Verstehen Sie mich nicht falsch – ich liebe die Eigenschaft Actual Rows Read, die wir in den Ausführungsplänen von SQL Server gesehen haben Ende 2015. Aber in SQL Server 2016 SP1, vor weniger als zwei Monaten (und wenn man bedenkt, dass wir Weihnachten dazwischen hatten, glaube ich nicht, dass die Zeit seitdem zählt), haben wir eine weitere aufregende Ergänzung bekommen – Geschätzte Anzahl zu lesender Zeilen (oh, und das hängt ein wenig mit dem von mir eingereichten Connect-Element zusammen, das beide zeigen, dass es sich lohnt, Connect-Elemente einzureichen, und diesen Beitrag für den T-SQL-Dienstag dieses Monats qualifiziert, der von Brent Ozar (@brento) zum Thema Connect-Elemente moderiert wird ).
Verstehen Sie mich nicht falsch – ich liebe die Eigenschaft Actual Rows Read, die wir in den Ausführungsplänen von SQL Server gesehen haben Ende 2015. Aber in SQL Server 2016 SP1, vor weniger als zwei Monaten (und wenn man bedenkt, dass wir Weihnachten dazwischen hatten, glaube ich nicht, dass die Zeit seitdem zählt), haben wir eine weitere aufregende Ergänzung bekommen – Geschätzte Anzahl zu lesender Zeilen (oh, und das hängt ein wenig mit dem von mir eingereichten Connect-Element zusammen, das beide zeigen, dass es sich lohnt, Connect-Elemente einzureichen, und diesen Beitrag für den T-SQL-Dienstag dieses Monats qualifiziert, der von Brent Ozar (@brento) zum Thema Connect-Elemente moderiert wird ).
Fassen wir einen Moment zusammen … Wenn die SQL-Engine auf Daten in einer Tabelle zugreift, verwendet sie entweder eine Scan-Operation oder eine Seek-Operation. Und es sei denn, dieser Seek hat ein Seek-Prädikat, das auf höchstens eine Zeile zugreifen kann (weil er nach einer Gleichheitsübereinstimmung in einer Reihe von Spalten sucht – könnte nur eine einzelne Spalte sein – die bekanntermaßen eindeutig sind), dann führt der Seek a aus RangeScan und verhält sich genau wie ein Scan, nur über die Teilmenge von Zeilen, die vom Seek-Prädikat erfüllt werden.
Die von einem Seek-Prädikat erfüllten Zeilen (im Fall eines RangeScan einer Seek-Operation) oder alle Zeilen in der Tabelle (im Fall einer Scan-Operation) werden im Wesentlichen auf die gleiche Weise behandelt. Beide werden möglicherweise vorzeitig beendet, wenn keine weiteren Zeilen vom Operator links von ihm angefordert werden, z. B. wenn ein Top-Operator irgendwo bereits genügend Zeilen erfasst hat oder wenn ein Merge-Operator keine weiteren Zeilen zum Abgleichen hat. Und beide können durch ein Residual Predicate (angezeigt als die Eigenschaft „Predicate“) weiter gefiltert werden, bevor die Zeilen überhaupt vom Scan/Seek-Operator bereitgestellt werden. Die Eigenschaften „Number of Rows“ und „Estimated Number of Rows“ würden uns mitteilen, wie viele Zeilen voraussichtlich vom Operator erzeugt werden, aber wir hatten keine Informationen darüber, wie viele Zeilen nur durch das Seek-Prädikat gefiltert würden. Wir konnten die TableCardinality sehen, aber das war nur für Scan-Operatoren wirklich nützlich, wo die Möglichkeit bestand, dass der Scan die gesamte Tabelle nach den benötigten Zeilen durchsuchte. Es war überhaupt nicht nützlich für Seeks.

