Letzten Monat habe ich eine Special Islands-Herausforderung behandelt. Die Aufgabe bestand darin, Aktivitätsperioden für jede Service-ID zu identifizieren und dabei eine Lücke von bis zu einer eingegebenen Anzahl von Sekunden zu tolerieren (@allowedgap ). Der Vorbehalt war, dass die Lösung vor 2012 kompatibel sein musste, sodass Sie keine Funktionen wie LAG und LEAD verwenden oder Fensterfunktionen mit einem Rahmen aggregieren konnten. Ich habe eine Reihe sehr interessanter Lösungen in den Kommentaren von Toby Ovod-Everett, Peter Larsson und Kamil Kosno gepostet. Stellen Sie sicher, dass Sie ihre Lösungen durchgehen, da sie alle ziemlich kreativ sind.
Seltsamerweise liefen einige Lösungen mit dem empfohlenen Index langsamer als ohne. In diesem Artikel schlage ich eine Erklärung dafür vor.
Auch wenn alle Lösungen interessant waren, wollte ich mich hier auf die Lösung von Kamil Kosno konzentrieren, der ETL-Entwickler bei Zopa ist. In seiner Lösung verwendete Kamil eine sehr kreative Technik, um LAG und LEAD ohne LAG und LEAD zu emulieren. Sie werden die Technik wahrscheinlich praktisch finden, wenn Sie LAG/LEAD-ähnliche Berechnungen mit Code durchführen müssen, der vor 2012 kompatibel ist.
Warum sind einige Lösungen ohne den empfohlenen Index schneller?
Zur Erinnerung habe ich vorgeschlagen, den folgenden Index zu verwenden, um die Lösungen für die Herausforderung zu unterstützen:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Meine vor 2012 kompatible Lösung war die folgende:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Abbildung 1 zeigt den Plan für meine Lösung mit dem empfohlenen Index.
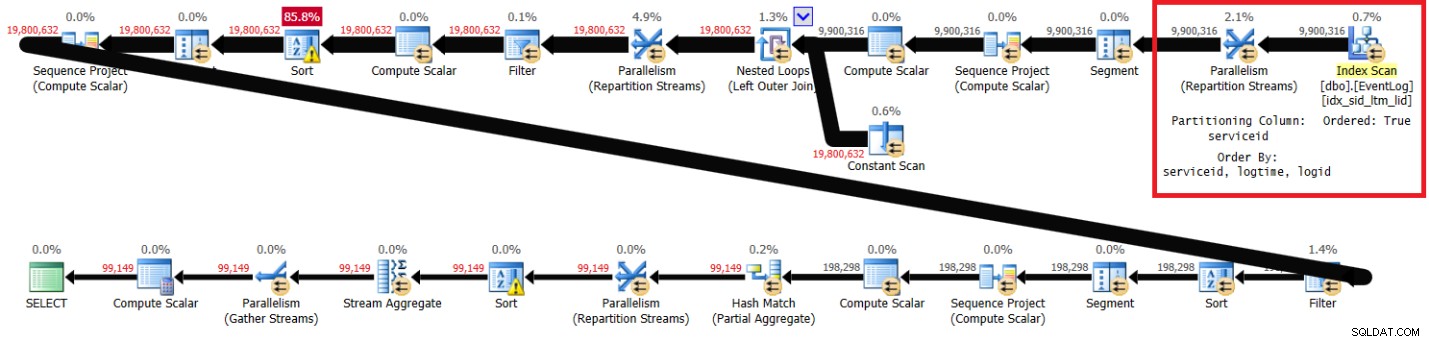 Abbildung 1:Plan für Itziks Lösung mit empfohlenem Index
Abbildung 1:Plan für Itziks Lösung mit empfohlenem Index
Beachten Sie, dass der Plan den empfohlenen Index in Schlüsselreihenfolge scannt (Ordered-Eigenschaft ist True), die Streams mithilfe eines reihenfolgeerhaltenden Austauschs nach Service-ID partitioniert und dann die anfängliche Berechnung der Zeilennummern basierend auf der Indexreihenfolge anwendet, ohne dass eine Sortierung erforderlich ist. Im Folgenden sind die Leistungsstatistiken aufgeführt, die ich für diese Abfrageausführung auf meinem Laptop erhalten habe (verstrichene Zeit, CPU-Zeit und maximale Wartezeit in Sekunden):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
Ich habe dann den empfohlenen Index gelöscht und die Lösung erneut ausgeführt:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Ich habe den in Abbildung 2 gezeigten Plan erhalten.
