Ich wurde vor kurzem gescholten, weil ich angedeutet habe, dass in manchen Fällen ein Non-Clustered-Index für eine bestimmte Abfrage besser abschneidet als der Clustered-Index. Diese Person erklärte, dass der gruppierte Index immer am besten sei, weil er per Definition immer abdeckt, und dass jeder nicht gruppierte Index mit einigen oder allen gleichen Schlüsselspalten immer redundant sei.
Ich stimme gerne zu, dass der Clustered-Index immer abdeckt (und um hier Unklarheiten zu vermeiden, bleiben wir bei festplattenbasierten Tabellen mit traditionellen B-Tree-Indizes).
 Ich stimme jedoch nicht zu, dass ein gruppierter Index immer ist schneller als ein nicht gruppierter Index. Ich bin auch nicht der Meinung, dass es immer überflüssig ist, einen nicht geclusterten Index oder eine eindeutige Einschränkung zu erstellen, die aus denselben (oder einigen derselben) Spalten im Clustering-Schlüssel besteht.
Ich stimme jedoch nicht zu, dass ein gruppierter Index immer ist schneller als ein nicht gruppierter Index. Ich bin auch nicht der Meinung, dass es immer überflüssig ist, einen nicht geclusterten Index oder eine eindeutige Einschränkung zu erstellen, die aus denselben (oder einigen derselben) Spalten im Clustering-Schlüssel besteht.
Nehmen wir dieses Beispiel, Warehouse.StockItemTransactions , von WideWorldImporters. Der gruppierte Index wird durch einen Primärschlüssel nur auf der StockItemTransactionID implementiert Spalte (ziemlich typisch, wenn Sie eine Art Ersatz-ID haben, die von einer IDENTITÄT oder einer SEQUENZ generiert wird).
Es ist ziemlich üblich, eine Zählung der gesamten Tabelle zu verlangen (obwohl es in vielen Fällen bessere Möglichkeiten gibt). Dies kann für eine gelegentliche Inspektion oder als Teil eines Paginierungsverfahrens sein. Die meisten Leute werden es so machen:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Mit dem aktuellen Schema wird dies einen nicht geclusterten Index verwenden:
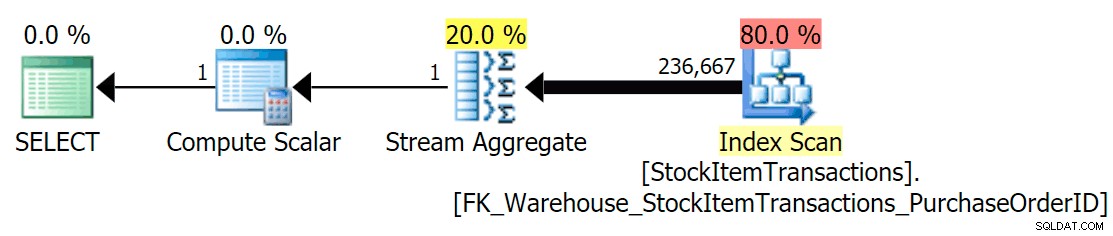
Wir wissen, dass der Non-Clustered-Index nicht alle Spalten des Clustered-Index enthält. Der Zählvorgang muss nur sicherstellen, dass alle Zeilen enthalten sind, ohne sich darum zu kümmern, welche Spalten vorhanden sind, sodass SQL Server normalerweise den Index mit der kleinsten Anzahl von Seiten auswählt (in diesem Fall hat der ausgewählte Index ~414 Seiten).
Lassen Sie uns nun die Abfrage erneut ausführen und sie dieses Mal mit einer angedeuteten Abfrage vergleichen, die die Verwendung des Clustered-Index erzwingt.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Wir erhalten eine fast identische Planform, aber wir können einen großen Unterschied bei den Lesevorgängen feststellen (414 für den ausgewählten Index gegenüber 1.982 für den geclusterten Index):
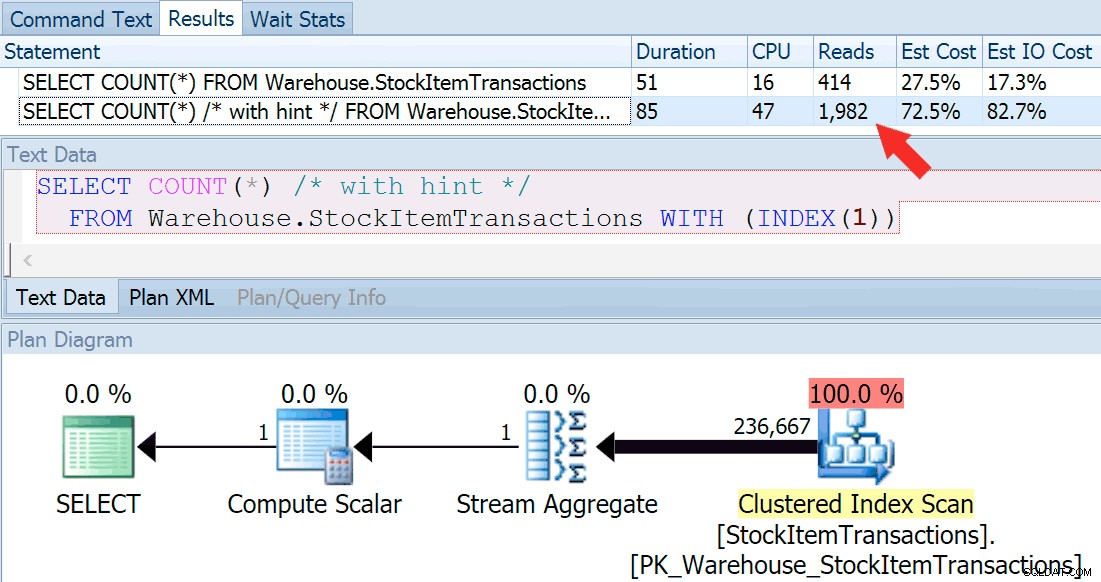
Die Dauer ist für den gruppierten Index etwas höher, aber der Unterschied ist vernachlässigbar, wenn wir es mit einer kleinen Menge zwischengespeicherter Daten auf einer schnellen Festplatte zu tun haben. Diese Diskrepanz wäre bei mehr Daten, auf einer langsamen Festplatte oder auf einem System mit Speichermangel viel ausgeprägter.