Die Abfrage, die ich hier ausführe, bezieht sich auf die WideWorldImporters-Datenbank und lautet:
SELECT COUNT(*) FROM Sales.Orders WHERE SalespersonPersonID = 7 AND YEAR(OrderDate) = 2013 AND MONTH(OrderDate) = 4;
Außerdem habe ich einen Index im Spiel:
CREATE NONCLUSTERED INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders (SalespersonPersonID, OrderDate);
Dieser Index deckt ab – die Abfrage benötigt keine weiteren Spalten, um ihre Antwort zu erhalten – und wurde so konzipiert, dass ein Suchprädikat für SalespersonPersonID verwendet werden kann, wodurch die Daten schnell auf einen kleineren Bereich heruntergefiltert werden. Die Funktionen für OrderDate bedeuten, dass diese letzten beiden Prädikate nicht innerhalb des Seek-Prädikats verwendet werden können, sodass sie stattdessen in das Residual-Prädikat verbannt werden. Eine bessere Abfrage würde diese Daten mit OrderDate>='20130401' AND OrderDate <'20130501' filtern, aber ich stelle mir hier ein Szenario vor, das allzu häufig vorkommt …
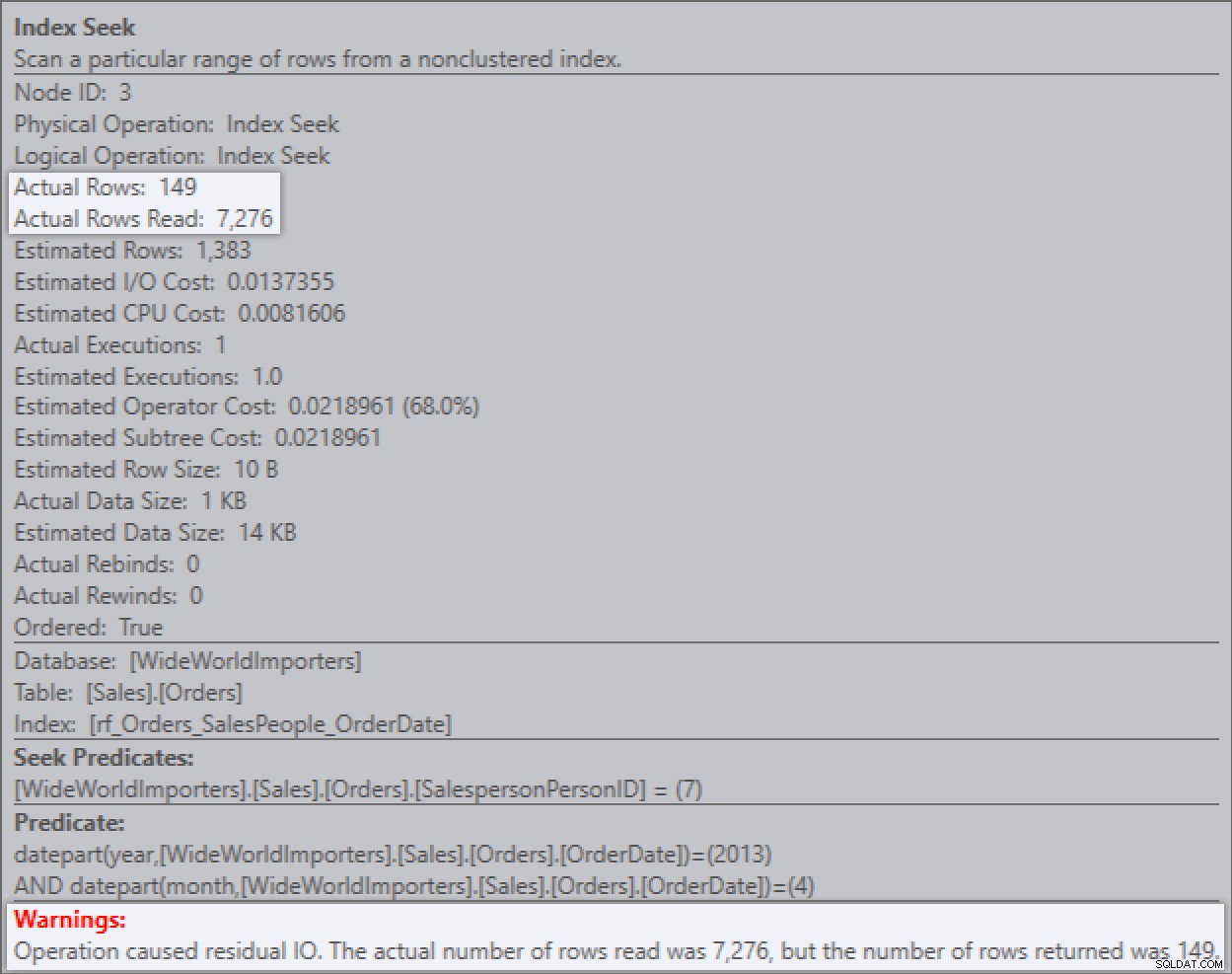
Wenn ich jetzt die Abfrage ausführe, kann ich die Auswirkung der Restprädikate sehen. Plan Explorer gibt sogar die nützliche Warnung aus, über die ich zuvor geschrieben hatte.