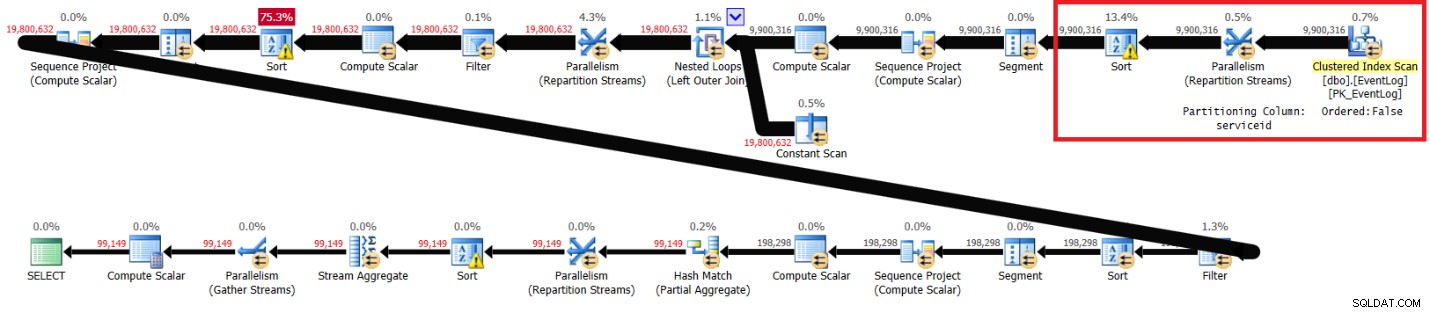 Abbildung 2:Plan für Itziks Lösung ohne empfohlenen Index
Abbildung 2:Plan für Itziks Lösung ohne empfohlenen Index
Die hervorgehobenen Abschnitte in den beiden Plänen zeigen den Unterschied. Der Plan ohne den empfohlenen Index führt einen ungeordneten Scan des Clustered-Index durch, partitioniert die Streams nach Service-ID mithilfe eines nicht ordnungserhaltenden Austauschs und sortiert dann die Zeilen so, wie es die Fensterfunktion benötigt (nach Service-ID, Logtime, Logid). Der Rest der Arbeit scheint in beiden Plänen gleich zu sein. Sie würden denken, dass der Plan ohne den empfohlenen Index langsamer sein sollte, da er eine zusätzliche Sortierung hat, die der andere Plan nicht hat. Aber hier sind die Leistungsstatistiken, die ich für diesen Plan auf meinem Laptop erhalten habe:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
Es ist mehr CPU-Zeit erforderlich, was teilweise auf die zusätzliche Sortierung zurückzuführen ist. es sind mehr E/A-Vorgänge erforderlich, wahrscheinlich aufgrund zusätzlicher Sortierüberläufe; Die verstrichene Zeit ist jedoch etwa 30 Prozent schneller. Was könnte das erklären? Eine Möglichkeit, dies herauszufinden, besteht darin, die Abfrage in SSMS mit aktivierter Option Live Query Statistics auszuführen. Als ich dies tat, beendete der Operator Parallelism (Repartition Streams) ganz rechts in 6 Sekunden ohne den empfohlenen Index und in 35 Sekunden mit dem empfohlenen Index. Der Hauptunterschied besteht darin, dass erstere die Daten von einem Index vorbestellt erhält und ein ordnungserhaltender Austausch ist. Letzterer erhält die Daten ungeordnet und ist kein ordnungserhaltender Austausch. Ordnungserhaltende Börsen sind tendenziell teurer als nicht ordnungserhaltende. Außerdem liefert ersterer zumindest im rechten Teil des Plans bis zur ersten Sortierung die Zeilen in der gleichen Reihenfolge wie die Austauschpartitionierungsspalte, sodass Sie nicht alle Threads dazu bringen, die Zeilen wirklich parallel zu verarbeiten. Letzteres liefert die Zeilen ungeordnet, sodass Sie alle Threads dazu bringen, Zeilen wirklich parallel zu verarbeiten. Sie können sehen, dass CXPACKET die höchste Wartezeit in beiden Plänen ist, aber im ersten Fall ist die Wartezeit doppelt so lang wie im letzteren, was Ihnen sagt, dass die Handhabung der Parallelität im letzteren Fall optimaler ist. Es könnten noch andere Faktoren eine Rolle spielen, an die ich nicht denke. Wenn Sie weitere Ideen haben, die den überraschenden Leistungsunterschied erklären könnten, teilen Sie uns dies bitte mit.
Auf meinem Laptop führte dies dazu, dass die Ausführung ohne den empfohlenen Index schneller war als die mit dem empfohlenen Index. Bei einem anderen Testgerät war es jedoch umgekehrt. Schließlich haben Sie eine zusätzliche Sorte mit Verschüttungspotential.
