Der IGNORE_DUP_KEY Die Option für eindeutige Indizes gibt an, wie SQL Server auf einen INSERT-Versuch reagiert Doppelte Werte:Gilt nur für Tabellen (nicht Ansichten) und nur für Einfügungen. Jeder Einfügungsteil eines MERGE -Anweisung ignoriert jeden IGNORE_DUP_KEY Indexeinstellung.
Wenn IGNORE_DUP_KEY ist OFF , führt das erste gefundene Duplikat zu einem Fehler , und keine der neuen Zeilen wird eingefügt.
Wenn IGNORE_DUP_KEY ist ON , werden eingefügte Zeilen, die die Eindeutigkeit verletzen würden, verworfen. Die verbleibenden Zeilen werden erfolgreich eingefügt. Eine Warnung anstelle eines Fehlers wird eine Nachricht ausgegeben:
Artikelzusammenfassung
Der IGNORE_DUP_KEY index-Option kann sowohl für geclusterte als auch für nicht geclusterte eindeutige Indizes angegeben werden. Die Verwendung auf einem geclusterten Index kann zu einer viel schlechteren Leistung führen als für einen nicht gruppierten eindeutigen Index.
Die Größe des Leistungsunterschieds hängt davon ab, wie viele Eindeutigkeitsverletzungen während INSERT auftreten Betrieb. Je mehr Verletzungen auftreten, desto schlechter schneidet der Clustered Unique Index im Vergleich ab. Wenn es überhaupt keine Verstöße gibt, kann die Clustered-Index-Einfügung sogar eine bessere Leistung erbringen.
Clustered Unique Index Inserts
Für einen Clustered Unique Index mit IGNORE_DUP_KEY festgelegt, werden Duplikate von der Speicher-Engine gehandhabt .
Ein Großteil der Arbeit, die mit dem Einfügen jeder Zeile verbunden ist, wird durchgeführt, bevor das Duplikat erkannt wird. Zum Beispiel ein Clustered Index Insert Der Operator navigiert den Clustered-Index-B-Baum nach unten bis zu dem Punkt, an dem die neue Zeile stehen würde, und nimmt Seitenverriegelungen und die übliche Hierarchie von Sperren, bevor er den doppelten Schlüssel entdeckt.
Wenn die Bedingung für doppelte Schlüssel erkannt wird, wird ein Fehler angezeigt wird angehoben. Anstatt die Ausführung abzubrechen und den Fehler an den Client zurückzugeben, wird der Fehler intern behandelt. Die problematische Zeile wird nicht eingefügt, und die Ausführung wird fortgesetzt, wobei nach der nächsten einzufügenden Zeile gesucht wird. Wenn diese Zeile auf einen doppelten Schlüssel stößt, wird ein weiterer Fehler ausgelöst und behandelt, und so weiter.
Ausnahmen sind sehr teuer zu werfen und zu fangen. Eine beträchtliche Anzahl von Duplikaten verlangsamt die Ausführung sehr merklich.
Nonclustered Unique Index Inserts
Für einen nicht gruppierten eindeutigen Index mit IGNORE_DUP_KEY gesetzt, Duplikate werden vom Abfrageprozessor behandelt . Vor jedem Einfügungsversuch werden Duplikate erkannt und eine Warnung ausgegeben.
Der Abfrageprozessor entfernt Duplikate aus dem Einfügungsstrom und stellt sicher, dass die Speicher-Engine keine Duplikate erkennt. Folglich werden keine eindeutigen Schlüsselverletzungsfehler ausgelöst oder intern behandelt.
Der Kompromiss
Es gibt einen Kompromiss zwischen den Kosten für das Erkennen und Entfernen doppelter Schlüssel im Ausführungsplan und den Kosten für die Durchführung erheblicher einsatzbezogener Arbeiten und das Auslösen und Abfangen von Fehlern, wenn ein Duplikat gefunden wird.
Wenn Duplikate voraussichtlich sehr selten sind , die Speicher-Engine-Lösung (Clustered Index) ist möglicherweise effizienter. Wenn Duplikate weniger selten sind, zahlt sich der Abfrageprozessoransatz wahrscheinlich aus. Der genaue Übergangspunkt hängt von Faktoren wie der Laufzeiteffizienz der Ausführungsplankomponenten ab, die zum Erkennen und Entfernen von Duplikaten verwendet werden.