Ich kann sehr deutlich sehen, dass der RangeScan 7.276 Zeilen beträgt und dass das Residual Predicate dies auf 149 herunterfiltert. Plan Explorer zeigt weitere Informationen dazu im Tooltip:
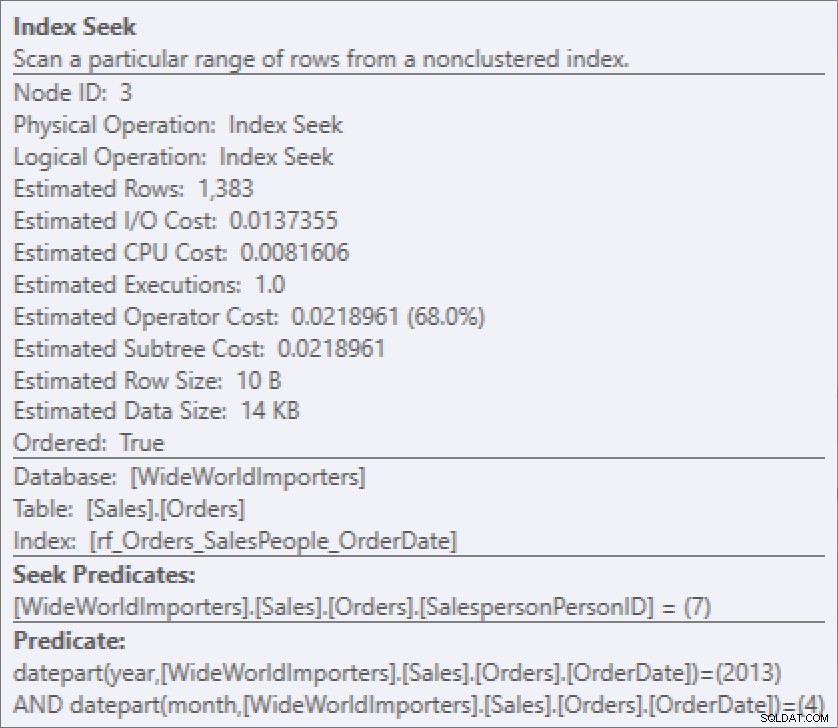
Aber ohne die Abfrage auszuführen, kann ich diese Informationen nicht sehen. Es ist einfach nicht da. Die Eigenschaften im geschätzten Plan haben es nicht:
Und ich bin mir sicher, dass ich Sie nicht daran erinnern muss – diese Informationen sind auch nicht im Plan-Cache vorhanden. Nachdem Sie den Plan aus dem Cache geholt haben mit:
SELECT p.query_plan, t.text FROM sys.dm_exec_cached_plans c CROSS APPLY sys.dm_exec_query_plan(c.plan_handle) p CROSS APPLY sys.dm_exec_sql_text(c.plan_handle) t WHERE t.text LIKE '%YEAR%';
Ich öffnete es und tatsächlich, kein Zeichen von diesem Wert von 7.276. Es sieht genauso aus wie der geschätzte Plan, den ich gerade gezeigt habe.
Beim Holen von Plänen aus dem Cache kommen die Schätzwerte voll zur Geltung. Es ist nicht nur so, dass ich es vorziehen würde, keine potenziell teuren Abfragen in Kundendatenbanken durchzuführen. Das Abfragen des Plan-Cache ist eine Sache, aber das Ausführen von Abfragen zum Abrufen der tatsächlichen Daten – das ist viel schwieriger.
