Dieser Beitrag ist Teil einer Reihe von Artikeln über Zeilenziele. Den ersten Teil finden Sie hier:
- Teil 1:Festlegen und Identifizieren von Zeilenzielen
Es ist relativ bekannt, dass die Verwendung von TOP oder ein FAST n Abfragehinweis kann ein Zeilenziel in einem Ausführungsplan festlegen (siehe Festlegen und Identifizieren von Zeilenzielen in Ausführungsplänen, wenn Sie eine Auffrischung zu Zeilenzielen und ihren Ursachen benötigen). Es wird eher weniger allgemein anerkannt, dass Semi-Joins (und Anti-Joins) auch ein Zeilenziel einführen können, obwohl dies etwas weniger wahrscheinlich ist als bei TOP , FAST und SET ROWCOUNT .
Dieser Artikel hilft Ihnen zu verstehen, wann und warum ein Semi-Join die Zeilenziellogik des Optimierers aufruft.
Semi-Joins
Ein Semi-Join gibt eine Zeile aus einer Join-Eingabe (A) zurück, wenn mindestens eine vorhanden ist übereinstimmende Zeile auf der anderen Join-Eingabe (B).
Die wesentlichen Unterschiede zwischen einem Semi-Join und einem regulären Join sind:
- Semi-Join gibt entweder jede Zeile von Eingabe A zurück oder nicht. Es kann keine Zeilenduplizierung auftreten.
- Normaler Join dupliziert Zeilen, wenn es mehrere Übereinstimmungen mit dem Join-Prädikat gibt.
- Semi-Join ist so definiert, dass nur Spalten von Eingabe A zurückgegeben werden.
- Ein regulärer Join kann Spalten von einer (oder beiden) Join-Eingaben zurückgeben.
T-SQL unterstützt derzeit keine direkte Syntax wie FROM A SEMI JOIN B ON A.x = B.y , also müssen wir indirekte Formen wie EXISTS verwenden , SOME/ANY (einschließlich der entsprechenden Abkürzung IN für Gleichheitsvergleiche) und setzen Sie INTERSECT .
Die obige Beschreibung eines Semi-Joins weist natürlich auf die Anwendung eines Zeilenziels hin, da wir daran interessiert sind, jede passende Zeile zu finden in B nicht alle diese Zeilen . Trotzdem führt ein in T-SQL ausgedrückter logischer Semi-Join aus mehreren Gründen möglicherweise nicht zu einem Ausführungsplan, der ein Zeilenziel verwendet, was wir als Nächstes entpacken werden.
Umwandlung und Vereinfachung
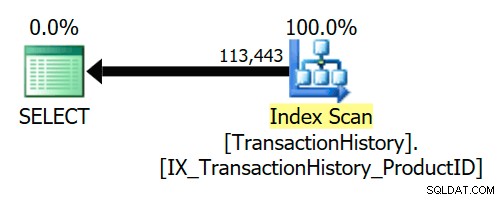
Ein logischer Semi-Join kann während der Abfragekompilierung und -optimierung wegvereinfacht oder durch etwas anderes ersetzt werden. Das AdventureWorks-Beispiel unten zeigt, dass ein Semi-Join aufgrund einer vertrauenswürdigen Fremdschlüsselbeziehung vollständig entfernt wird:
SELECT TH.ProductID FROM Production.TransactionHistory AS THWHERE TH.ProductID IN( SELECT P.ProductID FROM Production.Product ASP);
Der Fremdschlüssel stellt sicher, dass Product Zeilen werden immer für jede History-Zeile vorhanden sein. Folglich greift der Ausführungsplan nur auf die TransactionHistory zu Tabelle:
Ein häufigeres Beispiel ist, wenn der Semi-Join in einen Inner-Join umgewandelt werden kann. Zum Beispiel:
SELECT P.ProductID FROM Production.Product AS P WHERE EXISTS( SELECT * FROM Production.ProductInventory AS INV WHERE INV.ProductID =P.ProductID);
Der Ausführungsplan zeigt, dass der Optimierer ein Aggregat eingeführt hat (Gruppierung nach INV.ProductID ), um sicherzustellen, dass der innere Join nur Product zurückgeben kann Zeilen einmal oder gar nicht (wie erforderlich, um die Semi-Join-Semantik beizubehalten):
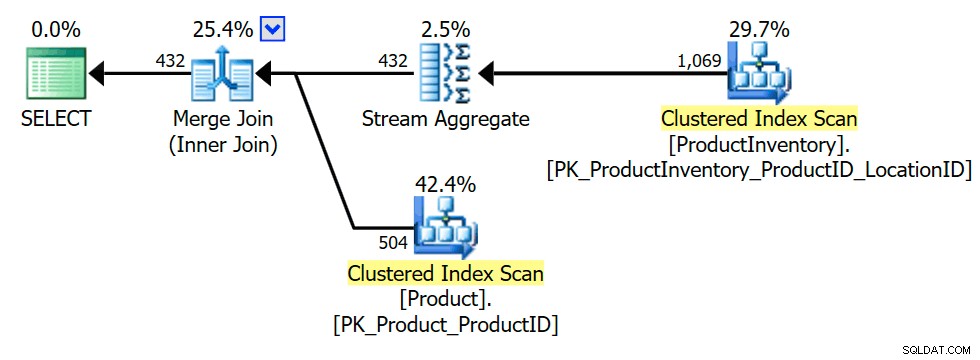
Die Umwandlung in Inner Join wird früh untersucht, da der Optimierer mehr Tricks für Inner Equijoins kennt als für Semi Joins, was möglicherweise zu mehr Optimierungsmöglichkeiten führt. Natürlich ist die endgültige Planwahl immer noch eine kostenbasierte Entscheidung unter den untersuchten Alternativen.
