Ich habe kürzlich eine E-Mail-Frage von jemandem aus der Community zum CLR_MANUAL_EVENT erhalten Wartetyp; insbesondere, wie Probleme mit dieser Wartezeit behoben werden können, die plötzlich für eine vorhandene Arbeitslast vorherrschen, die stark auf räumliche Datentypen und Abfragen angewiesen ist, die die räumlichen Methoden in SQL Server verwenden.
Als Berater lautet meine erste Frage fast immer:„Was hat sich geändert?“ Aber in diesem Fall, wie in so vielen Fällen, wurde mir versichert, dass sich nichts am Code oder den Workload-Mustern der Anwendung geändert hatte. Meine erste Station war also, das CLR_MANUAL_EVENT aufzurufen Warten Sie in der Wartetypenbibliothek von SQLskills.com, um zu sehen, welche anderen Informationen wir bereits zu diesem Wartetyp gesammelt haben, da es normalerweise keine Wartezeiten sind, bei denen ich in SQL Server Probleme sehe. Was ich wirklich interessant fand, war das Diagramm/die Heatmap der Vorkommen für diesen Wartetyp, das von SentryOne oben auf der Seite bereitgestellt wurde:
Die Tatsache, dass für diesen Typ bei einem guten Querschnitt ihrer Kunden keine Daten gesammelt wurden, bestätigte mir wirklich, dass dies normalerweise kein Problem ist, daher war ich fasziniert von der Tatsache, dass diese spezifische Arbeitslast jetzt auftrat Probleme mit dieser Wartezeit. Ich war mir nicht sicher, wohin ich gehen sollte, um das Problem weiter zu untersuchen, also antwortete ich auf die E-Mail und sagte, es tut mir leid, dass ich nicht weiter helfen konnte, weil ich keine Ahnung hatte, was buchstäblich Dutzende von Threads verursachen würde, die räumliche Abfragen durchführen Plötzlich müssen Sie bei diesem Wartetyp jeweils 2-4 Sekunden warten.
Einen Tag später erhielt ich von der Person, die die Frage gestellt hatte, eine freundliche Folge-E-Mail, die mich darüber informierte, dass sie das Problem gelöst hatte. In der Tat hatte sich nichts an der tatsächlichen Arbeitslast der Anwendung geändert, aber es gab eine Änderung an der Umgebung, die aufgetreten ist. Ein Drittanbieter-Softwarepaket wurde von ihrem Sicherheitsteam auf allen Servern in ihrer Infrastruktur installiert, und diese Software sammelte Daten in Fünf-Minuten-Intervallen und führte dazu, dass die .NET-Garbage-Collection-Verarbeitung unglaublich aggressiv lief und „durchdrehte“. Sie sagten. Bewaffnet mit diesen Informationen und einigen meiner früheren Kenntnisse über die .NET-Entwicklung entschied ich mich, damit herumzuspielen und zu sehen, ob ich das Verhalten reproduzieren und wie wir die Ursachen weiter beheben könnten.
Hintergrundinformationen
Im Laufe der Jahre habe ich immer den PSSQL-Blog auf MSDN verfolgt, und das ist normalerweise eine meiner Anlaufstellen, wenn ich mich daran erinnere, dass ich irgendwann in der Vergangenheit von einem Problem im Zusammenhang mit SQL Server gelesen habe, aber ich kann' Ich erinnere mich nicht an alle Einzelheiten.
Es gibt einen Blogpost mit dem Titel Hohe Wartezeiten bei CLR_MANUAL_EVENT und CLR_AUTO_EVENT von Jack Li aus dem Jahr 2008, der erklärt, warum diese Wartezeiten in den zusammengefassten sys.dm_os_wait_stats getrost ignoriert werden können DMV, da die Wartezeiten unter normalen Bedingungen auftreten, aber es geht nicht darauf ein, was zu tun ist, wenn die Wartezeiten übermäßig lang sind, oder was dazu führen könnte, dass sie über mehrere Threads hinweg in sys.dm_os_waiting_tasks angezeigt werden aktiv.
