Ein wichtiger Teil der Abfrageoptimierung ist das Verständnis der Algorithmen, die dem Optimierer zur Verfügung stehen, um verschiedene Abfragekonstrukte zu handhaben, z. B. Filtern, Verbinden, Gruppieren und Aggregieren, und wie sie skalieren. Dieses Wissen hilft Ihnen, eine optimale physische Umgebung für Ihre Abfragen vorzubereiten, z. B. die Erstellung der richtigen Indizes. Es hilft Ihnen auch, intuitiv zu erkennen, welchen Algorithmus Sie unter bestimmten Umständen im Plan sehen sollten, basierend auf Ihrer Vertrautheit mit den Schwellenwerten, bei denen der Optimierer von einem Algorithmus zum anderen wechseln sollte. Wenn Sie Abfragen mit schlechter Leistung optimieren, können Sie dann leichter Bereiche im Abfrageplan erkennen, in denen der Optimierer möglicherweise suboptimale Entscheidungen getroffen hat, z. B. aufgrund ungenauer Kardinalitätsschätzungen, und Maßnahmen ergreifen, um diese zu beheben.
Ein weiterer wichtiger Teil der Abfrageoptimierung ist das Denken über den Tellerrand hinaus – über die Algorithmen hinaus, die dem Optimierer zur Verfügung stehen, wenn er die offensichtlichen Tools verwendet. Seien Sie kreativ. Angenommen, Sie haben eine Abfrage, die schlecht funktioniert, obwohl Sie die optimale physische Umgebung eingerichtet haben. Für die von Ihnen verwendeten Abfragekonstrukte stehen dem Optimierer die Algorithmen x, y und z zur Verfügung, und der Optimierer wählte den besten aus, der unter den gegebenen Umständen möglich war. Dennoch führt die Abfrage schlecht. Können Sie sich einen theoretischen Plan mit einem Algorithmus vorstellen, der zu einer viel leistungsfähigeren Abfrage führen kann? Wenn Sie es sich vorstellen können, besteht die Möglichkeit, dass Sie es mit einigen Abfrageumschreibungen erreichen können, vielleicht mit weniger offensichtlichen Abfragekonstrukten für die Aufgabe.
In dieser Artikelserie konzentriere ich mich auf das Gruppieren und Aggregieren von Daten. Ich beginne damit, die Algorithmen durchzugehen, die dem Optimierer bei der Verwendung gruppierter Abfragen zur Verfügung stehen. Anschließend beschreibe ich Szenarien, in denen keiner der vorhandenen Algorithmen gut funktioniert, und zeige Abfrageumschreibungen, die zu einer hervorragenden Leistung und Skalierung führen.
Ich möchte Craig Freedman, Vassilis Papadimos und Joe Sack, Mitglieder der Schnittmenge der klügsten Leute der Welt und der Gruppe der SQL Server-Entwickler, für die Beantwortung meiner Fragen zur Abfrageoptimierung danken!
Für Beispieldaten verwende ich eine Datenbank namens PerformanceV3. Sie können hier ein Skript herunterladen, um die Datenbank zu erstellen und zu füllen. Ich verwende eine Tabelle namens dbo.Orders, die mit 1.000.000 Zeilen gefüllt ist. Diese Tabelle hat ein paar Indizes, die nicht benötigt werden und meine Beispiele stören könnten, also führen Sie den folgenden Code aus, um diese nicht benötigten Indizes zu löschen:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Die einzigen beiden Indizes, die in dieser Tabelle verbleiben, sind ein gruppierter Index namens idx_cl_od in der Spalte orderdate und ein nicht gruppierter eindeutiger Index namens PK_Orders in der Spalte orderid, wodurch die Primärschlüsseleinschränkung erzwungen wird.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Bestehende Algorithmen
SQL Server unterstützt zwei Hauptalgorithmen zum Aggregieren von Daten:Stream Aggregate und Hash Aggregate. Bei gruppierten Abfragen erfordert der Stream Aggregate-Algorithmus, dass die Daten nach den gruppierten Spalten sortiert werden, sodass Sie zwischen zwei Fällen unterscheiden müssen. Eines ist ein vorbestelltes Stromaggregat, z. B. wenn Daten vorbestellt von einem Index erhalten werden. Ein weiteres ist ein nicht vorbestelltes Stream Aggregate, bei dem ein zusätzlicher Schritt erforderlich ist, um die Eingabe explizit zu sortieren. Diese beiden Fälle werden sehr unterschiedlich skaliert, sodass Sie sie genauso gut als zwei verschiedene Algorithmen betrachten können.