Frühe Optimierungen
Obwohl T-SQL der direkte SEMI JOIN fehlt -Syntax weiß der Optimierer von Haus aus alles über Semi-Joins und kann sie direkt manipulieren. Die üblichen Semi-Join-Syntaxen zur Problemumgehung werden früh im Abfragekompilierungsprozess in einen "echten" internen Semi-Join umgewandelt (lange bevor auch nur ein trivialer Plan in Betracht gezogen wird).
Die beiden Hauptsyntaxgruppen zur Problemumgehung sind EXISTS/INTERSECT , und ANY/SOME/IN . Der EXISTS und INTERSECT Fälle unterscheiden sich nur dadurch, dass letzterer mit einem impliziten DISTINCT kommt (Gruppierung auf alle projizierten Säulen). Beide EXISTS und INTERSECT werden als EXISTS geparst mit korrelierter Unterabfrage. Der ANY/SOME/IN Darstellungen werden alle als EINIGE Operation interpretiert. Wir können diese Optimierungsaktivität frühzeitig mit einigen undokumentierten Trace-Flags untersuchen, die Informationen über die Optimiereraktivität an die Registerkarte SSMS-Nachrichten senden.
Beispielsweise kann der bisher verwendete Semi-Join auch mit IN geschrieben werden :
SELECT P.ProductIDFROM Production.Product AS PWHERE P.ProductID IN /* or =ANY/SOME */( SELECT TH.ProductID FROM Production.TransactionHistory AS TH)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);
Der Eingabebaum des Optimierers sieht wie folgt aus:

Der Skalaroperator ScaOp_SomeComp ist das SOME Vergleich oben erwähnt. Die 2 ist der Code für einen Gleichheitstest, da IN entspricht = SOME . Wenn Sie interessiert sind, gibt es Codes von 1 bis 6, die jeweils (<, =, <=,>, !=,>=) Vergleichsoperatoren darstellen.
Zurück zu den EXISTS Syntax, die ich am liebsten verwende, um einen Semi-Join indirekt auszudrücken:
SELECT P.ProductIDFROM Production.Product AS PWHERE EXISTS( SELECT * FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);
Der Eingabebaum des Optimierers ist:

Dieser Baum ist eine ziemlich direkte Übersetzung des Abfragetexts; Beachten Sie jedoch, dass SELECT * wurde bereits durch eine Projektion des konstanten ganzzahligen Wertes 1 ersetzt (siehe vorletzte Textzeile).
Als nächstes entschachtelt der Optimierer die Unterabfrage in der relationalen Auswahl (=Filter) mit der Regel RemoveSubqInSel . Der Optimierer tut dies immer, da er Unterabfragen nicht direkt bearbeiten kann. Das Ergebnis ist ein apply (auch bekannt als korrelierter oder lateraler Join):

(Die gleiche Unterabfrage-Entfernungsregel erzeugt die gleiche Ausgabe für SOME auch Eingabebaum).
Der nächste Schritt besteht darin, die Anwendung mithilfe des ApplyHandler in einen regulären Join umzuschreiben Familie regieren. Das ist etwas, was der Optimierer immer versucht, weil er mehr Explorationsregeln für Joins als für Apply hat. Nicht jede Anwendung kann als Join umgeschrieben werden, aber das aktuelle Beispiel ist einfach und erfolgreich:

Beachten Sie, dass der Join-Typ Left Semi ist. Tatsächlich ist dies genau derselbe Baum, den wir sofort erhalten würden, wenn T-SQL eine Syntax wie:
unterstützen würdeSELECT P.ProductID FROM Production.Product AS P LEFT SEMI JOIN Production.TransactionHistory AS TH ON TH.ProductID =P.ProductID;
Es wäre schön, Anfragen so direkter äußern zu können. Wie auch immer, der interessierte Leser wird ermutigt, die obigen Vereinfachungsaktivitäten mit anderen logisch äquivalenten Möglichkeiten zum Schreiben dieses Semi-Joins in T-SQL zu untersuchen.
Die wichtige Erkenntnis in dieser Phase ist, dass der Optimierer Unterabfragen immer entfernt , und ersetzen Sie sie durch ein apply. Anschließend wird versucht, die Bewerbung als reguläre Verknüpfung neu zu schreiben, um die Chancen zu maximieren, einen guten Plan zu finden. Denken Sie daran, dass alles Vorhergehende stattfindet, bevor auch nur ein trivialer Plan in Betracht gezogen wird. Während der kostenbasierten Optimierung kann der Optimierer auch eine Join-Transformation zurück zu einer Anwendung in Betracht ziehen.
