Jeder Programmierer wird Ihnen sagen, dass das Schreiben von sicherem Multithread-Code schwierig sein kann. Es erfordert große Sorgfalt und ein gutes Verständnis für die technischen Probleme. Als Datenbankexperte denken Sie vielleicht, dass diese Art von Schwierigkeiten und Komplikationen beim Schreiben von T-SQL nicht auftreten. Daher mag es ein kleiner Schock sein, zu erkennen, dass T-SQL-Code auch anfällig für die Art von Race Conditions und anderen Datenintegritätsrisiken ist, die am häufigsten mit Multithread-Programmierung verbunden sind. Dies gilt unabhängig davon, ob es sich um eine einzelne T-SQL-Anweisung handelt oder um eine Gruppe von Anweisungen, die in einer expliziten Transaktion eingeschlossen sind.
Der Kern des Problems ist die Tatsache, dass Datenbanksysteme die gleichzeitige Ausführung mehrerer Transaktionen zulassen. Dies ist ein bekannter (und sehr wünschenswerter) Zustand, aber ein großer Teil des T-SQL-Produktionscodes geht immer noch stillschweigend davon aus, dass sich die zugrunde liegenden Daten während der Ausführung einer Transaktion oder einer einzelnen DML-Anweisung wie SELECT , INSERT , UPDATE , DELETE , oder MERGE .
Selbst wenn sich der Code-Autor der möglichen Auswirkungen gleichzeitiger Datenänderungen bewusst ist, wird zu oft angenommen, dass die Verwendung expliziter Transaktionen mehr Schutz bietet, als eigentlich gerechtfertigt ist. Diese Annahmen und Missverständnisse können subtil sein und sind sicherlich in der Lage, selbst erfahrene Datenbankpraktiker in die Irre zu führen.
Nun gibt es Fälle, in denen diese Probleme im praktischen Sinne keine große Rolle spielen. Beispielsweise könnte die Datenbank schreibgeschützt sein, oder es könnte eine andere echte Garantie vorliegen dass niemand sonst die zugrunde liegenden Daten ändert, während wir damit arbeiten. Ebenso darf die betreffende Operation nicht erfordern Ergebnisse, die genau sind Korrekt; Unsere Datenkonsumenten könnten mit einem ungefähren Ergebnis vollkommen zufrieden sein (selbst mit einem, das nicht den festgeschriebenen Zustand der Datenbank zu irgendeinem darstellt Zeitpunkt).
Parallelitätsprobleme
Die Frage der Interferenz zwischen gleichzeitig ausgeführten Aufgaben ist ein bekanntes Problem für Anwendungsentwickler, die in Programmiersprachen wie C# oder Java arbeiten. Die Lösungen sind zahlreich und vielfältig, beinhalten aber im Allgemeinen die Verwendung von atomaren Operationen oder eine sich gegenseitig ausschließende Ressource erhalten (z. B. eine Sperre ), während ein sensibler Vorgang ausgeführt wird. Wenn keine angemessenen Vorsichtsmaßnahmen getroffen werden, sind die wahrscheinlichen Ergebnisse beschädigte Daten, ein Fehler oder vielleicht sogar ein vollständiger Absturz.
Viele der gleichen Konzepte (z. B. atomare Operationen und Sperren) existieren in der Datenbankwelt, aber leider haben sie oft entscheidende Bedeutungsunterschiede . Die meisten Datenbankexperten kennen die ACID-Eigenschaften von Datenbanktransaktionen, wobei das A für atomar steht . SQL Server verwendet auch Sperren (und andere interne Geräte zum gegenseitigen Ausschluss). Keiner dieser Begriffe bedeutet genau das, was ein erfahrener C#- oder Java-Programmierer vernünftigerweise erwarten würde, und viele Datenbankprofis haben auch ein verwirrtes Verständnis dieser Themen (wie eine schnelle Suche mit Ihrer bevorzugten Suchmaschine bezeugen wird).
Um es noch einmal zu wiederholen:Manchmal sind diese Probleme kein praktisches Anliegen. Wenn Sie eine Abfrage schreiben, um die Anzahl der aktiven Bestellungen in einem Datenbanksystem zu zählen, wie wichtig ist es dann, wenn die Zählung etwas daneben liegt? Oder ob es den Zustand der Datenbank zu einem anderen Zeitpunkt widerspiegelt?
