Beitrag von Dan Holmes, der unter sql.dnhlms.com bloggt.
SQL Server Books Online (BOL), Whitepapers und viele andere Quellen zeigen Ihnen, wie und warum Sie Statistiken für eine Tabelle oder einen Index aktualisieren sollten. Sie erhalten jedoch nur eine Möglichkeit, diese Werte zu formen. Ich zeige Ihnen, wie Sie die Statistik im Rahmen der 200 zur Verfügung stehenden Schritte genau so erstellen können, wie Sie es möchten.
Haftungsausschluss :Das funktioniert für mich, weil ich meine Anwendung, meine Datenbank und die regelmäßigen Workflow- und Anwendungsnutzungsmuster meiner Benutzer kenne. Es verwendet jedoch nicht dokumentierte Befehle und kann bei falscher Verwendung die Leistung Ihrer Anwendung erheblich verschlechtern.In unserer Anwendung liest und schreibt der Scheduling-Benutzer regelmäßig Daten, die Ereignisse für morgen und die nächsten Tage darstellen. Daten für heute und früher werden vom Scheduler nicht verwendet. Gleich morgens beginnt der Datensatz für morgen bei ein paar hundert Zeilen und kann am Mittag 1400 und mehr betragen. Das folgende Diagramm veranschaulicht die Zeilenanzahl. Diese Daten wurden am Mittwochmorgen, dem 18. November 2015, erfasst. In der Vergangenheit können Sie sehen, dass die reguläre Zeilenanzahl ungefähr 1.400 beträgt, außer an Wochenendtagen und am nächsten Tag.
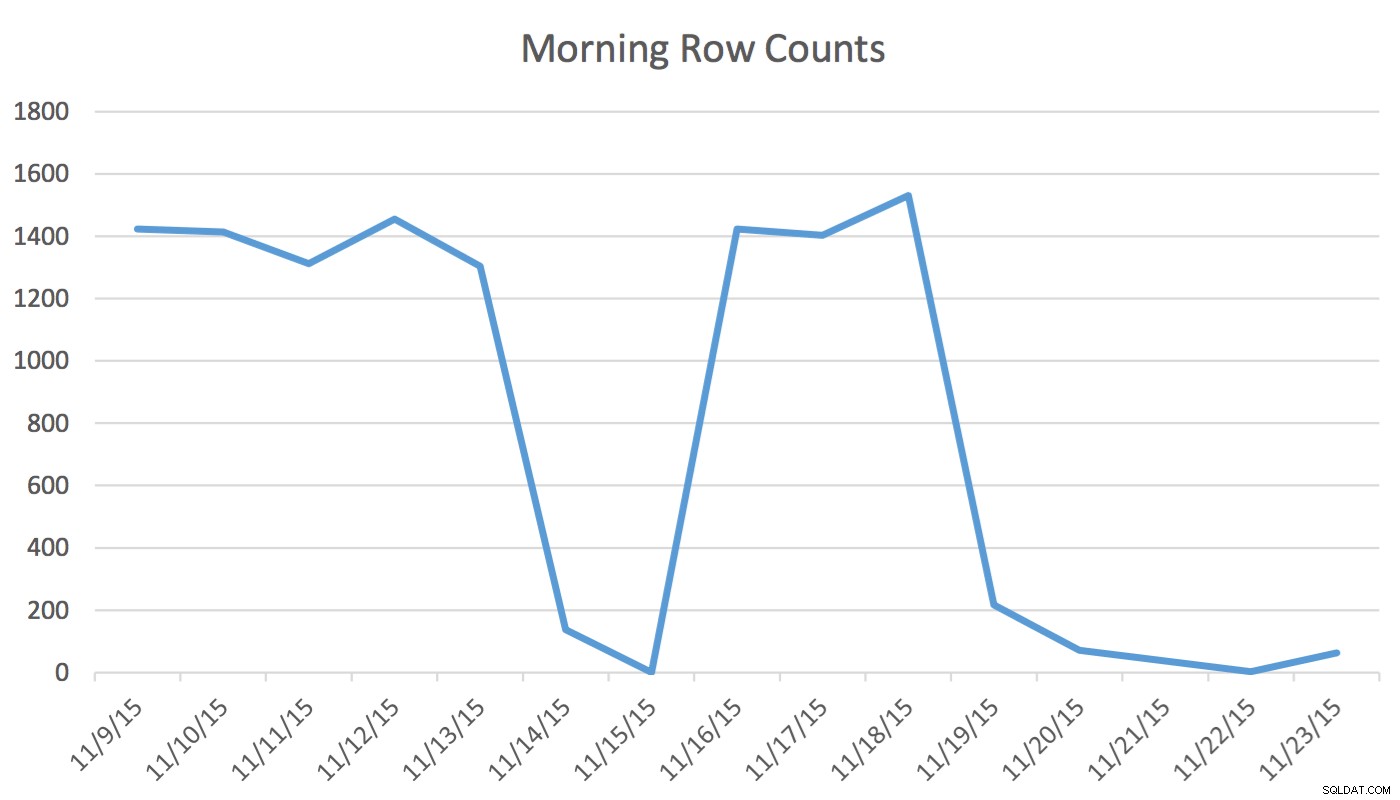
