Es ist dieser Dienstag im Monat – wissen Sie, der, an dem die Blogger-Block-Party namens T-SQL Tuesday stattfindet. Diesen Monat wird es von Russ Thomas (@SQLJudo) moderiert und das Thema lautet:„Aufruf an alle Tuner und Gear Heads“. Ich werde hier ein leistungsbezogenes Problem behandeln, entschuldige mich jedoch dafür, dass es möglicherweise nicht vollständig mit den Richtlinien übereinstimmt, die Russ in seiner Einladung dargelegt hat (ich werde keine Hinweise, Trace-Flags oder Planleitfäden verwenden). .
Auf der SQLBits letzte Woche hielt ich eine Präsentation über Trigger, und mein guter Freund und MVP-Kollege Erland Sommarskog nahm zufällig daran teil. An einem Punkt habe ich vorgeschlagen, dass Sie vor dem Erstellen eines neuen Triggers für eine Tabelle prüfen sollten, ob bereits Trigger vorhanden sind, und in Betracht ziehen, die Logik zu kombinieren, anstatt einen zusätzlichen Trigger hinzuzufügen. Meine Gründe waren hauptsächlich die Wartbarkeit des Codes, aber auch die Leistung. Erland fragte, ob ich jemals getestet hätte, ob es einen zusätzlichen Overhead gäbe, wenn mehrere Auslöser für dieselbe Aktion ausgelöst würden, und ich musste zugeben, nein, ich hatte nichts Umfangreiches getan. Also werde ich das jetzt tun.
In AdventureWorks2014 habe ich einen einfachen Satz von Tabellen erstellt, die im Wesentlichen sys.all_objects darstellen (~2.700 Zeilen) und sys.all_columns (~9.500 Zeilen). Ich wollte die Auswirkungen verschiedener Ansätze zum Aktualisieren beider Tabellen auf die Arbeitslast messen – im Wesentlichen aktualisieren Benutzer die Spaltentabelle und verwenden einen Trigger, um eine andere Spalte in derselben Tabelle und einige Spalten in der Objekttabelle zu aktualisieren.
- T1:Ausgangswert :Angenommen, Sie können den gesamten Datenzugriff über eine gespeicherte Prozedur steuern. In diesem Fall können die Aktualisierungen für beide Tabellen direkt durchgeführt werden, ohne dass Trigger erforderlich sind. (Dies ist in der realen Welt nicht praktikabel, da Sie den direkten Zugriff auf die Tabellen nicht zuverlässig verbieten können.)
- T2:Einzelner Trigger gegen andere Tabelle :Angenommen, Sie können die Aktualisierungsanweisung für die betroffene Tabelle steuern und andere Spalten hinzufügen, aber die Aktualisierungen der sekundären Tabelle müssen mit einem Trigger implementiert werden. Wir aktualisieren alle drei Spalten mit einer Anweisung.
- T3:Einzelner Trigger gegen beide Tabellen :In diesem Fall haben wir einen Trigger mit zwei Anweisungen, eine, die die andere Spalte in der betroffenen Tabelle aktualisiert, und eine, die alle drei Spalten in der sekundären Tabelle aktualisiert.
- T4:Einzelner Trigger gegen beide Tabellen :Wie T3, aber dieses Mal haben wir einen Trigger mit vier Anweisungen, eine, die die andere Spalte in der betroffenen Tabelle aktualisiert, und eine Anweisung für jede Spalte, die in der sekundären Tabelle aktualisiert wird. Dies könnte der Fall sein, wenn die Anforderungen im Laufe der Zeit hinzugefügt werden und eine separate Anweisung im Hinblick auf Regressionstests als sicherer erachtet wird.
- T5:Zwei Auslöser :Ein Trigger aktualisiert nur die betroffene Tabelle; die andere verwendet eine einzelne Anweisung, um die drei Spalten in der sekundären Tabelle zu aktualisieren. Dies kann der Fall sein, wenn die anderen Auslöser nicht beachtet werden oder wenn deren Änderung verboten ist.
