Dies ist der letzte Teil einer fünfteiligen Serie, die einen tiefen Einblick in die Art und Weise gibt, wie parallele Pläne im Zeilenmodus von SQL Server ausgeführt werden. Teil 1 initialisierte den Ausführungskontext Null für die übergeordnete Aufgabe, und Teil 2 erstellte den Abfrage-Scan-Baum. Teil 3 startete den Abfrage-Scan, führte eine frühe Phase durch Verarbeitung und startete die ersten zusätzlichen parallelen Tasks in Zweig C. Teil 4 beschrieb die Austauschsynchronisierung und den Start der parallelen Planzweige C &D.
Zweig B parallele Aufgaben starten
Eine Erinnerung an die Zweige in diesem parallelen Plan (zum Vergrößern anklicken):
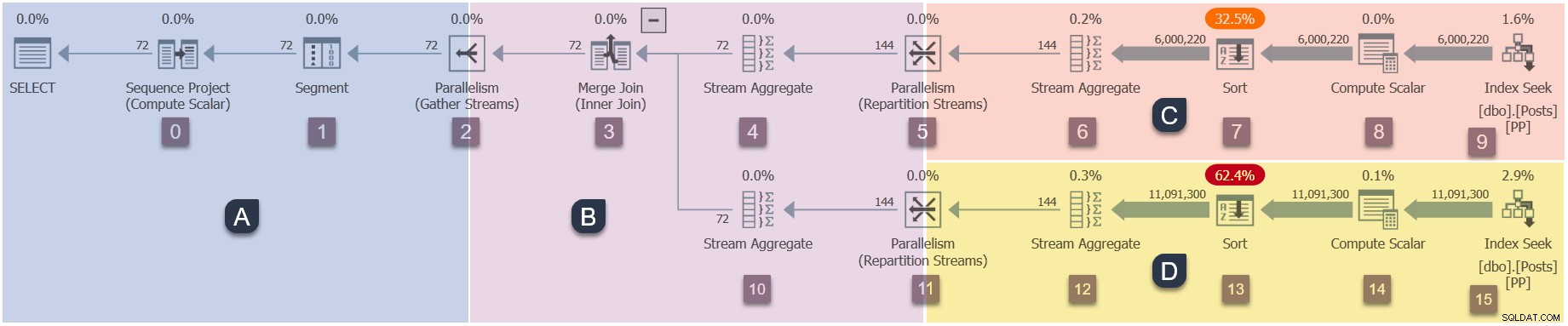
Dies ist die vierte Stufe in der Ausführungssequenz:
- Zweig A (übergeordnete Aufgabe).
- Zweig C (zusätzliche parallele Aufgaben).
- Zweig D (zusätzliche parallele Aufgaben).
- Zweig B (zusätzliche parallele Aufgaben).
Der einzige derzeit aktive Thread (nicht ausgesetzt auf CXPACKET ) ist die übergeordnete Aufgabe , das sich auf der Verbraucherseite des Repartition-Streams-Austauschs am Knoten 11 befindet in Zweig B:
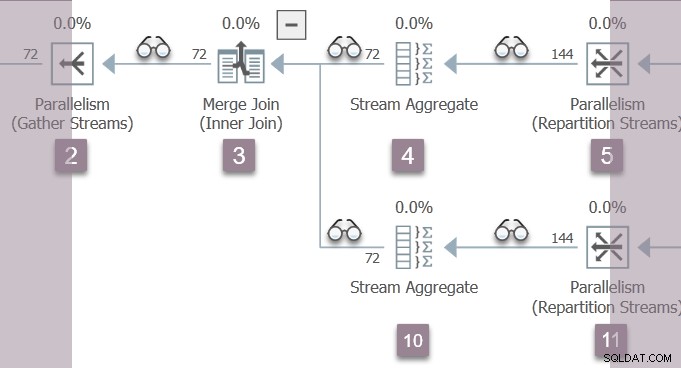
Die übergeordnete Aufgabe kehrt jetzt aus verschachtelten frühen Phasen zurück Aufrufe, Einstellen der verstrichenen und CPU-Zeiten in Profilern, während es geht. Erste und letzte aktive Zeit sind nicht während der Verarbeitung in der frühen Phase aktualisiert. Denken Sie daran, dass diese Zahlen für den Ausführungskontext Null aufgezeichnet werden – die parallelen Tasks von Branch B existieren noch nicht.