Für den Planer sind die einzig relevanten Daten die nächsten paar Tage. Was heute passiert und was gestern passiert ist, ist für seine Tätigkeit nicht relevant. Wie verursacht dies ein Problem? Diese Tabelle hat 2.259.205 Zeilen, was bedeutet, dass die Änderung der Zeilenanzahl von morgens bis mittags nicht ausreicht, um eine von SQL Server initiierte Statistikaktualisierung auszulösen. Außerdem ein manuell geplanter Job, der Statistiken mithilfe von UPDATE STATISTICS erstellt füllt das Histogramm mit einer Stichprobe aller Daten in der Tabelle, enthält jedoch möglicherweise nicht die relevanten Informationen. Dieses Delta der Zeilenanzahl reicht aus, um den Plan zu ändern. Ohne eine Statistikaktualisierung und ein genaues Histogramm wird sich der Plan jedoch nicht zum Besseren ändern, wenn sich die Daten ändern.
Eine relevante Auswahl des Histogramms für diese Tabelle aus einer Sicherung vom 4.11.2015 könnte so aussehen:
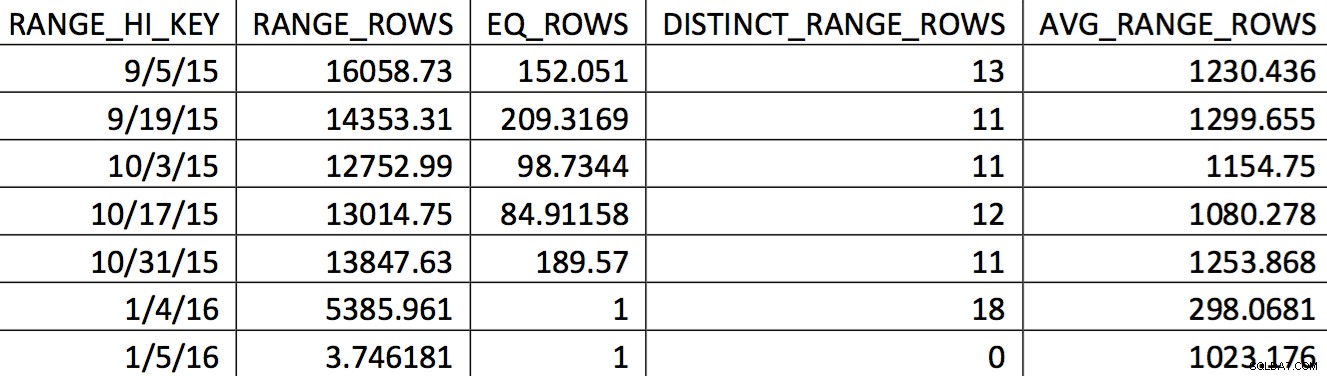
Die interessierenden Werte werden im Histogramm nicht genau wiedergegeben. Was für das Datum 5.11.2015 verwendet würde, wäre der hohe Wert 4.1.2016. Basierend auf der Grafik ist dieses Histogramm eindeutig keine gute Informationsquelle für den Optimierer für das interessierende Datum. Das Erzwingen der Nutzungswerte in das Histogramm ist nicht zuverlässig, also wie können Sie das tun? Mein erster Versuch war, wiederholt den WITH SAMPLE zu verwenden Option UPDATE STATISTICS und fragen Sie das Histogramm ab, bis die Werte, die ich brauchte, im Histogramm waren (ein Aufwand, der hier beschrieben wird). Letztendlich erwies sich dieser Ansatz als unzuverlässig.
