung von Tempdb ist viel konsistenter, zeigt einen stetigen Anstieg mit zunehmender Stichprobengröße und verwendet mehr Tempdb-Speicherplatz als ein FULLSCAN zwischen 25 % und 50 %. Was hier bemerkenswert ist, ist, dass UPDATE STATISTICS es tut verwenden tempdb, was wichtig ist, wenn Sie die Größe von tempdb für eine SQL Server-Umgebung anpassen. Die Verwendung von Tempdb wird im UPDATE STATISTICS BOL-Eintrag erwähnt:
UPDATE STATISTICS kann tempdb verwenden, um die Stichprobe von Zeilen zum Erstellen von Statistiken zu sortieren.“
Und der Effekt ist in Linchi Sheas Beitrag „Performance impact:tempdb and update statistics“ dokumentiert. Es wird jedoch nicht immer bei Diskussionen über die Größe von tempdb erwähnt. Wenn Sie große Tabellen haben und Aktualisierungen mit FULLSCAN oder hohen Beispielwerten durchführen, achten Sie auf die Verwendung von tempdb.
Durchführung ausgewählter Aktualisierungen
Als nächstes entschied ich mich, die UPDATE STATISTICS-Anweisungen für die anderen Statistiken in der Tabelle zu testen, beschränkte meine Tests jedoch auf die Kopie der Tabelle mit 23 Millionen Zeilen. Die obigen sechs Variationen der UPDATE STATISTICS-Anweisung wurden jeweils viermal für die folgenden einzelnen Statistiken wiederholt und dann mit der Aktualisierung für die gesamte Tabelle verglichen:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Alle Tests wurden mit der oben genannten Konfiguration auf meinem Laptop durchgeführt, und die Ergebnisse sind in der folgenden Grafik dargestellt:
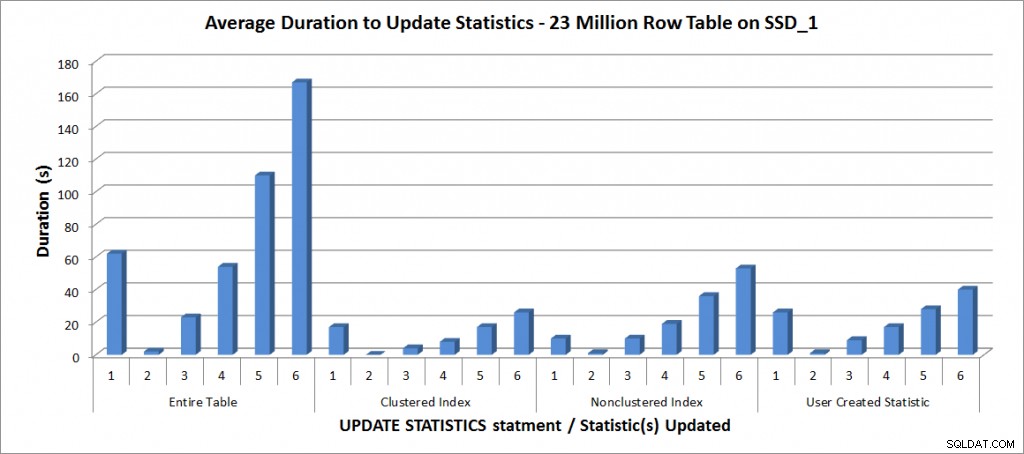
Durchschnittliche Dauer für UPDATE STATISTICS – All Statistics vs. Selected
Wie erwartet dauerte die Aktualisierung einer einzelnen Statistik weniger Zeit als die Aktualisierung aller Statistiken für die Tabelle. Der Wert, bei dem die Stichprobenaktualisierung länger dauerte als ein FULLSCAN, variierte:
| UPDATE-Anweisung | FULLSCAN-Dauer (s) | Erstes UPDATE, das länger gedauert hat |
|---|---|---|
| Gesamte Tabelle | 62 | 50 % – 110 Sekunden |
| Clustered-Index | 17 | 75 % – 26 Sekunden |
| Nicht gruppierter Index | 10 | 25 % – 19 Sekunden |
| Vom Benutzer erstellte Statistik | 26 | 50 % – 28 Sekunden |
Schlussfolgerung
Basierend auf diesen Daten und den FULLSCAN-Daten aus den 607 Millionen Zeilentabellen gibt es keine spezifische Wendepunkt, an dem ein gesampeltes Update länger dauert als ein FULLSCAN; Dieser Punkt hängt von der Tabellengröße und den verfügbaren Ressourcen ab. Aber die Daten sind immer noch wertvoll, da sie zeigen, dass es gibt ein Punkt, an dem die Erfassung eines abgetasteten Werts länger dauern kann als bei einem FULLSCAN. Es kommt wieder darauf an, Ihre Daten zu kennen. Dies ist nicht nur wichtig, um zu verstehen, ob eine Tabelle eine benutzerdefinierte Verwaltung von Statistiken erfordert, sondern auch um die ideale Stichprobengröße zu verstehen, um ein nützliches Histogramm zu erstellen und die Ressourcennutzung zu optimieren.
Spezifikationen
Laptop-Spezifikationen:Dell M6500, 1 Intel i7 (2,13 GHz 4 Kerne und HT ist aktiviert, also 8 logische Kerne), 32 GB Arbeitsspeicher, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), Datenbankdateien auf einer 265 GB Samsung SSD gespeichert PM810Testserver-Spezifikationen:Dell R720, 2 Intel E5-2670 (2,6 GHz 8 Kerne und HT ist aktiviert, also 16 logische Kerne pro Sockel), 64 GB Arbeitsspeicher, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), Datenbankdateien für Eine Tabelle befindet sich auf zwei 640-GB-Fusion-io-Duo-MLC-Karten, die Datenbankdateien für die andere Tabelle befinden sich auf neun Festplatten mit 15.000 U/min in einem RAID5-Array