In einem kürzlich erschienenen Tipp habe ich ein Szenario beschrieben, in dem eine SQL Server 2016-Instanz anscheinend mit Checkpoint-Zeiten zu kämpfen hatte. Das Fehlerprotokoll wurde mit einer alarmierenden Anzahl von FlushCache-Einträgen wie diesem gefüllt:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Ich war etwas perplex über dieses Problem, da das System sicherlich nicht träge war – viele Kerne, 3 TB Arbeitsspeicher und XtremIO-Speicher. Und keine dieser FlushCache-Meldungen wurde jemals mit den verräterischen 15-Sekunden-E/A-Warnungen im Fehlerprotokoll gepaart. Wenn Sie dort jedoch eine Reihe von Datenbanken mit vielen Transaktionen stapeln, kann die Checkpoint-Verarbeitung ziemlich träge werden. Nicht so sehr wegen der direkten Ein-/Ausgabe, sondern eher wegen der Abstimmung, die mit einer riesigen Anzahl schmutziger Seiten (nicht nur von committed) durchgeführt werden muss Transaktionen), die über eine so große Speichermenge verstreut sind und möglicherweise auf den Lazywriter warten (da es nur einen für die gesamte Instanz gibt).
Ich habe einige sehr wertvolle Posts schnell "aufgefrischt":
- Wie funktionieren Checkpoints und was wird protokolliert?
- Datenbankprüfpunkte (SQL Server)
- Was macht Checkpoint für tempdb?
- Jeden Tag ein SQL Server-DBA-Mythos:(15/30) Checkpoint schreibt nur Seiten von festgeschriebenen Transaktionen
- FlushCache-Meldungen sind möglicherweise keine tatsächlichen E/A-Blockierungen
- Indirect Checkpoint und tempdb – der gute, der schlechte und der unnachgiebige Scheduler
- Ändern Sie die Zielwiederherstellungszeit einer Datenbank
- Funktionsweise:Wann wird die FlushCache-Meldung zum SQL Server-Fehlerprotokoll hinzugefügt?
- Änderungen im Checkpoint-Verhalten von SQL Server 2016
- Zielwiederherstellungsintervall und indirekter Prüfpunkt – Neuer Standardwert von 60 Sekunden in SQL Server 2016
- SQL 2016 – Es läuft einfach schneller:Indirect Checkpoint Default
- SQL Server:großer Arbeitsspeicher und DB-Checkpointing
Ich entschied schnell, dass ich die Prüfpunktdauer für einige dieser problematischeren Datenbanken nachverfolgen wollte, bevor und nachdem ihr Zielwiederherstellungsintervall von 0 (die alte Methode) auf 60 Sekunden (die neue Methode) geändert wurde. Im Januar habe ich mir eine Sitzung für erweiterte Veranstaltungen von meiner Freundin und Kollegin Hannah Vernon ausgeliehen:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Ich habe den Zeitpunkt