Der Rest dieses Artikels stellt eine Demo dar und befasst sich ausführlicher damit, warum der Speicher-Engine-Ansatz so schlecht abschneiden kann.
Demo
Das folgende Skript erstellt eine temporäre Tabelle mit einer Million Zeilen. Es hat 1.000 eindeutige Werte und 1.000 Zeilen für jeden eindeutigen Wert. Dieser Datensatz wird als Datenquelle für Einfügungen in Tabellen mit unterschiedlichen Indexkonfigurationen verwendet.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); ERSTELLEN Basislinie
Das folgende Einfügen in eine Tabellenvariable mit einem nicht eindeutigen gruppierten Index dauert etwa 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Beachten Sie das Fehlen von IGNORE_DUP_KEY auf die Zieltabellenvariable.
Clustered Unique Index
Einfügen derselben Daten in einen eindeutigen Cluster Index mit IGNORE_DUP_KEY setzen Sie ON dauert etwa 15.900 ms — fast 18 Mal schlimmer:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Nonclustered Unique Index
Einfügen der Daten in ein eindeutiges nonclustered Index mit IGNORE_DUP_KEY setzen Sie ON dauert etwa 700 ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Leistungszusammenfassung
Der Baseline-Test dauert 900 ms um alle eine Million Zeilen einzufügen. Der Nonclustered-Index-Test dauert 700 ms um nur die 1.000 verschiedenen Schlüssel einzufügen. Der Clustered-Index-Test dauert 15.900 ms um dieselben 1.000 eindeutigen Zeilen einzufügen.
Dieser Test wurde bewusst eingerichtet, um die schlechte Leistung der Speicher-Engine-Implementierung hervorzuheben, indem für jede erfolgreiche Zeile 999 Einheiten vergeudeter Arbeit (Latches, Sperren, Fehlerbehandlung) generiert werden.
Die beabsichtigte Nachricht ist nicht dieser IGNORE_DUP_KEY wird auf geclusterten Indizes immer schlecht abschneiden, nur dass es sein könnte, und es kann einen großen Unterschied zwischen geclusterten und nicht geclusterten Indizes geben.
Clustered-Index-Ausführungsplan
Im Clustered-Index-Insert-Plan ist nicht viel zu sehen:
Es werden 1.000.000 Zeilen an die Clustered Index Insert übergeben -Operator, der als „Rückgabe“ von 1.000 Zeilen angezeigt wird. Wenn wir uns die Plandetails ansehen, sehen wir:
- 1.244.008 logische Lesevorgänge beim Insert-Operator.
- Der größte Teil der Ausführungszeit wird beim Einfügen verbracht Betreiber.
- 11ms von
SOS_SCHEDULER_YIELDwartet (d.h. keine anderen warten).
Nichts, was die 15.900 ms wirklich erklärt der verstrichenen Zeit.
Warum die Leistung so schlecht ist
Es ist offensichtlich, dass dieser Plan für jede Zeile viel Arbeit leisten muss:
- Navigieren Sie durch die B-Tree-Ebenen des geclusterten Index, verriegeln und sperren Sie dabei, um den Einfügepunkt für den neuen Datensatz zu finden.
- Wenn sich eine der benötigten Indexseiten nicht im Speicher befindet, müssen sie von der Festplatte abgerufen werden.
- Erzeuge eine neue B-Tree-Zeile im Speicher.
- Protokollaufzeichnungen vorbereiten.
- Wenn ein Schlüsselduplikat gefunden wird (das kein Geisterdatensatz ist), lösen Sie einen Fehler aus, behandeln Sie diesen Fehler intern, geben Sie die aktuelle Zeile frei und fahren Sie an einer geeigneten Stelle im Code fort, um die nächste Kandidatenzeile zu verarbeiten.
Das ist alles ziemlich viel Arbeit, und denken Sie daran, dass alles für jede Zeile passiert .
Der Teil, auf den ich mich konzentrieren möchte, ist das Auslösen und Behandeln von Fehlern, weil es extrem ist teuer. Die verbleibenden oben genannten Aspekte wurden bereits in der Demo so billig wie möglich gemacht, indem eine Tabellenvariable und eine temporäre Tabelle verwendet wurden.
Ausnahmen
Als erstes möchte ich zeigen, dass Clustered Index Insert Der Operator löst wirklich eine Ausnahme aus, wenn er auf einen doppelten Schlüssel stößt.