Es ist üblich, dass echte Systeme einen Kompromiss zwischen Parallelität und Konsistenz eingehen (auch wenn der Designer sich dessen damals nicht bewusst war – informiert). Kompromisse sind vielleicht ein selteneres Tier). Echte Systeme funktionieren oft gut genug , wobei Anomalien nur von kurzer Dauer sind oder als unwichtig angesehen werden. Ein Benutzer, der einen inkonsistenten Zustand auf einer Webseite sieht, löst das Problem oft, indem er die Seite aktualisiert. Wenn das Problem gemeldet wird, wird es höchstwahrscheinlich als nicht reproduzierbar geschlossen. Ich sage nicht, dass dies ein wünschenswerter Zustand ist, sondern erkenne nur an, dass es passiert.
Dennoch ist es enorm nützlich, Nebenläufigkeitsprobleme auf einer grundlegenden Ebene zu verstehen. Wenn wir uns ihrer bewusst sind, können wir richtig (oder informiert) schreiben richtig genug) T-SQL, wie es die Umstände erfordern. Noch wichtiger ist, dass es uns ermöglicht, das Schreiben von T-SQL zu vermeiden, das die logische Integrität unserer Daten gefährden könnte.
Aber SQL Server bietet ACID-Garantien!
Ja, aber sie sind nicht immer so, wie Sie es erwarten würden, und sie schützen nicht alles. Meistens lesen Menschen viel mehr in ACID hinein als gerechtfertigt ist.
Die am häufigsten missverstandenen Bestandteile des ACID-Akronyms sind die Worte Atomic, Consistent und Isolated – dazu kommen wir gleich noch. Der andere, langlebig , ist intuitiv genug, solange Sie sich daran erinnern, dass es nur für persistent gilt (wiederherstellbar) Benutzer Daten.
Trotz alledem beginnt SQL Server 2014 mit der Einführung der allgemeinen verzögerten Dauerhaftigkeit und der Nur-In-Memory-OLTP-Schema-Dauerhaftigkeit die Grenzen der Durable-Eigenschaft etwas zu verwischen. Ich erwähne sie nur der Vollständigkeit halber, wir werden diese neuen Features nicht weiter besprechen. Kommen wir zu den problematischeren ACID-Eigenschaften:
Das atomare Eigentum
Viele Programmiersprachen bieten atomare Operationen die zum Schutz vor Racebedingungen und anderen unerwünschten Nebenläufigkeitseffekten verwendet werden können, bei denen mehrere Ausführungsthreads auf gemeinsam genutzte Datenstrukturen zugreifen oder diese ändern können. Für den Anwendungsentwickler ist eine atomare Operation mit einer expliziten Garantie einer vollständigen Isolation verbunden vor den Auswirkungen anderer gleichzeitiger Verarbeitung in einem Multithread-Programm.
Eine analoge Situation ergibt sich in der Datenbankwelt, wo mehrere T-SQL-Abfragen gleichzeitig auf gemeinsam genutzte Daten (d. h. die Datenbank) von verschiedenen Threads zugreifen und diese ändern. Beachten Sie, dass wir hier nicht über parallele Abfragen sprechen; Gewöhnliche Singlethread-Abfragen werden routinemäßig so geplant, dass sie gleichzeitig innerhalb von SQL Server auf separaten Worker-Threads ausgeführt werden.
Leider ist die atomare Eigenschaft von SQL-Transaktionen garantiert nur, dass innerhalb einer Transaktion durchgeführte Datenänderungen als Einheit erfolgreich sind oder fehlschlagen . Nichts weiter als das. Es gibt sicherlich keine Garantie für vollständige Isolation von den Auswirkungen anderer gleichzeitiger Verarbeitung. Beachten Sie auch nebenbei, dass die atomare Transaktionseigenschaft nichts über Garantien bezüglich des Lesens aussagt Daten.
