Gastautor:Andy Mallon (@AMtwo)
Nein, ernsthaft. Was ist eine DTU?
Wenn Sie eine Anwendung bereitstellen, lautet eine der ersten Fragen, die auftauchen:„Was wird das kosten?“. Die meisten von uns haben diese Art von Übung zur Dimensionierung einer SQL Server-Installation irgendwann durchlaufen, aber was ist, wenn Sie in der Cloud bereitstellen? Bei Azure IaaS-Bereitstellungen hat sich nicht viel geändert – Sie bauen immer noch einen Server basierend auf der CPU-Anzahl, einer gewissen Menge an Arbeitsspeicher und konfigurieren Speicher, um Ihnen genügend IOPS für Ihre Workload bereitzustellen. Wenn Sie jedoch zu PaaS wechseln, wird Azure SQL-Datenbank mit unterschiedlichen Dienstebenen dimensioniert, wobei die Leistung in DTUs gemessen wird. Was zum Teufel ist eine DTU?
Ich weiß, was ein BTU ist. Vielleicht steht DTU für Database Thermal Unit? Ist es die Menge an Rechenleistung, die benötigt wird, um die Temperatur des Rechenzentrums um ein Grad zu erhöhen? Anstatt zu raten, sehen wir uns die Dokumentation an und sehen, was Microsoft zu sagen hat:
Eine [Database Transaction Unit] ist ein kombiniertes Maß aus CPU, Arbeitsspeicher und Daten-E/A und Transaktionsprotokoll-E/A in einem Verhältnis, das durch eine OLTP-Benchmark-Workload bestimmt wird, die typisch für reale OLTP-Workloads ist. Das Verdoppeln der DTUs durch Erhöhen des Leistungsniveaus einer Datenbank entspricht dem Verdoppeln des Ressourcensatzes, der dieser Datenbank zur Verfügung steht.OK, das war meine zweite Vermutung – aber was ist das „gemischte Maß“? Wie kann ich mein Wissen über die Dimensionierung eines Servers in die Dimensionierung einer Azure SQL-Datenbank übersetzen? Leider gibt es keine einfache Möglichkeit, „2 CPU-Kerne und 4 GB Arbeitsspeicher“ in eine DTU-Messung zu übersetzen.
Gibt es keinen DTU-Rechner?
Ja! Microsoft stellt uns einen DTU-Rechner zur Schätzung zur Verfügung die richtige Dienstebene von Azure SQL-Datenbank. Um es zu verwenden, laden Sie ein PowerShell-Skript (sql-perfmon.ps1) herunter und führen es auf dem Server aus, während Sie eine Arbeitslast in SQL Server ausführen. Das Skript gibt eine CSV-Datei aus, die vier Leistungsindikatoren enthält:(1) Gesamtprozessorzeit in %, (2) Gesamtzahl der Festplattenlesevorgänge/Sekunde, (3) Gesamtzahl der Festplattenschreibvorgänge pro Sekunde und (4) Gesamtzahl geleerter Protokollbytes/Sekunde. Diese CSV-Ausgabe wird dann in den DTU-Rechner hochgeladen, der schätzt, welche Dienstebene Ihren Anforderungen am besten entspricht. Die einzigen Daten, die der DTU-Rechner zusätzlich zur CSV-Datei übernimmt, ist die Anzahl der CPU-Kerne auf dem Server, der die Datei generiert hat. Der DTU-Rechner ist immer noch eine Art Blackbox – es ist nicht einfach, das, was wir aus unseren lokalen Datenbanken wissen, in Azure abzubilden.
Ich möchte darauf hinweisen, dass die Definition einer DTU lautet, dass es sich um „ein gemischtes Maß aus CPU, Speicher“ handelt , und Daten-E/A und Transaktionsprotokoll-E/A…" Keiner der vom DTU-Rechner verwendeten Leistungsindikatoren berücksichtigt den Arbeitsspeicher, aber er wird in der Definition eindeutig als Teil der Berechnung aufgeführt. Dies ist nicht unbedingt a Problem, aber es ist ein Beweis dafür, dass der DTU-Rechner nicht perfekt sein wird.
Ich werde eine synthetische Last in den DTU-Rechner hochladen und sehen, ob ich herausfinden kann, wie diese Blackbox funktioniert. Tatsächlich werde ich die CSVs vollständig erstellen, damit ich die Perfmon-Zahlen, die wir in den DTU-Rechner laden, vollständig kontrollieren kann. Lassen Sie uns eine Metrik nach der anderen durchgehen. Für jede Metrik laden wir 25 Minuten (1500 Sekunden – ich mag runde Zahlen) an erfundenen Daten hoch und sehen, wie diese Leistungsdaten in DTUs umgewandelt werden.
