Es gab viele Diskussionen über In-Memory OLTP (die Funktion, die früher als „Hekaton“ bekannt war) und wie sie bei sehr spezifischen, hochvolumigen Workloads helfen kann. Mitten in einem anderen Gespräch ist mir zufällig etwas im CREATE TYPE aufgefallen Dokumentation für SQL Server 2014, die mich denken ließ, dass es einen allgemeineren Anwendungsfall geben könnte:

Relativ leise und unangekündigte Ergänzungen zur CREATE TYPE-Dokumentation
Basierend auf dem Syntaxdiagramm scheint es, dass Tabellenwertparameter (TVPs) speicheroptimiert werden können, genau wie permanente Tabellen. Und damit drehten sich sofort die Räder.
Eine Sache, für die ich TVPs verwendet habe, ist, Kunden dabei zu helfen, teure String-Splitting-Methoden in T-SQL oder CLR zu eliminieren (siehe Hintergrund in früheren Posts hier, hier und hier). In meinen Tests übertraf die Verwendung eines regulären TVP äquivalente Muster mit CLR- oder T-SQL-Aufteilungsfunktionen um einen erheblichen Vorsprung (25–50 %). Ich habe mich logischerweise gefragt:Würde es einen Leistungsgewinn durch ein speicheroptimiertes TVP geben?
Es gab im Allgemeinen einige Bedenken gegenüber In-Memory-OLTP, da es viele Einschränkungen und Funktionslücken gibt, Sie eine separate Dateigruppe für speicheroptimierte Daten benötigen, Sie ganze Tabellen auf speicheroptimiert verschieben müssen und der beste Vorteil in der Regel besteht erreicht, indem auch nativ kompilierte gespeicherte Prozeduren erstellt werden (die ihre eigenen Einschränkungen haben). Wie ich demonstrieren werde, unter der Annahme, dass Ihr Tabellentyp einfache Datenstrukturen enthält (die z. B. eine Reihe von Ganzzahlen oder Zeichenfolgen darstellen), werden durch die Verwendung dieser Technologie nur für TVPs einige eliminiert dieser Probleme.
Der Test
Sie benötigen auch dann noch eine speicheroptimierte Dateigruppe, wenn Sie keine dauerhaften, speicheroptimierten Tabellen erstellen. Lassen Sie uns also eine neue Datenbank mit der entsprechenden Struktur erstellen:
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
Jetzt können wir einen regulären Tabellentyp erstellen, wie wir es heute tun würden, und einen speicheroptimierten Tabellentyp mit einem nicht gruppierten Hash-Index und einer Bucket-Anzahl, die ich aus der Luft gezogen habe (weitere Informationen zur Berechnung des Speicherbedarfs und der Bucket-Anzahl in die reale Welt hier):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Wenn Sie dies in einer Datenbank versuchen, die keine speicheroptimierte Dateigruppe hat, erhalten Sie diese Fehlermeldung, genau wie beim Versuch, eine normale speicheroptimierte Tabelle zu erstellen:
Nachricht 41337, Level 16, Status 0, Zeile 9Die Dateigruppe MEMORY_OPTIMIZED_DATA existiert nicht oder ist leer. Speicheroptimierte Tabellen können erst dann für eine Datenbank erstellt werden, wenn eine MEMORY_OPTIMIZED_DATA-Dateigruppe vorhanden ist, die nicht leer ist.
Um eine Abfrage mit einer regulären, nicht speicheroptimierten Tabelle zu testen, habe ich einfach einige Daten in eine neue Tabelle aus der AdventureWorks2012-Beispieldatenbank gezogen, indem ich SELECT INTO verwendet habe um all diese lästigen Beschränkungen, Indizes und erweiterten Eigenschaften zu ignorieren, erstellte ich dann einen gruppierten Index für die Spalte, von der ich wusste, dass ich suchen würde (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
Als Nächstes habe ich vier gespeicherte Prozeduren erstellt:zwei für jeden Tabellentyp; jeweils mit EXISTS und JOIN Herangehensweisen (normalerweise untersuche ich gerne beide, obwohl ich EXISTS bevorzuge; später werden Sie sehen, warum ich meine Tests nicht auf EXISTS beschränken wollte ). In diesem Fall weise ich einer Variablen lediglich eine beliebige Zeile zu, damit ich hohe Ausführungszahlen beobachten kann, ohne mich mit Ergebnismengen und anderen Ausgaben und Overheads befassen zu müssen:
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO
Als Nächstes musste ich die Art von Abfrage simulieren, die normalerweise auf diese Art von Tabelle stößt und überhaupt ein TVP oder ein ähnliches Muster erfordert. Stellen Sie sich ein Formular mit einem Dropdown-Menü oder einer Reihe von Kontrollkästchen vor, das eine Liste von Produkten enthält, und der Benutzer kann die 20 oder 50 oder 200 auswählen, die er vergleichen möchte, auflisten, was Sie haben. Die Werte werden nicht in einem schönen zusammenhängenden Satz sein; Sie werden normalerweise überall verstreut sein (wenn es sich um einen vorhersehbar zusammenhängenden Bereich handeln würde, wäre die Abfrage viel einfacher:Start- und Endwerte). Also habe ich einfach 20 willkürliche Werte aus der Tabelle ausgewählt (in dem Versuch, unter, sagen wir, 5 % der Tabellengröße zu bleiben), zufällig angeordnet. Eine einfache Möglichkeit, wiederverwendbare VALUES zu erstellen Klausel wie diese lautet wie folgt:
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; Die Ergebnisse (Ihre werden mit ziemlicher Sicherheit variieren):
(725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442), (450), (735). ),(441),(409),(454),(780),(966),(988),(512),
