In meinem letzten Beitrag ("Alter, wem gehört diese #temp-Tabelle?") habe ich vorgeschlagen, dass Sie in SQL Server 2012 und höher Extended Events verwenden könnten, um die Erstellung von #temp-Tabellen zu überwachen. Auf diese Weise können Sie bestimmte Objekte, die viel Platz in tempdb beanspruchen, mit der Sitzung korrelieren, die sie erstellt hat (z. B. um festzustellen, ob die Sitzung beendet werden könnte, um zu versuchen, den Speicherplatz freizugeben). Was ich nicht besprochen habe, ist der Overhead dieses Trackings – wir gehen davon aus, dass Extended Events leichter sind als Traces, aber kein Monitoring ist völlig kostenlos.
Da die meisten Leute den Standard-Trace aktiviert lassen, lassen wir das an Ort und Stelle. Wir testen beide Heaps mit SELECT INTO (die die Standardablaufverfolgung nicht erfasst) und Clustered-Indizes (was sie tun wird), und wir werden den Batch selbst als Baseline timen und den Batch dann erneut ausführen, während die Extended Events-Sitzung ausgeführt wird. Wir testen auch sowohl mit SQL Server 2012 als auch mit SQL Server 2014. Der Batch selbst ist ziemlich einfach:
SET NOCOUNT ON; SELECT SYSDATETIME(); GO -- run this portion for only the heap batch: SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #foo; -- run this portion for only the CIX batch: CREATE TABLE #bar(id INT PRIMARY KEY); INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #bar; GO 100000 SELECT SYSDATETIME();