Hash und Merge Semi Join
SQL Server verfügt über drei physische Hauptimplementierungsoptionen, die für einen logischen Semi-Join verfügbar sind. Solange ein Equijoin-Prädikat vorhanden ist, sind Hash- und Merge-Join verfügbar; beide können im Left- und Right-Semi-Join-Modus betrieben werden. Verschachtelte Schleifenverknüpfungen unterstützen nur linke (nicht rechte) Halbverknüpfungen, erfordern jedoch kein Equijoin-Prädikat. Schauen wir uns die physischen Hash- und Merge-Optionen für unsere Beispielabfrage an (diesmal als Set-Intersect geschrieben):
SELECT P.ProductID FROM Production.Product AS PINTERSECTSELECT TH.ProductID FROM Production.TransactionHistory AS TH;
Der Optimierer kann einen Plan für alle vier Kombinationen von (links/rechts) und (Hash/merge) Semi-Join für diese Abfrage finden:
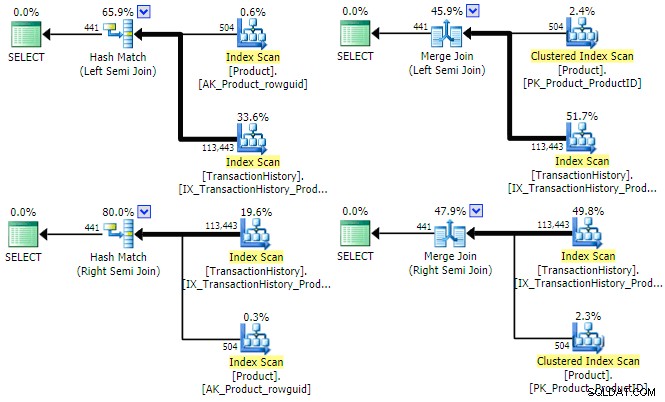
Es sollte kurz erwähnt werden, warum der Optimierer für jeden Join-Typ sowohl linke als auch rechte Semi-Joins berücksichtigen könnte. Bei Hash-Semi-Join ist ein wichtiger Kostenfaktor die geschätzte Größe der Hash-Tabelle, die anfangs immer die linke (obere) Eingabe ist. Beim Merge-Semi-Join bestimmen die Eigenschaften jeder Eingabe, ob eine Eins-zu-Viele- oder eine weniger effiziente Viele-zu-Viele-Zusammenführung mit Arbeitstabelle verwendet wird.
Aus den obigen Ausführungsplänen könnte ersichtlich sein, dass weder Hash noch Merge-Semi-Join von der Festlegung eines Zeilenziels profitieren würden . Beide Join-Typen testen das Join-Prädikat immer am Join selbst und zielen darauf ab, alle Zeilen aus beiden Eingaben zu verbrauchen, um eine vollständige Ergebnismenge zurückzugeben. Das soll nicht heißen, dass es keine Leistungsoptimierungen für Hash- und Merge-Joins im Allgemeinen gibt – beide können beispielsweise Bitmaps verwenden, um die Anzahl der Zeilen zu reduzieren, die den Join erreichen. Der Punkt ist vielmehr, dass ein Zeilenziel für eine der beiden Eingaben einen Hash- oder Merge-Semi-Join nicht effizienter machen würde.
Verschachtelte Schleifen und Semi-Join anwenden
Der verbleibende physische Join-Typ sind verschachtelte Schleifen, die es in zwei Varianten gibt:reguläre (unkorrelierte) verschachtelte Schleifen und Anwenden verschachtelte Schleifen (manchmal auch als korrelierte bezeichnet oder seitlich beitreten).
Reguläre Joins mit verschachtelten Schleifen ähneln Hash- und Merge-Joins, da das Join-Prädikat beim Join ausgewertet wird. Wie zuvor bedeutet dies, dass es keinen Wert hat, ein Zeilenziel für beide Eingaben festzulegen. Die linke (obere) Eingabe wird schließlich immer vollständig verbraucht, und die innere Eingabe hat keine Möglichkeit zu bestimmen, welche Zeile(n) priorisiert werden sollen, da wir nicht wissen können, ob eine Zeile verknüpft wird oder nicht, bis das Prädikat bei der Verknüpfung getestet wird .
Im Gegensatz dazu hat ein Apply-Nested-Loops-Join eine oder mehrere äußere Referenzen (korrelierte Parameter) am Join, wobei das Join-Prädikat nach unten gedrückt wird die innere (untere) Seite der Verbindung. Dies schafft eine Gelegenheit für die sinnvolle Anwendung eines Zeilenziels. Denken Sie daran, dass wir bei einem Semi-Join nur prüfen müssen, ob eine Zeile in Join-Eingabe B vorhanden ist, die mit der aktuellen Zeile in Join-Eingabe A übereinstimmt (denken wir jetzt nur an Join-Strategien mit verschachtelten Schleifen).
