In diesem Beitrag besprechen wir den SQL Server-Sperrmechanismus und die Überwachung der SQL Server-Sperre mit standardmäßigen dynamischen Verwaltungsansichten von SQL Server. Bevor wir mit der Erläuterung der Sperrarchitektur von SQL Server beginnen, nehmen wir uns einen Moment Zeit, um zu beschreiben, was die ACID-Datenbank (Atomicity, Consistency, Isolation, and Durability) ist. Die ACID-Datenbank kann als Datenbanktheorie erklärt werden. Wenn eine Datenbank als relationale Datenbank bezeichnet wird, muss sie die Anforderungen an Unteilbarkeit, Konsistenz, Isolation und Dauerhaftigkeit erfüllen. Nun werden wir diese Anforderungen kurz erläutern.
Atomizität :Es spiegelt das Prinzip der Unteilbarkeit wider, das wir als Hauptmerkmal des Transaktionsprozesses beschreiben. Ein Transaktionsblock darf nicht unbeaufsichtigt bleiben. Die Hälfte des verbleibenden Transaktionsblocks verursacht Dateninkonsistenz. Entweder wird die gesamte Transaktion durchgeführt oder die Transaktion kehrt zum Anfang zurück. Das heißt, alle durch die Transaktion vorgenommenen Änderungen werden rückgängig gemacht und auf ihren vorherigen Zustand zurückgesetzt.
Konsistenz :Es gibt eine Regel, die die Unterstruktur der Nichtteilbarkeitsregel festlegt. Transaktionsdaten müssen konsistent sein. Das heißt, wenn die Aktualisierungsoperation in einer Transaktion durchgeführt wird, müssen entweder alle verbleibenden Transaktionen durchgeführt oder die Aktualisierungsoperation abgebrochen werden. Diese Daten sind im Hinblick auf Konsistenz sehr wichtig.
Isolierung :Dies ist ein Anforderungspaket für jede Transaktionsdatenbank. Durch ein Anforderungspaket vorgenommene Änderungen müssen für eine andere Transaktion sichtbar sein, bevor sie abgeschlossen ist. Jede Transaktion muss separat verarbeitet werden. Alle Transaktionen müssen nach ihrer Ausführung für eine andere Transaktion sichtbar sein.
Haltbarkeit: Transaktionen können komplexe Operationen mit Daten ausführen. Um all diese Transaktionen abzusichern, müssen sie gegen einen Transaktionsfehler resistent sein. Systemprobleme, die in SQL Server auftreten können, sollten auf Stromausfälle, Betriebssystem- oder andere softwarebedingte Fehler vorbereitet und widerstandsfähig sein.
Transaktion: Die Transaktion ist der kleinste Stapel des Prozesses, der nicht in kleinere Teile unterteilt werden kann. Außerdem können einige Gruppen von Transaktionsprozessen nacheinander ausgeführt werden, aber wie wir im Atomicity-Prinzip erklärt haben, werden alle Transaktionsblöcke fehlschlagen, wenn auch nur eine der Transaktionen fehlschlägt.
Sperre: Sperren ist ein Mechanismus zum Sicherstellen der Datenkonsistenz. SQL Server sperrt Objekte, wenn die Transaktion beginnt. Wenn die Transaktion abgeschlossen ist, gibt SQL Server das gesperrte Objekt frei. Dieser Sperrmodus kann entsprechend dem SQL Server-Prozesstyp und der Isolationsstufe geändert werden. Diese Sperrmodi sind:
Hierarchie sperren: SQL Server verfügt über eine Sperrhierarchie, die Sperrobjekte in dieser Hierarchie erwirbt. Eine Datenbank befindet sich ganz oben in der Hierarchie und eine Zeile ganz unten. Das folgende Bild veranschaulicht die Sperrhierarchie von SQL Server.

Geteilte (S) Sperren: Dieser Sperrtyp tritt auf, wenn das Objekt gelesen werden muss. Dieser Sperrtyp verursacht keine großen Probleme.
Exklusive (X) Sperren: Wenn dieser Sperrtyp auftritt, geschieht dies, um zu verhindern, dass andere Transaktionen ein gesperrtes Objekt ändern oder darauf zugreifen.