markiert, zu dem ich jede Datenbank geändert habe, und dann die Ergebnisse aus den Daten der erweiterten Ereignisse mithilfe einer im ursprünglichen Tipp veröffentlichten Abfrage analysiert. Die Ergebnisse zeigten, dass jede Datenbank nach dem Wechsel zu indirekten Checkpoints von Checkpoints mit durchschnittlich 30 Sekunden zu Checkpoints mit durchschnittlich weniger als einer Zehntelsekunde überging (und in den meisten Fällen auch weit weniger Checkpoints). Aus dieser Grafik gibt es viel zu entpacken, aber dies sind die Rohdaten, die ich verwendet habe, um meine Argumentation zu präsentieren (zum Vergrößern klicken):
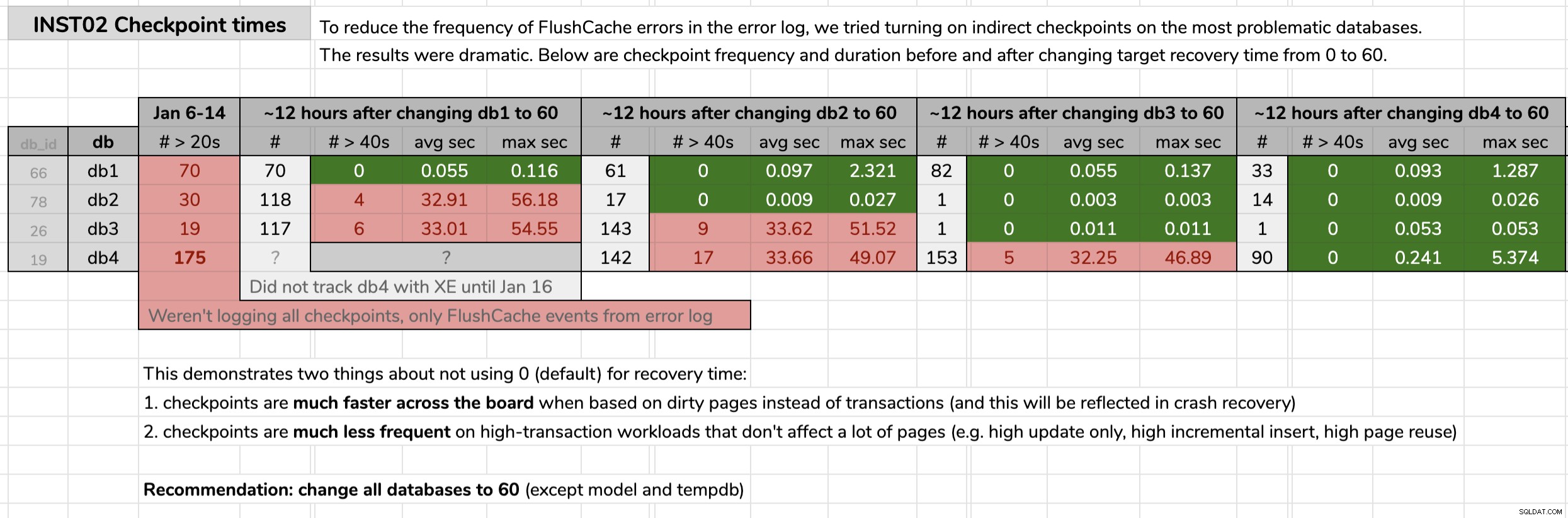 Meine Beweise
Meine Beweise
Nachdem ich meinen Fall in diesen problematischen Datenbanken bewiesen hatte, bekam ich grünes Licht, dies in allen unseren Benutzerdatenbanken in unserer gesamten Umgebung zu implementieren. Zuerst in der Entwicklung und dann in der Produktion habe ich Folgendes über eine CMS-Abfrage ausgeführt, um ein Maß dafür zu erhalten, über wie viele Datenbanken wir sprachen:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Einige Anmerkungen zur Abfrage:
database_id > 4
Ich wolltemasternicht anfassen überhaupt, und ich wolltetempdbnicht ändern Da wir uns jedoch nicht auf dem neuesten SQL Server 2017 CU befinden (siehe KB Nr. 4497928, sind diese Details aus einem Grund wichtig). Letzteres schließtmodelaus , da sich das Ändern des Modells auftempdbauswirken würde beim nächsten Failover / Neustart. Ich hättemsdbändern können , und ich werde vielleicht irgendwann darauf zurückkommen, aber mein Fokus lag hier auf Benutzerdatenbanken.
[state] / is_read_only / is_in_standby
Wir müssen sicherstellen, dass die Datenbanken, die wir ändern möchten, online und nicht schreibgeschützt sind (ich habe eine getroffen, die derzeit auf schreibgeschützt eingestellt war, und muss später darauf zurückkommen).
OUTER APPLY (...)
Wir möchten unsere Aktionen auf Datenbanken beschränken, die entweder die primäre in einer AG oder gar keine AG sind (und müssen auch verteilte AGs berücksichtigen, bei denen wir primär und lokal sein können, aber immer noch nicht beschreibbar sind). . Wenn Sie die Überprüfung zufällig auf einem sekundären Computer ausführen, können Sie das Problem dort nicht beheben, aber Sie sollten trotzdem eine Warnung erhalten. Danke an Erik Darling für die Hilfe bei dieser Logik und Taylor Martell für die Motivation zu Verbesserungen.