Prozessor
Ich werde eine CSV-Datei erstellen, die einen 16-Core-Server simuliert und die CPU-Auslastung langsam erhöht, bis sie auf 100 % festgelegt ist. Da ich das Hochfahren auf einem 16-Core-Server simulieren werde, erstelle ich meine CSV so, dass sie jeweils um 1/16 erhöht wird – im Wesentlichen simuliere ich, dass ein Kern maximal ist, dann ein zweiter maximal, dann der dritte. usw. Währenddessen zeigt die CSV-Datei null Lese-, Schreib- und Log-Flushes an. Ein Server würde niemals eine solche Arbeitslast erzeugen – aber das ist der Punkt. Ich isoliere die CPU-Auslastung vollständig, damit ich sehen kann, wie sich die CPU auf DTUs auswirkt.
Ich erstelle eine CSV-Datei mit einer Zeile pro Sekunde, und alle 94 Sekunden erhöhe ich den Gesamtprozessorzeitzähler in % um ~6 %. Die anderen drei Zähler sind in allen Fällen Null. Jetzt lade ich diese Datei auf den DTU-Rechner hoch (und sage dem DTU-Rechner, dass er 16 Kerne berücksichtigen soll), und hier ist die Ausgabe:
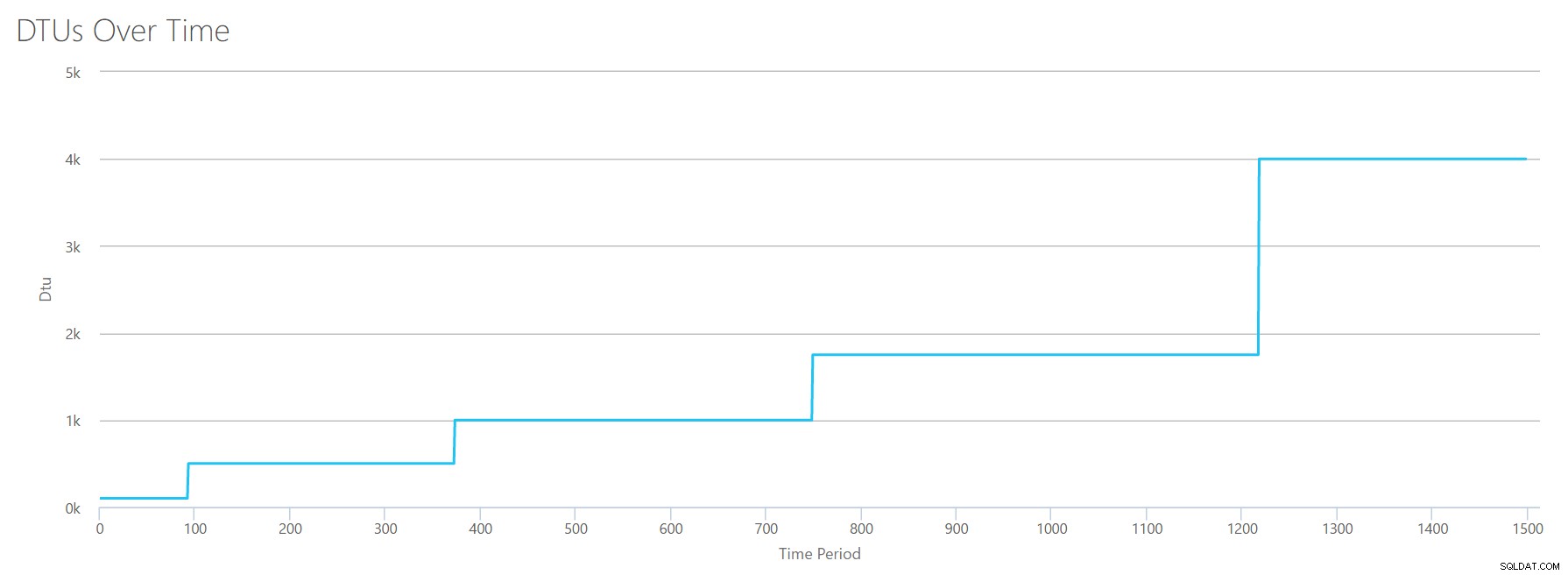
Warten? Habe ich die CPU-Auslastung nicht in 16 gleichmäßigen Schritten erhöht? Dieses DTU-Diagramm zeigt nur fünf Schritte. Ich muss mich geirrt haben. Nein – meine CSV hatte 16 gerade Schritte, aber das lässt sich (anscheinend) nicht gleichmäßig in DTUs übersetzen. Zumindest nicht laut DTU-Rechner. Basierend auf unserem maximalen CPU-Test würde unsere CPU-zu-DTU-zu-Service-Tier-Zuordnung wie folgt aussehen:
| Anzahl Kerne | DTUs | Dienststufe |
|---|---|---|
| 1 | 100 | Standard – S3 |
| 2-4 | 500 | Premium – P4 |
| 5-8 | 1000 | Premium – P6 |
| 9-13 | 1750 | Premium – P11 |
| 14-16 | 4000 | Premium – P15 |
Wenn wir uns diese Daten ansehen, erfahren wir einiges:
- Ein CPU-Kern, 100 % ausgelastet, entspricht 100 DTUs.