Die übergeordnete Aufgabe steigt auf den Baum von Knoten 11 über das Stream-Aggregat bei Knoten 10 und den Merge-Join bei Knoten 3 zurück zum Gather-Streams-Austausch bei Knoten 2.
Die Verarbeitung in der Frühphase ist jetzt abgeschlossen .
Mit den originalen EarlyPhases Aufruf am Knoten 2 Streams sammeln endlich austauschen abgeschlossen ist, kehrt die übergeordnete Aufgabe zum Öffnen dieses Austauschs zurück (vielleicht erinnern Sie sich noch genau an diesen Aufruf vom Anfang dieser Serie). Die offene Methode an Knoten 2 ruft jetzt CQScanExchangeNew::StartAllProducers auf um die parallelen Aufgaben zu erstellen für Filiale B.
Die übergeordnete Aufgabe jetzt wartet auf CXPACKET beim Verbraucher Seite des Knotens 2 Streams sammeln Austausch. Dieses Warten wird fortgesetzt, bis die neu erstellten Zweig-B-Tasks ihr verschachteltes Open abgeschlossen haben Aufrufe und kehrte zurück, um die Erzeugerseite des Gather-Streams-Austauschs vollständig zu öffnen.
Zweig B parallele Aufgaben geöffnet
Die beiden neuen parallelen Tasks in Zweig B beginnen beim Produzenten Seite des Knotens 2 Streams sammeln Austausch. Nach dem üblichen iterativen Ausführungsmodell im Zeilenmodus rufen sie auf:
CQScanXProducerNew::Open(Knoten 2 Erzeugerseite offen).CQScanProfileNew::Open(Profiler für Knoten 3).CQScanMergeJoinNew::Open(Knoten 3 Merge-Join).CQScanProfileNew::Open(Profiler für Knoten 4).CQScanStreamAggregateNew::Open(Stromaggregat von Knoten 4).CQScanProfileNew::Open(Profiler für Knoten 5).CQScanExchangeNew::Open(Repartition Streams Austausch).
Die parallelen Tasks folgen beide der äußeren (oberen) Eingabe für den Merge-Join, genau wie die Verarbeitung in der frühen Phase.
Austausch abschließen
Wenn die Tasks von Zweig B beim Verbraucher ankommen Seite der Repartitionsströme tauschen am Knoten 5 jede Aufgabe aus:
- Registriert sich beim Exchange-Port (
CXPort). - Erzeugt die Rohre (
CXPipe), die diese Aufgabe mit einer oder mehreren herstellerseitigen Aufgaben verbinden (abhängig von der Art des Austauschs). Der aktuelle Austausch ist ein Repartition-Stream, daher hat jede Verbraucheraufgabe zwei Pipes (bei DOP 2). Jeder Konsument kann Zeilen von einem der beiden Produzenten erhalten. - Fügt einen
CXPipeMergehinzu fusionieren Zeilen aus mehreren Pipes (da dies ein ordnungserhaltender Austausch ist). - Erzeugt Zeilenpakete (verwirrend benannt
CXPacket), die zur Flusskontrolle und zum Puffern von Reihen über die Austauschrohre verwendet werden. Diese werden aus dem zuvor gewährten Abfragespeicher zugewiesen.
Sobald beide verbraucherseitigen parallelen Tasks diese Arbeit abgeschlossen haben, ist die Vermittlung von Knoten 5 bereit zu gehen. Die beiden Consumer (in Branch B) und die beiden Producer (in Branch C) haben alle den Exchange-Port geöffnet, also den Knoten 5 CXPACKET wartet Ende .
