Letzte Woche habe ich während der GroupBy-Konferenz meine Sitzung T-SQL:Bad Habits and Best Practices vorgestellt. Eine Videowiedergabe und andere Materialien sind hier verfügbar:
- T-SQL:Schlechte Angewohnheiten und Best Practices
Einer der Punkte, die ich in dieser Sitzung immer wieder erwähne, ist, dass ich im Allgemeinen GROUP BY gegenüber DISTINCT bevorzuge, wenn Duplikate eliminiert werden. Während DISTINCT die Absicht besser erklärt und GROUP BY nur erforderlich ist, wenn Aggregationen vorhanden sind, sind sie in vielen Fällen austauschbar.
Beginnen wir mit etwas Einfachem, indem wir Wide World Importers verwenden. Diese beiden Abfragen erzeugen das gleiche Ergebnis:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
Und tatsächlich leiten sie ihre Ergebnisse mit genau demselben Ausführungsplan ab:

Gleiche Operatoren, gleiche Anzahl von Lesevorgängen, vernachlässigbare Unterschiede in CPU und Gesamtdauer (sie „gewinnen“ abwechselnd).
Warum würde ich also empfehlen, die wortreichere und weniger intuitive GROUP BY-Syntax gegenüber DISTINCT zu verwenden? Nun, in diesem einfachen Fall ist es ein Münzwurf. In komplexeren Fällen kann DISTINCT jedoch mehr Arbeit leisten. Im Wesentlichen sammelt