- DTUs nehmen irgendwie zu linear mit zunehmender CPU, aber scheinbar in Anfällen und Schüben.
- Die Dienststufen Basic und Standard entsprechen weniger als einem einzelnen CPU-Kern.
- Jeder Multi-Core-Server würde innerhalb der Premium-Dienstebene zu einer gewissen Größe führen.
Liest
Diesmal werde ich die gleiche Methode anwenden. Ich werde eine CSV mit steigenden Zahlen für den Lese-/Sekundenzähler generieren, wobei die anderen Perfmon-Zähler auf Null stehen. Ich werde die Zahl im Laufe der Zeit langsam steigern. Lassen Sie uns dieses Mal alle 100 Sekunden in 2000er-Schritten aufsteigen, bis wir 30000 erreichen. Dies gibt uns die gleiche Gesamtzeit von 25 Minuten – aber dieses Mal habe ich 15 Schritte statt 16. (Ich mag runde Zahlen.)
Wenn wir diese CSV-Datei in den DTU-Rechner hochladen, erhalten wir dieses DTU-Diagramm:
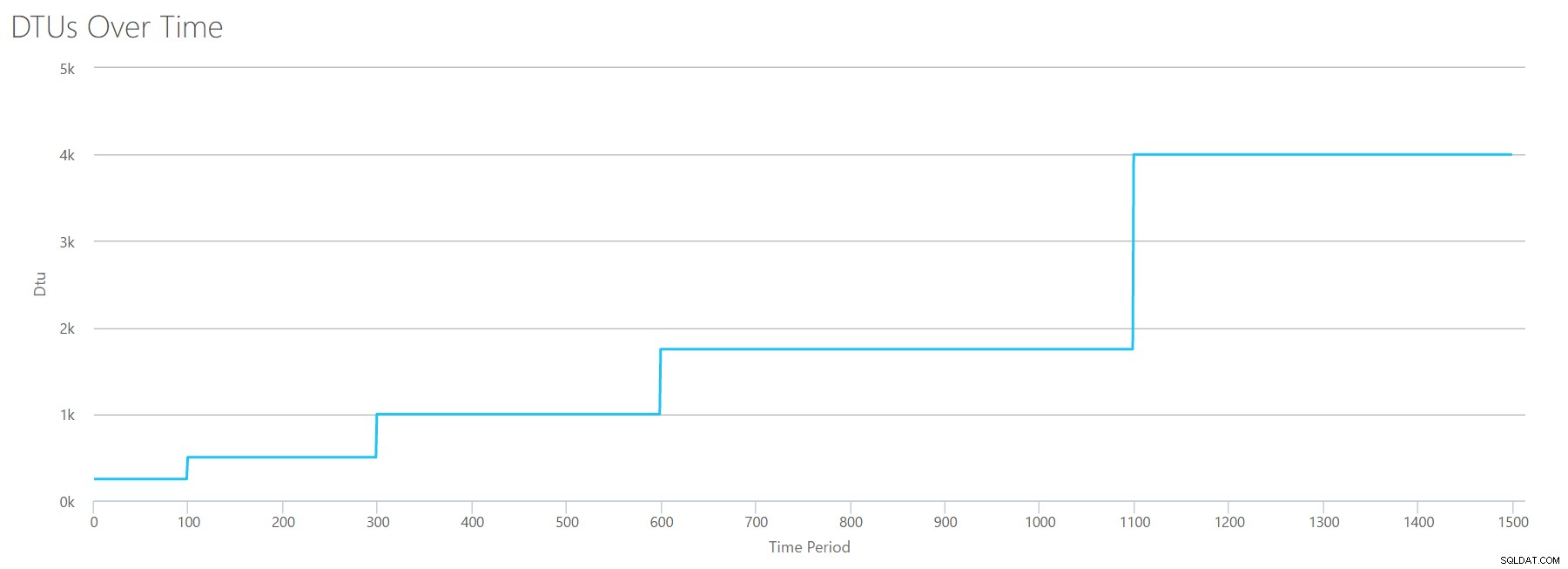
Warten Sie eine Sekunde ... das sieht dem ersten Diagramm ziemlich ähnlich. Auch hier steigt es in 5 ungeraden Schritten, obwohl ich 15 gerade Schritte in meiner Datei hatte. Betrachten wir es in tabellarischer Form:
| Lesungen/Sek. | DTUs | Dienststufe |
|---|---|---|
| 2000 | 250 | Premium – P2 |
| 4000-6000 | 500 | Premium – P4 |
| 8000-12000 | 1000 | Premium – P6 |
| 14000-22000 | 1750 | Premium – P11 |
| 24000-30000 | 4000 | Premium – P15 |
Auch hier sehen wir, dass die Stufen Basic und Standard ziemlich schnell übersprungen werden (weniger als 2.000 Lesevorgänge/Sek.), aber die Premium-Stufe ist ziemlich breit und umfasst 2.000 bis 30.000 Lesevorgänge pro Sekunde. In der obigen Tabelle könnte man sich „Lesevorgänge/Sek.“ wahrscheinlich als „IOPS“ vorstellen … Oder technisch gesehen einfach „OPS“, da es keine Schreibvorgänge gibt, die den „Eingabe“-Teil von IOPS darstellen.
