Hinweis:Dieser Beitrag wurde ursprünglich nur in unserem eBook High Performance Techniques for SQL Server, Band 4 veröffentlicht. Sie können sich hier über unsere eBooks informieren.
Mir wird regelmäßig die Frage gestellt:„Wo fange ich an, wenn ich versuche, eine SQL Server-Instanz zu optimieren?“ Meine erste Antwort ist, sie nach der Konfiguration ihrer Instanz zu fragen. Wenn bestimmte Dinge nicht richtig konfiguriert sind, kann es Zeitverschwendung sein, sofort mit der Suche nach lang andauernden oder kostenintensiven Abfragen zu beginnen.
Ich habe über häufige Dinge gebloggt, die Administratoren vermissen, wo ich viele der Einstellungen teile, die Administratoren von einer Standardinstallation von SQL Server ändern sollten. Bei leistungsbezogenen Elementen sage ich ihnen, dass sie Folgendes überprüfen sollten:
- Speichereinstellungen
- Statistiken aktualisieren
- Indexpflege
- MAXDOP und Kostenschwelle für Parallelität
- Best Practices für tempdb
- Für Ad-hoc-Workloads optimieren
Sobald ich die Konfigurationselemente hinter mir habe, frage ich, ob sie sich Datei- und Wartestatistiken sowie kostenintensive Abfragen angesehen haben. Meistens ist die Antwort „nein“ – mit einer Erklärung, dass sie nicht sicher sind, wie sie diese Informationen finden.
Wenn jemand sagt, dass er einen SQL-Server optimieren muss, ist die häufigste Kritik, dass er langsam läuft. Was bedeutet langsam? Ist es ein bestimmter Bericht, eine bestimmte Anwendung oder alles? Hat es gerade erst angefangen oder ist es mit der Zeit schlimmer geworden? Ich beginne damit, die üblichen Triage-Fragen zu stellen, wie die Speicher-, CPU- und Festplattenauslastung verglichen wird, wenn die Dinge normal sind, ob das Problem gerade erst aufgetreten ist und was sich kürzlich geändert hat. Sofern der Kunde keine Baseline erfasst, hat er keine Metriken zum Vergleichen, um festzustellen, ob die aktuellen Statistiken abnormal sind.
Fast jeder SQL Server, an dem ich arbeite, hostet mehr als eine Benutzerdatenbank. Wenn ein Client meldet, dass der SQL Server langsam läuft, macht er sich meistens Sorgen über eine bestimmte Anwendung, die seinen Kunden Probleme bereitet. Eine reflexartige Reaktion besteht darin, sich sofort auf diese bestimmte Datenbank zu konzentrieren, obwohl oft ein anderer Prozess wertvolle Ressourcen verbraucht und die Datenbank der Anwendung beeinträchtigt wird. Wenn Sie beispielsweise eine große Berichtsdatenbank haben und jemand einen massiven Bericht gestartet hat, der die Festplatte sättigt, die CPU in die Höhe treibt und den Plan-Cache leert, können Sie darauf wetten, dass die anderen Benutzerdatenbanken langsamer werden, während dieser Bericht generiert wird.
Ich beginne immer gerne damit, mir die Dateistatistiken anzusehen. Für SQL Server 2005 und höher können Sie die DMV sys.dm_io_virtual_file_stats abfragen, um E/A-Statistiken für jede Daten- und Protokolldatei abzurufen. Diese DMV ersetzte die Funktion fn_virtualfilestats. Um die Dateistatistiken zu erfassen, verwende ich gerne ein Skript, das Paul Randal zusammengestellt hat:Erfassen von IO-Latenzen für einen bestimmten Zeitraum. Dieses Skript erfasst eine Baseline und 30 Minuten später (es sei denn, Sie ändern die Dauer im Abschnitt WAITFOR DELAY) die Statistiken und berechnet die Deltas zwischen ihnen. Pauls Skript macht auch ein bisschen Mathematik, um die Lese- und Schreiblatenzen zu bestimmen, was es für uns viel einfacher macht, es zu lesen und zu verstehen.
Auf meinem Laptop habe ich eine Kopie der AdventureWorks2014-Datenbank auf einem USB-Laufwerk wiederhergestellt, damit ich langsamere Festplattengeschwindigkeiten hätte; Ich habe dann einen Prozess gestartet, um eine Last dagegen zu generieren. Sie können die Ergebnisse unten sehen, wobei meine Schreiblatenz für meine Datendatei 240 ms und die Schreiblatenz für meine Protokolldatei 46 ms beträgt. So hohe Latenzen sind lästig.