Der Hash-Aggregate-Algorithmus organisiert die Gruppen und ihre Aggregate in einer Hash-Tabelle. Die Eingabe muss nicht geordnet werden.
Mit genügend Daten erwägt der Optimierer, die Arbeit zu parallelisieren, indem er ein sogenanntes lokal-globales Aggregat anwendet. In einem solchen Fall wird die Eingabe in mehrere Threads aufgeteilt, und jeder Thread wendet einen der oben genannten Algorithmen an, um seine Teilmenge von Zeilen lokal zu aggregieren. Ein globales Aggregat verwendet dann einen der oben genannten Algorithmen, um die Ergebnisse der lokalen Aggregate zu aggregieren.
In diesem Artikel konzentriere ich mich auf den vorbestellten Stream Aggregate-Algorithmus und seine Skalierung. In zukünftigen Teilen dieser Serie werde ich andere Algorithmen behandeln und die Schwellenwerte beschreiben, bei denen der Optimierer von einem zum anderen wechselt, und wann Sie das Umschreiben von Abfragen in Betracht ziehen sollten.
Vorbestelltes Stream-Aggregat
Bei einer gruppierten Abfrage mit einem nicht leeren Gruppierungssatz (dem Satz von Ausdrücken, nach dem Sie gruppieren) erfordert der Stream Aggregate-Algorithmus, dass die Eingabezeilen nach den Ausdrücken sortiert werden, die den Gruppierungssatz bilden. Wenn der Algorithmus die erste Zeile in einer Gruppe verarbeitet, initialisiert er ein Mitglied, das den Zwischenaggregatwert mit dem relevanten Wert enthält (z. B. den Wert der ersten Zeile für ein MAX-Aggregat). Wenn es eine nichterste Zeile in der Gruppe verarbeitet, weist es diesem Mitglied das Ergebnis einer Berechnung zu, die den Zwischensummenwert und den Wert der neuen Zeile umfasst (z. B. das Maximum zwischen dem Zwischensummenwert und dem neuen Wert). Sobald eines der Mitglieder des Gruppierungssatzes seinen Wert ändert oder die Eingabe verbraucht wird, gilt der aktuelle Gesamtwert als Endergebnis für die letzte Gruppe.
Eine Möglichkeit, die Daten so zu ordnen, wie es der Stream Aggregate-Algorithmus benötigt, besteht darin, sie von einem Index vorgeordnet zu erhalten. Sie müssen den Index mit den Spalten des Gruppierungssatzes als Schlüssel definieren – in beliebiger Reihenfolge. Sie möchten auch, dass der Index abdeckt. Betrachten Sie beispielsweise die folgende Abfrage (wir nennen sie Abfrage 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Ein optimaler Rowstore-Index zur Unterstützung dieser Abfrage wäre einer, der mit shipperid als führender Schlüsselspalte und orderdate entweder als eingeschlossene Spalte oder als zweite Schlüsselspalte definiert ist:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
Mit diesem Index erhalten Sie den in Abbildung 1 gezeigten geschätzten Plan (unter Verwendung von SentryOne Plan Explorer).

Abbildung 1:Plan für Abfrage 1
Beachten Sie, dass der Index Scan-Operator über eine Ordered:True-Eigenschaft verfügt, die angibt, dass er die nach dem Indexschlüssel geordneten Zeilen liefern muss. Der Stream Aggregate-Operator nimmt dann die geordneten Zeilen nach Bedarf auf. Wie die Kosten des Betreibers berechnet werden; bevor wir dazu kommen, ein kurzes Vorwort zuerst…
Wie Sie vielleicht bereits wissen, wertet SQL Server bei der Optimierung einer Abfrage mehrere Kandidatenpläne aus und wählt schließlich den Plan mit den niedrigsten geschätzten Kosten aus. Die geschätzten Plankosten sind die Summe aller geschätzten Kosten der Betreiber. Die geschätzten Kosten jedes Operators wiederum sind die Summe der geschätzten E/A-Kosten und der geschätzten CPU-Kosten. Die Kosteneinheit ist an sich bedeutungslos. Seine Relevanz liegt in dem Vergleich, den der Optimierer zwischen Kandidatenplänen durchführt. Das heißt, die Kalkulationsformeln wurden mit dem Ziel entwickelt, dass zwischen den Kandidatenplänen derjenige mit den niedrigsten Kosten (hoffentlich) derjenige ist, der schneller fertig wird. Eine furchtbar komplexe Aufgabe, um sie genau auszuführen!