Im Gegensatz zu einem direkten INSERT...SELECT , dies macht es ziemlich einfach, diese Ausgabe in eine wiederverwendbare Anweisung zu manipulieren, um unsere TVPs wiederholt mit denselben Werten und in mehreren Testdurchläufen zu füllen:
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
Wenn wir diesen Batch mit dem SQL Sentry Plan Explorer ausführen, zeigen die resultierenden Pläne einen großen Unterschied:Das In-Memory-TVP kann einen Nested-Loop-Join und 20 einzeilige Clustered-Index-Suchvorgänge verwenden, im Vergleich zu einem Merge-Join, der 502 Zeilen speist ein Clustered-Index-Scan für das klassische TVP. Und in diesem Fall ergaben EXISTS und JOIN identische Pläne. Dies könnte bei einer viel höheren Anzahl von Werten kippen, aber lassen Sie uns mit der Annahme fortfahren, dass die Anzahl der Werte weniger als 5 % der Tabellengröße beträgt:
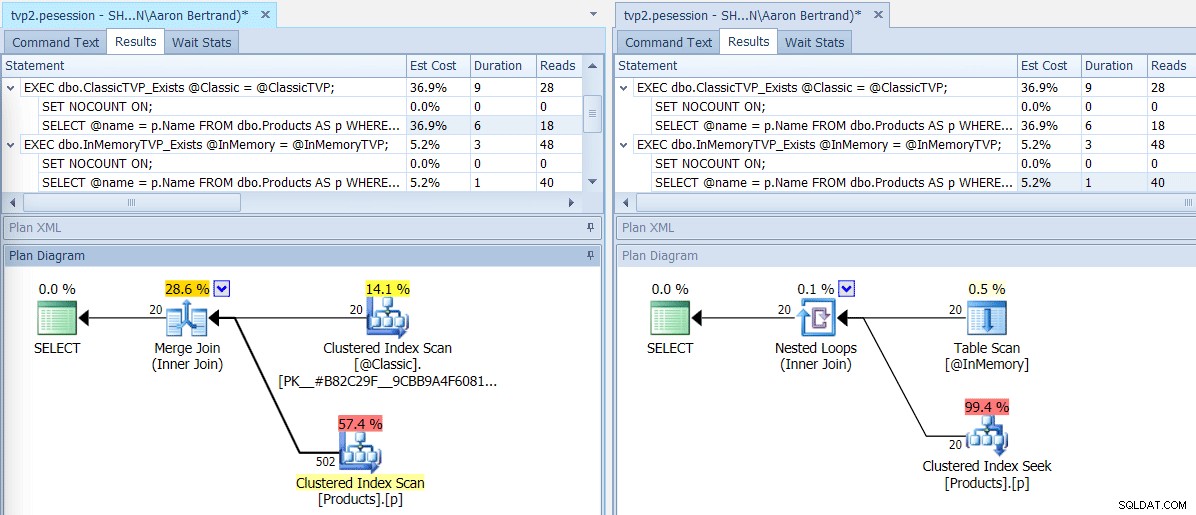 Pläne für klassische und In-Memory-TVPs
Pläne für klassische und In-Memory-TVPs
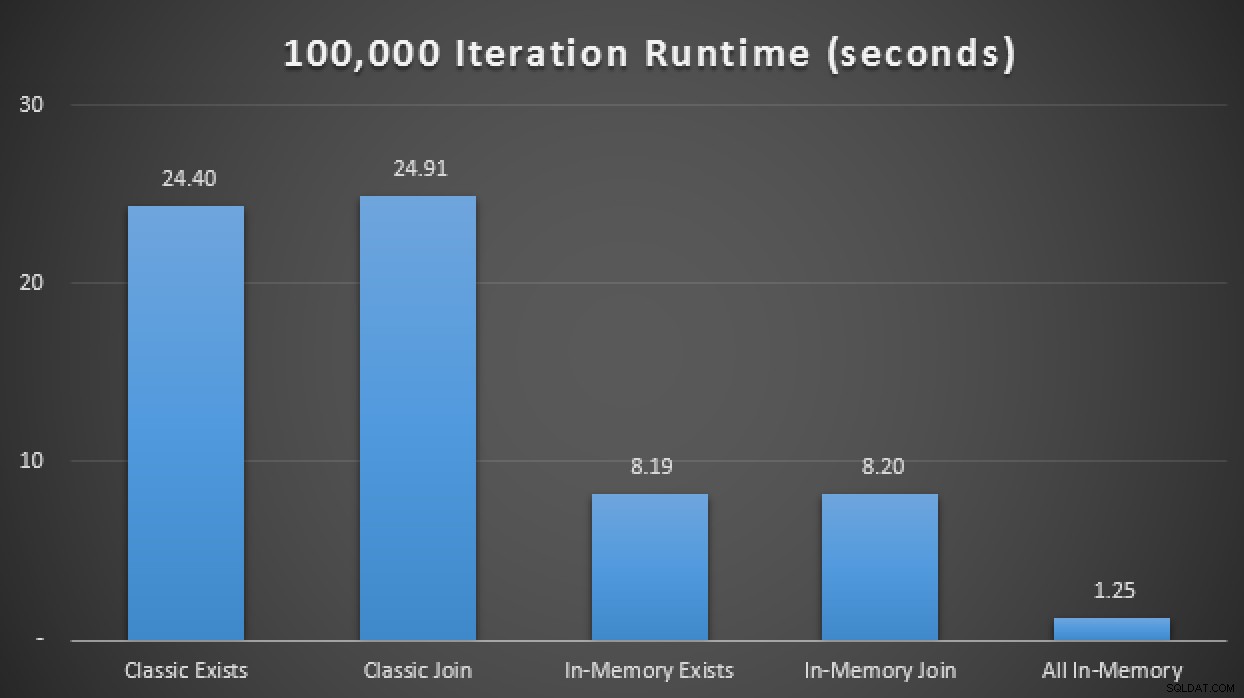 Tooltips für Scan-/Suchoperatoren, die die wichtigsten Unterschiede hervorheben – Klassisch links, In- Speicher rechts
Tooltips für Scan-/Suchoperatoren, die die wichtigsten Unterschiede hervorheben – Klassisch links, In- Speicher rechts
Was bedeutet das nun im Maßstab? Lassen Sie uns alle Showplan-Sammlungen deaktivieren und das Testskript leicht ändern, um jede Prozedur 100.000 Mal auszuführen und die kumulative Laufzeit manuell zu erfassen:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
SELECT SYSDATETIME(); In den über 10 Läufe gemittelten Ergebnissen sehen wir, dass zumindest in diesem begrenzten Testfall die Verwendung eines speicheroptimierten Tabellentyps eine ungefähr 3-fache Verbesserung der wohl kritischsten Leistungsmetrik in OLTP (Laufzeitdauer) ergab:
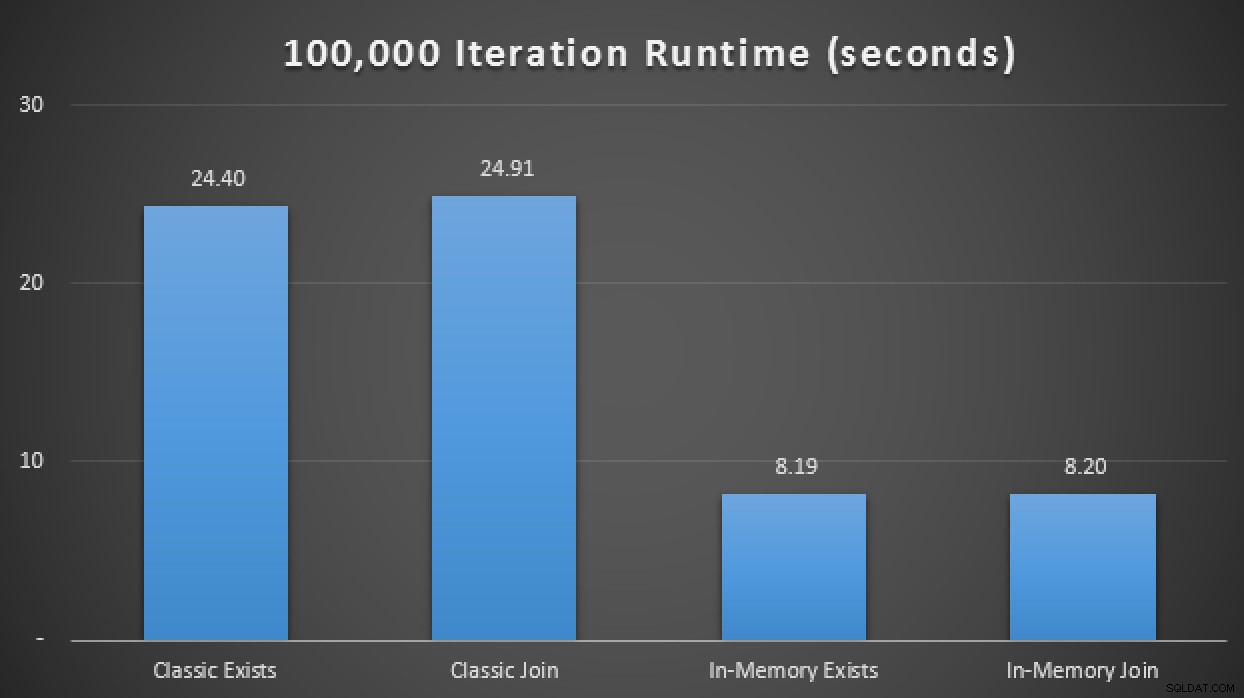
Laufzeitergebnisse zeigen eine 3-fache Verbesserung mit In-Memory-TVPs
In-Memory + In-Memory + In-Memory:In-Memory-Inception
Nachdem wir nun gesehen haben, was wir tun können, indem wir unseren regulären Tabellentyp einfach in einen speicheroptimierten Tabellentyp ändern, wollen wir sehen, ob wir aus demselben Abfragemuster noch mehr Leistung herausholen können, wenn wir das Trifecta anwenden:einen In-Memory table unter Verwendung einer nativ kompilierten speicheroptimierten gespeicherten Prozedur, die eine In-Memory-Tabelle table als Tabellenwertparameter akzeptiert.
Zuerst müssen wir eine neue Kopie der Tabelle erstellen und sie aus der bereits erstellten lokalen Tabelle füllen:
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