Kontrollpunkt
Stand der Dinge:
- Die übergeordnete Aufgabe in Zweig A wartet auf
CXPACKETauf der Verbraucherseite des Knotens 2 sammeln Streams austauschen. Dieses Warten wird fortgesetzt, bis beide Erzeuger von Knoten 2 zurückkehren und den Austausch öffnen. - Die beiden parallelen Aufgaben in Zweig B sind lauffähig . Sie haben gerade die Consumer-Seite des Repartition Streams Exchange am Knoten 5 geöffnet.
- Die beiden parallelen Aufgaben in Zweig C wurden gerade von ihrem
CXPACKETveröffentlicht warten, und sind jetzt lauffähig . Die zwei Stream-Aggregate an Knoten 6 (einer pro paralleler Task) können mit dem Aggregieren von Zeilen aus den beiden Sortierungen an Knoten 7 beginnen. Erinnern Sie sich, dass die Indexsuchen an Knoten 9 vor einiger Zeit geschlossen wurden, als die Sortierungen ihre Eingabephase abgeschlossen haben. - Die zwei parallelen Aufgaben in Zweig D warten auf
CXPACKETauf der Erzeugerseite tauschen die Repartitionsströme am Knoten 11 aus. Sie warten darauf, dass die Verbraucherseite des Knotens 11 durch die beiden parallelen Tasks in Zweig B geöffnet wird. Die Indexsuchen wurden beendet, und die Sortierungen sind bereit für den Übergang ihre Ausgangsphase.
Mehrere aktive Branches
Dies ist das erste Mal, dass wir mehrere Zweige (B und C) gleichzeitig aktiv haben, was schwierig zu diskutieren sein könnte. Glücklicherweise ist das Design der Demo-Abfrage so, dass die Stream-Aggregate in Zweig C nur wenige Zeilen erzeugen. Die kleine Anzahl schmaler Ausgabezeilen passt leicht in die Zeilenpaket-Puffer am Knoten 5 tauschen die Verteilungsströme aus. Die Tasks von Zweig C können daher mit ihrer Arbeit fortfahren (und schließlich schließen), ohne darauf warten zu müssen, dass die Consumer-Seite der Neupartitionierungsströme von Knoten 5 irgendwelche Zeilen abruft.
Praktischerweise bedeutet dies, dass wir die beiden parallelen Tasks von Zweig C im Hintergrund laufen lassen können, ohne uns darum kümmern zu müssen. Wir brauchen uns nur darum zu kümmern, was die beiden parallelen Tasks von Zweig B tun.
Eröffnung von Filiale B abgeschlossen
Eine Erinnerung an Zweigstelle B:
Die beiden Parallelarbeiter in Filiale B kehren von ihrem Open zurück Aufrufe am Knoten 5 tauschen die Verteilungsströme aus. Dadurch werden sie durch das Stream-Aggregat an Knoten 4 zurück zum Merge-Join an Knoten 3 geführt.
Weil wir aufsteigen den Baum im Open -Methode zeichnen die Profiler über Knoten 5 und Knoten 4 zuletzt aktiv auf Zeit, sowie akkumulierte verstrichene und CPU-Zeiten (pro Task). Wir führen jetzt keine frühen Phasen der übergeordneten Aufgabe aus, daher sind die für den Ausführungskontext Null aufgezeichneten Zahlen nicht betroffen.
Beim Merge-Join beginnen die beiden parallelen Tasks von Zweig B abzusteigen die innere (untere) Eingabe, die sie durch das Stream-Aggregat am Knoten 10 (und ein paar Profiler) zur Verbraucherseite des Repartition-Streams-Austauschs am Knoten 11 führt.
Zweig D nimmt die Ausführung wieder auf
Eine Wiederholung der Verzweigungs-C-Ereignisse am Knoten 5 tritt nun an den Neupartitionierungsströmen des Knotens 11 auf. Die Verbraucherseite des Austauschs des Knotens 11 ist abgeschlossen und geöffnet. Die beiden Produzenten in Zweig D beenden ihr CXPACKET wartet und wird lauffähig wieder. Wir lassen die Zweig-D-Tasks im Hintergrund laufen und platzieren ihre Ergebnisse in Austauschpuffern.