DISTINCT alle Zeilen, einschließlich aller Ausdrücke, die ausgewertet werden müssen, und wirft dann Duplikate aus. GROUP BY kann (wieder in einigen Fällen) die doppelten Zeilen vorher herausfiltern Durchführung einer dieser Arbeiten.
Lassen Sie uns zum Beispiel über String-Aggregation sprechen. Während Sie in SQL Server v.Next STRING_AGG verwenden können (siehe Beiträge hier und hier), müssen die anderen mit FOR XML PATH weitermachen (und bevor Sie mir erzählen, wie erstaunlich rekursive CTEs dafür sind, bitte lesen Sie auch diesen Beitrag). Wir könnten eine Abfrage wie diese haben, die versucht, alle Bestellungen aus der Sales.OrderLines-Tabelle zusammen mit Artikelbeschreibungen als durch senkrechte Striche getrennte Liste zurückzugeben:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Dies ist eine typische Abfrage zum Lösen dieser Art von Problem mit dem folgenden Ausführungsplan (die Warnung in allen Plänen bezieht sich nur auf die implizite Konvertierung, die aus dem XPath-Filter kommt):
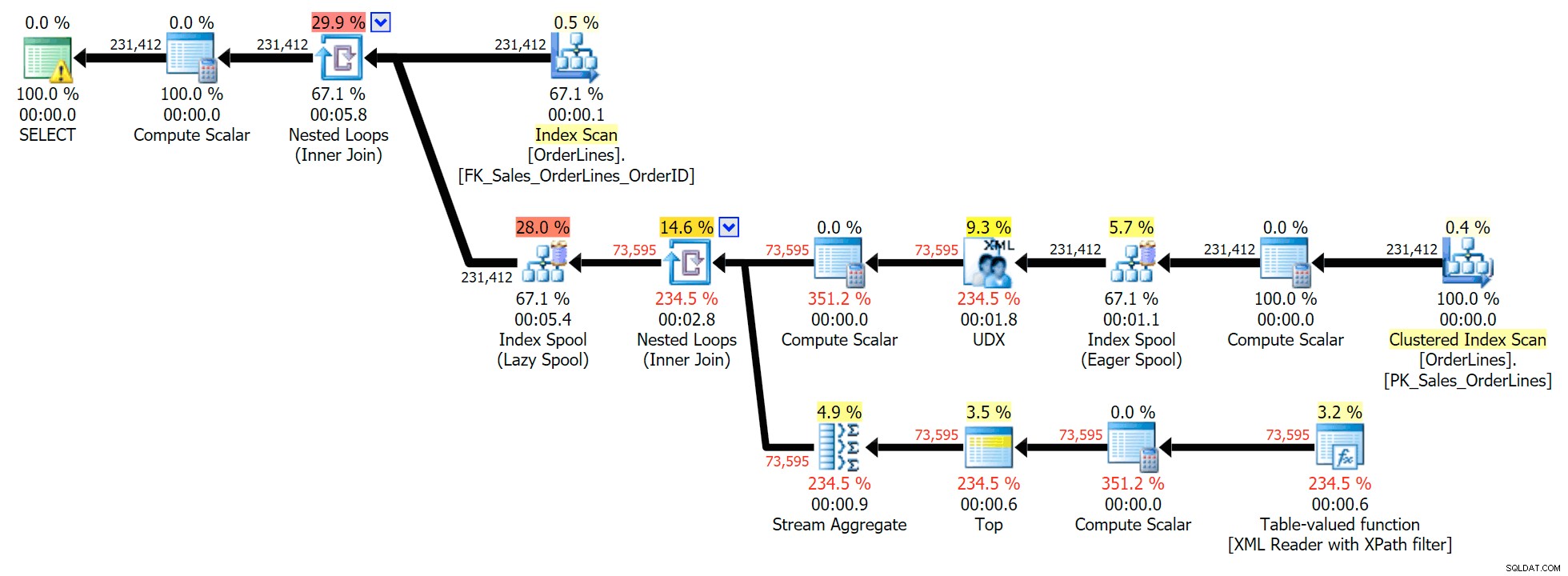
Es gibt jedoch ein Problem, das Sie möglicherweise in der Ausgabeanzahl der Zeilen bemerken. Sie können es sicherlich erkennen, wenn Sie die Ausgabe beiläufig scannen:

