Wir alle machen Fehler, und wir alle können aus den Fehlern anderer Menschen lernen. In diesem Beitrag werfen wir einen Blick auf zahlreiche Online-Ressourcen, um ein schlechtes Datenbankdesign zu vermeiden, das zu vielen Problemen führen und sowohl Zeit als auch Geld kosten kann. Und in einem der nächsten Artikel werden wir Ihnen sagen, wo Sie Tipps und Best Practices finden.
Fehler beim Datenbankdesign und zu vermeidende Fehler
Es gibt zahlreiche Online-Ressourcen, die Datenbankdesignern dabei helfen, häufige Fehler und Irrtümer zu vermeiden. Offensichtlich ist dieser Artikel keine vollständige Liste aller Artikel da draußen. Stattdessen haben wir eine Vielzahl unterschiedlicher Quellen überprüft und kommentiert, damit Sie diejenige finden, die am besten zu Ihnen passt.
Unsere Empfehlung
Wenn es unter diesen Ressourcen nur einen Artikel gibt, den Sie lesen werden, sollte es „How to get Database Design Horribly False“ sein von Robert Sheldon
Beginnen wir mit dem DATAVERSITY-Blog, der eine breite Palette recht guter Ressourcen bereitstellt:
Zu vermeidende Primärschlüssel- und Fremdschlüsselfehler
von Michael Blaha | DATAVERSITY-Blog | 2. September 2015
Weitere Fehler beim Datenbankdesign – Verwirrung bei Viele-zu-Viele-Beziehungen
von Michael Blaha | DATAVERSITY-Blog | 30. September 2015
Verschiedene Fehler beim Datenbankdesign
von Michael Blaha | DATAVERSITY-Blog | 26. Oktober 2015
Michael Blaha hat einen schönen Satz von drei Artikeln beigesteuert. Jeder Artikel befasst sich mit verschiedenen Fallstricken bei der Datenbankmodellierung und dem physikalischen Design; Zu den Themen gehören Schlüssel, Beziehungen und allgemeine Fehler. Außerdem gibt es Diskussionen mit Michael zu einigen Punkten. Wenn Sie nach Fallstricken rund um Schlüssel und Beziehungen suchen, ist dies ein guter Ausgangspunkt.
Herr Blaha gibt an, dass „ungefähr 20 % der Datenbanken gegen Primärschlüsselregeln verstoßen“. Wow! Das bedeutet, dass etwa 20 % der Datenbankentwickler Primärschlüssel nicht richtig erstellt haben. Wenn diese Statistik wahr ist, dann zeigt sie wirklich die Bedeutung von Datenmodellierungswerkzeugen, die Modellierer stark „ermutigen“ oder sogar verlangen, Primärschlüssel zu definieren.
Herr Blaha teilt auch die Heuristik, dass „ungefähr 50 % der Datenbanken“ Fremdschlüsselprobleme haben (gemäß seiner Erfahrung mit Legacy-Datenbanken, die er untersucht hat). Er erinnert uns daran, informelle Verknüpfungen zwischen Tabellen zu vermeiden, indem der Wert von einer Tabelle in eine andere eingebettet wird, anstatt einen Fremdschlüssel zu verwenden.
Ich habe dieses Problem viele Male gesehen. Ich gebe zu, dass eine informelle Verknüpfung durch die zu implementierende Funktionalität erforderlich sein kann, aber häufiger geschieht dies aus einfacher Faulheit. Beispielsweise möchten wir möglicherweise die Benutzer-ID von jemandem anzeigen, der etwas geändert hat, also speichern wir die Benutzer-ID direkt in der Tabelle. Aber was ist, wenn dieser Benutzer seine Benutzer-ID ändert? Dann ist diese informelle Verbindung unterbrochen. Dies liegt oft an schlechtem Design und schlechter Modellierung.
Gestaltung Ihrer Datenbank:Die 5 wichtigsten Fehler, die Sie vermeiden sollten
von Henrique Netzka | DATAVERSITY-Blog | 2. November 2015
Ich war ein wenig enttäuscht von diesem Artikel, da er ein paar ziemlich spezifische Punkte (Speichern des Protokolls in einem CLOB) und ein paar sehr allgemeine (denken Sie an die Lokalisierung) enthielt. Insgesamt ist der Artikel in Ordnung, aber sind das wirklich die Top 5 Fehler, die es zu vermeiden gilt? Meiner Meinung nach gibt es mehrere andere häufige Fehler, die auf die Liste kommen sollten.
Positiv anzumerken ist jedoch, dass dies einer der wenigen Artikel ist, in dem Globalisierung und Lokalisierung sinnvoll erwähnt werden. Ich arbeite in einer sehr mehrsprachigen Umgebung und habe mehrere schreckliche Implementierungen der Lokalisierung gesehen, daher war ich froh, dass dieses Problem erwähnt wurde. Sprachspalten und Zeitzonenspalten mögen offensichtlich erscheinen, aber sie kommen sehr selten in Datenbankmodellen vor.