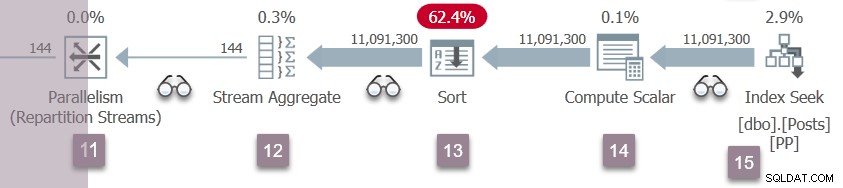
Es gibt jetzt sechs parallele Aufgaben (jeweils zwei in den Zweigen B, C und D), die sich kooperativ Zeit auf den beiden Schedulern teilen, die zusätzlichen parallelen Aufgaben in dieser Abfrage zugewiesen sind.
Eröffnung von Zweig A abgeschlossen
Die zwei parallelen Tasks in Zweig B kehren von ihrem Open zurück Aufrufe am Knoten 11 tauschen die Streams neu auf, über das Stream-Aggregat des Knotens 10 hinaus, durch den Merge-Join am Knoten 3 und zurück zur Erzeugerseite der Sammel-Streams bei Knoten 2. Profiler zuletzt aktiv und akkumulierte verstrichene &CPU-Zeiten werden aktualisiert, wenn wir den Baum in verschachteltem Open aufsteigen Methoden.
Beim Produzenten Seite des Gather-Streams-Austauschs synchronisieren die beiden parallelen Tasks von Branch B das Öffnen des Austausch-Ports und warten dann auf CXPACKET damit sich die Verbraucherseite öffnet.
Die übergeordnete Aufgabe Warten auf der Verbraucherseite der Gather-Streams ist jetzt freigegeben aus seinem CXPACKET warten, um das Öffnen des Austauschports auf der Verbraucherseite abzuschließen. Dies wiederum entbindet die Produzenten von ihrem (kurzen) CXPACKET warte ab. Der Sammelstrom des Knotens 2 wurde nun von allen Eigentümern geöffnet.
Abschließen des Abfragescans
Die übergeordnete Aufgabe Jetzt steigt der Abfrage-Scan-Baum vom Austausch der Sammelströme auf und kehrt vom Open zurück Anrufe an der Vermittlungsstelle, Segment und Sequenzprojekt Operatoren in Zweig A.
Damit ist das Öffnen abgeschlossen der Abfrage-Scan-Baum, der vor so langer Zeit durch den Aufruf von CQueryScan::StartupQuery initiiert wurde . Alle Zweige des parallelen Plans haben nun mit der Ausführung begonnen.
Zurückgegebene Zeilen
Der Ausführungsplan ist bereit, Zeilen als Antwort auf GetRow zurückzugeben Aufrufe an der Root des Abfragescanbaums, initiiert durch einen Aufruf von CQueryScan::GetRow . Ich werde nicht ins Detail gehen, da es den Rahmen eines Artikels darüber, wie parallele Pläne starten, eindeutig sprengen würde .
Dennoch ist die kurze Sequenz:
- Die übergeordnete Aufgabe ruft
GetRowauf im Sequenzprojekt, dasGetRowaufruft auf dem Segment, dasGetRowaufruft auf den Verbraucher Seite des Gather-Streams-Austauschs. - Wenn noch keine Zeilen am Austausch verfügbar sind, wartet die übergeordnete Aufgabe auf
CXCONSUMER. - In der Zwischenzeit haben die unabhängig laufenden parallelen Tasks von Zweig B rekursiv
GetRowaufgerufen beginnend beim Produzenten Seite des Gather-Streams-Austauschs. - Zeilen werden von den Verbraucherseiten der Verteilungsstromaustausche an den Knoten 5 und 12 an Zweig B geliefert.