- Wenn Sie Instanzen haben, auf denen ältere Versionen wie SQL Server 2008 R2 ausgeführt werden (ich habe eine gefunden!), müssen Sie dies ein wenig optimieren, da die
target_recovery_time_in_secondsSpalte existiert dort nicht. In einem Fall musste ich dynamisches SQL verwenden, um dies zu umgehen, aber Sie könnten auch vorübergehend verschieben oder entfernen, wo diese Instanzen in Ihre CMS-Hierarchie fallen. Sie könnten auch nicht so faul sein wie ich und den Code in Powershell anstelle eines CMS-Abfragefensters ausführen, wo Sie Datenbanken mit einer beliebigen Anzahl von Eigenschaften einfach herausfiltern könnten, bevor Sie jemals auf Probleme bei der Kompilierung stoßen.
In der Produktion gab es 102 Instanzen (etwa die Hälfte) und insgesamt 1.590 Datenbanken mit der alten Einstellung. Alles war auf SQL Server 2017, also warum war diese Einstellung so weit verbreitet? Weil sie erstellt wurden, bevor indirekte Prüfpunkte in SQL Server 2016 zum Standard wurden. Hier ist ein Beispiel der Ergebnisse:
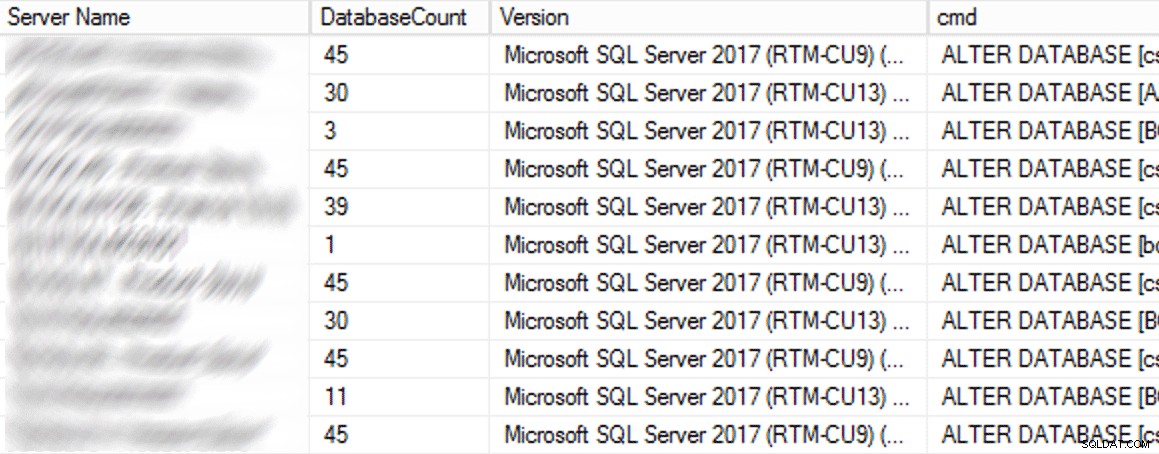 Teilergebnisse der CMS-Abfrage.
Teilergebnisse der CMS-Abfrage.
Dann habe ich die CMS-Abfrage erneut ausgeführt, diesmal mit sys.sp_executesql unkommentiert. Es dauerte ungefähr 12 Minuten, um dies über alle 1.590 Datenbanken hinweg auszuführen. Innerhalb einer Stunde erhielt ich bereits Berichte von Leuten, die einen erheblichen CPU-Einbruch bei einigen der ausgelasteten Instanzen beobachteten.
Ich habe noch mehr zu tun. Zum Beispiel muss ich die potenziellen Auswirkungen auf tempdb testen , und ob die Horrorgeschichten, die ich gehört habe, in unserem Anwendungsfall Gewicht haben. Und wir müssen sicherstellen, dass die 60-Sekunden-Einstellung Teil unserer Automatisierung und aller Anfragen zur Datenbankerstellung ist, insbesondere derjenigen, die per Skript erstellt oder aus Sicherungen wiederhergestellt werden.