Schreibt
Wenn wir eine CSV-Datei mit derselben Formel erstellen, die wir für Reads verwendet haben, und diese CSV-Datei in den DTU-Rechner hochladen, erhalten wir ein Diagramm, das mit dem Diagramm für Reads identisch ist:
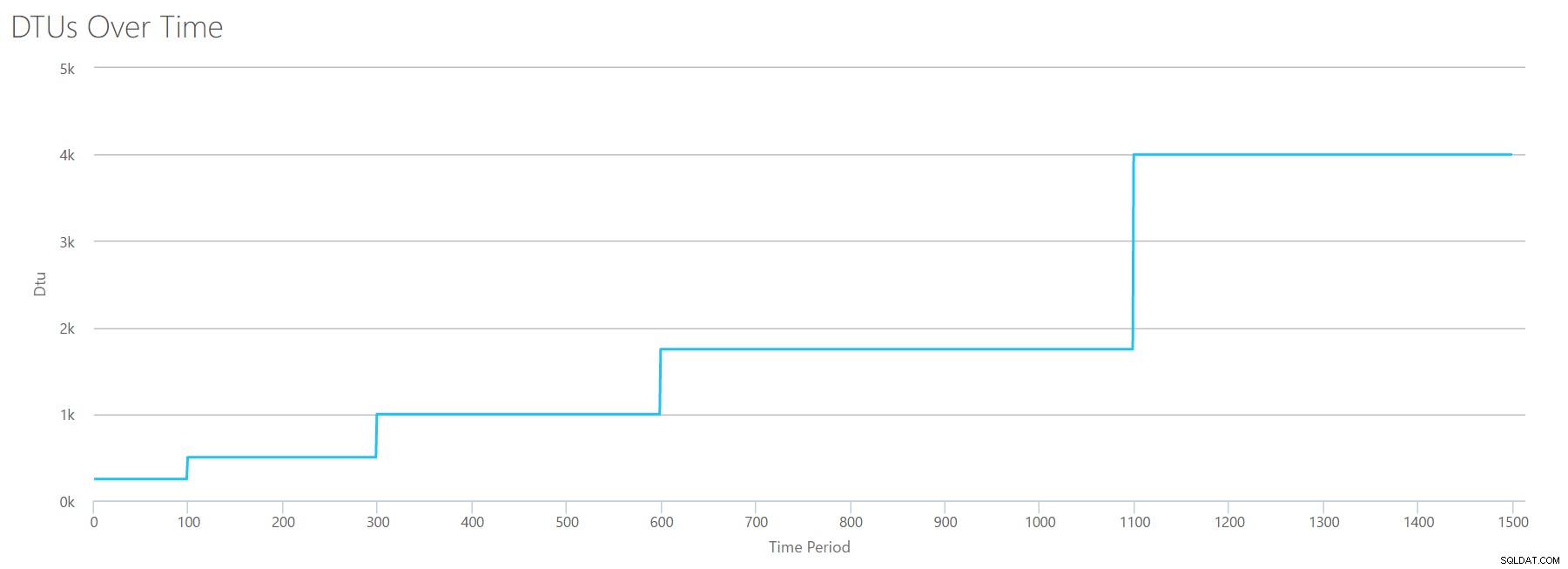
IOPS sind IOPS. Unabhängig davon, ob es sich um einen Lese- oder einen Schreibvorgang handelt, sieht es so aus, als würde die DTU-Berechnung dies gleichermaßen berücksichtigen. Alles, was wir über Lesevorgänge wissen (oder zu wissen glauben) scheint auch für Schreibvorgänge zu gelten.