Beide Instanzen haben tempdb mit vier Datendateien und mit aktiviertem TF 1117 und TF 1118 in einer VM mit vier CPUs, 16 GB Arbeitsspeicher und nur SSD konfiguriert. Ich habe absichtlich kleine #temp-Tabellen erstellt, um alle beobachteten Auswirkungen auf den Stapel selbst zu verstärken (die übertönt würden, wenn die Erstellung der #temp-Tabellen lange dauerte oder übermäßige automatische Wachstumsereignisse verursachte).
Ich habe diese Stapel in jedem Szenario ausgeführt, und hier sind die Ergebnisse, gemessen als Stapeldauer in Sekunden:
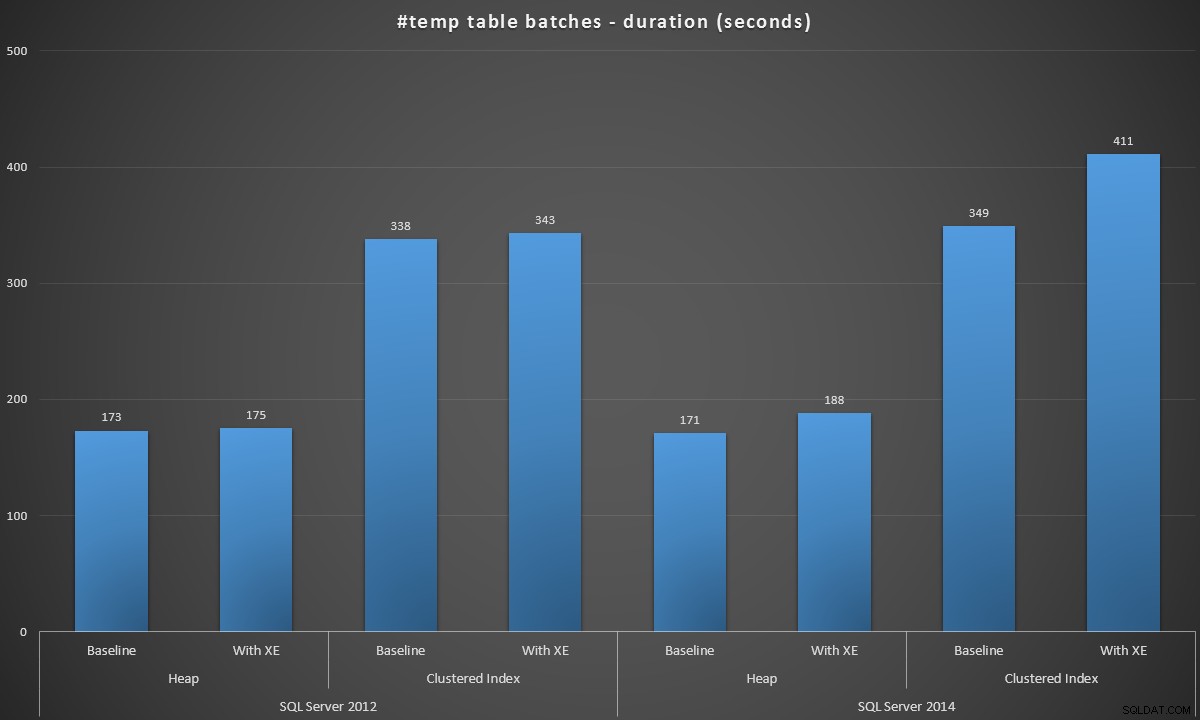
Batchdauer der Erstellung von 100.000 #temp-Tabellen
Etwas anders ausgedrückt:Wenn wir 100.000 durch die Dauer dividieren, können wir die Anzahl der #temp-Tabellen anzeigen, die wir pro Sekunde in jedem Szenario erstellen können (sprich:Durchsatz). Hier sind die Ergebnisse:
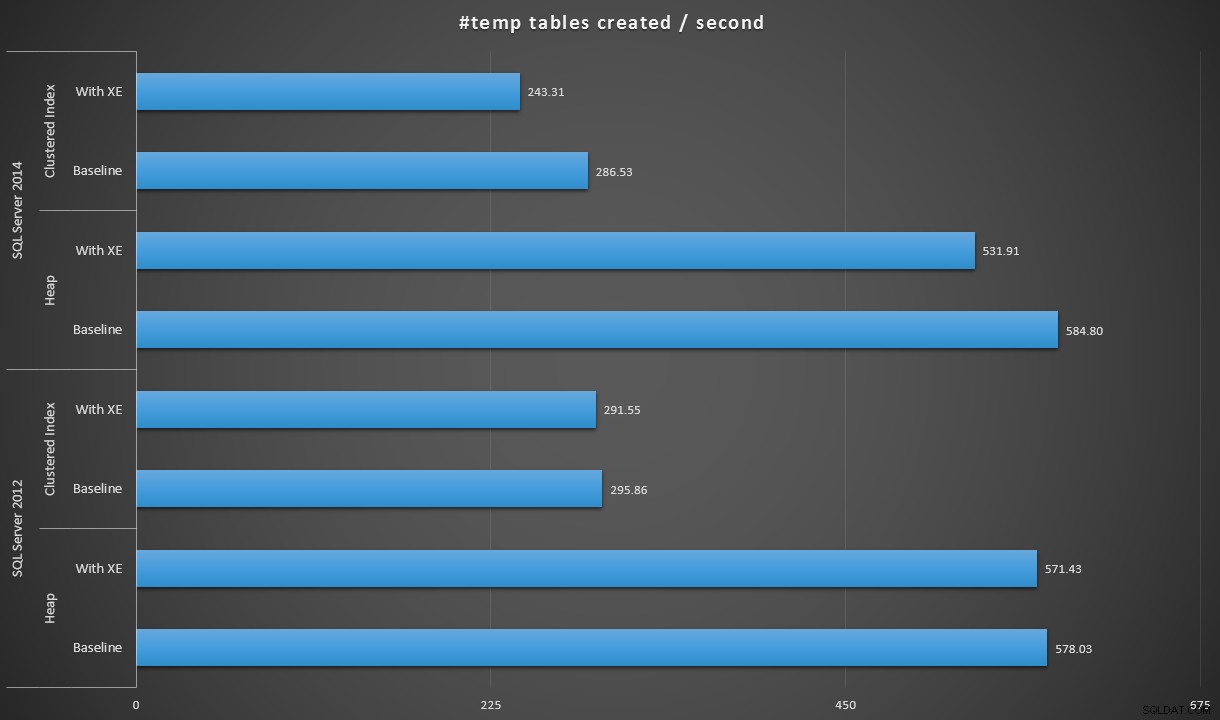
#temp-Tabellen, die pro Sekunde in jedem Szenario erstellt werden
Die Ergebnisse waren für mich etwas überraschend – ich hatte erwartet, dass mit den Verbesserungen der Eifer-Write-Logik von SQL Server 2014 zumindest die Heap-Population viel schneller laufen würde. Der Haufen im Jahr 2014 war zwei mickrige Sekunden schneller als 2012 bei der Grundkonfiguration, aber erweiterte Ereignisse haben die Zeit ziemlich in die Höhe getrieben (ungefähr eine Steigerung von 10 % gegenüber der Grundlinie); während die geclusterte Indexzeit vergleichbar mit 2012 an der Basislinie war, aber mit aktivierten erweiterten Ereignissen um fast 18 % anstieg. Im Jahr 2012 waren die Deltas für Heaps und Clustered-Indizes viel bescheidener – 1,1 % bzw. 1,5 %. (Und um es klarzustellen:Bei keinem der Tests traten Autogrow-Ereignisse auf.)
