Hinweis:Dieser Beitrag wurde ursprünglich nur in unserem eBook High Performance Techniques for SQL Server, Band 3 veröffentlicht. Sie können sich hier über unsere eBooks informieren.
Eine Anforderung, die ich gelegentlich sehe, besteht darin, eine Abfrage mit nach Kunden gruppierten Bestellungen zurückzugeben, die die maximal fällige Summe für jede Bestellung bis heute anzeigt (ein "laufendes Maximum"). Stellen Sie sich also diese Beispielzeilen vor:
| SalesOrderID | Kundennummer | Bestelldatum | TotalDue |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37,55 |
| 23 | 1 | 2014-01-02 | 45.29 |
| 31 | 2 | 2014-01-03 | 24.56 |
| 32 | 2 | 2014-01-04 | 89.84 |
| 37 | 1 | 2014-01-05 | 32.56 |
| 44 | 2 | 6.1.2014 | 45.54 |
| 55 | 1 | 2014-01-07 | 99.24 |
| 62 | 2 | 2014-01-08 | 12.55 |
Einige Zeilen mit Beispieldaten
Die gewünschten Ergebnisse aus den angegebenen Anforderungen lauten wie folgt:Einfach ausgedrückt:Sortieren Sie die Bestellungen jedes Kunden nach Datum und listen Sie jede Bestellung auf. Wenn dies der höchste TotalDue-Wert für alle bis zu diesem Datum angezeigten Bestellungen ist, drucken Sie die Gesamtsumme dieser Bestellung aus, andernfalls drucken Sie den höchsten TotalDue-Wert aller vorherigen Bestellungen aus:
| SalesOrderID | Kundennummer | Bestelldatum | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45.29 | 45.29 |
| 23 | 1 | 2014-01-05 | 32.56 | 45.29 |
| 31 | 1 | 2014-01-07 | 99.24 | 99.24 |
| 32 | 2 | 2014-01-01 | 37,55 | 37,55 |
| 37 | 2 | 2014-01-03 | 24.56 | 37,55 |
| 44 | 2 | 2014-01-04 | 89.84 | 89.84 |
| 55 | 2 | 6.1.2014 | 45,54 | 89.84 |
| 62 | 2 | 2014-01-08 | 12.55 | 89.84 |
Beispiel für gewünschte Ergebnisse
Viele Leute würden instinktiv einen Cursor oder eine While-Schleife verwenden wollen, um dies zu erreichen, aber es gibt mehrere Ansätze, die diese Konstrukte nicht beinhalten.
Korrelierte Unterabfrage
Dieser Ansatz scheint der einfachste und unkomplizierteste Ansatz für das Problem zu sein, aber er hat sich immer wieder als nicht skalierbar erwiesen, da die Lesevorgänge exponentiell wachsen, wenn die Tabelle größer wird:
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = (SELECT MAX(TotalDue)
FROM Sales.SalesOrderHeader
WHERE CustomerID = h.CustomerID
AND SalesOrderID <= h.SalesOrderID)
FROM Sales.SalesOrderHeader AS h
ORDER BY CustomerID, SalesOrderID; Hier ist der Plan gegen AdventureWorks2014 mit SQL Sentry Plan Explorer:
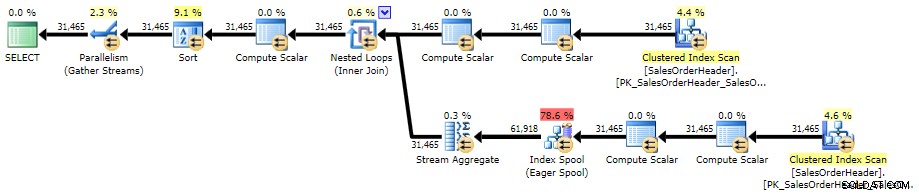 Ausführungsplan für korrelierte Unterabfrage (zum Vergrößern klicken)
Ausführungsplan für korrelierte Unterabfrage (zum Vergrößern klicken)
Selbstreferenzierende CROSS APPLY
Dieser Ansatz ist nahezu identisch mit dem Correlated Subquery-Ansatz in Bezug auf Syntax, Planform und Leistung im Maßstab.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDue
FROM Sales.SalesOrderHeader AS h
CROSS APPLY
(
SELECT MaxTotalDue = MAX(TotalDue)
FROM Sales.SalesOrderHeader AS i
WHERE i.CustomerID = h.CustomerID
AND i.SalesOrderID <= h.SalesOrderID
) AS x
ORDER BY h.CustomerID, h.SalesOrderID; Der Plan ist dem korrelierten Unterabfrageplan ziemlich ähnlich, der einzige Unterschied besteht in der Position einer Art:
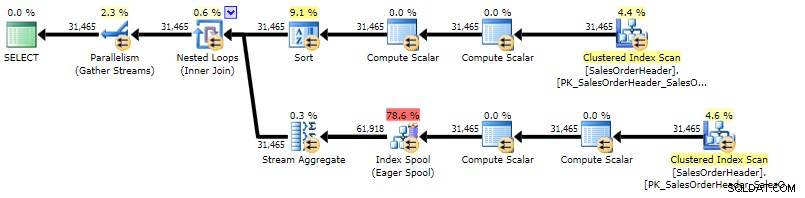 Ausführungsplan für CROSS APPLY (zum Vergrößern klicken)
Ausführungsplan für CROSS APPLY (zum Vergrößern klicken)
Rekursiver CTE
Hinter den Kulissen verwendet dies Schleifen, aber bis wir es tatsächlich ausführen, können wir so tun, als ob es nicht so wäre (obwohl es mit Sicherheit das komplizierteste Stück Code ist, das ich jemals schreiben möchte, um dieses spezielle Problem zu lösen):