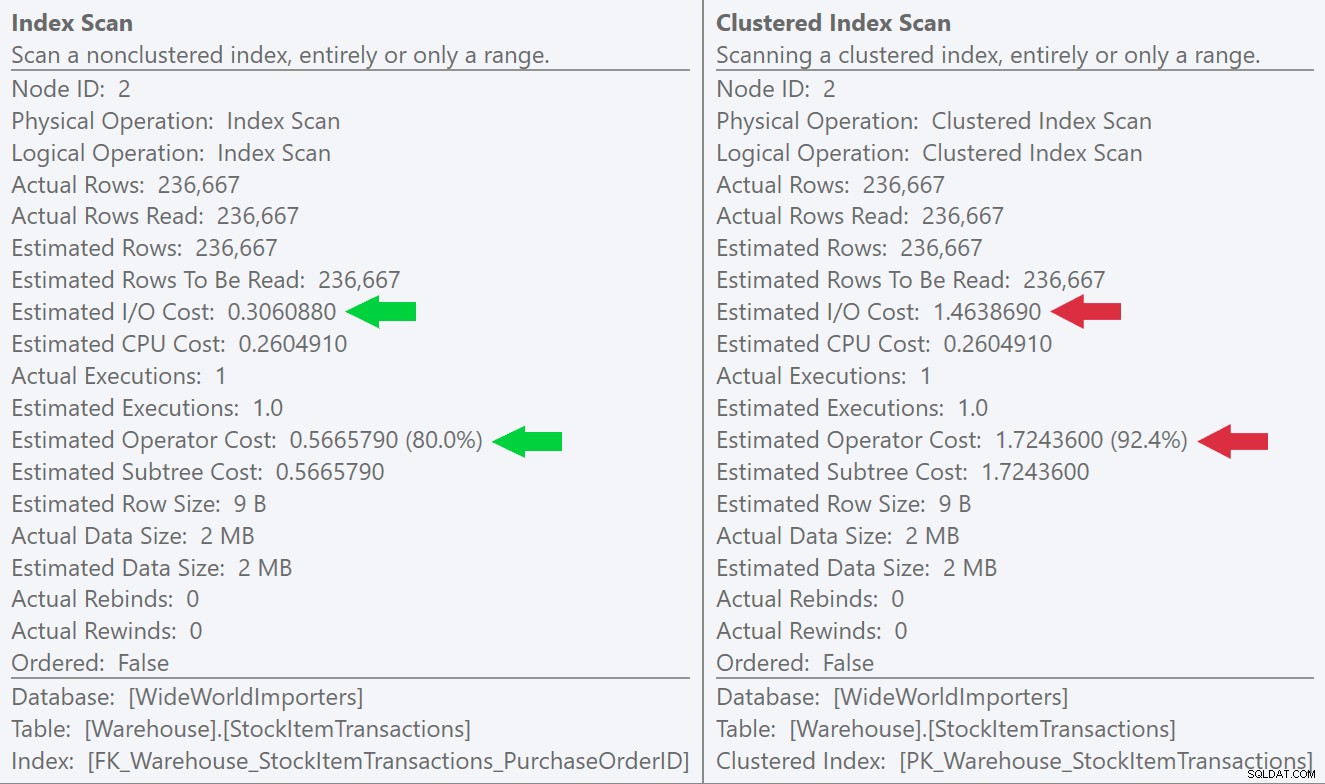
Wenn wir uns die QuickInfos für die Scanvorgänge ansehen, können wir sehen, dass die Anzahl der Zeilen und die geschätzten CPU-Kosten zwar identisch sind, der große Unterschied jedoch von den geschätzten E/A-Kosten herrührt (weil SQL Server weiß, dass es mehr Seiten in der gruppierter Index als der nicht gruppierte Index):
Wir können diesen Unterschied noch deutlicher erkennen, wenn wir einen neuen, eindeutigen Index nur für die ID-Spalte erstellen (was ihn "redundant" mit dem Clustered-Index macht, oder?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
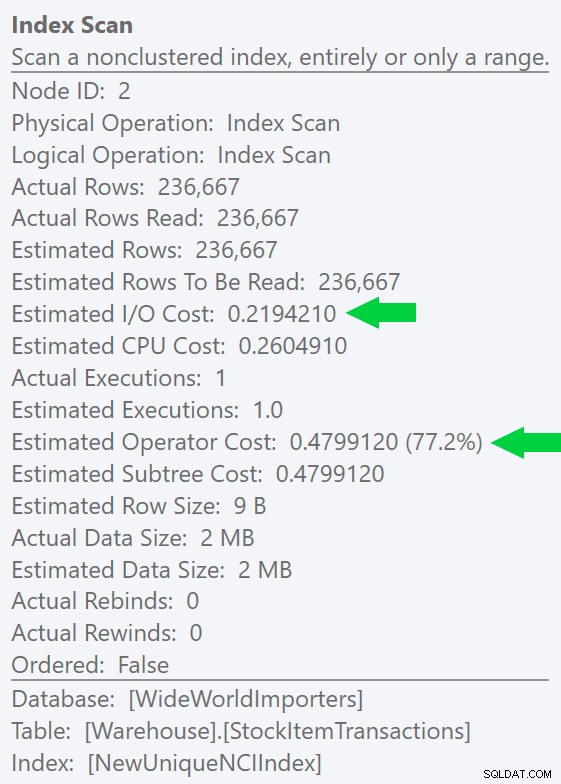 Das Ausführen einer ähnlichen Abfrage mit einem expliziten Indexhinweis erzeugt dieselbe Planform, aber eine noch niedrigere geschätzte E/A Kosten (und noch geringerer Dauer) – siehe Bild rechts. Und wenn Sie die ursprüngliche Abfrage ohne den Hinweis ausführen, werden Sie sehen, dass SQL Server jetzt auch diesen Index auswählt.
Das Ausführen einer ähnlichen Abfrage mit einem expliziten Indexhinweis erzeugt dieselbe Planform, aber eine noch niedrigere geschätzte E/A Kosten (und noch geringerer Dauer) – siehe Bild rechts. Und wenn Sie die ursprüngliche Abfrage ohne den Hinweis ausführen, werden Sie sehen, dass SQL Server jetzt auch diesen Index auswählt.
Es mag offensichtlich erscheinen, aber viele Leute würden glauben, dass der Clustered Index hier die beste Wahl ist. SQL Server wird fast immer die Methode stark bevorzugen, die die billigste Möglichkeit bietet, alle I/O-Vorgänge auszuführen, und im Falle eines vollständigen Scans wird dies der "dünnste" Index sein. Dies kann auch bei beiden Sucharten (Singleton- und Range-Scans) passieren, zumindest wenn der Index abdeckend ist.