Also dachte ich, was wäre, wenn ich eine schlankere, gemeinere Extended Events-Sitzung erstellen würde? Sicherlich könnte ich einige dieser Aktionsspalten entfernen – vielleicht brauche ich nur den Anmeldenamen und die Spid und kann den App-Namen, den Hostnamen und den möglicherweise teuren sql_text ignorieren. Vielleicht könnte ich den zusätzlichen Filter gegen den Commit löschen (doppelt so viele Ereignisse sammeln, aber weniger CPU für das Filtern ausgeben) und den Verlust mehrerer Ereignisse zulassen, um die potenziellen Auswirkungen auf die Arbeitslast zu verringern. Diese schlankere Sitzung sieht so aus:
CREATE EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER
ADD EVENT sqlserver.object_created
(
ACTION
(
sqlserver.server_principal_name,
sqlserver.session_id
)
WHERE
(
sqlserver.like_i_sql_unicode_string([object_name], N'#%')
)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = 'c:\temp\TempTableCreation2014_LeanerMeaner.xel',
MAX_FILE_SIZE = 32768,
MAX_ROLLOVER_FILES = 10
)
WITH
(
EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
);
GO
ALTER EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER STATE = START; Leider nein, gleiche Ergebnisse. Etwas mehr als drei Minuten für den Heap und knapp sieben Minuten für den gruppierten Index. Um genauer zu untersuchen, wo die zusätzliche Zeit aufgewendet wurde, habe ich die Instanz von 2014 mit SQL Sentry beobachtet und nur den Clustered-Index-Batch ausgeführt, ohne dass Sitzungen mit erweiterten Ereignissen konfiguriert waren. Dann habe ich den Stapel erneut ausgeführt, diesmal mit der leichter konfigurierten XE-Sitzung. Die Batch-Zeiten waren 5:47 (347 Sekunden) und 6:55 (415 Sekunden) – also sehr ähnlich zum vorherigen Batch (ich war froh zu sehen, dass unsere Überwachung nicht weiter zur Dauer beigetragen hat :-)) . Ich habe bestätigt, dass keine Ereignisse verworfen wurden und dass keine Autogrow-Ereignisse aufgetreten sind.