Mit anderen Worten, wir können bei jeder Iteration eines apply aufhören, Eingabe B zu betrachten, sobald die erste Übereinstimmung gefunden wird, indem wir das Pushdown-Join-Prädikat verwenden. Genau dafür ist ein Zeilenziel gut:Generieren eines Teils eines Plans, der so optimiert ist, dass er die ersten n übereinstimmenden Zeilen schnell zurückgibt (wobei n = 1 hier).
Natürlich kann ein Reihentor je nach den Umständen eine gute Sache sein oder nicht. In dieser Hinsicht ist das Semi Join Row Goal nichts Besonderes. Stellen Sie sich eine Situation vor, in der die Innenseite des Semi-Joins komplexer ist als ein einzelner einfacher Tabellenzugriff, vielleicht ein Multi-Table-Join. Das Festlegen eines Zeilenziels kann dem Optimierer dabei helfen, eine effiziente Navigationsstrategie nur für diesen bestimmten Teilbaum auszuwählen , Suchen der ersten übereinstimmenden Zeile, um den Semi-Join über Joins mit verschachtelten Schleifen und Indexsuchen zu erfüllen. Ohne das Zeilenziel könnte der Optimierer natürlich Hash wählen oder Joins mit Sortierungen zusammenführen, um die erwarteten Kosten für die Rückgabe aller möglichen Zeilen zu minimieren. Beachten Sie, dass es hier eine Annahme gibt, nämlich dass Leute Semi-Joins normalerweise mit der Erwartung schreiben, dass eine Zeile, die der Suchbedingung entspricht, tatsächlich existiert. Dies scheint mir eine hinreichend faire Annahme zu sein.
Unabhängig davon ist der wichtige Punkt in dieser Phase:Nur bewerben Nested Loops Join hat ein Zeilenziel vom Optimierer angewendet (denken Sie jedoch daran, dass ein Zeilenziel für das Anwenden von Joins mit verschachtelten Schleifen nur hinzugefügt wird, wenn das Zeilenziel kleiner als die Schätzung ohne es ist). Wir werden uns ein paar ausgearbeitete Beispiele ansehen, um das alles hoffentlich als nächstes zu verdeutlichen.
Beispiele für Halbverknüpfungen mit verschachtelten Schleifen
Das folgende Skript erstellt zwei temporäre Heap-Tabellen. Die erste hat Zahlen von 1 bis einschließlich 20; die andere hat 10 Kopien jeder Zahl in der ersten Tabelle:
DROPT TABLE IF EXISTS #E1, #E2; ERSTELLE TABELLE #E1 (c1 Ganzzahl NULL); ERSTELLE TABELLE #E2 (c1 Ganzzahl NULL); INSERT #E1 (c1)SELECT SV.numberFROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=20; INSERT #E2 (c1)SELECT (SV.number % 20) + 1FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=200;Ohne Indizes und mit einer relativ kleinen Anzahl von Zeilen wählt der Optimierer eine Implementierung mit verschachtelten Schleifen (statt Hash oder Merge) für die folgende Semi-Join-Abfrage). Die undokumentierten Trace-Flags ermöglichen es uns, den Ausgabebaum des Optimierers und Informationen zum Zeilenziel anzuzeigen:
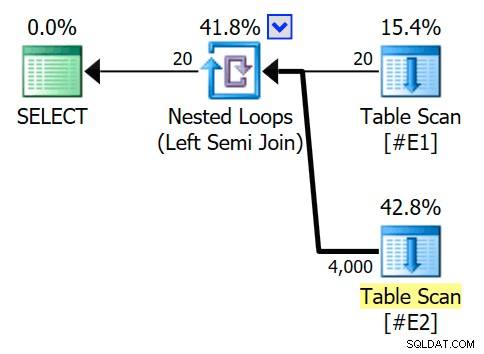
SELECT E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Der geschätzte Ausführungsplan sieht einen Semi-Join mit Nested-Loops-Join vor, mit 200 Zeilen pro vollständigem Scan der Tabelle
#E2. Die 20 Iterationen der Schleife ergeben eine Gesamtschätzung von 4.000 Zeilen:
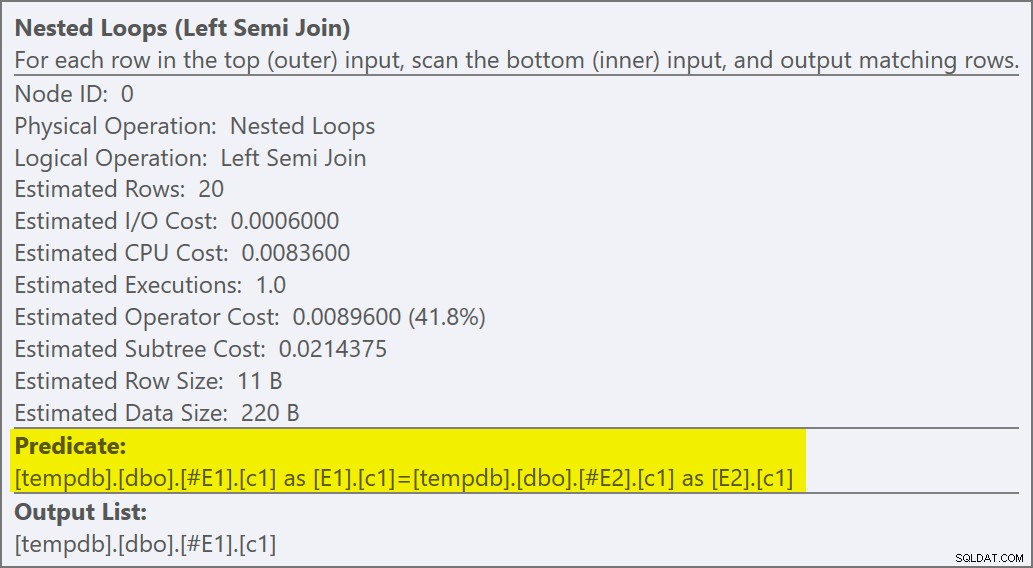
Die Eigenschaften des Operators für verschachtelte Schleifen zeigen, dass das Prädikat beim Join angewendet wird was bedeutet, dass dies ein unkorrelierter Join mit verschachtelten Schleifen ist :
Die Ausgabe des Ablaufverfolgungsflags (auf der Registerkarte „SSMS-Meldungen“) zeigt einen Semi-Join mit verschachtelten Schleifen und kein Zeilenziel (RowGoal 0):
Beachten Sie, dass der Nachausführungsplan für diese Spielzeugabfrage nicht insgesamt 4.000 aus Tabelle #E2 gelesene Zeilen anzeigt. Verschachtelte Schleifen-Halbverknüpfungen (korreliert oder nicht) hören auf, nach weiteren Zeilen auf der inneren Seite (pro Iteration) zu suchen, sobald die erste Übereinstimmung für die aktuelle äußere Zeile gefunden wird. Nun ist die Reihenfolge der Zeilen, die beim Heap-Scan von #E2 bei jeder Iteration angetroffen werden, nicht deterministisch (und kann bei jeder Iteration anders sein), also im Prinzip Fast alle Zeilen könnten bei jeder Iteration getestet werden, für den Fall, dass die übereinstimmende Zeile so spät wie möglich gefunden wird (oder tatsächlich, falls keine übereinstimmende Zeile vorhanden ist, überhaupt nicht).
Wenn wir beispielsweise von einer Laufzeitimplementierung ausgehen, bei der Zeilen zufällig jedes Mal in derselben Reihenfolge (z. B. "Einfügungsreihenfolge") gescannt werden, beträgt die Gesamtzahl der gescannten Zeilen in diesem Spielzeugbeispiel 20 Zeilen bei der ersten Iteration, 1 Zeile bei der zweiten Iteration, 2 Zeilen bei der dritten Iteration und so weiter für insgesamt 20 + 1 + 2 + (…) + 19 =210 Zeilen. In der Tat ist es sehr wahrscheinlich, dass Sie diese Summe beobachten, die mehr über die Einschränkungen von einfachem Demonstrationscode aussagt als über irgendetwas anderes. Man kann sich nicht mehr auf die Reihenfolge der Zeilen verlassen, die von einer ungeordneten Zugriffsmethode zurückgegeben werden, als man sich auf die anscheinend geordnete Ausgabe einer Abfrage ohne