Je mehr die Kalkulationsformeln die Faktoren angemessen berücksichtigen, die sich wirklich auf die Leistung und Skalierung des Algorithmus auswirken, desto genauer sind sie und desto wahrscheinlicher ist es, dass der Optimierer bei akkuraten Kardinalitätsschätzungen den optimalen Plan wählt. Wenn Sie verstehen wollen, warum der Optimierer einen Algorithmus gegenüber einem anderen auswählt, müssen Sie auf jeden Fall zwei Dinge verstehen:Zum einen die Funktionsweise und Skalierung der Algorithmen und zum anderen das Kostenmodell von SQL Server.
Also zurück zum Plan in Abbildung 1; Lassen Sie uns versuchen zu verstehen, wie die Kosten berechnet werden. Als Richtlinie wird Microsoft die internen Kalkulationsformeln, die sie verwenden, nicht offenlegen. Schon als Kind hat es mich fasziniert, Dinge auseinanderzunehmen. Uhren, Radios, Kassetten (ja, ich bin so alt), was auch immer. Ich wollte wissen, wie die Dinge hergestellt werden. Ebenso sehe ich einen Wert im Reverse Engineering der Formeln, denn wenn es mir gelingt, die Kosten einigermaßen genau vorherzusagen, bedeutet dies wahrscheinlich, dass ich den Algorithmus gut verstehe. Während des Prozesses lernt man viel.
Unsere Abfrage nimmt 1.000.000 Zeilen auf. Selbst bei dieser Anzahl von Zeilen scheinen die E/A-Kosten im Vergleich zu den CPU-Kosten vernachlässigbar zu sein, daher ist es wahrscheinlich sicher, sie zu ignorieren.
Was die CPU-Kosten betrifft, sollten Sie versuchen herauszufinden, welche Faktoren sie auf welche Weise beeinflussen. Theoretisch könnte es eine Reihe von Faktoren geben:Anzahl der Eingabezeilen, Anzahl der Gruppen, Kardinalität des Gruppierungssatzes, Datentyp und Größe der Mitglieder des Gruppierungssatzes. Um also zu versuchen, die Wirkung eines dieser Faktoren zu messen, möchten Sie die geschätzten Kosten von zwei Abfragen vergleichen, die sich nur in dem Faktor unterscheiden, den Sie messen möchten. Um beispielsweise die Auswirkungen der Anzahl der Zeilen auf die Kosten zu messen, führen Sie zwei Abfragen mit einer unterschiedlichen Anzahl von Eingabezeilen durch, bei denen jedoch alle anderen Aspekte gleich sind (Anzahl der Gruppen, Kardinalität des Gruppierungssatzes usw.). Außerdem ist es wichtig zu überprüfen, ob die geschätzten Zahlen – nicht die tatsächlichen – den gewünschten Zahlen entsprechen, da sich der Optimierer auf die geschätzten Zahlen stützt, um die Kosten zu berechnen.
Wenn Sie solche Vergleiche durchführen, ist es gut, Techniken zu haben, mit denen Sie die geschätzten Zahlen vollständig kontrollieren können. Eine einfache Möglichkeit, die geschätzte Anzahl der Eingabezeilen zu steuern, besteht beispielsweise darin, einen Tabellenausdruck abzufragen, der auf einer TOP-Abfrage basiert, und die Aggregatfunktion in der äußeren Abfrage anzuwenden. Wenn Sie befürchten, dass der Optimierer aufgrund Ihrer Verwendung des TOP-Operators Zeilenziele anwendet und diese zu einer Anpassung der ursprünglichen Kosten führen, gilt dies nur für Operatoren, die im Plan unter dem Top-Operator erscheinen (bis zum rechts), nicht oben (links). Der Stream Aggregate-Operator wird im Plan natürlich über dem Top-Operator angezeigt, da er die gefilterten Zeilen aufnimmt.