Ich habe mir das SQL Sentry-Dashboard im Verlaufsmodus angesehen, wodurch ich schnell die Leistungsmetriken beider Batches nebeneinander anzeigen konnte:
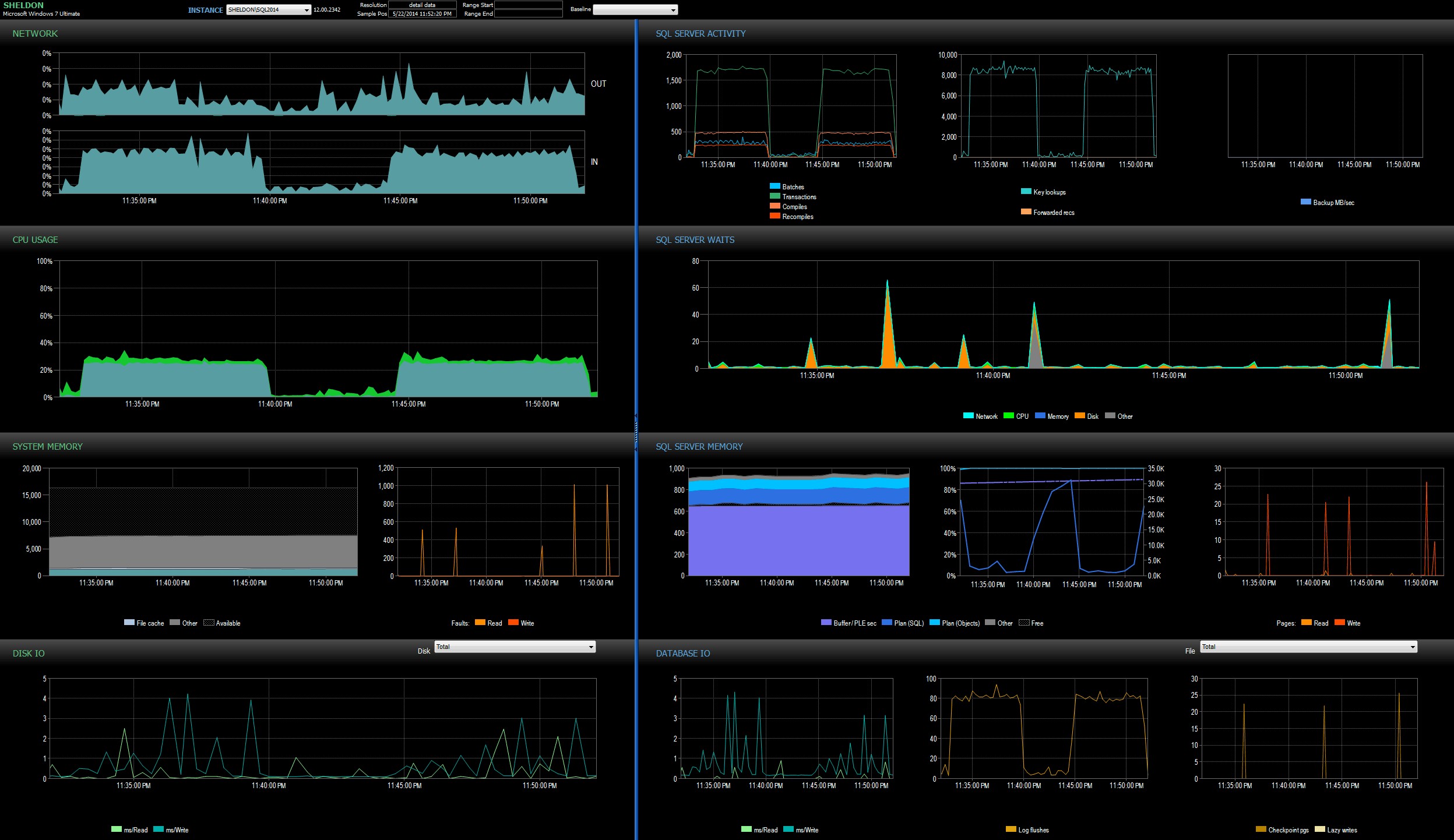
SQL Sentry-Dashboard im Verlaufsmodus, das beide Stapel anzeigt
Beide Batches waren in Bezug auf Netzwerk, CPU, Transaktionen, Kompilierungen, Schlüsselsuchen usw. praktisch identisch. Es gibt einen kleinen Unterschied bei den Waits – die Spitzen während des ersten Batches waren ausschließlich WRITELOG, während einige kleinere CXPACKET-Waits im zweiter Stapel. Meine Arbeitstheorie weit nach Mitternacht ist, dass vielleicht ein guter Teil der beobachteten Verzögerung auf Kontextwechsel zurückzuführen ist, die durch den Prozess der erweiterten Ereignisse verursacht wurden. Da wir weder genau wissen, was XE unter der Decke tut, noch wissen, welche zugrunde liegenden Mechanismen sich in XE zwischen 2012 und 2014 geändert haben, werde ich vorerst bei dieser Geschichte bleiben, bis ich es bin komfortabler mit xperf und/oder WinDbg.
Schlussfolgerung
Auf jeden Fall ist es klar, dass das Verfolgen der Erstellung von #temp-Tabellen nicht kostenlos ist und die Kosten je nach Typ der von Ihnen erstellten #temp-Tabellen, der Menge an Informationen, die Sie in Ihren XE-Sitzungen sammeln, und sogar der Version variieren können des von Ihnen verwendeten SQL Servers. Sie können also ähnliche Tests durchführen wie ich hier und entscheiden, wie wertvoll das Sammeln dieser Informationen in Ihrer Umgebung ist.