Update (U) Locks: Dieser Sperrtyp ähnelt dem exklusiven Sperren, weist jedoch einige Unterschiede auf. Wir können den Aktualisierungsvorgang in verschiedene Phasen unterteilen:Lesephase und Schreibphase. Während der Lesephase möchte SQL Server nicht, dass andere Transaktionen Zugriff auf dieses zu ändernde Objekt haben. Aus diesem Grund verwendet SQL Server die Update-Sperre.
Absichtssperren: Die beabsichtigte Sperre tritt auf, wenn SQL Server die freigegebene (S) Sperre oder die exklusive (X) Sperre für einige der in der Sperrenhierarchie niedrigeren Ressourcen erwerben möchte. In der Praxis ist, wenn SQL Server eine Sperre für eine Seite oder Zeile erwirbt, die Absichtssperre in der Tabelle erforderlich.
Nach all diesen kurzen Erklärungen werden wir versuchen, eine Antwort darauf zu finden, wie Schlösser identifiziert werden können. SQL Server bietet viele dynamische Verwaltungsansichten für den Zugriff auf Metriken. Um SQL Server-Sperren zu identifizieren, können wir sys.dm_tran_locks verwenden Aussicht. In dieser Ansicht finden wir viele Informationen über derzeit aktive Lock Manager-Ressourcen.
Im ersten Beispiel erstellen wir eine Demotabelle, die keine Indizes enthält, und versuchen, diese Demotabelle zu aktualisieren.
CREATE TABLE TestBlock (Id INT , Nm VARCHAR(100)) INSERT INTO TestBlock values(1,'CodingSight') In this step, we will create an open transaction and analyze the locked resources. BEGIN TRAN UPDATE TestBlock SET Nm='NewValue_CodingSight' where Id=1 select @@SPID
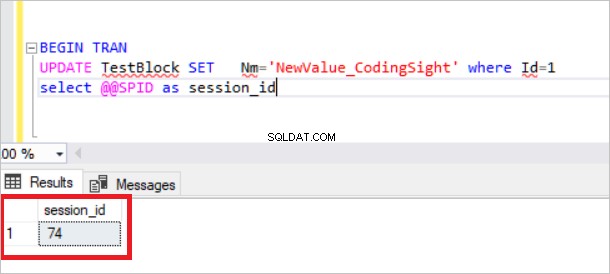
Jetzt prüfen wir die Ansicht sys.dm_tran_lock.
select * from sys.dm_tran_locks WHERE request_session_id=74
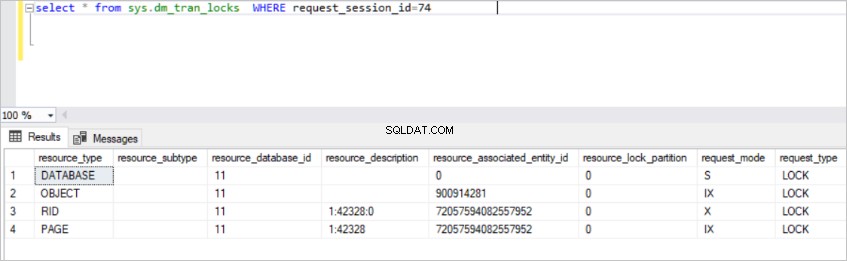
Diese Ansicht gibt viele Informationen über aktive Sperrressourcen zurück. Es ist jedoch nicht möglich, einige der Daten in dieser Ansicht zu verstehen. Aus diesem Grund müssen wir den sys.dm_tran_locks beitreten Ansicht zu anderen Ansichten.