Dieses Histogramm kann zu einem Plan mit dieser Art von Verhalten führen. Die Unterschätzung von Zeilen erzeugt einen Nested-Loop-Join und eine Indexsuche. Die Reads sind infolgedessen aufgrund dieser Planwahl höher als sie sein sollten. Dies wirkt sich auch auf die Anweisungsdauer aus.
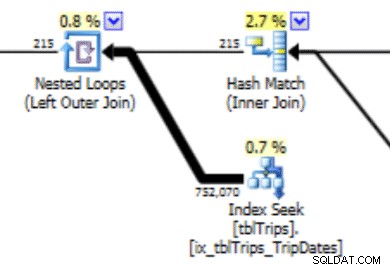
Was viel besser funktionieren würde, wäre, die Daten genau so zu erstellen, wie Sie es möchten, und so geht das.
Es gibt eine nicht unterstützte Option von UPDATE STATISTICS :STATS_STREAM . Dies wird vom Microsoft-Kundensupport verwendet, um Statistiken zu exportieren und zu importieren, damit sie einen Optimierer neu erstellen können, ohne alle Daten in der Tabelle zu haben. Wir können diese Funktion nutzen. Die Idee ist, eine Tabelle zu erstellen, die die DDL der Statistik nachahmt, die wir anpassen möchten. Die relevanten Daten werden der Tabelle hinzugefügt. Die Statistik wird exportiert und in die Originaltabelle importiert.
In diesem Fall handelt es sich um eine Tabelle mit 200 Zeilen mit Nicht-NULL-Daten und 1 Zeile, die die NULL-Werte enthält. Außerdem gibt es einen Index für diese Tabelle, der mit dem Index mit den fehlerhaften Histogrammwerten übereinstimmt.
Der Name der Tabelle ist tblTripsScheduled . Es hat einen nicht gruppierten Index auf (id, TheTripDate) und ein gruppierter Index auf TheTripDate . Es gibt noch eine Handvoll anderer Spalten, aber nur die, die im Index vorkommen, sind wichtig.
Erstellen Sie eine Tabelle (wenn Sie möchten eine temporäre Tabelle), die die Tabelle und den Index nachahmt. Die Tabelle und der Index sehen folgendermaßen aus:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Als nächstes muss die Tabelle mit 200 Datenzeilen gefüllt werden, auf denen die Statistiken basieren sollen. Für meine Situation ist es der Tag der nächsten sechzig Tage. Die letzten 60 Tage und darüber hinaus werden alle 10 Tage mit einer "zufälligen" Auswahl gefüllt. (Die cnt Wert im CTE ist ein Debug-Wert. Sie spielt für das Endergebnis keine Rolle.) Die absteigende Reihenfolge für den rn Spalte stellt sicher, dass die 60 Tage enthalten sind und dann so viel Vergangenheit wie möglich.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Unsere Tabelle ist jetzt mit jeder Zeile gefüllt, die für den Benutzer heute wertvoll ist, sowie mit einer Auswahl historischer Zeilen. Wenn die Spalte TheTripdate nullable wäre, hätte die Einfügung auch Folgendes enthalten:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Als nächstes aktualisieren wir die Statistiken im Index unserer temporären Tabelle.