Es gibt einen weiteren Blogbeitrag von Jack Li aus dem Jahr 2013 mit dem Titel Ein Leistungsproblem im Zusammenhang mit der CLR-Garbage-Collection und der SQL-CPU-Affinitätseinstellung auf die ich in unserem IEPTO2-Leistungsoptimierungskurs verweise, wenn ich über Überlegungen zu mehreren Instanzen spreche und wie sich der von einer Instanz ausgelöste .NET Garbage Collector (GC) auf die anderen Instanzen auf demselben Server auswirken kann.
Der GC in .NET dient dazu, die Speichernutzung von Anwendungen zu reduzieren, die CLR verwenden, indem der den Objekten zugewiesene Speicher automatisch bereinigt wird, wodurch die Notwendigkeit für Entwickler entfällt, die Speicherzuweisung und -aufhebung in dem für nicht verwalteten Code erforderlichen Ausmaß manuell vorzunehmen . Die GC-Funktionalität ist in der Online-Dokumentation dokumentiert, wenn Sie mehr darüber wissen möchten, wie sie funktioniert, aber die Besonderheiten, die über die Tatsache hinausgehen, dass Sammlungen blockiert werden können, sind für die Fehlerbehebung bei aktiven Wartezeiten auf CLR_MANUAL_EVENT nicht wichtig in SQL Server weiter.
Das Problem an der Wurzel packen
Mit dem Wissen, dass die Garbage Collection von .NET das Problem verursachte, entschied ich mich, einige Experimente mit einer einzelnen räumlichen Abfrage für AdventureWorks2016 durchzuführen und ein sehr einfaches PowerShell-Skript, um den Garbage Collector manuell in einer Schleife aufzurufen, um zu verfolgen, was in sys.dm_os_waiting_tasks passiert innerhalb von SQL Server für die Abfrage:
USE AdventureWorks2016; GO SELECT a.SpatialLocation.ToString(), a.City, b.SpatialLocation.ToString(), b.City FROM Person.Address AS a INNER JOIN Person.Address AS b ON a.SpatialLocation.STDistance(b.SpatialLocation) <= 100 ORDER BY a.SpatialLocation.STDistance(b.SpatialLocation);
Diese Abfrage vergleicht alle Adressen in Person.Address Tabelle miteinander vergleichen, um jede Adresse zu finden, die sich innerhalb von 100 Metern von einer anderen Adresse in der Tabelle befindet. Dadurch wird eine lang andauernde parallele Aufgabe innerhalb von SQL Server erstellt, die auch ein großes kartesisches Ergebnis erzeugt. Wenn Sie sich entscheiden, dieses Verhalten selbst zu reproduzieren, erwarten Sie nicht, dass dies abgeschlossen ist oder Ergebnisse zurückgegeben werden. Wenn die Abfrage ausgeführt wird, beginnt der übergeordnete Thread für die Aufgabe, auf CXPACKET zu warten wartet, und die Abfrage wird einige Minuten lang weiter verarbeitet. Was mich jedoch interessierte, war, was passiert, wenn die Garbage Collection in der CLR-Laufzeit stattfindet oder wenn die GC aufgerufen wird, also habe ich ein einfaches PowerShell-Skript verwendet, das die Ausführung der GC in einer Schleife und manuell erzwingt.
HINWEIS:DIES IST AUS VIELEN GRÜNDEN KEINE EMPFOHLENE PRAXIS IM PRODUKTIONSCODE!