Nun, wie immer, das tut es nicht bedeutet in keiner Weise, dass Sie zusätzliche Indizes für alle Ihre Tabellen erstellen sollten, um Zählabfragen zu erfüllen. Das ist nicht nur eine ineffiziente Methode, um die Tabellengröße zu überprüfen (siehe auch diesen Artikel), sondern ein zu unterstützender Index müsste bedeuten, dass Sie diese Abfrage häufiger ausführen, als Sie die Daten aktualisieren. Denken Sie daran, dass jeder Index Speicherplatz auf der Festplatte und im Arbeitsspeicher benötigt und dass alle Schreibvorgänge in die Tabelle auch jeden Index berühren müssen (ausgenommen gefilterte Indizes).
Zusammenfassung
Ich könnte mir viele andere Beispiele einfallen lassen, die zeigen, wann ein Non-Clustered nützlich sein und die Wartungskosten wert sein kann, selbst wenn die Schlüsselspalte(n) des Clustered-Index dupliziert werden. Nicht gruppierte Indizes können mit denselben Schlüsselspalten, aber in einer anderen Schlüsselreihenfolge oder mit unterschiedlichen ASC/DESC in den Spalten selbst erstellt werden, um eine alternative Präsentationsreihenfolge besser zu unterstützen. Durch die Verwendung eines Filters können Sie auch nicht gruppierte Indizes haben, die nur eine kleine Teilmenge der Zeilen enthalten. Wenn Sie schließlich Ihre häufigsten Abfragen mit dünneren, nicht geclusterten Indizes erfüllen können, ist dies auch besser für den Speicherverbrauch.
Aber eigentlich geht es mir bei dieser Serie nur darum, ein Gegenbeispiel zu zeigen, das die Torheit verdeutlicht, pauschale Aussagen wie diese zu machen. Ich überlasse Ihnen eine Erklärung von Paul White, der in einer Antwort von DBA.SE erklärt, warum ein solcher nicht geclusterter Index tatsächlich viel besser abschneiden kann als ein geclusterter Index. Dies gilt auch dann, wenn beide Suchtypen verwenden:
- Unterschied zwischen Clustered-Index-Suche und Non-Clustered-Index-Suche