;WITH /* Recursive CTE */ cte AS
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue = TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader
) AS x
WHERE rn = 1
UNION ALL
SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue,
MaxTotalDue = CASE
WHEN r.TotalDue > cte.MaxTotalDue THEN r.TotalDue
ELSE cte.MaxTotalDue
END
FROM cte
CROSS APPLY
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader AS h
WHERE h.CustomerID = cte.CustomerID
AND h.SalesOrderID > cte.SalesOrderID
) AS r
WHERE r.rn = 1
)
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM cte
ORDER BY CustomerID, SalesOrderID
OPTION (MAXRECURSION 0); Sie können sofort sehen, dass der Plan komplexer ist als die beiden vorherigen, was angesichts der komplexeren Abfrage nicht verwundert:
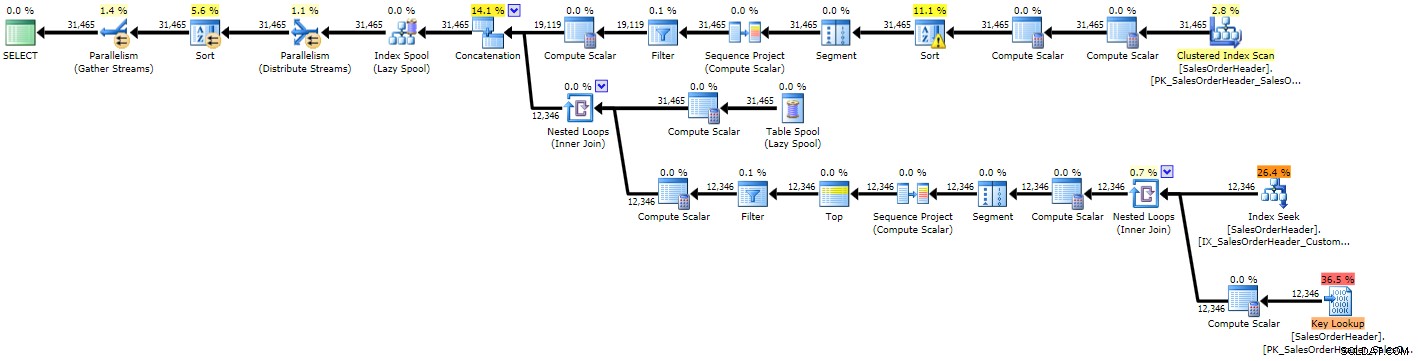 Ausführungsplan für rekursiven CTE (zum Vergrößern klicken)
Ausführungsplan für rekursiven CTE (zum Vergrößern klicken)
Aufgrund einiger schlechter Schätzungen sehen wir eine Indexsuche mit einer begleitenden Schlüsselsuche, die wahrscheinlich beide durch einen einzigen Scan hätten ersetzt werden sollen, und wir erhalten auch eine Sortieroperation, die letztendlich in tempdb übergehen muss (Sie können dies im Tooltip sehen wenn Sie den Mauszeiger über den Sortieroperator mit dem Warnsymbol bewegen):

MAX() OVER (ROWS UNBOUNDED)
Dies ist eine Lösung, die nur in SQL Server 2012 und höher verfügbar ist, da sie neu eingeführte Erweiterungen für Fensterfunktionen verwendet.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = MAX(TotalDue) OVER
(
PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS UNBOUNDED PRECEDING
)
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID; Der Plan zeigt genau, warum er besser skaliert als alle anderen; es hat nur eine geclusterte Index-Scan-Operation, im Gegensatz zu zwei (oder der schlechten Wahl eines Scans und einer Suche + Suche im Fall des rekursiven CTE):
 Ausführungsplan für MAX() OVER() (zum Vergrößern klicken)
Ausführungsplan für MAX() OVER() (zum Vergrößern klicken)
Leistungsvergleich
Die Pläne lassen uns sicherlich glauben, dass das neue MAX() OVER() Die Leistungsfähigkeit in SQL Server 2012 ist ein echter Gewinner, aber wie sieht es mit konkreten Laufzeitmetriken aus? So wurden die Hinrichtungen verglichen:

Die ersten beiden Abfragen waren fast identisch; während in diesem Fall das CROSS APPLY in Bezug auf die Gesamtdauer um einen kleinen Rand besser war, schlägt die korrelierte Unterabfrage stattdessen manchmal etwas. Der rekursive CTE ist jedes Mal wesentlich langsamer, und Sie können die Faktoren sehen, die dazu beitragen – nämlich die schlechten Schätzungen, die massive Menge an Lesevorgängen, die Schlüsselsuche und die zusätzliche Sortieroperation. Und wie ich zuvor mit laufenden Summen demonstriert habe, ist die SQL Server 2012-Lösung in fast jeder Hinsicht besser.
Schlussfolgerung
Wenn Sie SQL Server 2012 oder höher verwenden, möchten Sie sich auf jeden Fall mit allen Erweiterungen der Windowing-Funktionen vertraut machen, die erstmals in SQL Server 2005 eingeführt wurden – sie können Ihnen einige ziemlich ernsthafte Leistungssteigerungen geben, wenn Sie noch laufenden Code erneut aufrufen. der alte Weg." Wenn Sie mehr über einige dieser neuen Funktionen erfahren möchten, empfehle ich das Buch von Itzik Ben-Gan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Wenn Sie noch nicht auf SQL Server 2012 sind, könnten Sie zumindest in diesem Test zwischen CROSS APPLY wählen und die korrelierte Unterabfrage. Wie immer sollten Sie verschiedene Methoden anhand Ihrer Daten auf Ihrer Hardware testen.