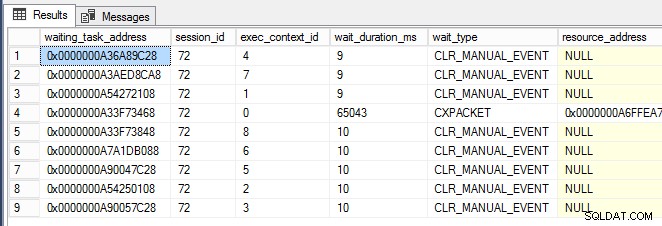
while (1 -eq 1) {[System.GC]::Collect() } Sobald das PowerShell-Fenster ausgeführt wurde, fing ich fast sofort an, CLR_MANUAL_EVENT zu sehen Wartezeiten, die bei den parallelen Subtask-Threads (unten gezeigt, wobei exec_context_id größer als Null ist) in sys.dm_os_waiting_tasks auftreten :
Jetzt, da ich dieses Verhalten auslösen konnte und klar wurde, dass SQL Server hier nicht unbedingt das Problem ist und möglicherweise nur das Opfer anderer Aktivitäten ist, wollte ich wissen, wie ich tiefer graben und die Ursache des Problems lokalisieren kann . Hier hat sich PerfMon als nützlich erwiesen, um die .NET CLR-Speicherindikatorgruppe für alle Aufgaben auf dem Server nachzuverfolgen.
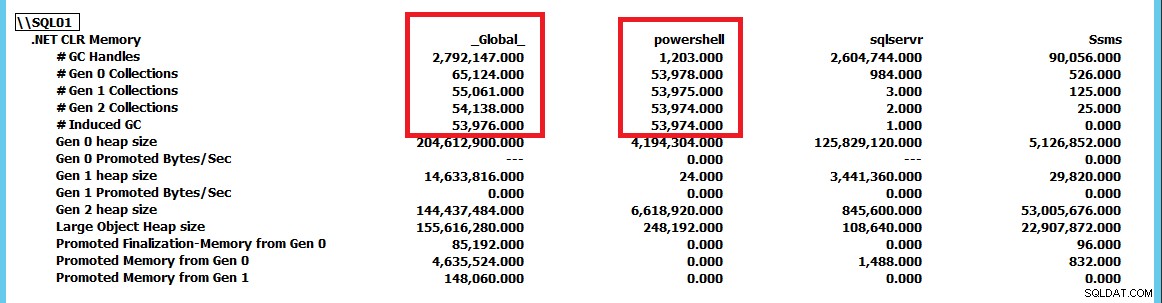
Dieser Screenshot wurde reduziert, um die Sammlungen für sqlservr zu zeigen und Powershell als Anwendungen im Vergleich zu _Global_ Sammlungen durch die .NET-Laufzeit. Durch Erzwingen von GC.Collect() ständig laufen können wir sehen, dass die Powershell -Instanz steuert die GC-Sammlungen auf dem Server. Mithilfe dieser PerfMon-Zählergruppe können wir nachverfolgen, welche Anwendungen die meisten Sammlungen durchführen, und von dort aus weitere Untersuchungen des Problems durchführen. In diesem Fall wird durch einfaches Stoppen des PowerShell-Skripts das CLR_MANUAL_EVENT eliminiert wartet innerhalb von SQL Server und die Abfrage setzt die Verarbeitung fort, bis wir sie entweder stoppen oder ihr erlauben, die Milliarden Zeilen von Ergebnissen zurückzugeben, die von ihr ausgegeben würden.
Schlussfolgerung
Wenn Sie aktiv auf CLR_MANUAL_EVENT warten Verlangsamung der Anwendung verursachen, gehen Sie nicht automatisch davon aus, dass das Problem innerhalb von SQL Server besteht. SQL Server verwendet die Garbage Collection auf Serverebene (zumindest vor SQL Server 2017 CU4, wo kleine Server mit weniger als 2 GB RAM die Garbage Collection auf Clientebene verwenden können, um die Ressourcennutzung zu reduzieren). Wenn Sie feststellen, dass dieses Problem in SQL Server auftritt, verwenden Sie die Leistungsindikatorengruppe .NET CLR Memory in PerfMon und prüfen Sie, ob eine andere Anwendung die Garbage Collection in CLR vorantreibt und die CLR-Aufgaben dadurch intern in SQL Server blockiert.