Für jede Bestellung sehen wir die durch senkrechte Striche getrennte Liste, aber wir sehen eine Zeile für jeden Artikel bei jeder Bestellung. Die spontane Reaktion besteht darin, ein DISTINCT auf die Spaltenliste zu werfen:
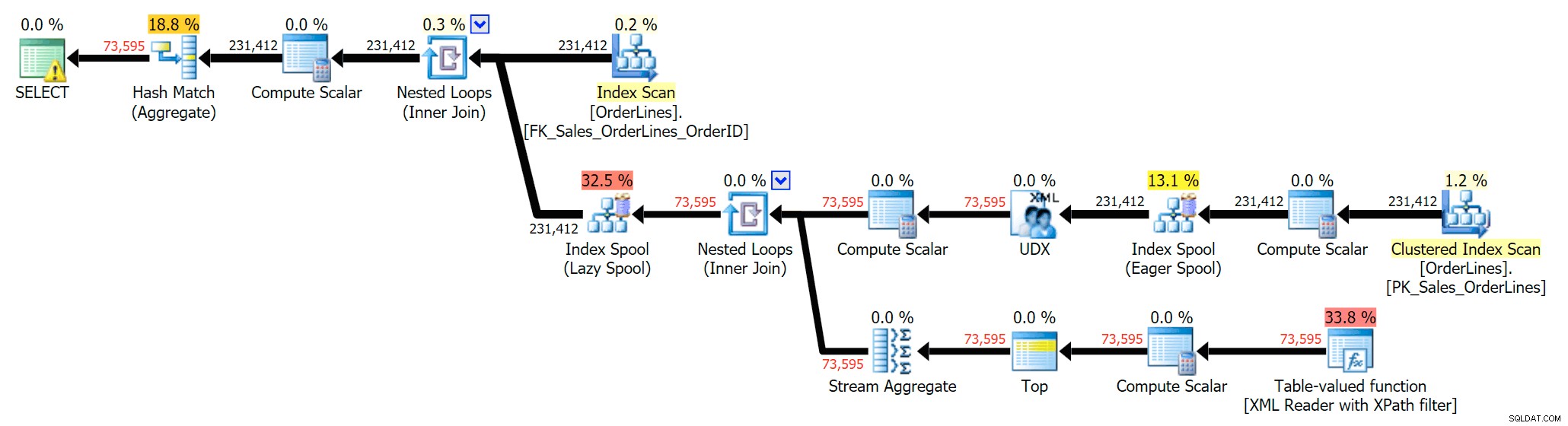
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Dadurch werden die Duplikate eliminiert (und die Sortiereigenschaften der Scans geändert, sodass die Ergebnisse nicht unbedingt in einer vorhersagbaren Reihenfolge angezeigt werden) und der folgende Ausführungsplan erstellt:
Eine andere Möglichkeit, dies zu tun, besteht darin, ein GROUP BY für die OrderID hinzuzufügen (da die Unterabfrage nicht explizit braucht erneut im GROUP BY referenziert werden):
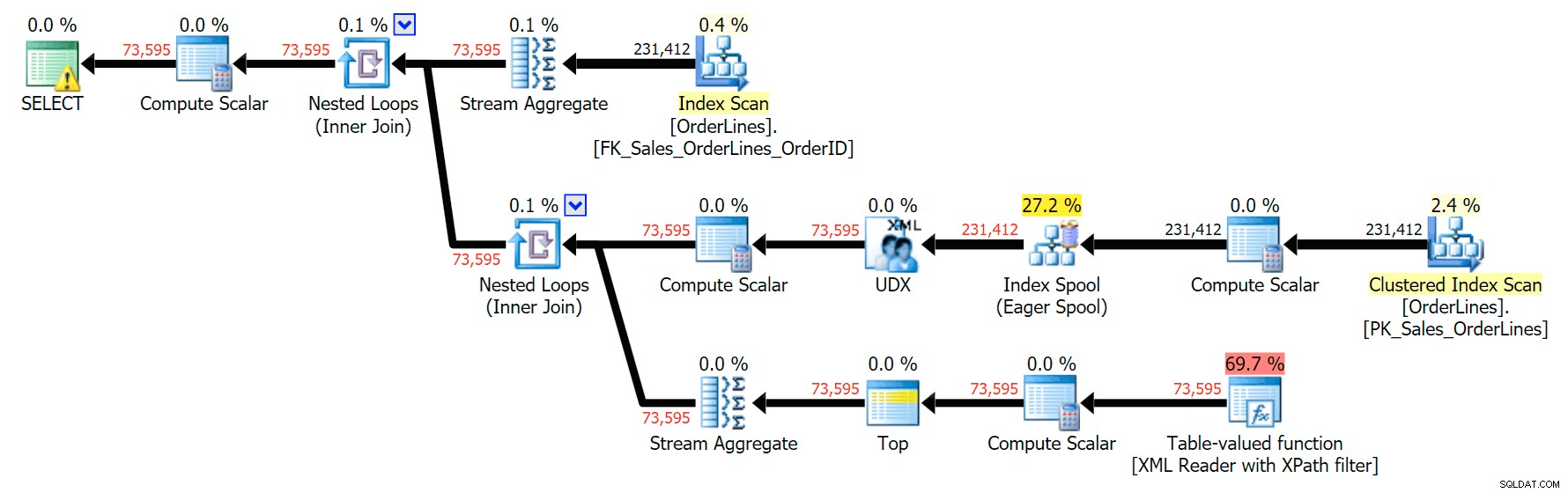
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Dies führt zu denselben Ergebnissen (obwohl die Bestellung zurückgekehrt ist) und zu einem etwas anderen Plan:
Die Leistungsmetriken sind jedoch interessant zu vergleichen.

Die DISTINCT-Variante benötigte im Vergleich zur GROUP BY-Variante 4-mal so lange, verbrauchte 4-mal die CPU und fast 6-mal so viele Lesevorgänge. (Denken Sie daran, dass diese Abfragen genau dieselben Ergebnisse zurückgeben.)