Protokollbytes geleert
Wir sind beim letzten Perfmon-Zähler angelangt:Protokollbytes, die pro Sekunde geleert werden. Dies ist ein weiteres Maß für IO, aber spezifisch für das SQL Server-Transaktionsprotokoll. Falls Sie es noch nicht verstanden haben, erstelle ich diese CSVs so, dass die hohen Werte als P15-Azure-DB berechnet werden, und dividiere dann einfach den Wert, um ihn in gleichmäßige Schritte aufzuteilen. Dieses Mal werden wir in 5-Millionen-Schritten von 5 Millionen auf 75 Millionen steigen. Wie bei allen vorherigen Tests sind die anderen Perfmon-Zähler null. Da dieser Leistungszähler in Bytes pro Sekunde angegeben ist und wir in Millionen messen, können wir uns dies in der Einheit vorstellen, mit der wir uns wohler fühlen:Megabytes pro Sekunde.
Wir laden diese CSV-Datei in den DTU-Rechner hoch und erhalten das folgende Diagramm:
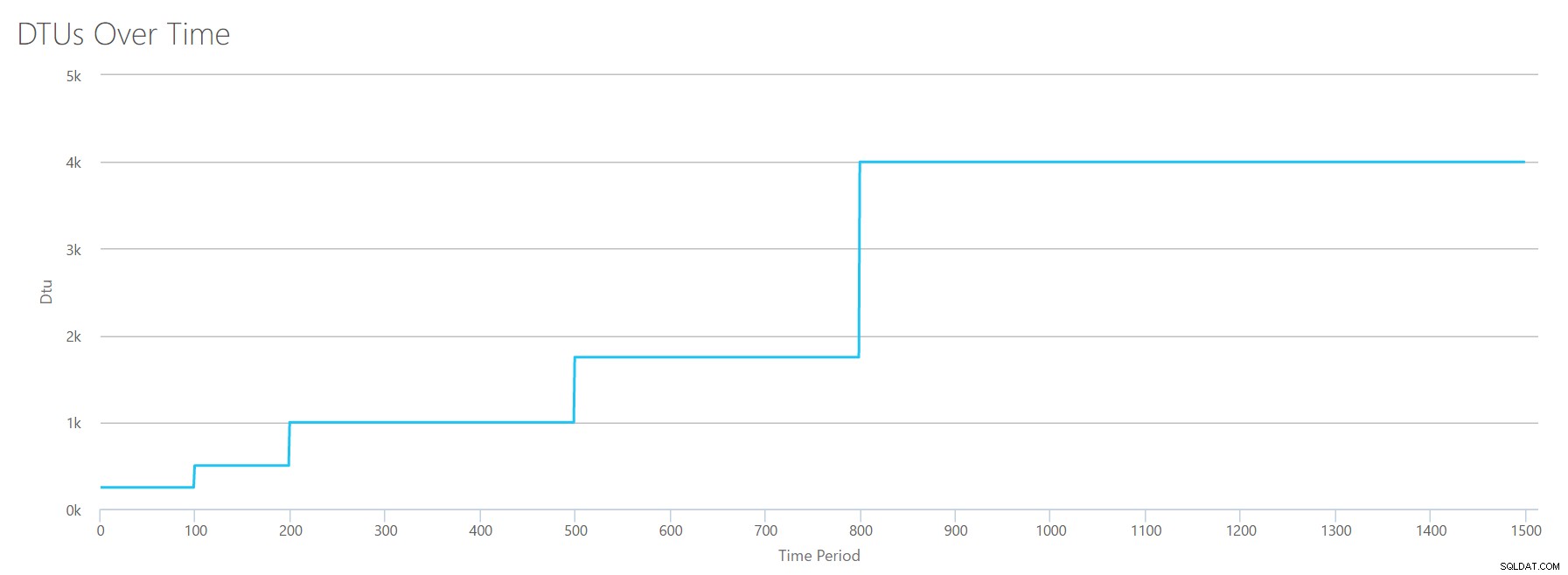
| Gelöschte Megabyte/Sekunde protokollieren | DTUs | Dienststufe |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15-25 | 1000 | Premium – P6 |
| 30-40 | 1750 | Premium – P11 |
| 45-75 | 4000 | Premium – P15 |
Die Form dieses Diagramms wird ziemlich vorhersehbar. Nur dass wir dieses Mal etwas schneller durch die Ebenen steigen und P15 nach nur 8 Schritten erreichen (im Vergleich zu 11 für IO und 12 für CPU). Das könnte dazu führen, dass Sie denken:„Das wird mein engster Engpass!“ aber da wäre ich mir nicht so sicher. Wie oft generieren Sie 75 MB Protokoll in einer Sekunde ? Das sind 4,5 GB pro Minute . Das ist eine Menge Datenbankaktivität. Meine synthetische Arbeitsbelastung ist nicht unbedingt eine realistische Arbeitsbelastung.
Alles kombinieren
OK, jetzt, wo wir gesehen haben, wo einige der Obergrenzen isoliert sind, werde ich die Daten kombinieren und sehen, wie sie verglichen werden, wenn CPU, I/O und Transaktionslog-IO auf einmal passieren – immerhin , ist es nicht so, wie die Dinge tatsächlich passieren?