Eine Möglichkeit, dies direkt zu zeigen, besteht darin, einen Debugger anzuhängen und einen Stack-Trace an dem Punkt zu erfassen, an dem die Ausnahme ausgelöst wird:
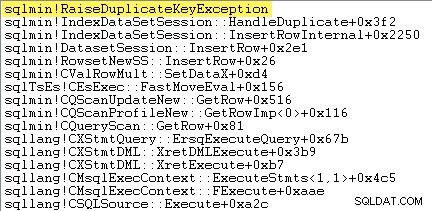
Der wichtige Punkt hier ist, dass das Auslösen und Abfangen von Ausnahmen sehr teuer ist.
Überwachen von SQL Server mit Windows Performance Recorder während der Test ausgeführt wurde und Analysieren der Ergebnisse in Windows Performance Analyzer zeigt:
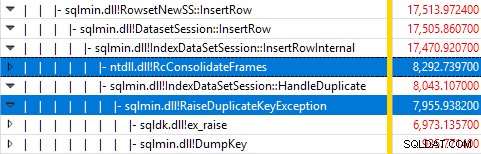
Fast die gesamte Abfrageausführungszeit wird in sqlmin!IndexDataSetSession::InsertRowInternal verbracht wie man es von einer Abfrage erwarten würde, die außer dem Einfügen von Zeilen kaum etwas anderes tut.
Die Überraschung ist, dass 45 % dieser Zeit damit verbracht wird, Ausnahmen über sqlmin!RaiseDuplicateKeyException auszulösen und weitere 47 % werden in den zugehörigen Ausnahmeabfangblock (die ntdll!RcConsolidateFrames Hierarchie) .
Zusammenfassend:Das Auslösen und Abfangen von Ausnahmen macht 92 % der Ausführungszeit aus unserer Test-Clustered-Index-Insert-Abfrage.
Probleme bei der Datenerfassung
Aufmerksamen Lesern wird vielleicht auffallen, dass ein erheblicher Anteil – etwa 12 % – der Zeit, die Ausnahmen auslöst, in sqlmin!DumpKey verbracht wird in der Windows Performance Analyzer-Grafik. Es lohnt sich, dies zusammen mit ein paar verwandten Artikeln schnell zu erkunden.
Als Teil des Auslösens einer Ausnahme muss SQL Server einige Daten sammeln, die nur zum Zeitpunkt des Auftretens des Fehlers verfügbar sind. Die mit einer Ausnahme bei doppeltem Schlüssel verknüpfte Fehlernummer ist 2627. Der Nachrichtentext in sys.messages für diese Fehlernummer ist:
Informationen zum Füllen dieser Platzmarkierungen müssen zu dem Zeitpunkt gesammelt werden, zu dem der Fehler gemeldet wird – sie sind später nicht mehr verfügbar! Das bedeutet, den Typ der Einschränkung, ihren Namen, den vollständigen Namen des Zielobjekts und den spezifischen Schlüsselwert nachzuschlagen und zu formatieren. All das braucht Zeit.
Der folgende Stack-Trace zeigt, wie der Server den doppelten Schlüsselwert während des DumpKey als Unicode-String formatiert Aufruf:
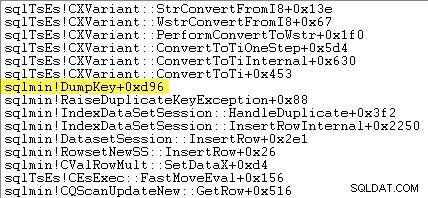
Die Ausnahmebehandlung beinhaltet auch das Erfassen eines Stack-Trace:
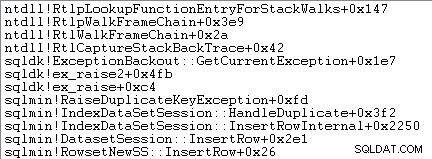
SQL Server zeichnet auch Informationen über Ausnahmen (einschließlich Stapelrahmen) in einem kleinen Ringpuffer auf, wie im Folgenden gezeigt:
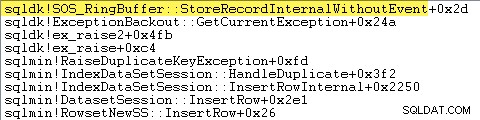
Sie können diese Ringpuffereinträge mit einem Befehl wie dem folgenden anzeigen:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Es folgt ein Beispiel für den XML-Datensatz für eine Ausnahme bei doppeltem Schlüssel. Beachten Sie die Stapelrahmen:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> All diese Hintergrundarbeit geschieht für jede Ausnahme. In unserem Test bedeutet dies, dass dies 999.000 Mal passiert – einmal für jede Zeile, die auf eine doppelte Schlüsselverletzung stößt.