ORDER BYauf oberster Ebene verlassen kann Klausel.Semi-Join anwenden
Wir erstellen jetzt einen Nonclustered-Index für die größere Tabelle (um den Optimierer zu ermutigen, einen Semi-Join anwenden zu wählen) und führen die Abfrage erneut aus:
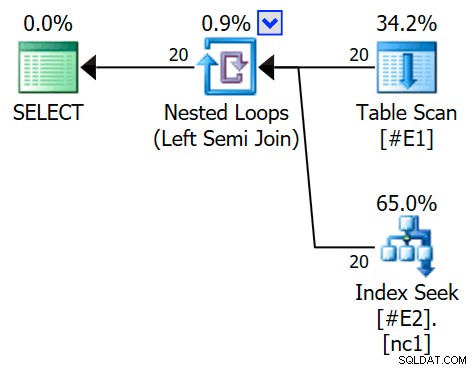
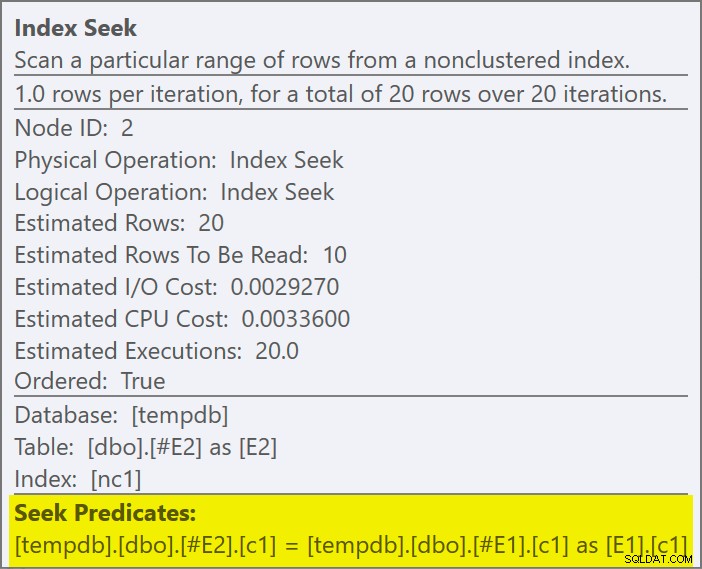
ERSTELLE NICHT EINGESCHLOSSENEN INDEX nc1 AUF #E2 (c1); SELECT E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Der Ausführungsplan verfügt jetzt über einen Apply-Semi-Join mit 1 Zeile pro Indexsuche (und 20 Iterationen wie zuvor):
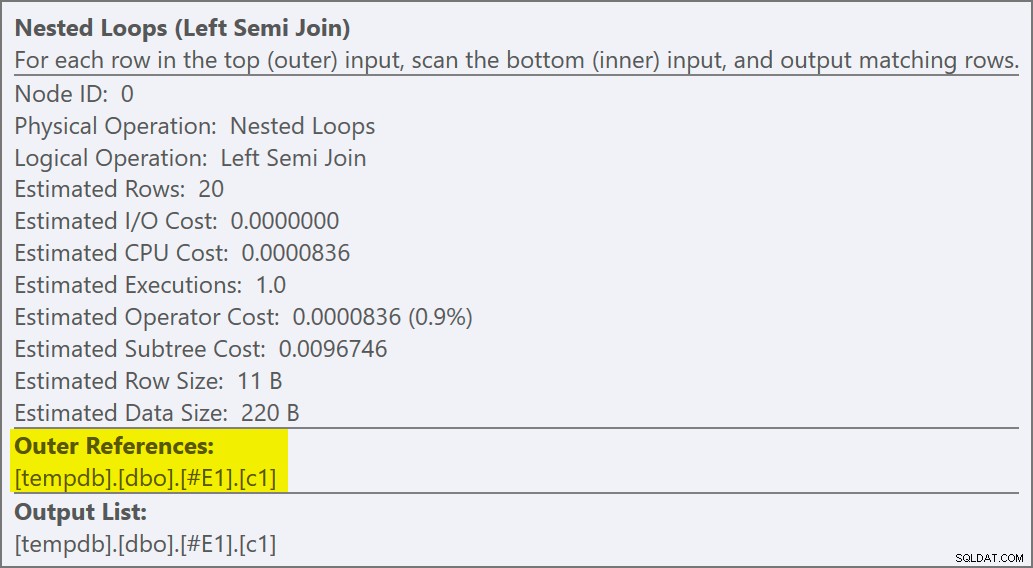
Wir können erkennen, dass es sich um einen semi join anwenden handelt weil die Join-Eigenschaften eine äußere Referenz zeigen anstelle eines Join-Prädikats:
Das Join-Prädikat wurde nach unten verschoben der Innenseite der Anwendung und angepasst an den neuen Index:
Es wird erwartet, dass jede Suche 1 Zeile zurückgibt, obwohl jeder Wert 10 Mal in dieser Tabelle dupliziert wird; dies ist ein Effekt des Zeilenziels . Das Zeilenziel ist in SQL Server-Builds, die EstimateRowsWithoutRowGoal verfügbar machen, einfacher zu identifizieren plan-Attribut (SQL Server 2017 CU3 zum Zeitpunkt des Schreibens). In einer kommenden Version von Plan Explorer wird dies auch in Tooltips für relevante Operatoren angezeigt:
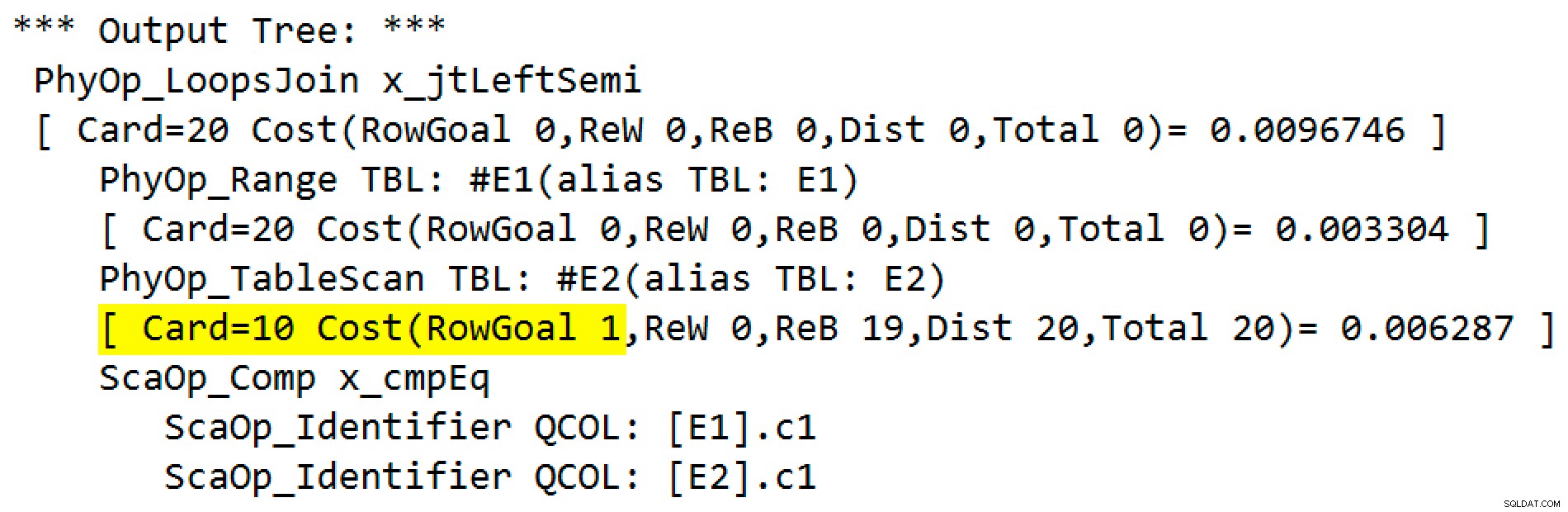
Die Ausgabe des Trace-Flags lautet:
Der physische Operator hat sich von einem Loops-Join zu einem Apply-Modus geändert, der im linken Semi-Join-Modus ausgeführt wird. Zugriff auf Tabelle
#E2hat ein Zeilenziel von 1 erreicht (die Kardinalität ohne das Zeilenziel wird als 10 angezeigt). Das Zeilenziel ist in diesem Fall keine große Sache, da die Kosten für das Abrufen von geschätzten zehn Zeilen pro Suche nicht sehr viel höher sind als für eine Zeile. Deaktivieren von Zeilenzielen für diese Abfrage (unter Verwendung des Ablaufverfolgungsflags 4138 oder desDISABLE_OPTIMIZER_ROWGOALAbfragehinweis) würde die Form des Plans nicht ändern.Dennoch kann in realistischeren Abfragen die Kostenreduzierung aufgrund des innerseitigen Zeilenziels den Unterschied zwischen konkurrierenden Implementierungsoptionen ausmachen. Beispielsweise kann das Deaktivieren des Zeilenziels dazu führen, dass der Optimierer stattdessen einen Hash oder Merge-Semi-Join oder eine der vielen anderen Optionen auswählt, die für die Abfrage in Betracht gezogen werden. Nicht zuletzt spiegelt das Zeilenziel hier genau die Tatsache wider, dass ein Semi-Join anwenden aufhört, die innere Seite zu durchsuchen, sobald die erste Übereinstimmung gefunden wird, und mit der nächsten äußeren Seitenreihe fortfährt.