Um diese CSV-Datei zu erstellen, habe ich einfach die vorhandenen Werte genommen, die wir oben für jeden einzelnen Test verwendet haben, und diese Werte in einer einzigen CSV-Datei kombiniert, was diese schöne Grafik ergibt:
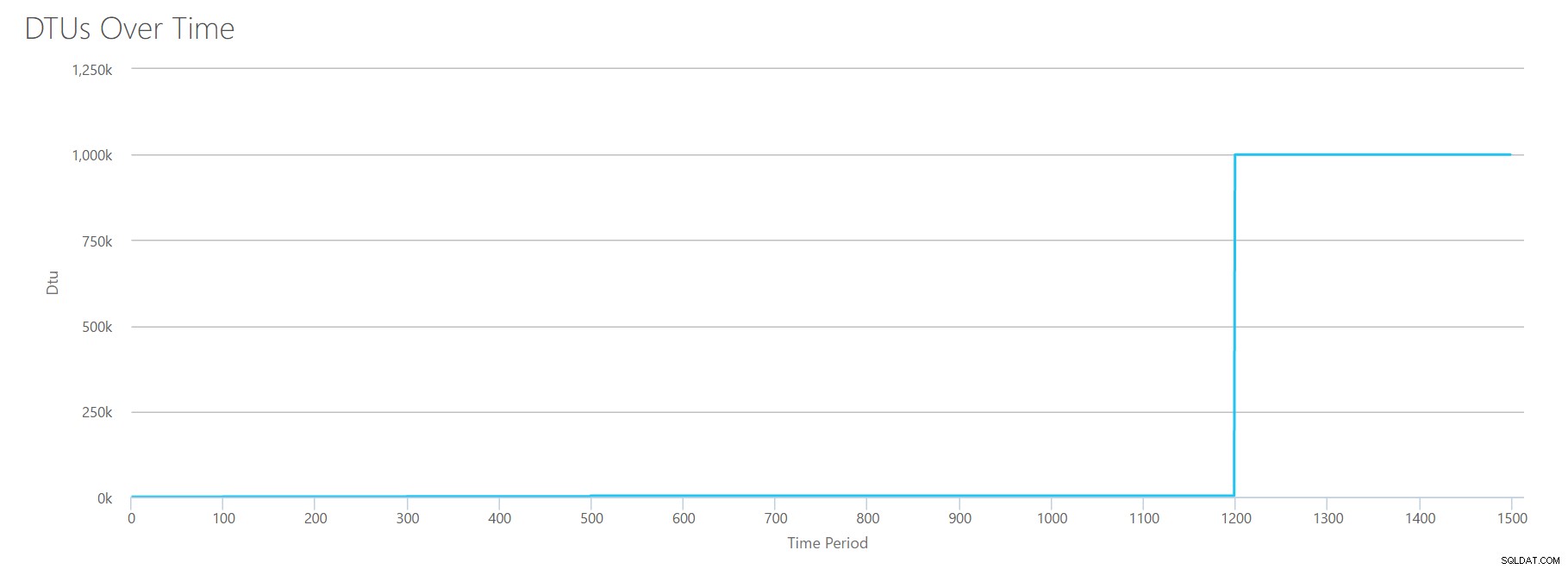
Es ergibt auch die Nachricht:
Basierend auf Ihrer Datenbankauslastung liegt Ihre SQL Server-Arbeitslast außerhalb des Bereichs . Derzeit gibt es kein Service Tier/Performance Level, das Ihre Nutzung abdeckt.Wenn Sie sich die Y-Achse ansehen, sehen Sie, dass wir bei der 1200-Sekunden-Marke „1.000.000“ (dh 1 Million) DTUs erreicht haben. Das scheint … äh … falsch? Wenn wir uns die obigen Tests ansehen, war die 1200-Sekunden-Marke, als alle 4 individuellen Metriken die Marke für 4000 DTU, P15-Tier erreichten. Es macht Sinn, dass wir außerhalb der Reichweite sind, aber die Form des Diagramms ergibt für mich keinen Sinn – ich glaube, der DTU-Rechner hat einfach seine Hände hochgeworfen und gesagt:„Wie auch immer, Andy. Es ist viel. Es ist auch viel. Es sind eine Bajillion DTUs. Diese Workload passt nicht für Azure SQL-Datenbank."
OK, also was passiert vorher die 1200-Sekunden-Marke? Lassen Sie uns die CSV-Datei kürzen und sie mit nur den ersten 1200 Sekunden erneut an den Rechner senden. Die Maximalwerte für jede Spalte sind:81 % CPU (oder ca. 13 Kerne bei 100 %), 24.000 Lesevorgänge/Sek., 24.000 Schreibvorgänge/Sek. und 60 MB Protokollleerung/Sek.