Zur Steuerung der geschätzten Anzahl von Ausgabegruppen können Sie dies tun, indem Sie den Gruppierungsausdruck
Um sicherzustellen, dass Sie den Stream Aggregate-Algorithmus und einen seriellen Plan erhalten, können Sie dies mit den Abfragehinweisen erzwingen:OPTION(ORDER GROUP, MAXDOP 1).
Sie möchten auch herausfinden, ob für den Betreiber Startkosten anfallen, damit Sie diese in Ihrer Reverse-Engineering-Formel berücksichtigen können.
Beginnen wir damit, herauszufinden, wie sich die Anzahl der Eingabezeilen auf die geschätzten CPU-Kosten des Operators auswirkt. Natürlich sollte dieser Faktor für die Kosten des Betreibers relevant sein. Außerdem würden Sie erwarten, dass die Kosten pro Zeile konstant sind. Hier sind ein paar Abfragen zum Vergleich, die sich nur in der geschätzten Anzahl der Eingabezeilen unterscheiden (nennen Sie sie Abfrage 2 bzw. Abfrage 3):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Abbildung 2 enthält die relevanten Teile der geschätzten Pläne für diese Abfragen:

Abbildung 2:Pläne für Abfrage 2 und Abfrage 3
Unter der Annahme, dass die Kosten pro Zeile konstant sind, können Sie sie als Differenz zwischen den Operatorkosten dividiert durch die Differenz zwischen den Operatoreingabekardinalitäten berechnen:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
Um zu überprüfen, ob die erhaltene Zahl tatsächlich konstant und korrekt ist, können Sie versuchen, die geschätzten Kosten in Abfragen mit einer anderen Anzahl von Eingabezeilen vorherzusagen. Die vorhergesagten Kosten mit 500.000 Eingabezeilen betragen beispielsweise:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Verwenden Sie die folgende Abfrage, um zu überprüfen, ob Ihre Vorhersage korrekt ist (nennen Sie sie Abfrage 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Der relevante Teil des Plans für diese Abfrage ist in Abbildung 3 dargestellt.
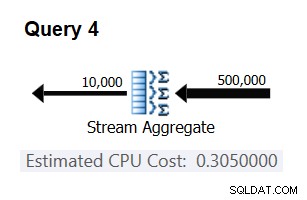
Abbildung 3:Plan für Abfrage 4
Bingo. Natürlich ist es eine gute Idee, mehrere zusätzliche Eingabekardinalitäten zu überprüfen. Bei allen, die ich überprüft habe, war die These, dass es konstante Kosten pro Eingabezeile von 0,0000006 gibt, richtig.
Versuchen wir als Nächstes herauszufinden, wie sich die geschätzte Anzahl von Gruppen auf die CPU-Kosten des Operators auswirkt. Sie würden erwarten, dass einige CPU-Arbeit erforderlich ist, um jede Gruppe zu verarbeiten, und es ist auch vernünftig zu erwarten, dass sie pro Gruppe konstant ist. Um diese These zu überprüfen und die Kosten pro Gruppe zu berechnen, können Sie die folgenden zwei Abfragen verwenden, die sich nur in der Anzahl der Ergebnisgruppen unterscheiden (nennen Sie sie Abfrage 5 bzw. Abfrage 6):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
Die relevanten Teile der geschätzten Abfragepläne sind in Abbildung 4 dargestellt.
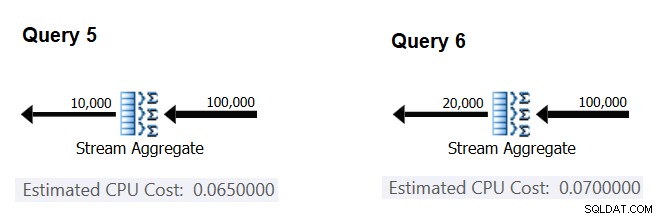
Abbildung 4:Pläne für Abfrage 5 und Abfrage 6
Ähnlich wie Sie die Fixkosten pro Eingabezeile berechnet haben, können Sie die Fixkosten pro Ausgabegruppe als Differenz zwischen den Operatorkosten dividiert durch die Differenz zwischen den Operatorausgabekardinalitäten berechnen:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
Und genau wie ich zuvor gezeigt habe, können Sie Ihre Ergebnisse überprüfen, indem Sie die Kosten mit einer anderen Anzahl von Ausgabegruppen vorhersagen und Ihre vorhergesagten Zahlen mit den vom Optimierer erzeugten vergleichen. Bei allen Gruppenzahlen, die ich ausprobiert habe, waren die prognostizierten Kosten genau.