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
and request_session_id=74
ORDER BY request_session_id, resource_associated_entity_id
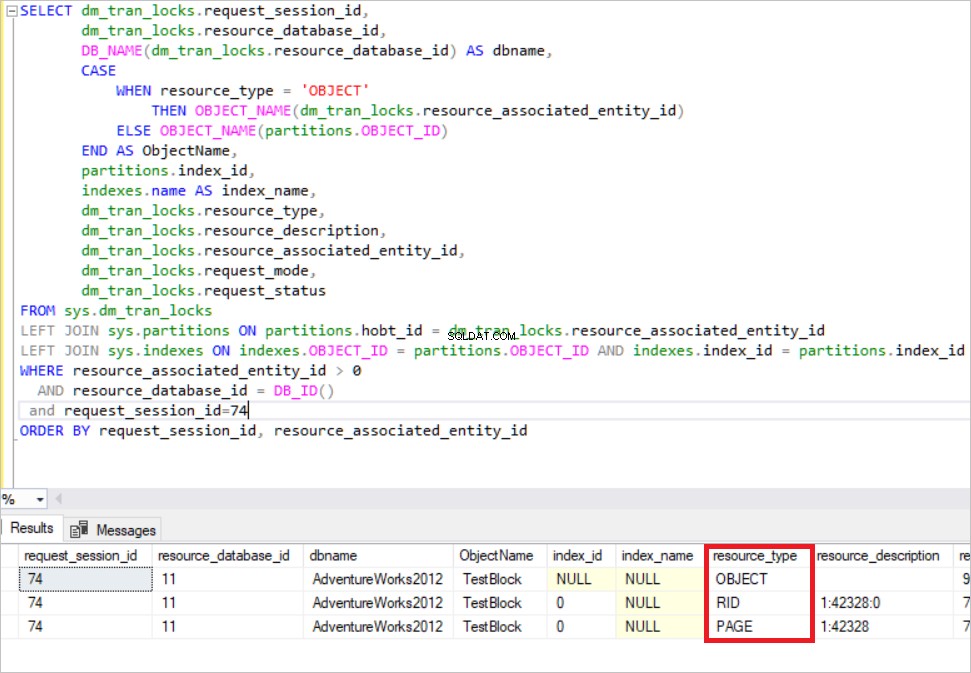
Im obigen Bild sehen Sie die gesperrten Ressourcen. SQL Server erwirbt die exklusive Sperre in dieser Zeile. (RID :Eine Zeilenkennung, die verwendet wird, um eine einzelne Zeile innerhalb eines Heaps zu sperren) Gleichzeitig erwirbt SQL Server die beabsichtigte exklusive Sperre in der Seite und im TestBlock Tisch. Dies bedeutet, dass kein anderer Prozess diese Ressource lesen kann, bis der SQL Server die Sperren freigibt. Dies ist der grundlegende Sperrmechanismus im SQL Server.
Jetzt werden wir einige synthetische Daten in unsere Testtabelle eintragen.
TRUNCATE TABLE TestBlock DECLARE @K AS INT=0 WHILE @K <8000 BEGIN INSERT TestBlock VALUES(@K, CAST(@K AS varchar(10)) + ' Value' ) SET @example@sqldat.com+1 END After completing this step, we will run two queries and check the sys.dm_tran_locks view. BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<5000