Wenn SQL 2016 SP1 installiert ist, kann ich dank dieses Connect-Elements jetzt die Eigenschaft „Geschätzte Anzahl zu lesender Zeilen“ in geschätzten Plänen und im Plan-Cache sehen. Der hier gezeigte Operator-Tooltip stammt aus dem Cache, und ich kann leicht erkennen, dass die Estimated-Eigenschaft 7.276 anzeigt, sowie die verbleibende Warnung:
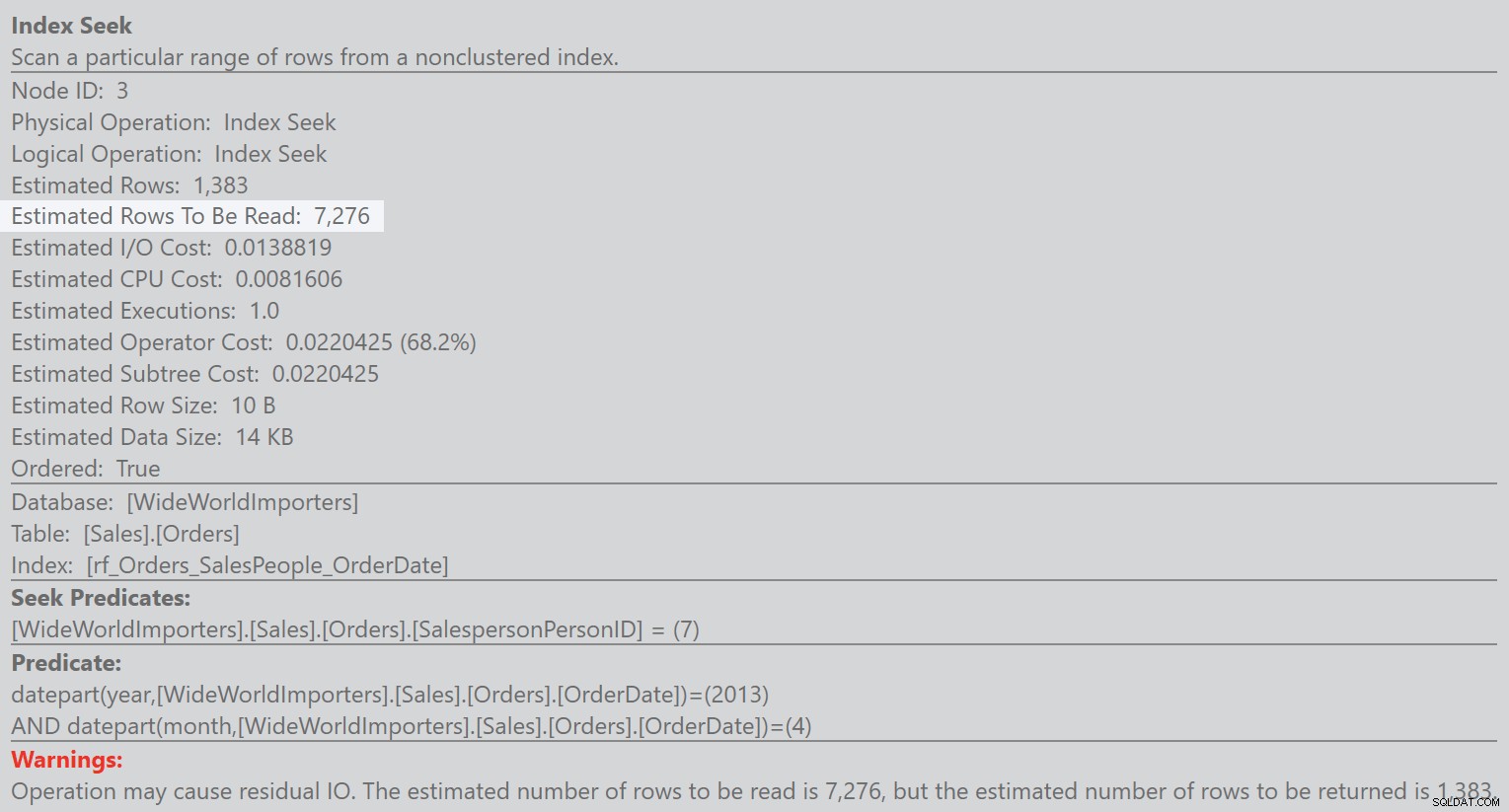
Dies ist etwas, was ich auf einer Kundenbox tun könnte, indem ich im Cache nach Situationen in problematischen Plänen suche, in denen das Verhältnis zwischen der geschätzten Anzahl der zu lesenden Zeilen und der geschätzten Anzahl der Zeilen nicht groß ist. Möglicherweise könnte jemand einen Prozess erstellen, der jeden Plan im Cache überprüft, aber ich habe das nicht getan.