- T6:Vier Auslöser :Ein Trigger aktualisiert nur die betroffene Tabelle; die anderen drei aktualisieren jede Spalte in der sekundären Tabelle. Auch dies könnte der Fall sein, wenn Sie nicht wissen, dass die anderen Trigger existieren, oder wenn Sie aufgrund von Regressionsbedenken Angst haben, die anderen Trigger zu berühren.
Hier sind die Quelldaten, mit denen wir es zu tun haben:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Jetzt führen wir für jeden der 6 Tests unsere Updates 1.000 Mal aus und messen die Zeitdauer
T1:Ausgangswert
Dies ist das Szenario, in dem wir das Glück haben, Auslöser zu vermeiden (wiederum nicht sehr realistisch). In diesem Fall messen wir die Lesevorgänge und die Dauer dieses Stapels. Ich habe /*real*/ eingefügt in den Abfragetext, sodass ich die Statistiken für genau diese Anweisungen und nicht für Anweisungen innerhalb der Trigger abrufen kann, da die Metriken letztendlich zu den Anweisungen gezählt werden, die die Trigger aufrufen. Beachten Sie auch, dass die tatsächlichen Aktualisierungen, die ich vornehme, keinen Sinn ergeben, also ignorieren Sie, dass ich die Sortierung auf den Server-/Instanznamen und die principal_id des Objekts setze zur session_id der aktuellen Sitzung .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:Einzelauslöser
Dazu benötigen wir den folgenden einfachen Trigger, der nur dbo.src aktualisiert :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Dann muss unser Batch nur die beiden Spalten in der Primärtabelle aktualisieren:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:Einzelner Trigger gegen beide Tabellen
Für diesen Test sieht unser Trigger so aus:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Und jetzt muss der Batch, den wir testen, lediglich die ursprüngliche Spalte in der Primärtabelle aktualisieren; der andere wird vom Trigger behandelt:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:Einzelner Trigger gegen beide Tabellen
Dies ist genau wie T3, aber jetzt hat der Trigger vier Anweisungen:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Der Teststapel ist unverändert:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:Zwei Auslöser