Einzelne Anweisungen
Es gibt auch nichts Besonderes an einer einzelnen Anweisung im SQL-Server. Wo eine explizit enthaltende Transaktion (BEGIN TRAN...COMMIT TRAN ) nicht vorhanden ist, wird dennoch eine einzelne DML-Anweisung innerhalb einer Autocommit-Transaktion ausgeführt. Dieselben ACID-Garantien gelten für eine einzelne Anweisung und dieselben Einschränkungen. Insbesondere enthält eine einzelne Anweisung keine besonderen Garantien dafür, dass Daten während der Verarbeitung nicht geändert werden.
Betrachten Sie die folgende Toy AdventureWorks-Abfrage:
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); Die Abfrage soll Informationen über die Bestellung anzeigen, die nach Menge an erster Stelle steht. Der Ausführungsplan lautet wie folgt:
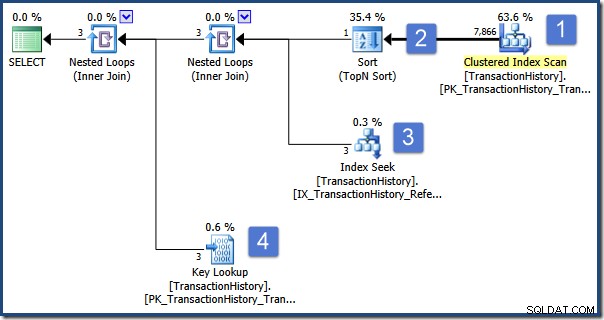
Die Hauptoperationen in diesem Plan sind:
- Durchsuchen Sie die Tabelle, um Zeilen mit dem erforderlichen Transaktionstyp zu finden
- Finden Sie die Bestell-ID, die gemäß der Spezifikation in der Unterabfrage am höchsten sortiert wird
- Suchen Sie die Zeilen (in derselben Tabelle) mit der ausgewählten Bestell-ID mithilfe eines nicht gruppierten Indexes
- Suchen Sie die verbleibenden Spaltendaten mit dem gruppierten Index
Stellen Sie sich nun vor, dass ein gleichzeitiger Benutzer die Bestellung 495 ändert, indem er den Transaktionstyp von P in W ändert und diese Änderung in die Datenbank überträgt. Glücklicherweise wird diese Änderung durchgeführt, während unsere Abfrage die Sortieroperation ausführt (Schritt 2).
Wenn die Sortierung abgeschlossen ist, findet die Indexsuche in Schritt 3 die Zeilen mit der ausgewählten Bestell-ID (die zufällig 495 ist) und die Schlüsselsuche in Schritt 4 ruft die verbleibenden Spalten aus der Basistabelle ab (wobei der Transaktionstyp jetzt W ist). .
Diese Abfolge von Ereignissen bedeutet, dass unsere Abfrage ein scheinbar unmögliches Ergebnis liefert:

Anstatt Aufträge mit Transaktionstyp P als angegebene Abfrage zu finden, zeigen die Ergebnisse Transaktionstyp W.
Die Ursache ist klar:Unsere Abfrage ging implizit davon aus, dass sich die Daten nicht ändern konnten, während unsere Abfrage mit einer einzelnen Anweisung ausgeführt wurde. Das Zeitfenster war in diesem Fall aufgrund der blockierenden Sortierung relativ groß, aber die gleiche Art von Race-Condition kann im Allgemeinen in jeder Phase der Abfrageausführung auftreten. Natürlich sind die Risiken in der Regel höher, wenn mehr gleichzeitige Änderungen vorgenommen werden, größere Tabellen vorhanden sind und Blockierungsoperatoren im Abfrageplan erscheinen.
Ein weiterer hartnäckiger Mythos im selben allgemeinen Bereich ist das MERGE ist gegenüber separatem INSERT zu bevorzugen , UPDATE und DELETE Anweisungen, da die Einzelanweisung MERGE ist atomar. Das ist natürlich Unsinn. Wir werden später in der Serie auf diese Argumentation zurückkommen.
Die allgemeine Botschaft an dieser Stelle ist, dass sich Datenzeilen und Indexeinträge jederzeit während des Ausführungsprozesses ändern, ihre Position verschieben oder vollständig verschwinden können, sofern nicht ausdrücklich Schritte unternommen werden, um etwas anderes sicherzustellen. Beim Schreiben von T-SQL-Abfragen sollte man sich gut ein Bild von ständigen und zufälligen Änderungen in der Datenbank machen.