Aus Neugier habe ich eine serielle Ausführung (mit der Option MAXDOP 1) mit dem empfohlenen Index getestet und die folgenden Leistungsstatistiken auf meinem Laptop erhalten:
elapsed: 42, CPU: 40, logical reads: 143,519
Wie Sie sehen, ähnelt die Laufzeit der Laufzeit der parallelen Ausführung mit dem empfohlenen Index. Ich habe nur 4 logische CPUs in meinem Laptop. Natürlich kann Ihre Laufleistung mit unterschiedlicher Hardware variieren. Der Punkt ist, dass es sich lohnt, verschiedene Alternativen zu testen, einschließlich mit und ohne die Indizierung, von der Sie denken, dass sie helfen sollte. Die Ergebnisse sind manchmal überraschend und kontraintuitiv.
Kamils Lösung
Ich war wirklich fasziniert von Kamils Lösung und mochte besonders die Art und Weise, wie er LAG und LEAD mit einer vor 2012 kompatiblen Technik emulierte.
Hier ist der Code, der den ersten Schritt in der Lösung implementiert:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
Dieser Code generiert die folgende Ausgabe (die nur Daten für Service-ID 1 anzeigt):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
In diesem Schritt werden zwei Zeilennummern berechnet, die für jede Zeile voneinander getrennt sind, nach Dienst-ID partitioniert und nach Protokollzeit geordnet sind. Die aktuelle Zeilennummer stellt die Endzeit dar (nennen Sie es end_time), und die aktuelle Zeilennummer minus eins stellt die Startzeit dar (nennen Sie es start_time).
Der folgende Code implementiert den zweiten Schritt der Lösung:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; Dieser Schritt generiert die folgende Ausgabe:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
Dieser Schritt entpivoziert jede Zeile in zwei Zeilen, wodurch jeder Protokolleintrag dupliziert wird – einmal für den Zeittyp start_time und ein weiterer für end_time. Wie Sie sehen können, erscheint jede Zeilennummer außer der minimalen und maximalen Zeilennummer zweimal – einmal mit der Protokollzeit des aktuellen Ereignisses (start_time) und ein weiteres Mal mit der Protokollzeit des vorherigen Ereignisses (end_time).
Der folgende Code implementiert den dritten Schritt in der Lösung:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; Dieser Code generiert die folgende Ausgabe:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
Dieser Schritt dreht die Daten, gruppiert Zeilenpaare mit derselben Zeilennummer und gibt eine Spalte für die aktuelle Ereignisprotokollzeit (start_time) und eine andere für die vorherige Ereignisprotokollzeit (end_time) zurück. Dieser Teil emuliert effektiv eine LAG-Funktion.
Der folgende Code implementiert den vierten Schritt in der Lösung:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; Dieser Code generiert die folgende Ausgabe:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
Dieser Schritt filtert Paare, bei denen die Differenz zwischen der vorherigen Endzeit und der aktuellen Startzeit größer als die zulässige Lücke ist, und Zeilen mit nur einem Ereignis. Jetzt müssen Sie die Startzeit jeder aktuellen Zeile mit der Endzeit der nächsten Zeile verbinden. Dies erfordert eine LEAD-ähnliche Kalkulation. Um dies zu erreichen, erstellt der Code wiederum Zeilennummern, die um eins auseinander liegen, nur dass diesmal die aktuelle Zeilennummer die Startzeit (start_time_grp) und die aktuelle Zeilennummer minus eins die Endzeit (end_time_grp) darstellt.
Wie zuvor besteht der nächste Schritt (Nummer 5) darin, die Zeilen zu entpivotieren. Hier ist der Code, der diesen Schritt implementiert:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; Ausgabe:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
Wie Sie sehen können, ist die grp-Spalte für jede Insel innerhalb einer Dienst-ID eindeutig.
Schritt 6 ist der letzte Schritt in der Lösung. Hier ist der Code, der diesen Schritt implementiert, der auch der vollständige Lösungscode ist:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); Dieser Schritt generiert die folgende Ausgabe:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
Dieser Schritt gruppiert die Zeilen nach serviceid und grp, filtert nur relevante Gruppen und gibt die minimale Startzeit als Beginn der Insel und die maximale Endzeit als Ende der Insel zurück.
Abbildung 3 zeigt den Plan, den ich für diese Lösung mit dem empfohlenen Index erhalten habe:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Planen Sie mit dem empfohlenen Index in Abbildung 3.