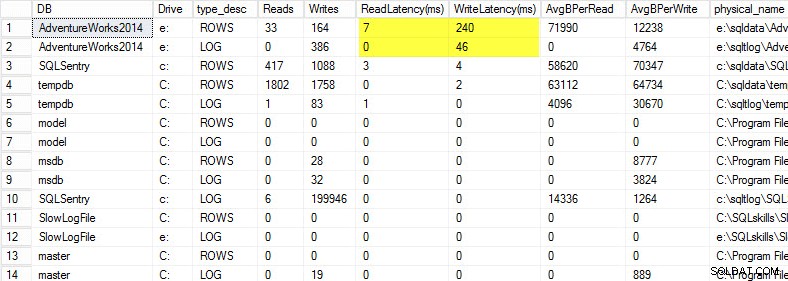
Alles über 20 ms sollte als schlecht angesehen werden, wie ich in einem früheren Beitrag mitgeteilt habe:Überwachung der Lese-/Schreiblatenz. Meine Leselatenz ist anständig, aber die AdventureWorks2014-Datenbank leidet unter langsamen Schreibvorgängen. In diesem Fall würde ich untersuchen, was die Schreibvorgänge generiert, und die Leistung meines E/A-Subsystems untersuchen. Wenn dies übermäßig hohe Leselatenzen gewesen wären, würde ich damit beginnen, die Abfrageleistung (warum werden so viele Lesevorgänge durchgeführt, beispielsweise von fehlenden Indizes) sowie die Gesamtleistung des I/O-Subsystems zu untersuchen.
Es ist wichtig, die Gesamtleistung Ihres E/A-Subsystems zu kennen, und der beste Weg, um herauszufinden, wozu es in der Lage ist, besteht darin, es zu vergleichen. Glenn Berry spricht darüber in seinem Artikel zur Analyse der E/A-Leistung für SQL Server. Glenn erklärt Latenz, IOPS und Durchsatz und zeigt CrystalDiskMark, ein kostenloses Tool, mit dem Sie Ihren Speicher abgleichen können.
Nachdem ich herausgefunden habe, wie sich die Dateistatistiken verhalten, schaue ich mir gerne die Wartestatistiken an, indem ich die DMV sys.dm_os_wait_stats verwende, die Informationen über alle aufgetretenen Wartezeiten zurückgibt. Dazu wende ich mich einem anderen Skript zu, das Paul Randal in seinem Blog-Post zum Erfassen von Wartestatistiken für einen bestimmten Zeitraum bereitstellt. Pauls Drehbuch rechnet wieder ein wenig für uns, aber was noch wichtiger ist, es schließt viele der harmlosen Wartezeiten aus, die uns normalerweise nicht interessieren. Dieses Skript hat auch ein WAITFOR DELAY und ist auf 30 Minuten eingestellt. Das Lesen von Wartestatistiken kann etwas kniffliger sein:Sie können Wartezeiten haben, die prozentual hoch erscheinen, aber die durchschnittliche Wartezeit ist so niedrig, dass Sie sich keine Sorgen machen müssen.
Ich habe denselben Ladevorgang gestartet und meine Wartestatistiken erfasst, die ich unten gezeigt habe. Für Erklärungen zu vielen dieser Wartetypen können Sie einen anderen von Pauls Blogposts, Wartestatistiken oder bitte sagen Sie mir, wo es weh tut, sowie einige seiner Posts in diesem Blog lesen.