Scharfsinniges Lesen wird bemerkt haben, dass die tatsächlichen Zeilen, die aus diesem Operator hervorgingen, 149 waren, was viel kleiner war als die geschätzten 1382,56. Aber wenn ich nach Restprädikaten suche, die zu viele Zeilen prüfen müssen, ist das Verhältnis von 1.382,56 :7.276 immer noch signifikant.
Nachdem wir nun festgestellt haben, dass diese Abfrage unwirksam ist, ohne dass sie überhaupt ausgeführt werden muss, können Sie sie beheben, indem Sie sicherstellen, dass das Residual Predicate ausreichend SARG-fähig ist. Diese Abfrage…
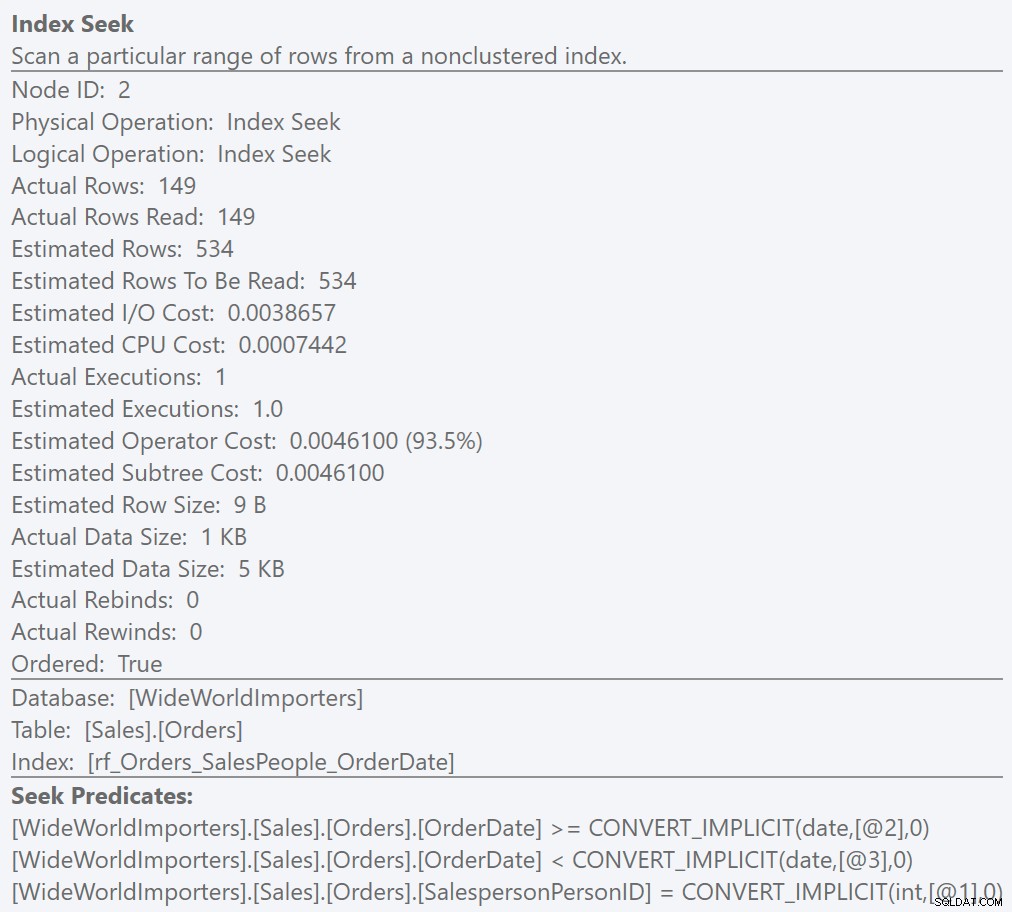
SELECT COUNT(*) FROM Sales.Orders WHERE SalespersonPersonID = 7 AND OrderDate >= '20130401' AND OrderDate < '20130501';
…ergibt die gleichen Ergebnisse und hat kein Residualprädikat. In dieser Situation ist der Wert für die geschätzte Anzahl der zu lesenden Zeilen identisch mit der geschätzten Anzahl der Zeilen, und die Ineffizienz ist verschwunden:
Wie bereits erwähnt, ist dieser Beitrag Teil des T-SQL-Dienstags dieses Monats. Warum gehen Sie nicht dorthin, um zu sehen, welche anderen Funktionsanfragen kürzlich gewährt wurden?