Mit ähnlichen Techniken können Sie prüfen, ob andere Faktoren die Kosten des Betreibers beeinflussen. Meine Tests zeigen, dass die Kardinalität des Gruppierungssatzes (Anzahl der Ausdrücke, nach denen Sie gruppieren), die Datentypen und Größen der gruppierten Ausdrücke keinen Einfluss auf die geschätzten Kosten haben.
Was bleibt, ist zu prüfen, ob für den Betreiber sinnvolle Anlaufkosten angenommen werden. Wenn es eine gibt, sollte die vollständige (hoffentlich) Formel zur Berechnung der CPU-Kosten des Betreibers lauten:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
So können Sie die Startkosten aus dem Rest ableiten:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
Sie können für diesen Zweck einen beliebigen Abfrageplan aus diesem Artikel verwenden. Wenn Sie beispielsweise die Zahlen aus dem Plan für Abfrage 5 verwenden, der zuvor in Abbildung 4 gezeigt wurde, erhalten Sie Folgendes:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Wie es scheint, hat der Stream Aggregate-Operator keine CPU-bezogenen Startkosten oder sie sind so niedrig, dass sie nicht mit der Genauigkeit der Kostenmessung angezeigt werden.
Zusammenfassend lautet die rückentwickelte Formel für die Betreiberkosten von Stream Aggregate:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Abbildung 5 zeigt die Skalierung der Kosten des Stream Aggregate-Operators in Bezug auf die Anzahl der Zeilen und die Anzahl der Gruppen.
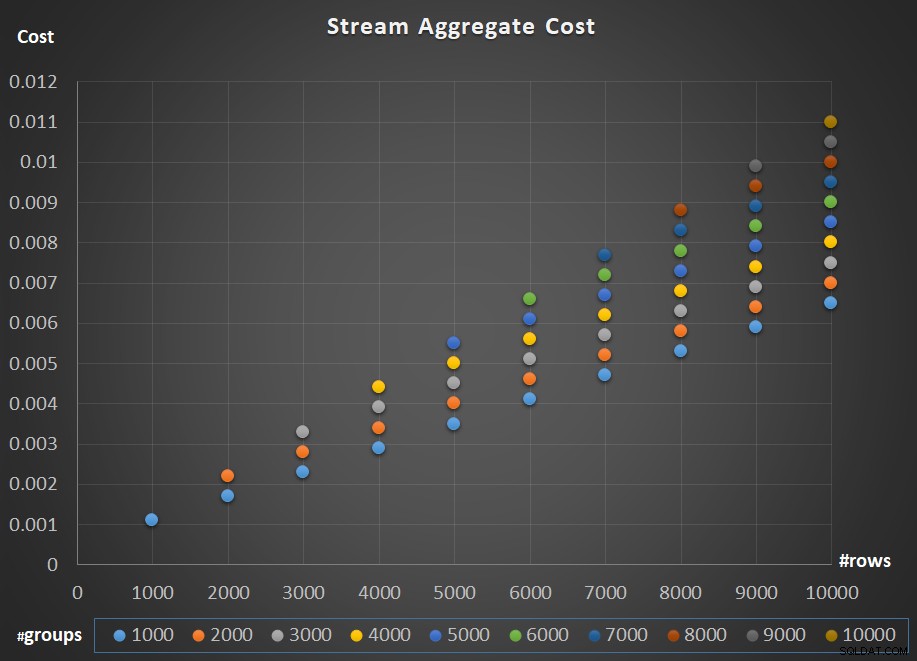
Abbildung 5:Skalierungsdiagramm des Stream Aggregate-Algorithmus
Wie für die Skalierung des Operators; es ist linear. In Fällen, in denen die Anzahl der Gruppen tendenziell proportional zur Anzahl der Reihen ist, steigen die Kosten des gesamten Betreibers um den gleichen Faktor, um den sowohl die Anzahl der Reihen als auch die Gruppen steigen. Das bedeutet, dass die Verdopplung der Anzahl sowohl der Eingangsreihen als auch der Eingangsgruppen zu einer Verdoppelung der gesamten Betreiberkosten führt. Um zu verstehen warum, nehmen wir an, dass wir die Kosten des Operators wie folgt darstellen:
r * 0.0000006 + g * 0.0000005
Wenn Sie sowohl die Anzahl der Zeilen als auch die Anzahl der Gruppen um den gleichen Faktor p erhöhen, erhalten Sie:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Wenn also für eine gegebene Anzahl von Zeilen und Gruppen die Kosten des Stream Aggregate-Operators C betragen, führt eine Erhöhung sowohl der Anzahl von Zeilen als auch der Gruppen um den gleichen Faktor p zu Operatorkosten von pC. Prüfen Sie, ob Sie dies überprüfen können, indem Sie Beispiele in der Tabelle in Abbildung 5 identifizieren.