Beachten Sie, dass Duplikate in Tabelle
#E2erstellt wurden so dass das Ziel zum Anwenden von Semi-Join-Zeilen (1) niedriger als die normale Schätzung (10, aus statistischen Dichteinformationen) wäre. Wenn es keine Duplikate gab, wird die Zeilenschätzung für jede Suche in#E2durchgeführt wäre auch 1 Zeile, also würde ein Zeilenziel von 1 nicht angewendet (denken Sie an die allgemeine Regel dazu!)Reihenziele vs. Top
Angesichts der Tatsache, dass Ausführungspläne vor SQL Server 2017 CU3 überhaupt nicht auf das Vorhandensein eines Zeilenziels hinweisen, könnte man denken, dass es klarer gewesen wäre, diese Optimierung mit einem expliziten Top-Operator zu implementieren, anstatt mit einer versteckten Eigenschaft wie einem Zeilenziel. Die Idee wäre, einfach einen Top (1)-Operator auf der Innenseite eines Apply-Semi/Anti-Joins zu platzieren, anstatt ein Zeilenziel am Join selbst festzulegen.
Die Verwendung eines Top-Operators auf diese Weise wäre nicht ganz ohne Präzedenzfall gewesen. Beispielsweise gibt es bereits eine spezielle Version von Top, bekannt als Row Count Top, die in Ausführungsplänen für Datenänderungen zu sehen ist, wenn ein
SET ROWCOUNTungleich Null ist ist in Kraft (beachten Sie, dass diese spezielle Verwendung seit 2005 veraltet ist, obwohl sie in SQL Server 2017 immer noch zulässig ist). Die Top-Implementierung der Zeilenanzahl ist ein wenig umständlich, da der Top-Operator im Ausführungsplan immer als Top (0) angezeigt wird, unabhängig von der tatsächlich wirksamen Zeilenanzahlbegrenzung.Es gibt keinen zwingenden Grund, warum das Ziel Apply Semi Join Row nicht durch einen expliziten Operator Top (1) hätte ersetzt werden können. Allerdings gibt es einige Gründe, vorzuziehen um das nicht zu tun:


- Das Hinzufügen eines expliziten Top (1) erfordert mehr Programmier- und Testaufwand für den Optimierer als das Hinzufügen eines Zeilenziels (das bereits für andere Dinge verwendet wird).
- Top ist kein Vergleichsoperator; der Optimierer hat wenig Unterstützung, um darüber nachzudenken. Dies könnte sich negativ auf die Planqualität auswirken, indem die Fähigkeit des Optimierers eingeschränkt wird, Teile eines Abfrageplans umzuwandeln, z. durch Verschieben von Aggregaten, Vereinigungen, Filtern und Verknüpfungen.