Es gibt viele Möglichkeiten, dies zu sehen, zum Beispiel durch Ausführen eines Profiler-Trace mit der Exception Ereignis in den Fehlern und Warnungen Klasse. In unserem Testfall wird dies irgendwann der Fall sein 999.000 Zeilen mit TextData erzeugen Elemente wie diese:
Verletzung der UNIQUE KEY-Einschränkung 'UQ__#AC166DE__3213663B8B6E2E0E'Kann keinen doppelten Schlüssel in Objekt 'dbo.@T' einfügen.
Der doppelte Schlüsselwert ist (173).
Das Anfügen von Profiler bedeutet, dass jedes Ausnahmebehandlungsereignis einen großen zusätzlichen Aufwand verursacht, da die erforderlichen zusätzlichen Daten gesammelt und formatiert werden. Die zuvor erwähnten Standarddaten werden immer erfasst, auch wenn niemand die Informationen aktiv nutzt.
Um es klar zu sagen:Die in diesem Artikel gemeldeten Leistungszahlen wurden alle ohne angeschlossenen Debugger und ohne andere aktive Überwachung ermittelt.
Nonclustered-Index-Ausführungsplan
Obwohl er so viel schneller ist, ist der Nonclustered-Index-Insert-Plan etwas komplexer, also werde ich ihn in zwei Teile aufteilen.
Das allgemeine Thema ist, dass dieser Plan schneller ist, weil er Duplikate vorher eliminiert versuchen, sie in die Zieltabelle einzufügen.
Teil 1
Zuerst die rechte Seite des Nonclustered-Indexplans:
Dieser Teil des Plans lehnt alle Zeilen ab, die eine Schlüsselübereinstimmung in der Zieltabelle aufweisen für den eindeutigen Index mit IGNORE_DUP_KEY setzen Sie ON .
Möglicherweise erwarten Sie einen Anti Semi Join hier, aber SQL Server verfügt nicht über die notwendige Infrastruktur, um die erforderliche doppelte Schlüsselwarnung mit einem Anti Semi Join auszugeben Operator. (Falls das nicht schon Sinn macht, sollte es in Kürze.)
Stattdessen erhalten wir einen Plan mit einer Reihe interessanter Funktionen:
- Der Clustered Index Scan ist
Ordered:Trueum Eingaben für Merge Left Semi Join bereitzustellen sortiert nach Spaltec1im#DataTabelle. - Der Index-Scan der Tabellenvariablen ist
Ordered:False - Die Sortierung ordnet Zeilen nach Spalte
c1in der Tabellenvariable. Diese Bestellung könnte von einem Bestellten geliefert worden sein Scan des Tabellenvariablenindex aufc1, aber der Optimierer entscheidet über die Sortierung ist der günstigste Weg, um das erforderliche Maß an Halloween-Schutz zu bieten. - Die Tabellenvariable Index Scan hat internen
UPDLOCKundSERIALIZABLEHinweise, die angewendet werden, um die Zielstabilität während der Planausführung sicherzustellen. - Die Linke Halbverbindung zusammenführen sucht nach Übereinstimmungen in der Tabellenvariable für jeden Wert von
c1von#Datazurückgegeben Tisch. Im Gegensatz zu einem normalen Semi-Join gibt es jede Zeile aus, die an seiner oberen Eingabe empfangen wird. Es setzt ein Flag in einer Probe-Spalte um anzuzeigen, ob die aktuelle Zeile eine Übereinstimmung gefunden hat oder nicht. Die Sondenspalte wird von Merge Left Semi Join ausgegeben als Ausdruck namensExpr1012. - Die Bestätigung Der Operator prüft den Wert der Sondenspalte
Expr1012. Wenn es zum ersten Mal eine Zeile mit einem Prüfspaltenwert ungleich Null sieht (was darauf hinweist, dass eine Indexschlüsselübereinstimmung gefunden wurde), gibt es ein “Doppelter Schlüssel wurde ignoriert” aus Nachricht. - Die Bestätigung gibt nur Zeilen weiter, in denen die Sondenspalte null ist. Dadurch werden eingehende Zeilen eliminiert, die einen doppelten Schlüsselfehler erzeugen würden.