Wir können die Ausführungspläne auch vergleichen, wenn wir die Kosten von CPU + I/O kombiniert auf nur I/O ändern, eine exklusive Funktion von Plan Explorer. Wir zeigen auch die neu berechneten Werte (die auf dem tatsächlichen basieren während der Abfrageausführung beobachtete Kosten, eine Funktion, die ebenfalls nur im Plan-Explorer zu finden ist). Hier ist der DISTINCT-Plan:
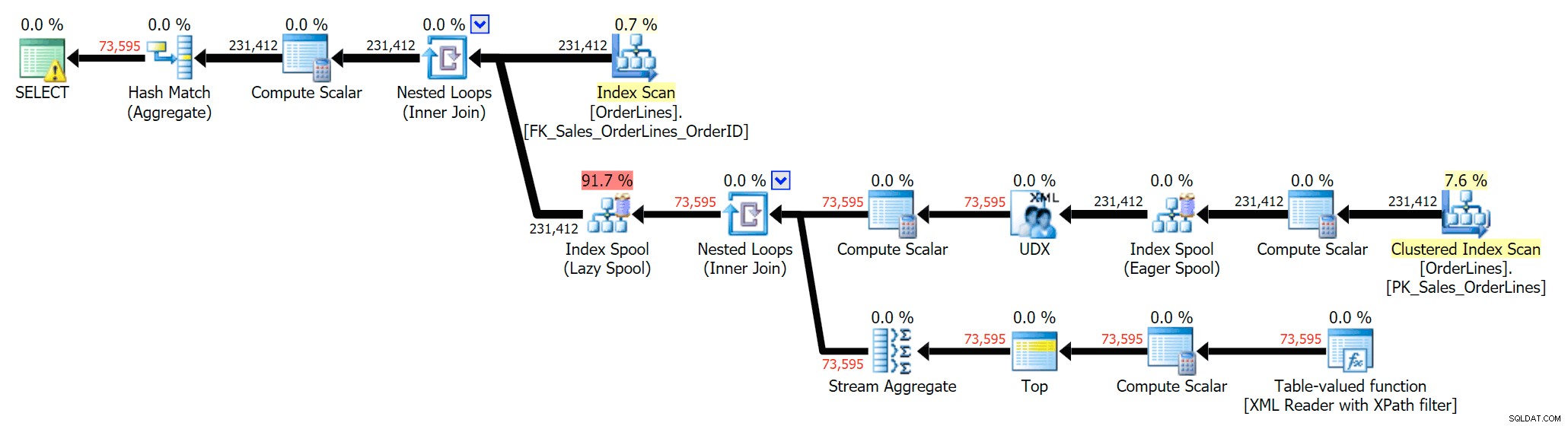
Und hier ist der GROUP BY-Plan:
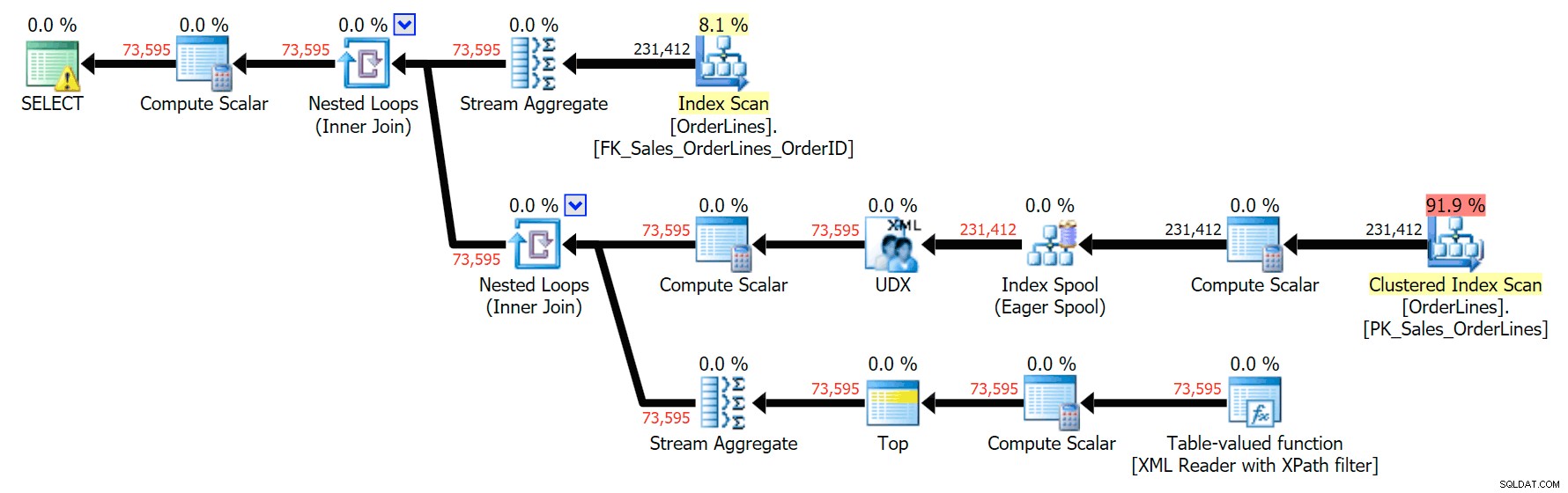
Sie können sehen, dass im GROUP BY-Plan fast alle E/A-Kosten in den Scans enthalten sind (hier ist der Tooltip für den CI-Scan, der E/A-Kosten von ~3,4 "Abfrage-Bucks" zeigt). Doch im DISTINCT-Plan liegen die meisten I/O-Kosten in der Index-Spool (und hier ist dieser Tooltip; die I/O-Kosten betragen hier ~41,4 "Abfrage-Bucks"). Beachten Sie, dass die CPU auch mit der Indexspule viel höher ist. Wir werden ein anderes Mal über "Abfragegelder" sprechen, aber der Punkt ist, dass die Indexspule mehr als 10-mal so teuer ist wie der Scan - der Scan ist jedoch in beiden Plänen immer noch derselbe 3.4. Dies ist einer der Gründe, warum es mich immer nervt, wenn Leute sagen, dass sie den Betreiber im Plan mit den höchsten Kosten „reparieren“ müssen. Einige Betreiber im Plan werden immer der teuerste sein; das bedeutet nicht, dass es repariert werden muss.
@AaronBertrand diese Abfragen sind nicht wirklich logisch äquivalent – DISTINCT ist auf beiden Spalten, während Ihr GROUP BY nur auf einer steht