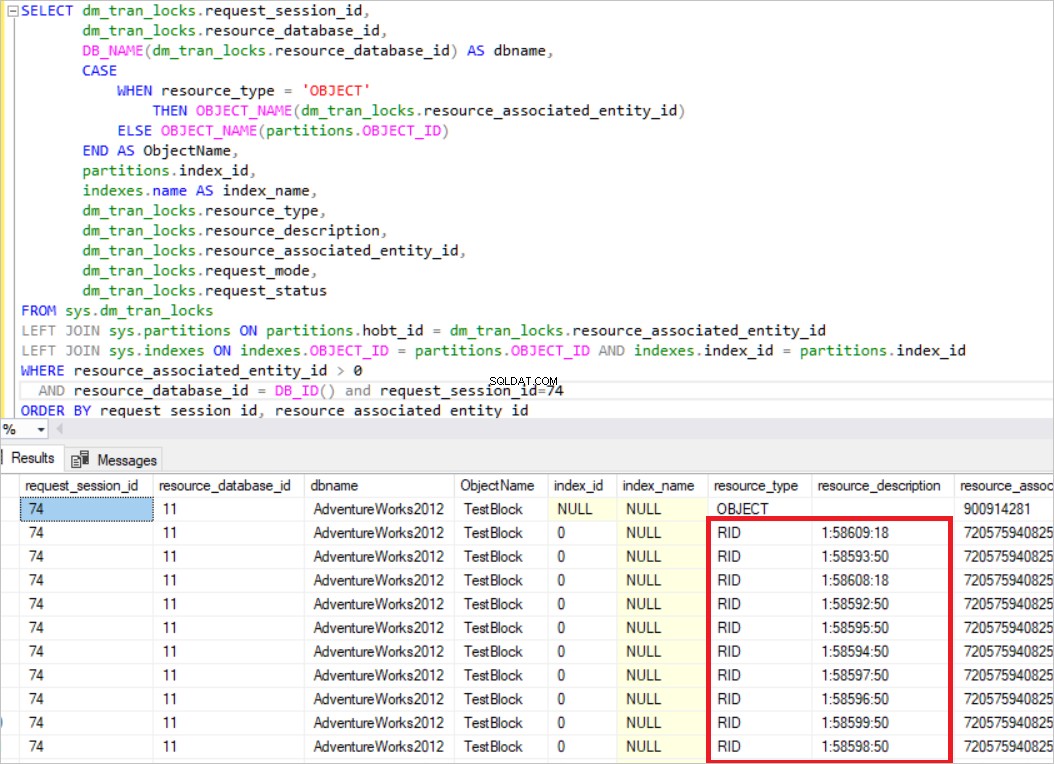
In der obigen Abfrage erwirbt SQL Server die exklusive Sperre für jede einzelne Zeile. Jetzt führen wir eine weitere Abfrage durch.
BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<7000
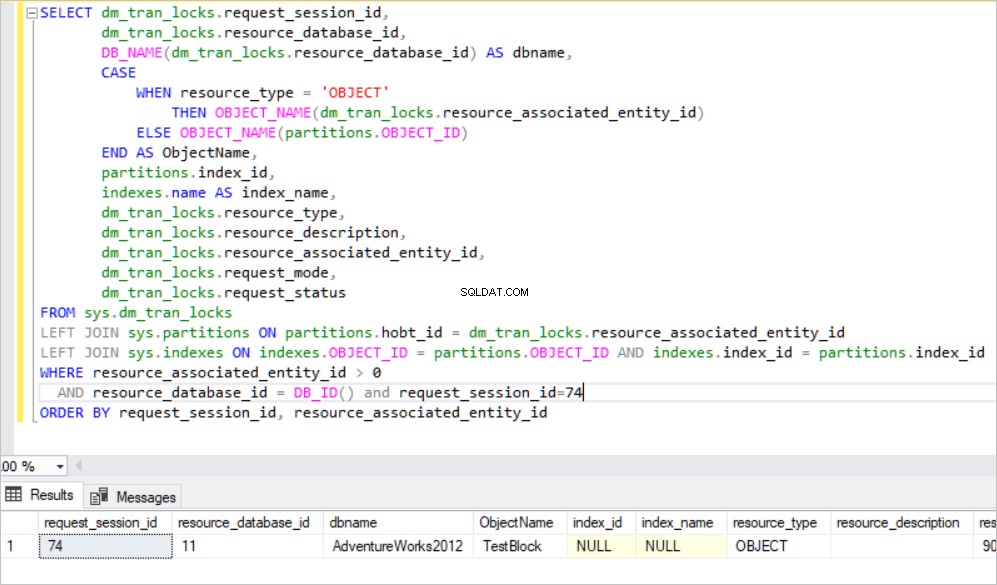
In der obigen Abfrage erstellt SQL Server die exklusive Sperre für die Tabelle, da SQL Server versucht, viele RID-Sperren für diese Zeilen zu erwerben, die aktualisiert werden. Dieser Fall verursacht einen hohen Ressourcenverbrauch in der Datenbank-Engine. Daher verschiebt SQL Server diese exklusive Sperre automatisch auf ein übergeordnetes Objekt, das sich in der Sperrenhierarchie befindet. Wir definieren diesen Mechanismus als Lock Escalation. Die Sperrenausweitung kann auf Tabellenebene geändert werden.