Hier haben wir einen Trigger zum Aktualisieren der Primärtabelle und einen Trigger zum Aktualisieren der Sekundärtabelle:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Der Teststapel ist wieder sehr einfach:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Vier Auslöser
Dieses Mal haben wir einen Trigger für jede betroffene Spalte; eine in der primären Tabelle und drei in den sekundären Tabellen.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Und der Teststapel:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Auswirkungen der Workload messen
Schließlich habe ich eine einfache Abfrage für sys.dm_exec_query_stats geschrieben So messen Sie die Messwerte und die Dauer für jeden Test:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Ergebnisse
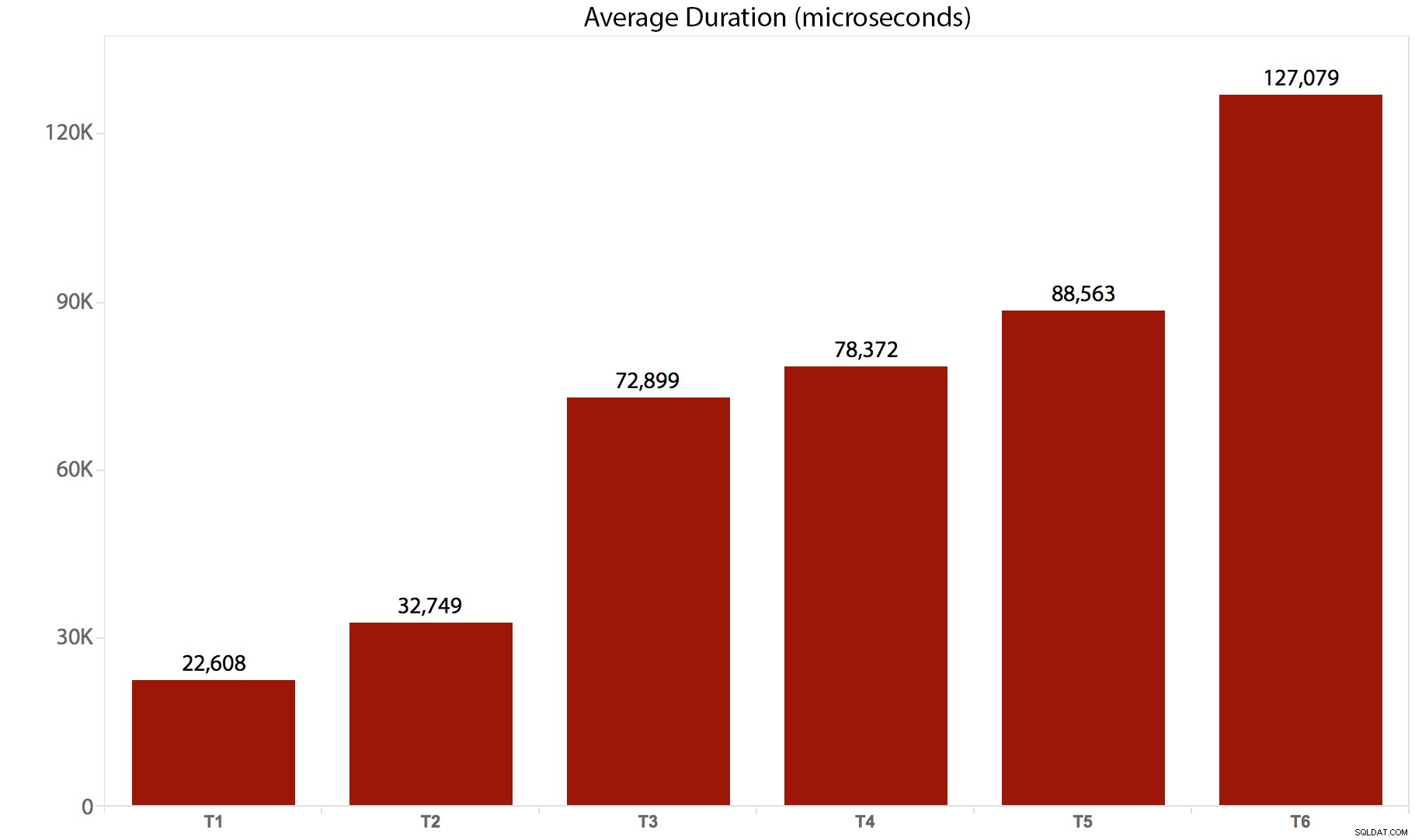
Ich habe die Tests 10 Mal durchgeführt, die Ergebnisse gesammelt und alles gemittelt. So brach es zusammen:
| Test/Batch | Durchschnittliche Dauer (Mikrosekunden) | Gesamtlesevorgänge (8.000 Seiten) |
|---|---|---|
| T1 :UPDATE /*real*/ dbo.tr1 … | 22.608 | 205.134 |
| T2 :UPDATE /*real*/ dbo.tr2 … | 32.749 | 11.331.628 |
| T3 :UPDATE /*real*/ dbo.tr3 … | 72.899 | 22.838.308 |
| T4 :UPDATE /*real*/ dbo.tr4 … | 78.372 | 44.463.275 |
| T5 :UPDATE /*real*/ dbo.tr5 … | 88.563 | 41.514.778 |
| T6 :UPDATE /*real*/ dbo.tr6 … | 127.079 | 100.330.753 |
Und hier ist eine grafische Darstellung der Dauer:
Schlussfolgerung
Es ist klar, dass in diesem Fall für jeden Trigger, der aufgerufen wird, ein erheblicher Overhead anfällt – alle diese Stapel wirkten sich letztendlich auf dieselbe Anzahl von Zeilen aus, aber in einigen Fällen wurden dieselben Zeilen mehrmals berührt. Ich werde wahrscheinlich weitere Folgetests durchführen, um den Unterschied zu messen, wenn dieselbe Zeile nie mehr als einmal berührt wird – ein komplizierteres Schema vielleicht, bei dem jedes Mal 5 oder 10 andere Tabellen berührt werden müssen, und diese unterschiedlichen Aussagen könnten sein in einem einzigen Trigger oder in mehreren. Ich vermute, dass die Overhead-Unterschiede eher durch Dinge wie Parallelität und die Anzahl der betroffenen Zeilen als durch den Overhead des Triggers selbst verursacht werden – aber wir werden sehen.
Möchten Sie die Demo selbst ausprobieren? Laden Sie das Skript hier herunter.