Als Nächstes erstellen wir eine nativ kompilierte gespeicherte Prozedur, die unseren vorhandenen speicheroptimierten Tabellentyp als TVP verwendet:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Ein paar Vorbehalte. Wir können keinen regulären, nicht speicheroptimierten Tabellentyp als Parameter für eine nativ kompilierte gespeicherte Prozedur verwenden. Wenn wir es versuchen, erhalten wir:
Msg 41323, Level 16, State 1, Procedure InMemoryProcedureDer Tabellentyp „dbo.ClassicTVP“ ist kein speicheroptimierter Tabellentyp und kann nicht in einer nativ kompilierten gespeicherten Prozedur verwendet werden.
Außerdem können wir den EXISTS nicht verwenden Muster hier entweder; Wenn wir es versuchen, erhalten wir:
Unterabfragen (in einer anderen Abfrage verschachtelte Abfragen) werden mit nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Es gibt viele andere Vorbehalte und Einschränkungen bei In-Memory-OLTP und nativ kompilierten gespeicherten Prozeduren. Ich wollte nur ein paar Dinge mitteilen, die bei den Tests offensichtlich zu fehlen scheinen.
Als ich diese neue nativ kompilierte gespeicherte Prozedur zur obigen Testmatrix hinzufügte, stellte ich fest, dass – wiederum gemittelt über 10 Läufe – die 100.000 Iterationen in nur 1,25 Sekunden ausgeführt wurden. Dies stellt eine ungefähr 20-fache Verbesserung gegenüber regulären TVPs und eine 6- bis 7-fache Verbesserung gegenüber In-Memory-TVPs dar, die herkömmliche Tabellen und Verfahren verwenden:
Laufzeitergebnisse zeigen eine bis zu 20-fache Verbesserung mit In-Memory rundum
Schlussfolgerung
Wenn Sie jetzt TVPs verwenden oder Muster verwenden, die durch TVPs ersetzt werden könnten, müssen Sie unbedingt erwägen, speicheroptimierte TVPs zu Ihren Testplänen hinzuzufügen, aber bedenken Sie, dass Sie möglicherweise nicht die gleichen Verbesserungen in Ihrem Szenario sehen. (Und natürlich sollte man bedenken, dass TVPs im Allgemeinen viele Vorbehalte und Einschränkungen haben und auch nicht für alle Szenarien geeignet sind. Erland Sommarskog hat hier einen großartigen Artikel über die heutigen TVPs.)
Tatsächlich sehen Sie vielleicht, dass es am unteren Ende von Lautstärke und Parallelität keinen Unterschied gibt – aber bitte testen Sie in einem realistischen Maßstab. Dies war ein sehr einfacher und erfundener Test auf einem modernen Laptop mit einer einzelnen SSD, aber wenn Sie über echtes Volumen und/oder drehende mechanische Festplatten sprechen, können diese Leistungsmerkmale viel mehr Gewicht haben. Es folgt ein Follow-up mit einigen Demonstrationen zu größeren Datenmengen.