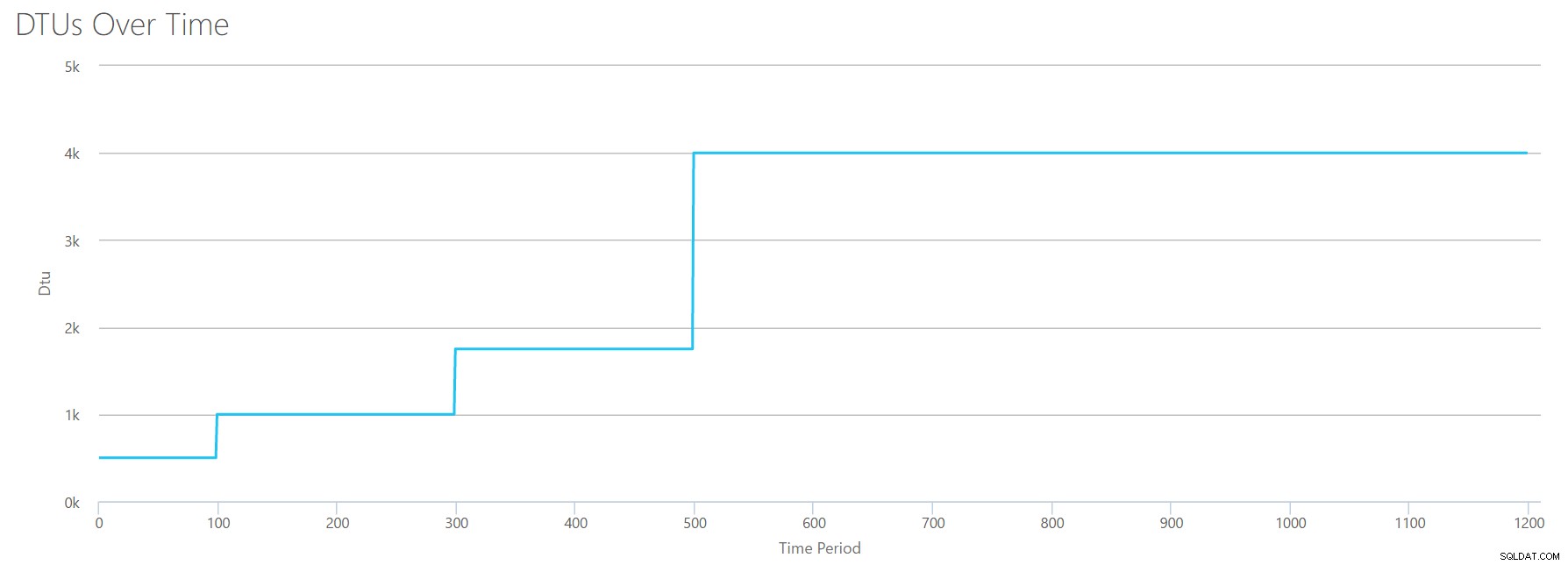
Hallo, alter Freund… Diese vertraute Form ist wieder da. Hier ist eine Zusammenfassung der Daten aus dem CSV und was der DTU-Rechner für die gesamte DTU-Nutzung und Dienstebene schätzt.
| Anzahl Kerne | Lesungen/Sek. | Schreibvorgänge/Sek. | Gelöschte Megabyte/Sekunde protokollieren | DTUs | Dienststufe |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Premium – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Premium – P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | Premium – P15 |
Sehen wir uns nun an, wie die einzelnen DTU-Berechnungen (wenn wir sie isoliert ausgewertet haben) im Vergleich zu den DTU-Berechnungen aus dieser letzten Überprüfung aussehen:
| CPU-DTUs | DTUs lesen | DTUs schreiben | Flush-DTUs protokollieren | Summe Gesamt-DTUs | Schätzung des DTU-Rechners | Dienstebene |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Premium – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Premium – P15 |
Sie werden feststellen, dass die DTU-Berechnung nicht so einfach ist wie das Addieren Ihrer einzelnen DTUs. Wie die eingangs zitierte Definition besagt, handelt es sich um ein „gemischtes Maß“ dieser separaten Metriken. Die Formel, die für das „Mischen“ verwendet wird, ist kompliziert, und wir haben diese Formel nicht wirklich. Wir können sehen, dass die Schätzungen des DTU-Rechners niedriger sind als die Summe der separaten DTU-Berechnungen.
Zuordnen von DTUs zu herkömmlicher Hardware
Nehmen wir die Daten aus dem DTU-Rechner und versuchen wir, einige Vermutungen darüber anzustellen, wie herkömmliche Hardware einigen Ebenen der Azure SQL-Datenbank zugeordnet werden könnte.