In Fällen, in denen die Anzahl der Gruppen ziemlich stabil bleibt, selbst wenn die Anzahl der Eingabezeilen wächst, erhalten Sie immer noch eine lineare Skalierung. Betrachten Sie einfach die mit der Anzahl der Gruppen verbundenen Kosten als Konstante. Das heißt, wenn für eine gegebene Anzahl von Zeilen und Gruppen die Kosten des Operators C =G (Kosten in Verbindung mit der Anzahl von Gruppen) plus R (Kosten in Verbindung mit der Anzahl von Zeilen) sind, wird nur die Anzahl der Zeilen um einen Faktor von erhöht p ergibt G + pR. In einem solchen Fall sind die Kosten des gesamten Betreibers natürlich geringer als pC. Das heißt, die Verdoppelung der Anzahl der Zeilen führt zu weniger als einer Verdoppelung der gesamten Betreiberkosten.
In der Praxis ist beim Gruppieren von Daten in vielen Fällen die Anzahl der Eingabezeilen wesentlich größer als die Anzahl der Ausgabegruppen. Diese Tatsache, kombiniert mit der Tatsache, dass die zugewiesenen Kosten pro Reihe und Kosten pro Gruppe fast gleich sind, wird der Anteil der Kosten des Betreibers, der der Anzahl der Gruppen zugeschrieben wird, vernachlässigbar. Sehen Sie sich als Beispiel den Plan für Abfrage 1 an, der zuvor in Abbildung 1 gezeigt wurde. In solchen Fällen können Sie sich die Kosten des Operators einfach als lineare Skalierung in Bezug auf die Anzahl der Eingabezeilen vorstellen.
Sonderfälle
Es gibt spezielle Fälle, in denen der Stream Aggregate-Operator die Daten überhaupt nicht sortiert benötigt. Wenn Sie darüber nachdenken, hat der Stream Aggregate-Algorithmus eine entspanntere Sortieranforderung von der Eingabe im Vergleich dazu, wenn Sie die Daten zu Präsentationszwecken geordnet benötigen, z. B. wenn die Abfrage eine äußere Präsentations-ORDER BY-Klausel hat. Der Stream Aggregate-Algorithmus erfordert lediglich, dass alle Zeilen aus derselben Gruppe zusammen geordnet werden. Nehmen Sie den Eingabesatz {5, 1, 5, 2, 1, 2}. Für Präsentationszwecke muss dieser Satz wie folgt geordnet werden:1, 1, 2, 2, 5, 5. Für Aggregationszwecke würde der Stream Aggregate-Algorithmus immer noch gut funktionieren, wenn die Daten in der folgenden Reihenfolge angeordnet wären:5, 5, 1, 1, 2, 2. Wenn Sie also ein skalares Aggregat berechnen (Abfrage mit einer Aggregatfunktion und ohne GROUP BY-Klausel) oder die Daten nach einem leeren Gruppierungssatz gruppieren, gibt es nie mehr als eine Gruppe . Unabhängig von der Reihenfolge der Eingabezeilen kann der Stream Aggregate-Algorithmus angewendet werden. Der Hash-Aggregate-Algorithmus hasht die Daten basierend auf den Ausdrücken des Gruppierungssatzes als Eingaben, und sowohl bei skalaren Aggregaten als auch bei einem leeren Gruppierungssatz gibt es keine Eingaben zum Hashen. Sowohl bei skalaren Aggregaten als auch bei Aggregaten, die auf einen leeren Gruppierungssatz angewendet werden, verwendet der Optimierer also immer den Stream Aggregate-Algorithmus, ohne dass die Daten vorgeordnet werden müssen. Das ist zumindest im Zeilenausführungsmodus der Fall, da der Batchmodus derzeit (ab SQL Server 2017 CU4) nur mit dem Hash-Aggregate-Algorithmus verfügbar ist. Ich werde die folgenden zwei Abfragen verwenden, um dies zu demonstrieren (nennen Sie sie Abfrage 7 und Abfrage 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Die Pläne für diese Abfragen sind in Abbildung 6 dargestellt.