- Zweige C und D verarbeiten immer noch Zeilen von ihren Sortierungen durch ihre jeweiligen Stream-Aggregate. Aufgaben von Zweig B müssen möglicherweise warten auf
CXCONSUMERBei der Neupartitionierung werden die Knoten 5 und 12 gestreamt, damit ein vollständiges Zeilenpaket verfügbar wird. - Zeilen, die aus dem verschachtelten
GetRowhervorgehen Anrufe in Zweig B werden beim Produzenten zu Zeilenpaketen zusammengesetzt Seite des Gather-Streams-Austauschs. - Der
CXCONSUMERder übergeordneten Aufgabe Warten auf der Consumer-Seite der Gather-Streams endet, wenn ein Paket verfügbar wird. - Eine Zeile nach der anderen wird dann durch die übergeordneten Operatoren in Branch A verarbeitet und schließlich an den Client weitergeleitet.
- Irgendwann gehen die Zeilen aus und ein verschachteltes
CloseDer Aufruf läuft den Baum hinunter, über die Börsen, und die parallele Ausführung geht zu Ende.
Zusammenfassung und Schlussbemerkungen
Zunächst eine Zusammenfassung der Ausführungsreihenfolge dieses speziellen parallelen Ausführungsplans:
- Die übergeordnete Aufgabe öffnet Zweig A . Frühphase Die Verarbeitung beginnt beim Gather-Streams-Exchange.
- Anrufe in der frühen Phase der übergeordneten Aufgabe steigen im Scan-Baum zur Indexsuche bei Knoten 9 ab und steigen dann zurück zum Neupartitionierungsaustausch bei Knoten 5.
- Die übergeordnete Aufgabe startet parallele Aufgaben für Zweig C , und wartet dann, während sie alle verfügbaren Zeilen in die blockierenden Sortieroperatoren am Knoten 7 einlesen.
- Aufrufe in der frühen Phase steigen zum Zusammenführungsjoin auf und steigen dann die innere Eingabe zum Austausch bei Knoten 11 ab.
- Aufgaben für Zweig D werden wie bei Branch C gestartet, während die Parent-Task am Knoten 11 wartet.
- Anrufe in der frühen Phase kehren vom Knoten 11 bis zu den Sammelströmen zurück. Die Frühphase endet hier.
- Die übergeordnete Aufgabe erstellt parallele Aufgaben für Zweig B , und wartet, bis die Öffnung von Zweig B abgeschlossen ist.
- Tasks von Zweig B erreichen die Repartitionsströme von Knoten 5, synchronisieren, schließen den Austausch ab und geben Tasks von Zweig C frei, um mit dem Aggregieren von Zeilen aus den Sortierungen zu beginnen.
- Wenn Tasks von Zweig B die Repartitionsströme von Knoten 12 erreichen, synchronisieren sie sich, schließen den Austausch ab und geben Tasks von Zweig D frei, um mit dem Aggregieren von Zeilen aus der Sortierung zu beginnen.
- Zweig-B-Tasks kehren zum Gathering-Streams-Austausch zurück und synchronisieren sich, wodurch die Elterntask aus ihrer Wartezeit entlassen wird. Die übergeordnete Aufgabe ist jetzt bereit, den Prozess der Rückgabe von Zeilen an den Client zu starten.
Vielleicht möchten Sie die Ausführung dieses Plans im Sentry One Plan Explorer verfolgen. Stellen Sie sicher, dass Sie die Option „Mit Live-Abfrageprofil“ der Ist-Plan-Erfassung aktivieren. Das Schöne an der Ausführung der Abfrage direkt im Plan Explorer ist, dass Sie in Ihrem eigenen Tempo durch mehrere Erfassungen gehen und sogar zurückspulen können. Es zeigt auch eine grafische Zusammenfassung von E/A, CPU und Wartezeiten, die mit den Profildaten der Live-Abfragen synchronisiert sind.
Zusätzliche Hinweise
Das Aufsteigen des Abfragescanbaums während der Verarbeitung in der frühen Phase legt erste und letzte aktive Zeiten bei jedem Profiling-Iterator für die übergeordnete Aufgabe fest, akkumuliert jedoch keine verstrichene Zeit oder CPU-Zeit. Aufsteigen des Baums während Open und GetRow ruft eine parallele Aufgabe auf, setzt die letzte aktive Zeit und akkumuliert die verstrichene Zeit und die CPU-Zeit bei jedem Profiling-Iterator pro Aufgabe.