Nehmen wir zunächst an, dass „reads/sec“ und „writes/sec“ direkt in IOPS übersetzt werden, ohne dass eine Übersetzung erforderlich ist. Nehmen wir zweitens an, dass das Hinzufügen dieser beiden Zähler uns unsere Gesamt-IOPS ergibt. Drittens, lassen Sie uns zugeben, dass wir keine Ahnung haben, was die Speichernutzung ist, und wir haben keine Möglichkeit, diesbezüglich irgendwelche Schlussfolgerungen zu ziehen.
Während ich die Hardwarespezifikationen schätze, wähle ich auch eine mögliche Azure-VM-Größe aus, die zu jeder Hardwarekonfiguration passen würde. Es gibt viele ähnliche Azure-VM-Größen, die jeweils für unterschiedliche Leistungsmetriken optimiert sind, aber ich habe meine Auswahl auf die A-Serie und die DSv2-Serie beschränkt.
| Anzahl Kerne | IOPS | Erinnerung | DTUs | Dienststufe | Vergleichbare Azure-VM-Größe |
|---|---|---|---|---|---|
| 1 Kern, 5 % Auslastung | 10 | ??? | 5 | Basis | Standard_A0, kaum benutzt |
| <1 Kern | 150 | ??? | 100 | Standard S0-S3 | Standard_A0, nicht voll ausgelastet |
| 1 Kern | bis zu 4000 | ??? | 500 | Premium – P4 | Standard_DS1_v2 |
| 2-3 Kerne | bis zu 12000 | ??? | 1000 | Premium – P6 | Standard_DS3_v2 |
| 4-5 Kerne | bis zu 20000 | ??? | 1750 | Premium – P11 | Standard_DS4_v2 |
| 6-13 | bis zu 48000 | ??? | 4000 | Premium – P15 | Standard_DS5_v2 |
Die Basic-Stufe ist unglaublich begrenzt. Es eignet sich gut für den gelegentlichen Gebrauch und ist eine kostengünstige Möglichkeit, Ihre Datenbank zu "parken", wenn Sie sie nicht verwenden. Aber wenn Sie eine echte Anwendung ausführen, wird die Basic-Stufe für Sie nicht funktionieren.
Die Standard-Stufe ist ebenfalls ziemlich begrenzt, aber für kleine Anwendungen ist sie in der Lage, Ihre Anforderungen zu erfüllen. Wenn Sie einen 2-Core-Server haben, auf dem eine Handvoll Datenbanken ausgeführt werden, passen diese Datenbanken möglicherweise einzeln in den Standard-Tarif. Wenn Sie einen Server mit nur einer Datenbank haben, auf dem 1 CPU-Kern mit 100 % (oder 2 Kerne mit 50 %) ausgeführt wird, reicht dies wahrscheinlich gerade aus, um die Waage in die Dienstebene Premium-P1 zu bringen.
Wenn Sie einen Multi-Core-Server in einem lokalen (oder IaaS) verwenden würden, würden Sie in der Premium-Dienstebene auf Azure SQL-Datenbank suchen. Es ist nur eine Frage der Bestimmung, wie viel CPU- und E/A-Leistung Sie für Ihre Arbeitslast benötigen. Ihr 4-GB-Server mit 2 Kernen landet Sie wahrscheinlich irgendwo in der Nähe einer P6-Azure-SQL-Datenbank. Bei einer reinen CPU-Arbeitslast (ohne E/A) könnte eine P15-Datenbank eine Verarbeitung von 16 Kernen bewältigen, aber sobald Sie der Mischung E/A hinzufügen, passt alles, was größer als ~12 Kerne ist, nicht in Azure SQL-Datenbank.
Beim nächsten Mal nehme ich einige tatsächliche Workloads und vergleiche die Leistung über Dienstebenen hinweg. Sind die Schätzungen des DTU-Rechners genau? Wir finden es heraus.
Über den Autor
 Andy Mallon ist ein SQL Server DBA und Microsoft Data Platform MVP, der Datenbanken in den Bereichen Gesundheitswesen, Finanzen, z -Handel und Non-Profit-Sektoren. Seit 2003 unterstützt Andy hochvolumige, hochverfügbare OLTP-Umgebungen mit anspruchsvollen Leistungsanforderungen. Andy ist der Gründer von BostonSQL, Mitorganisator von SQLSaturday Boston und bloggt auf am2.co.
Andy Mallon ist ein SQL Server DBA und Microsoft Data Platform MVP, der Datenbanken in den Bereichen Gesundheitswesen, Finanzen, z -Handel und Non-Profit-Sektoren. Seit 2003 unterstützt Andy hochvolumige, hochverfügbare OLTP-Umgebungen mit anspruchsvollen Leistungsanforderungen. Andy ist der Gründer von BostonSQL, Mitorganisator von SQLSaturday Boston und bloggt auf am2.co.