– Adam Machanic (@AdamMachanic) 20. Januar 2017
Während Adam Machanic Recht hat, wenn er sagt, dass diese Abfragen semantisch unterschiedlich sind, ist das Ergebnis das gleiche – wir erhalten die gleiche Anzahl von Zeilen, die genau die gleichen Ergebnisse enthalten, und wir haben es mit viel weniger Lesevorgängen und CPU geschafft.
Während also DISTINCT und GROUP BY in vielen Szenarien identisch sind, ist hier ein Fall, in dem der GROUP BY-Ansatz definitiv zu einer besseren Leistung führt (auf Kosten einer weniger klaren deklarativen Absicht in der Abfrage selbst). Mich würde interessieren, ob es Ihrer Meinung nach Szenarien gibt, in denen DISTINCT besser ist als GROUP BY, zumindest in Bezug auf die Leistung, die weit weniger subjektiv als der Stil ist, oder ob eine Aussage selbstdokumentierend sein muss.
Dieser Beitrag passt in meine Reihe „Überraschungen und Annahmen“, da viele Dinge, die wir auf der Grundlage begrenzter Beobachtungen oder bestimmter Anwendungsfälle für wahr halten, in anderen Szenarien getestet werden können. Wir müssen nur daran denken, uns die Zeit dafür als Teil der SQL-Abfrageoptimierung zu nehmen…
Referenzen
- Gruppierte Verkettung in SQL Server
- Gruppierte Verkettung:Ordnen und Entfernen von Duplikaten
- Vier praktische Anwendungsfälle für die gruppierte Verkettung
- SQL Server v.Next :Leistung von STRING_AGG()
- SQL Server v.Next:STRING_AGG-Leistung, Teil 2