Das alles mag komplex erscheinen, aber es ist im Wesentlichen so einfach wie das Setzen eines Flags, wenn eine Übereinstimmung gefunden wird, das Ausgeben einer Warnung, wenn das Flag zum ersten Mal gesetzt wird, und das Weiterleiten von Zeilen an die Einfügung, die nicht bereits in der Zieltabelle vorhanden sind .
Teil 2
Der zweite Teil des Plans folgt dem Assert Betreiber:
Im vorherigen Teil des Plans wurden Zeilen entfernt, die eine Übereinstimmung in der Zieltabelle aufwiesen. Dieser Teil des Plans entfernt Duplikate innerhalb des Insert-Sets .
Stellen Sie sich beispielsweise vor, dass es in der Zieltabelle keine Zeilen gibt, in denen c1 = 1 ist . Wir können immer noch einen doppelten Schlüsselfehler verursachen, wenn wir versuchen, zwei Zeilen mit c1 = 1 einzufügen aus der Quelltabelle. Wir müssen das vermeiden, um die Semantik von IGNORE_DUP_KEY = ON zu berücksichtigen .
Dieser Aspekt wird vom Segment behandelt und Oben Betreiber.
Das Segment Operator setzt ein neues Flag (mit der Bezeichnung Segment1015 ), wenn es auf eine Zeile mit einem neuen Wert für c1 stößt . Da Zeilen in c1 dargestellt werden bestellen (dank des ordnungserhaltenden Merge ), kann sich der Plan auf alle Zeilen mit demselben c1 stützen Wert, der in einem zusammenhängenden Strom ankommt.
Das Oben Der Operator übergibt eine Zeile für jede Gruppe von Duplikaten, wie durch das Segment angegeben Flagge. Wenn die Oberseite Operator findet mehr als eine Zeile für dasselbe Segment Gruppe (c1 Wert), gibt es ein "Doppelter Schlüssel wurde ignoriert" aus Warnung, wenn dies das erste Mal ist, dass der Plan auf diese Bedingung gestoßen ist.
Der Nettoeffekt all dessen ist, dass für jeden eindeutigen Wert von c1 nur eine Zeile an die Einfügeoperatoren übergeben wird , und bei Bedarf wird eine Warnung generiert.
Der Ausführungsplan hat nun alle potenziellen Verstöße gegen doppelte Schlüssel eliminiert, also die verbleibende Table Insert und Index einfügen Operatoren können Zeilen sicher in den Heap- und Nonclustered-Index einfügen, ohne Angst vor einem doppelten Schlüsselfehler zu haben.
Denken Sie daran, dass der UPDLOCK und SERIALIZABLE Hinweise, die auf die Zieltabelle angewendet werden, stellen sicher, dass set sich während der Ausführung nicht ändern kann. Mit anderen Worten, eine gleichzeitige Anweisung kann die Zieltabelle nicht so ändern, dass beim Insert ein Fehler wegen doppeltem Schlüssel auftritt Betreiber. Das ist hier kein Problem, da wir eine private Tabellenvariable verwenden, aber SQL Server fügt die Hinweise trotzdem als allgemeine Sicherheitsmaßnahme hinzu.
Ohne diese Hinweise könnte ein nebenläufiger Prozess der Zieltabelle eine Zeile hinzufügen, die trotz der in Teil 1 des Plans durchgeführten Überprüfungen eine Verletzung des doppelten Schlüssels erzeugen würde. SQL Server muss sicher sein, dass die Ergebnisse der Existenzprüfung gültig bleiben.
Der neugierige Leser kann einige der oben beschriebenen Funktionen sehen, indem er die Trace-Flags 3604 und 8607 aktiviert, um den Ausgabebaum des Optimierers anzuzeigen:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Abschließende Gedanken
Der IGNORE_DUP_KEY Die index-Option wird von den meisten Leuten nicht sehr oft verwendet. Dennoch ist es interessant zu sehen, wie diese Funktionalität implementiert wird und warum es große Leistungsunterschiede zwischen IGNORE_DUP_KEY geben kann auf gruppierten und nicht gruppierten Indizes.
In vielen Fällen lohnt es sich, dem Beispiel des Abfrageprozessors zu folgen und Abfragen zu schreiben, die Duplikate explizit eliminieren, anstatt sich auf IGNORE_DUP_KEY zu verlassen . In unserem Beispiel würde das bedeuten:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Dies wird in etwa 400 ms ausgeführt , nur fürs Protokoll.