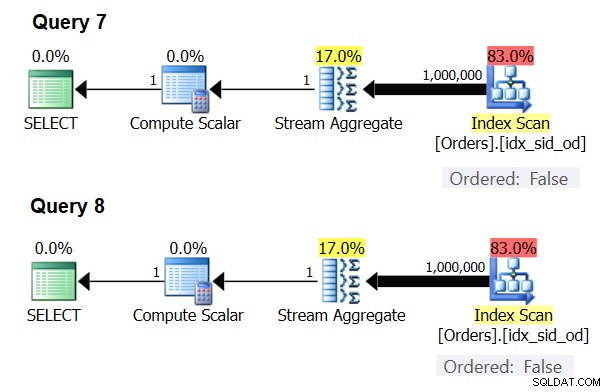
Abbildung 6:Pläne für Abfrage 7 und Abfrage 8
Versuchen Sie, in beiden Fällen einen Hash-Aggregate-Algorithmus zu erzwingen:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
Der Optimierer ignoriert Ihre Anfrage und erstellt dieselben Pläne wie in Abbildung 6.
Schnelles Quiz:Was ist der Unterschied zwischen einem skalaren Aggregat und einem Aggregat, das auf einen leeren Gruppierungssatz angewendet wird?
Antwort:Bei einer leeren Eingabemenge gibt ein skalares Aggregat ein Ergebnis mit einer Zeile zurück, während ein Aggregat in einer Abfrage mit einer leeren Gruppierungsmenge eine leere Ergebnismenge zurückgibt. Probieren Sie es aus:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Wenn Sie fertig sind, führen Sie den folgenden Code zur Bereinigung aus:
DROP INDEX idx_sid_od ON dbo.Orders;
Zusammenfassung und Herausforderung
Das Reverse-Engineering der Kalkulationsformel für den Stream Aggregate-Algorithmus ist ein Kinderspiel. Ich hätte Ihnen einfach sagen können, dass die Kostenformel für einen vorbestellten Stream Aggregate-Algorithmus @numrows * 0,0000006 + @numgroups * 0,0000005 lautet, anstatt einen ganzen Artikel zu erklären, wie Sie das herausfinden. Es ging jedoch darum, den Prozess und die Prinzipien des Reverse-Engineering zu beschreiben, bevor wir uns den komplexeren Algorithmen und den Schwellenwerten zuwenden, bei denen ein Algorithmus optimaler wird als die anderen. Dir beibringen, wie man fischt, anstatt dir so etwas wie Fisch zu geben. Ich habe so viel gelernt und Dinge entdeckt, über die ich noch nicht einmal nachgedacht habe, während ich versuchte, Kostenformeln für verschiedene Algorithmen zurückzuentwickeln.
Sind Sie bereit, Ihre Fähigkeiten zu testen? Ihre Mission, sollten Sie sich entscheiden, sie anzunehmen, ist eine Stufe schwieriger als das Reverse-Engineering des Stream Aggregate-Operators. Reverse-Engineering der Kalkulationsformel eines seriellen Sort-Operators. Dies ist für unsere Forschung wichtig, da ein Stream Aggregate-Algorithmus, der für eine Abfrage mit einem nicht leeren Gruppierungssatz angewendet wird, bei dem die Eingabedaten nicht vorgeordnet sind, eine explizite Sortierung erfordert. In einem solchen Fall hängen die Kosten und die Skalierung der Aggregatoperation von den Kosten und der Skalierung der Sort- und Stream-Aggregate-Operatoren zusammen ab.
Wenn Sie es schaffen, die Kosten des Sort-Operators angemessen vorherzusagen, können Sie das Gefühl haben, dass Sie das Recht verdient haben, Ihrer Signatur „Reverse Engineer“ hinzuzufügen. Es gibt viele Softwareentwickler da draußen; aber Sie sehen sicherlich nicht viele Reverse Engineers! Stellen Sie einfach sicher, dass Sie Ihre Formel sowohl mit kleinen als auch mit großen Zahlen testen. Sie werden vielleicht überrascht sein, was Sie finden.