ALTER TABLE XX_TableName SET ( LOCK_ESCALATION = AUTO -- or TABLE or DISABLE ) GO
Ich möchte einige Anmerkungen zur Sperreneskalation hinzufügen. Wenn Sie eine partitionierte Tabelle haben, können wir die Eskalation auf die Partitionsebene setzen.
In diesem Schritt führen wir eine Abfrage aus, die eine Sperre in der AdventureWorks HumanResources-Tabelle erstellt. Diese Tabelle hat geclusterte und nicht geclusterte Indizes.
BEGIN TRAN UPDATE [HumanResources].[Department] SET Name='NewName' where DepartmentID=1
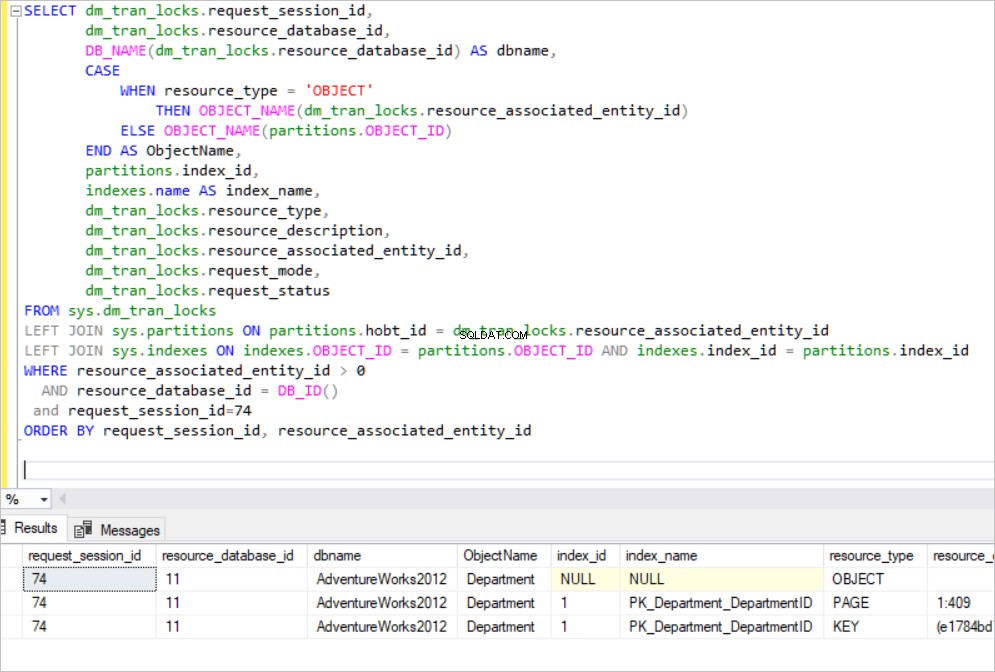
Wie Sie im Ergebnisbereich unten sehen können, erwirbt unsere Transaktion exklusive Sperren im Cluster-Indexschlüssel PK_Department_DepartmentID und erwirbt auch exklusive Sperren im nicht gruppierten Indexschlüssel AK_Department_Name. Jetzt können wir diese Frage stellen:„Warum sperrt SQL Server einen nicht geclusterten Index?“
Der Name Spalte ist im nicht gruppierten Index AK_Department_Name indiziert und wir versuchen, den Namen zu ändern Säule. In diesem Fall muss SQL Server alle nicht gruppierten Indizes für diese Spalte ändern. Die Blattebene des nicht geclusterten Index enthält jeden aussortierten KEY-Wert.
Schlussfolgerungen
In diesem Artikel haben wir die Hauptlinien des SQL Server-Sperrmechanismus erwähnt und die Verwendung von sys.dm_tran_locks betrachtet. Die Ansicht sys.dm_tran_locks gibt viele Informationen über derzeit aktive Sperrressourcen zurück. Wenn Sie googeln, finden Sie viele Beispielabfragen zu dieser Ansicht.
Referenzen
SQL Server Transaction Locking and Row Versioning Guide
SQL Server, Sperrobjekt