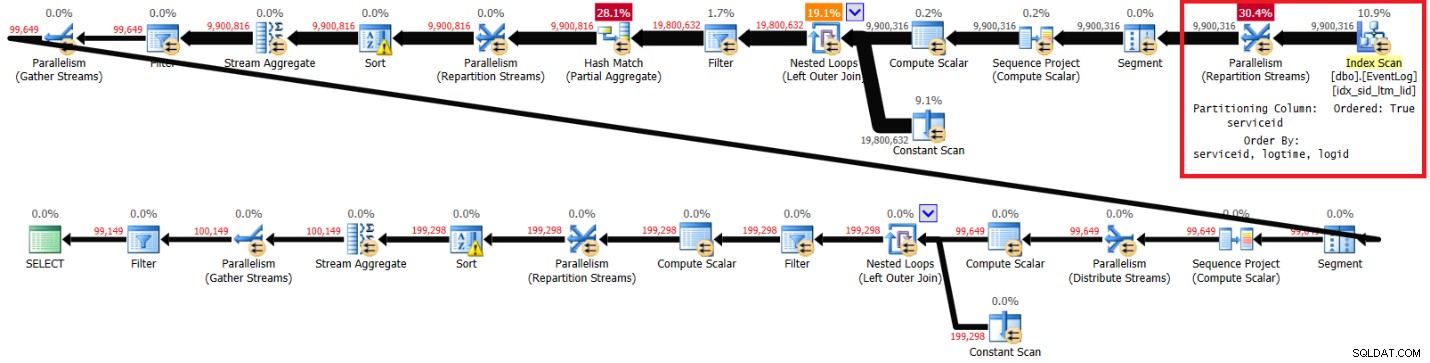 Abbildung 3:Plan für Kamils Lösung mit empfohlenem Index
Abbildung 3:Plan für Kamils Lösung mit empfohlenem Index
Hier sind die Leistungsstatistiken, die ich für diese Ausführung auf meinem Laptop erhalten habe:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
Ich habe dann den empfohlenen Index gelöscht und die Lösung erneut ausgeführt:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Ich habe den in Abbildung 4 gezeigten Plan für die Ausführung ohne den empfohlenen Index erhalten.
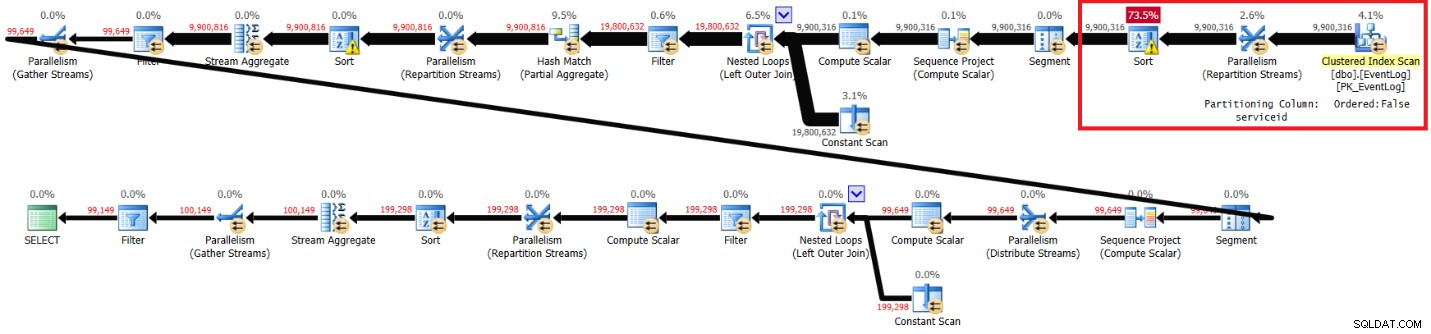 Abbildung 4:Plan für Kamils Lösung ohne empfohlenen Index
Abbildung 4:Plan für Kamils Lösung ohne empfohlenen Index
Hier sind die Leistungsstatistiken, die ich für diese Ausführung erhalten habe:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
Die Laufzeiten, CPU-Zeiten und CXPACKET-Wartezeiten sind meiner Lösung sehr ähnlich, obwohl die logischen Lesevorgänge geringer sind. Kamils Lösung läuft auch ohne den empfohlenen Index schneller auf meinem Laptop, und es scheint, dass es ähnliche Gründe hat.
Schlussfolgerung
Anomalien sind eine gute Sache. Sie machen Sie neugierig und veranlassen Sie, die Ursache des Problems zu erforschen und als Ergebnis neue Dinge zu lernen. Es ist interessant zu sehen, dass einige Abfragen auf bestimmten Computern ohne die empfohlene Indizierung schneller ausgeführt werden.
Nochmals vielen Dank an Toby, Peter und Kamil für Ihre Lösungen. In diesem Artikel habe ich Kamils Lösung mit seiner kreativen Technik zur Emulation von LAG und LEAD mit Zeilennummern, Unpivoting und Pivoting behandelt. Sie werden diese Technik nützlich finden, wenn Sie LAG- und LEAD-ähnliche Berechnungen benötigen, die in Umgebungen vor 2012 unterstützt werden müssen.