In meinem vorherigen Beitrag in dieser Reihe habe ich gezeigt, dass nicht alle Abfrageszenarien von In-Memory-OLTP-Technologien profitieren können. Tatsächlich kann sich die Verwendung von Hekaton in bestimmten Anwendungsfällen nachteilig auf die Leistung auswirken (zum Vergrößern klicken):

Profil der Leistungsüberwachung während der Ausführung gespeicherter Prozeduren
Allerdings hätte ich in diesem Szenario auf zwei Arten gegen Hekaton antreten können:
- Der von mir erstellte speicheroptimierte Tabellentyp hatte eine Bucket-Anzahl von 256, aber ich habe bis zu 2.000 Werte zum Vergleich übergeben. In einem neueren Blogbeitrag des SQL Server-Teams erklärten sie, dass eine Überdimensionierung der Bucket-Anzahl besser ist als eine Unterdimensionierung – etwas, das ich im Allgemeinen wusste, aber nicht erkannte, dass es auch erhebliche Auswirkungen auf Tabellenvariablen hatte:Keep Beachten Sie, dass für einen Hash-Index die Bucket_count etwa 1-2x die Anzahl der erwarteten eindeutigen Indexschlüssel betragen sollte. Überdimensionierung ist normalerweise besser als Unterdimensionierung:Wenn Sie manchmal nur 2 Werte in die Variablen einfügen, aber manchmal bis zu 1000 Werte einfügen, ist es normalerweise besser,
BUCKET_COUNT=1000anzugeben .Sie diskutieren den eigentlichen Grund dafür nicht explizit, und ich bin sicher, dass es viele technische Details gibt, in die wir uns vertiefen könnten, aber die vorgeschriebene Anleitung scheint zu überdimensioniert zu sein.
- Der Primärschlüssel war ein Hash-Index für zwei Spalten, während der Tabellenwertparameter nur versuchte, Werte in einer dieser Spalten abzugleichen. Ganz einfach bedeutete dies, dass der Hash-Index nicht verwendet werden konnte. Tony Rogerson erklärt dies etwas ausführlicher in einem kürzlich erschienenen Blogbeitrag:Der Hash wird über alle im Index enthaltenen Spalten generiert, Sie müssen auch alle Spalten im Hash-Index in Ihrem Gleichheitsprüfungsausdruck angeben, da sonst der Index nicht verwendet werden kann .
Ich habe es vorher nicht gezeigt, aber beachten Sie, dass der Plan für die speicheroptimierte Tabelle mit dem zweispaltigen Hash-Index tatsächlich einen Tabellenscan durchführt, anstatt die Indexsuche, die Sie vielleicht für den nicht gruppierten Hash-Index erwarten würden (da die führende Spalte war
SalesOrderID):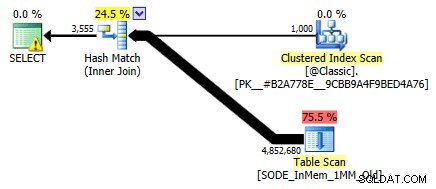
Abfrageplan mit einer In-Memory-Tabelle mit zwei Spalten Hash-IndexGenauer gesagt, in einem Hash-Index bedeutet die führende Spalte nicht einen Hügel von Bohnen für sich allein; der Hash wird immer noch über alle Spalten hinweg abgeglichen, also funktioniert er überhaupt nicht wie ein herkömmlicher B-Tree-Index (bei einem herkömmlichen Index könnte ein Prädikat, das nur die führende Spalte umfasst, immer noch sehr nützlich sein, um Zeilen zu eliminieren).
Was tun?
Nun, zuerst habe ich einen sekundären Hash-Index nur für die SalesOrderID erstellt Säule. Ein Beispiel für eine solche Tabelle mit einer Million Buckets:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Denken Sie daran, dass unsere Tabellentypen folgendermaßen eingerichtet sind:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Sobald ich die neuen Tabellen mit Daten gefüllt und eine neue gespeicherte Prozedur erstellt habe, um auf die neuen Tabellen zu verweisen, zeigt der Plan, den wir erhalten, korrekt eine Indexsuche gegen den einspaltigen Hash-Index:

Verbesserter Plan mit dem einspaltigen Hash-Index
Aber was würde das wirklich für die Leistung bedeuten? Ich habe die gleichen Tests noch einmal durchgeführt – Abfragen dieser Tabelle mit Bucket-Anzahlen von 16.000, 131.000 und 1 MM; Verwendung sowohl klassischer als auch In-Memory-TVPs mit 100, 1.000 und 2.000 Werten; und im Fall von In-Memory-TVP sowohl eine herkömmliche gespeicherte Prozedur als auch eine nativ kompilierte gespeicherte Prozedur. So verlief die Leistung bei 10.000 Iterationen pro Kombination:

Leistungsprofil für 10.000 Iterationen gegen einen einspaltigen Hash-Index, mit einem 256-Bucket-TVP
Sie denken vielleicht, hey, das Leistungsprofil sieht nicht so toll aus; im Gegenteil, es ist viel besser als mein vorheriger Test im letzten Monat. Es zeigt nur, dass die Bucket-Anzahl für die Tabelle einen großen Einfluss auf die Fähigkeit von SQL Server haben kann, den Hash-Index effektiv zu verwenden. In diesem Fall ist die Verwendung einer Bucket-Anzahl von 16.000 für keinen dieser Fälle eindeutig nicht optimal, und es wird exponentiell schlimmer, wenn die Anzahl der Werte im TVP zunimmt.
Denken Sie daran, dass die Bucket-Anzahl des TVP 256 betrug. Was würde also passieren, wenn ich dies gemäß den Anweisungen von Microsoft erhöhe? Ich habe einen zweiten Tabellentyp mit einer angemesseneren Bucket-Größe erstellt. Da ich 100, 1.000 und 2.000 Werte getestet habe, habe ich die nächste Potenz von 2 für die Bucket-Anzahl verwendet (2.048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Ich habe dafür unterstützende Prozeduren erstellt und die gleiche Reihe von Tests erneut durchgeführt. Hier sind die Leistungsprofile nebeneinander:

Leistungsprofilvergleich mit 256- und 2.048-Bucket-TVPs
Die Änderung der Bucket-Anzahl für den Tabellentyp hatte nicht die Auswirkungen, die ich angesichts der Microsoft-Anweisung zur Größenbestimmung erwartet hätte. Es hatte wirklich überhaupt keine positive Wirkung; Tatsächlich war es für einige Szenarien ein bisschen schlimmer. Aber insgesamt sind die Leistungsprofile in jeder Hinsicht gleich.
Was jedoch einen großen Effekt hatte, war die Erstellung des *richtigen* Hash-Index zur Unterstützung des Abfragemusters. Ich war dankbar, dass ich zeigen konnte, dass – trotz meiner vorherigen Tests, die etwas anderes anzeigten – eine In-Memory-Tabelle und ein In-Memory-TVP die alte Schule schlagen konnten, um dasselbe zu erreichen. Nehmen wir einfach den extremsten Fall aus meinem vorherigen Beispiel, als die Tabelle nur einen zweispaltigen Hash-Index hatte:

Leistungsprofil für 10 Iterationen gegen einen zweispaltigen Hash-Index
Der Balken ganz rechts zeigt die Dauer von nur 10 Iterationen des Abgleichs der nativen gespeicherten Prozedur mit einem unangemessenen Hash-Index – Abfragezeiten reichen von 735 bis 1.601 Millisekunden. Jetzt jedoch, mit dem richtigen Hash-Index, werden dieselben Abfragen in einem viel kleineren Bereich ausgeführt – von 0,076 Millisekunden bis 51,55 Millisekunden. Wenn wir den schlimmsten Fall (16K Bucket Counts) auslassen, ist die Diskrepanz noch ausgeprägter. In allen Fällen ist dies mindestens doppelt so effizient (zumindest in Bezug auf die Dauer) wie jede Methode ohne eine naiv kompilierte gespeicherte Prozedur für dieselbe speicheroptimierte Tabelle. und hundertmal besser als alle Ansätze gegenüber unserer alten speicheroptimierten Tabelle mit dem einzigen zweispaltigen Hash-Index.
Schlussfolgerung
Ich hoffe, ich habe gezeigt, dass bei der Implementierung von speicheroptimierten Tabellen jeglicher Art viel Sorgfalt geboten ist und dass in vielen Fällen die Verwendung eines speicheroptimierten TVP allein möglicherweise nicht den größten Leistungsgewinn bringt. Sie sollten erwägen, nativ kompilierte gespeicherte Prozeduren zu verwenden, um das Beste aus Ihrem Geld herauszuholen, und um die beste Skalierung zu erzielen, sollten Sie wirklich auf die Bucket-Anzahl für die Hash-Indizes in Ihren speicheroptimierten Tabellen achten (aber vielleicht nicht so viel Aufmerksamkeit für Ihre speicheroptimierten Tabellentypen).
Weitere Informationen zur In-Memory-OLTP-Technologie im Allgemeinen finden Sie in diesen Ressourcen:
- Der Blog des SQL Server-Teams (Tag:Hekaton und Tag:In-Memory OLTP – sind Codenamen nicht lustig?)
- Bob Beauchemins Blog
- Klaus Aschenbrenners Blog