Die Verarbeitung in der frühen Phase ist spezifisch für parallele Pläne im Zeilenmodus. Es muss sichergestellt werden, dass der Austausch in der richtigen Reihenfolge initialisiert wird und alle parallelen Maschinen ordnungsgemäß funktionieren.
Die Elterntask führt nicht immer die gesamte Frühphasenverarbeitung durch. Frühe Phasen beginnen bei einem Root-Austausch, aber wie diese Aufrufe durch den Baum navigieren, hängt von den angetroffenen Iteratoren ab. Ich habe mich für diese Demo für einen Merge-Join entschieden, weil er zufällig eine frühe Phasenverarbeitung für beide Eingaben erfordert.
Frühe Phasen (zum Beispiel) bei einem parallelen Hash-Join werden nur über die Build-Eingabe weitergegeben. Wenn der Hash-Join in seine Prüfphase übergeht, wird er geöffnet Iteratoren für diese Eingabe, einschließlich aller Austauschvorgänge. Eine weitere Runde der Frühphasenverarbeitung wird initiiert, die von (genau) einer der parallelen Tasks ausgeführt wird und die Rolle der übergeordneten Task spielt.
Wenn die Verarbeitung in der frühen Phase auf einen parallelen Zweig trifft, der einen blockierenden Iterator enthält, startet sie die zusätzlichen parallelen Aufgaben für diesen Zweig und wartet darauf, dass diese Produzenten ihre Eröffnungsphase abschließen. Dieser Zweig kann auch untergeordnete Zweige haben, die rekursiv auf die gleiche Weise behandelt werden.
Einige Verzweigungen in einem parallelen Plan im Zeilenmodus müssen möglicherweise auf einem einzelnen Thread ausgeführt werden (z. B. aufgrund eines globalen Aggregats oder Top). Diese „seriellen Zonen“ laufen auch auf einer zusätzlichen „parallelen“ Aufgabe, der einzige Unterschied besteht darin, dass es nur eine Aufgabe, einen Ausführungskontext und einen Arbeiter für diesen Zweig gibt. Die Verarbeitung in der frühen Phase funktioniert unabhängig von der Anzahl der einem Zweig zugewiesenen Aufgaben gleich. Beispielsweise meldet eine „serielle Zone“ die Zeiten für die übergeordnete Aufgabe (oder eine parallele Aufgabe, die diese Rolle spielt) sowie für die einzelne zusätzliche Aufgabe. Dies manifestiert sich in Showplan als Daten für „Thread 0“ (frühe Phasen) sowie „Thread 1“ (die zusätzliche Aufgabe).
Abschlussgedanken
All dies stellt sicherlich eine zusätzliche Komplexitätsebene dar. Die Rendite dieser Investition liegt in der Nutzung von Laufzeitressourcen (hauptsächlich Threads und Arbeitsspeicher), reduzierten Synchronisierungswartezeiten, erhöhtem Durchsatz, potenziell genauen Leistungsmetriken und einer minimierten Wahrscheinlichkeit paralleler Deadlocks innerhalb von Abfragen.
Obwohl die Zeilenmodus-Parallelität weitgehend von der moderneren Batch-Modus-Parallelausführungs-Engine in den Schatten gestellt wurde, hat das Zeilenmodus-Design immer noch eine gewisse Schönheit. Die meisten Iteratoren können so tun, als würden sie immer noch in einem seriellen Plan ausgeführt, wobei fast die gesamte Synchronisierung, Flusssteuerung und Planung von den Vermittlungsstellen übernommen wird. Die Sorgfalt und Aufmerksamkeit, die sich in Implementierungsdetails wie der Verarbeitung in der frühen Phase zeigt, ermöglicht es, selbst die größten parallelen Pläne erfolgreich auszuführen, ohne dass der Abfragedesigner zu viel über die praktischen Schwierigkeiten nachdenkt.