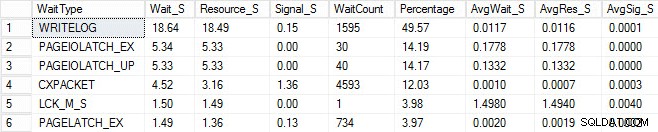
In dieser erfundenen Ausgabe könnten die PAGEIOLATCH-Wartezeiten auf einen Engpass bei meinem E/A-Subsystem hindeuten, könnten aber auch ein Speicherproblem, Tabellenscans anstelle von Suchvorgängen oder eine Vielzahl anderer Probleme sein. In meinem Fall wissen wir, dass es sich um ein Festplattenproblem handelt, da ich die Datenbank auf einem USB-Stick speichere. Die LCK_M_S-Wartezeit ist sehr hoch, jedoch gibt es nur eine Instanz des Wartens. Mein WRITELOG ist auch höher als ich gerne sehen würde, ist aber verständlich, wenn man die Latenzprobleme mit dem USB-Stick kennt. Dies zeigt auch CXPACKET-Wartezeiten, und es wäre leicht, reflexartig zu reagieren und zu glauben, dass Sie ein Parallelitäts-/MAXDOP-Problem haben, obwohl der AvgWait_S-Zähler sehr niedrig ist. Seien Sie vorsichtig, wenn Sie Wartezeiten für die Fehlerbehebung verwenden. Lassen Sie es Ihnen als Leitfaden dienen, der Ihnen Dinge sagt, die nicht das Problem sind, und Ihnen eine Richtung gibt, wo Sie nach Problemen suchen müssen. Bei der richtigen Fehlerbehebung werden Verhaltensweisen aus mehreren Bereichen korreliert, um das Problem einzugrenzen.
Nachdem ich mir die Datei und die Wartestatistik angesehen habe, beginne ich dann, basierend auf den gefundenen Problemen, in die teuren Abfragen einzutauchen. Dazu wende ich mich Glenn Berrys Diagnostic Information Queries zu. Diese Gruppen von Abfragen sind die wichtigsten Skripte, die viele Berater verwenden. Glenn und die Community stellen ständig Aktualisierungen bereit, um sie so informativ und robust wie möglich zu machen. Eine meiner Lieblingsabfragen sind die am häufigsten zwischengespeicherten Abfragen nach Ausführungsanzahl. Ich liebe es, Abfragen oder gespeicherte Prozeduren zu finden, die eine hohe Ausführungszahl in Verbindung mit hohen Gesamtzahl_logischer_Lesezugriffe haben. Wenn diese Abfragen Tuning-Möglichkeiten haben, können Sie schnell einen großen Unterschied für den Server machen. Ebenfalls in den Skripten enthalten sind die obersten zwischengespeicherten SPs nach Gesamtzahl logischer Lesevorgänge und die obersten zwischengespeicherten SPs nach Gesamtzahl physischer Lesevorgänge. Beide eignen sich gut für die Suche nach hohen Lesevorgängen mit hohen Ausführungszahlen, sodass Sie die Anzahl der I/Os reduzieren können.
Zusätzlich zu Glenns Skripten verwende ich gerne sp_whoisactive von Adam Machanic, um zu sehen, was gerade läuft.
Zur Leistungsoptimierung gehört viel mehr als nur das Betrachten von Datei- und Wartestatistiken und kostspieligen Abfragen, aber damit fange ich gerne an. Es ist eine Möglichkeit, eine Umgebung schnell zu sichten, um festzustellen, was das Problem verursacht. Es gibt keinen absolut idiotensicheren Weg zur Optimierung:Was jeder Produktions-DBA braucht, ist eine Checkliste mit Dingen, die zu beseitigen sind, und eine wirklich gute Sammlung von Skripts, die durchlaufen werden müssen, um den Zustand des Systems zu analysieren. Eine Basislinie zu haben ist der Schlüssel zum schnellen Ausschluss von normalem und abnormalem Verhalten. Meine gute Freundin Erin Stellato hat einen ganzen Kurs zu Pluralsight mit dem Titel „SQL Server:Benchmarking and Baselining“, wenn Sie Hilfe beim Einrichten und Erfassen Ihrer Baseline benötigen.