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Exportieren Sie diese Statistiken jetzt in eine temporäre Tabelle. Diese Tabelle sieht so aus. Es stimmt mit der Ausgabe von DBCC SHOW_STATISTICS WITH HISTOGRAM überein .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS hat die Option, die Statistiken als Stream zu exportieren. Es ist dieser Strom, den wir wollen. Dieser Stream ist auch derselbe Stream wie die UPDATE STATISTICS Stream-Option verwendet. Dazu:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Der letzte Schritt besteht darin, die SQL zu erstellen, die die Statistiken unserer Zieltabelle aktualisiert, und sie dann auszuführen.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); An dieser Stelle haben wir das Histogramm durch unser kundenspezifisches ersetzt. Sie können dies anhand des Histogramms überprüfen:
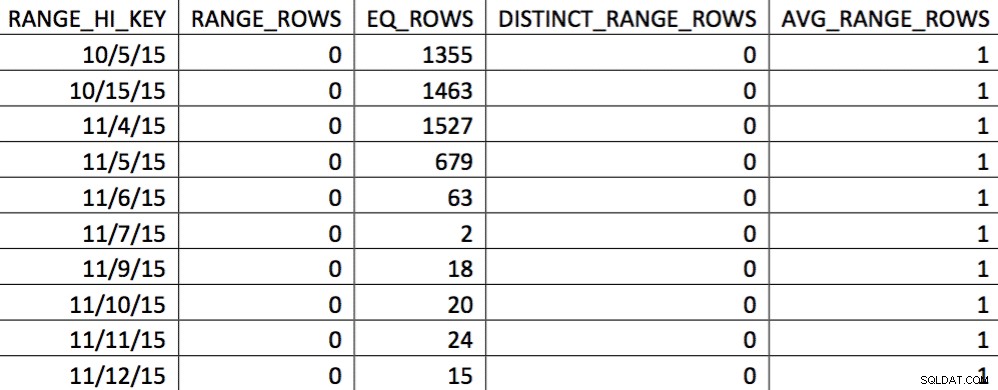
In dieser Auswahl der Daten zum 4.11. sind alle Tage ab dem 4.11. dargestellt, und die historischen Daten sind dargestellt und genau. Wenn Sie sich den zuvor gezeigten Teil des Abfrageplans noch einmal ansehen, sehen Sie, dass der Optimierer basierend auf den korrigierten Statistiken eine bessere Wahl getroffen hat:
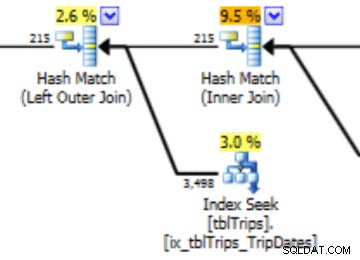
Importierte Statistiken haben einen Leistungsvorteil. Die Kosten für die Berechnung der Statistiken befinden sich in einer „Offline“-Tabelle. Die einzige Ausfallzeit für die Produktionstabelle ist die Dauer des Stream-Imports.
Dieser Prozess verwendet undokumentierte Funktionen und es sieht so aus, als könnte er gefährlich sein, aber denken Sie daran, dass es ein einfaches Rückgängigmachen gibt:die Update-Statistik-Anweisung. Wenn etwas schief geht, können die Statistiken jederzeit mit Standard-T-SQL aktualisiert werden.
Die regelmäßige Ausführung dieses Codes kann dem Optimierer sehr dabei helfen, bessere Pläne zu erstellen, wenn sich ein Datensatz über dem Wendepunkt ändert, aber nicht genug, um eine Statistikaktualisierung auszulösen.
Als ich den ersten Entwurf dieses Artikels fertigstellte, änderte sich die Zeilenanzahl in der Tabelle im ersten Diagramm von 217 auf 717. Das ist eine Änderung von 300 %. Das reicht aus, um das Verhalten des Optimierers zu ändern, aber nicht genug, um eine Statistikaktualisierung auszulösen. Diese Datenänderung hätte einen schlechten Plan hinterlassen. Mit dem hier beschriebenen Verfahren wird dieses Problem gelöst.
Referenzen:
- STATISTIKEN AKTUALISIEREN (Books Online)
- Whitepaper zu SQL 2008-Statistiken
- Kipppunktsuche