Die Konsistenzeigenschaft
Auch das zweite Wort des ACID-Akronyms hat eine Reihe möglicher Interpretationen. In einer SQL Server-Datenbank bedeutet Konsistenz nur dass eine Transaktion die Datenbank in einem Zustand verlässt, der keine aktiven Einschränkungen verletzt. Es ist wichtig zu verstehen, wie begrenzt diese Aussage ist:Die einzigen ACID-Garantien für Datenintegrität und logische Konsistenz sind diejenigen, die durch aktive Einschränkungen bereitgestellt werden.
SQL Server stellt eine begrenzte Anzahl von Einschränkungen bereit, um die logische Integrität zu erzwingen, einschließlich PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE , und NOT NULL . Diese werden alle zum Zeitpunkt des Commit einer Transaktion garantiert erfüllt. Darüber hinaus garantiert SQL Server die physische Integrität der Datenbank natürlich jederzeit.
Die integrierten Einschränkungen reichen nicht immer aus, um alle Geschäfts- und Datenintegritätsregeln durchzusetzen, die wir uns wünschen. Es ist sicherlich möglich, mit den Standardeinrichtungen kreativ zu sein, aber diese werden schnell komplex und können dazu führen, dass doppelte Daten gespeichert werden.
Folglich enthalten die meisten realen Datenbanken zumindest einige T-SQL-Routinen, die geschrieben wurden, um zusätzliche Regeln durchzusetzen, beispielsweise in gespeicherten Prozeduren und Triggern. Die Verantwortung dafür, dass dieser Code korrekt funktioniert, liegt vollständig beim Autor – die Consistency-Eigenschaft bietet keinen besonderen Schutz.
Um den Punkt zu betonen, müssen in T-SQL geschriebene Pseudoeinschränkungen korrekt ausgeführt werden, unabhängig davon, welche gleichzeitigen Änderungen auftreten. Ein Anwendungsentwickler kann eine sensible Operation wie diese mit einer Sperranweisung schützen. Das, was T-SQL-Programmierer dieser Einrichtung für gefährdete gespeicherte Prozeduren und Triggercode am nächsten kommt, ist das vergleichsweise selten verwendete sp_getapplock System gespeicherte Prozedur. Das heißt nicht, dass es die einzige oder gar bevorzugte Option ist, sondern dass es existiert und unter bestimmten Umständen die richtige Wahl sein kann.
Die Isolationseigenschaft
Dies ist die am häufigsten missverstandene ACID-Transaktionseigenschaft.
Im Prinzip eine völlig isolierte Die Transaktion wird als einzige Aufgabe ausgeführt, die während ihrer Lebensdauer für die Datenbank ausgeführt wird. Andere Transaktionen können erst gestartet werden, wenn die aktuelle Transaktion vollständig abgeschlossen ist (d. h. festgeschrieben oder zurückgesetzt). Auf diese Weise ausgeführt, wäre eine Transaktion wirklich eine atomare Operation , im strengen Sinn, den ein Nicht-Datenbank-Mitarbeiter dem Ausdruck zuschreiben würde.
In der Praxis arbeiten Datenbanktransaktionen stattdessen mit einem Grad an Isolation angegeben durch die aktuell gültige Transaktionsisolationsstufe (die übrigens auch für eigenständige Anweisungen gilt). Dieser Kompromiss (das Grad Isolation) ist die praktische Konsequenz der zuvor erwähnten Kompromisse zwischen Parallelität und Korrektheit. Ein System, das Transaktionen buchstäblich einzeln verarbeitet, ohne zeitliche Überschneidungen, würde eine vollständige Isolierung bieten, aber der Gesamtsystemdurchsatz wäre wahrscheinlich schlecht.
Nächstes Mal
Der nächste Teil dieser Serie wird die Untersuchung von Parallelitätsproblemen, ACID-Eigenschaften und Transaktionsisolation mit einem detaillierten Blick auf die serialisierbare Isolationsstufe fortsetzen, ein weiteres Beispiel für etwas, das möglicherweise nicht das bedeutet, was Sie denken.
[Siehe den Index für die gesamte Serie]