- Es würde eine enge Kopplung zwischen der Anwendungsimplementierung der Halbverbindung und der Oberseite einführen. Sonderfälle und enge Kopplung sind großartige Möglichkeiten, Fehler einzuschleusen und zukünftige Änderungen schwieriger und fehleranfälliger zu machen.
- Das Top (1) wäre logisch redundant und nur wegen seines Zeilenziel-Nebeneffekts vorhanden.
Dieser letzte Punkt ist es wert, mit einem Beispiel erweitert zu werden:
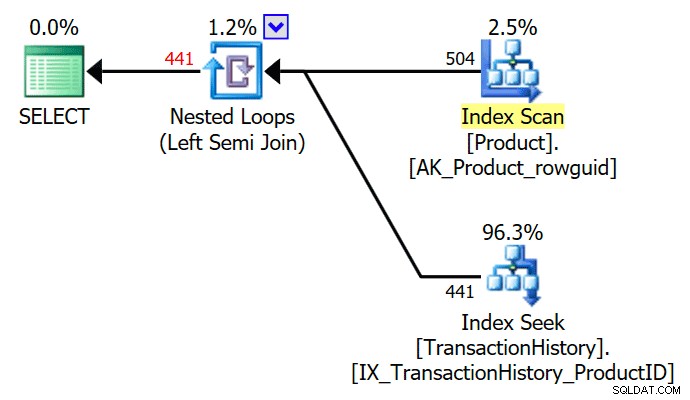
SELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Die TOP (1) in der Unterabfrage "exists" wird vom Optimierer vereinfacht und ergibt einen einfachen Semi-Join-Ausführungsplan:
Der Optimierer kann auch ein redundantes DISTINCT entfernen oder GROUP BY in der Unterabfrage. Die folgenden erzeugen alle denselben Plan wie oben:
-- Redundant DISTINCTSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT DISTINCT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID ); - Redundant GROUP BYSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID GROUP BY TH.ProductID ); -- Redundant DISTINCT TOP (1)SELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT DISTINCT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Zusammenfassung und abschließende Gedanken
Nur bewerben Semi-Join mit verschachtelten Schleifen kann ein vom Optimierer festgelegtes Zeilenziel haben. Dies ist der einzige Join-Typ, der das/die Join-Prädikat(e) aus dem Join nach unten schiebt, sodass Tests auf das Vorhandensein einer Übereinstimmung früh durchgeführt werden können . Nicht korrelierte verschachtelte Loops halbverbinden fast nie* setzt ein Zeilenziel, und weder ein Hash noch ein Merge-Semi-Join. Apply Nested Loops können von unkorrelierten Nested Loops Joins durch das Vorhandensein von äußeren Referenzen unterschieden werden (anstelle eines Prädikats) für den Join-Operator für verschachtelte Schleifen für ein apply.
Die Chancen, im endgültigen Ausführungsplan einen Apply-Semi-Join zu sehen, hängen etwas von der frühen Optimierungsaktivität ab. Ohne direkte T-SQL-Syntax müssen wir Semi-Joins indirekt ausdrücken. Diese werden in einen logischen Baum geparst, der eine Unterabfrage enthält, deren frühe Optimierungsaktivität in eine Anwendung umgewandelt wird, und dann, wenn möglich, in einen unkorrelierten Semi-Join.
Diese Vereinfachungsaktivität bestimmt, ob ein logischer Semi-Join dem kostenbasierten Optimierer als Anwenden- oder regulärer Semi-Join präsentiert wird. Wenn es als logische Bewerbung präsentiert wird Semi-Join, der CBO wird mit ziemlicher Sicherheit einen endgültigen Ausführungsplan erstellen, der verschachtelte Schleifen mit physischer Anwendung enthält (und so ein Zeilenziel festlegt). Wenn ein unkorrelierter Semi-Join angezeigt wird, kann der CBO darf Betrachten Sie die Umwandlung in ein Apply (oder auch nicht). Die endgültige Wahl des Plans besteht wie üblich aus einer Reihe kostenbasierter Entscheidungen.
Wie alle Row-Goals kann das Semi-Join-Row-Goal gut oder schlecht für die Leistung sein. Zu wissen, dass ein Semi-Join anwenden ein Zeilenziel festlegt, hilft den Leuten zumindest, die Ursache zu erkennen und zu beheben, falls ein Problem auftreten sollte. Die Lösung besteht nicht immer (oder sogar normalerweise) darin, Zeilenziele für die Abfrage zu deaktivieren. Verbesserungen bei der Indizierung (und/oder der Abfrage) können oft vorgenommen werden, um eine effiziente Methode zum Auffinden der ersten übereinstimmenden Zeile bereitzustellen.
Ich werde Anti-Semi-Joins in einem separaten Artikel behandeln und die Reihe der Zeilenziele fortsetzen.
* Die Ausnahme ist ein unkorrelierter Semi-Join mit verschachtelten Schleifen ohne Join-Prädikat (ein ungewöhnlicher Anblick). Dadurch wird ein Zeilenziel festgelegt.