Besser noch, holen Sie sich ein hochmodernes Tool wie SQL Sentry Performance Advisor, das nicht nur historische Informationen für die Profilerstellung und Trenderstellung sammelt und speichert und einfachen Zugriff auf alle oben genannten Details und mehr bietet, sondern es auch gibt die Möglichkeit, Aktivitäten mit integrierten oder benutzerdefinierten Baselines zu vergleichen, Indizes effizient zu pflegen, ohne einen Finger zu rühren, und auf der Grundlage einer sehr robusten benutzerdefinierten Bedingungsarchitektur Alarme auszugeben oder Reaktionen zu automatisieren. Der folgende Screenshot zeigt die Verlaufsansicht des Performance Advisor-Dashboards mit Datenträgerwartezeiten in Orange, Datenbank-E/A unten rechts und Basislinien, die den aktuellen und den vorherigen Zeitraum in jedem Diagramm vergleichen (zum Vergrößern klicken):
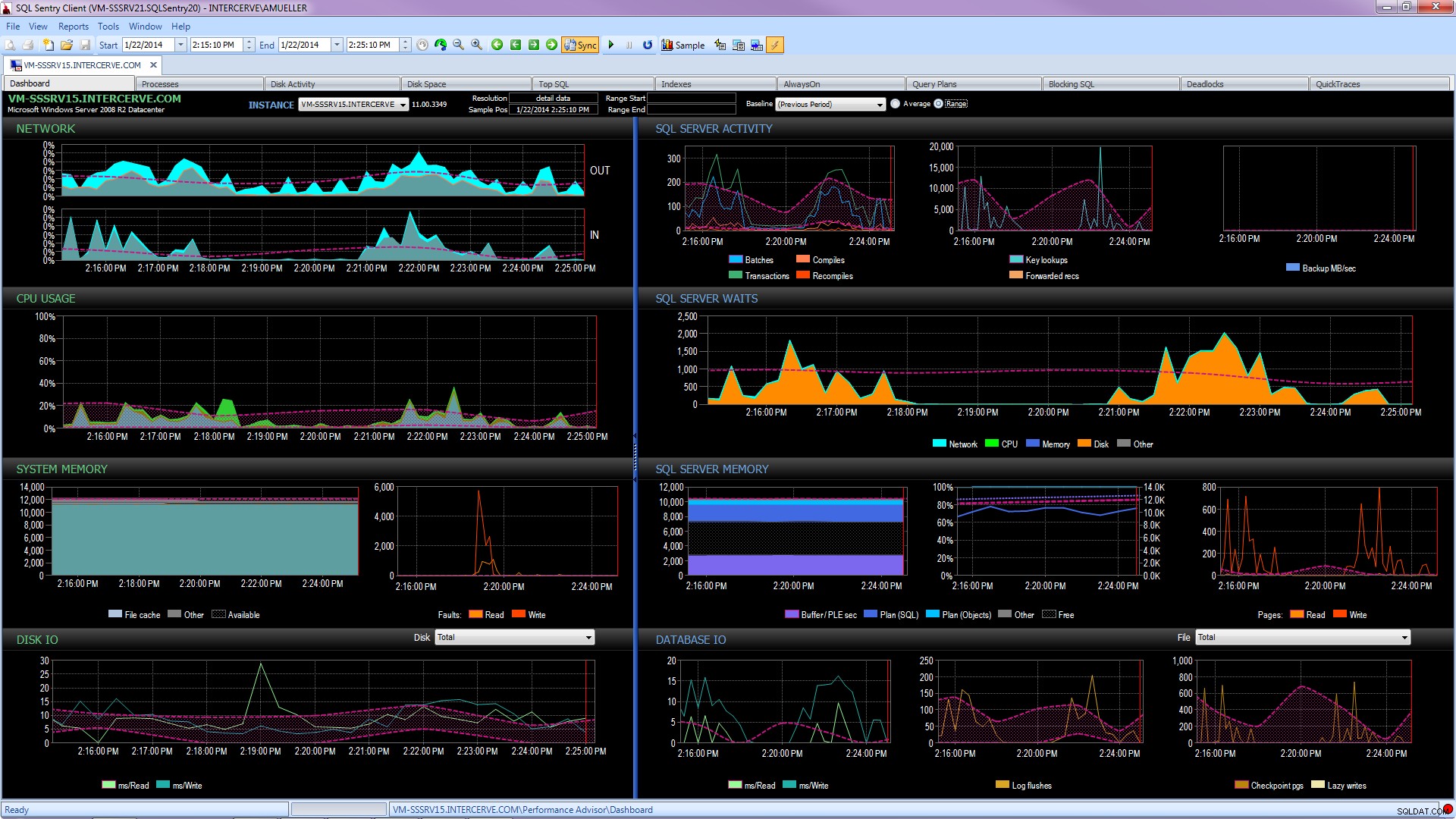
Qualitätsüberwachungstools sind nicht kostenlos, aber sie bieten eine Unmenge an Funktionalität und Support, die es Ihnen ermöglichen, sich auf die Leistungsprobleme auf Ihren Servern zu konzentrieren, anstatt sich auf Abfragen, Jobs und Warnungen zu konzentrieren, die möglicherweise sind ermöglichen es Ihnen, sich auf Ihre Leistungsprobleme zu konzentrieren – aber nur, wenn Sie sie richtig gelöst haben. Es ist oft von großem Wert, das Rad nicht neu zu erfinden.