Davon abgesehen hielt ich es für interessant, ein Modell zu erstellen, das Übersetzungen enthält, die von Endbenutzern geändert werden können (im Gegensatz zur Verwendung von Ressourcenpaketen). Vor einiger Zeit habe ich über ein Modell für eine Online-Umfragedatenbank geschrieben. Hier habe ich eine vereinfachte Übersetzung von Fragen und Antwortmöglichkeiten modelliert:
Unter der Annahme, dass wir Endbenutzern erlauben müssen, die Übersetzungen zu pflegen, wäre die bevorzugte Methode, Übersetzungstabellen für Fragen und Antworten hinzuzufügen:
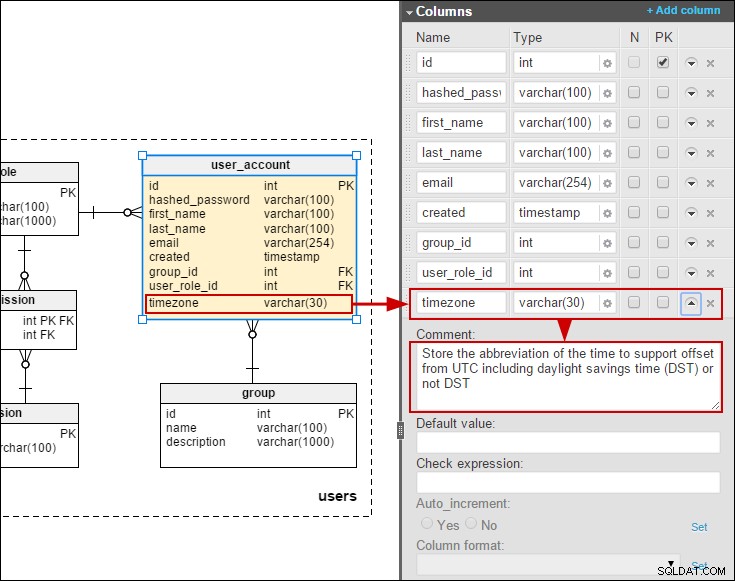
Ich habe auch eine Zeitzone zum user_account Tabelle, damit wir Daten/Zeiten in der Ortszeit der Benutzer speichern können:
7 häufige Fehler beim Datenbankdesign
von Grzegorz Kaczor | Vertabelo-Blog | 17. Juli 2015
Ich werde hier eine kleine Eigenwerbung machen. Wir bemühen uns, hier regelmäßig interessante und ansprechende Artikel zu veröffentlichen.
Dieser spezielle Artikel weist auf mehrere wichtige Problembereiche hin, wie Benennung, Indexierung, Volumenüberlegungen und Audit-Trails. Der Artikel geht sogar auf Probleme im Zusammenhang mit bestimmten DBM-Systemen ein, wie z. B. Oracle-Einschränkungen für Tabellennamen. Ich mag wirklich schöne, klare Beispiele, auch wenn sie zeigen, wie Designer Fehler und Irrtümer machen.
Offensichtlich ist es nicht möglich, jeden Designfehler aufzulisten, und die aufgelisteten Fehler sind möglicherweise nicht Ihre die häufigsten Fehler. Wenn wir über häufige Fehler schreiben, beziehen wir uns auf Fehler, die wir gemacht oder in der Arbeit anderer gefunden haben. Eine vollständige Liste der Fehler, geordnet nach Häufigkeit, wäre für eine einzelne Person unmöglich zu erstellen. Dennoch denke ich, dass dieser Artikel einige nützliche Einblicke in mögliche Fallstricke bietet. Es ist insgesamt eine schöne solide Ressource.
Während Herr Kaczor in seinem Artikel mehrere interessante Punkte anführt, fand ich seine Kommentare über „Mögliches Volumen oder Verkehr nicht berücksichtigen“ ziemlich interessant. Insbesondere die Empfehlung, häufig verwendete Daten von historischen Daten zu trennen, ist besonders relevant. Dies ist eine Lösung, die wir häufig in unseren Messaging-Anwendungen verwenden; Wir müssen über einen durchsuchbaren Verlauf aller Nachrichten verfügen, aber die Nachrichten, auf die am wahrscheinlichsten zugegriffen wird, sind diejenigen, die in den letzten Tagen gepostet wurden. Daher ist die Aufteilung „aktiver“ oder aktueller Daten, auf die häufig zugegriffen wird (ein viel kleineres Datenvolumen), von langfristigen historischen Daten (der großen Datenmenge) im Allgemeinen eine sehr gute Technik.
Häufige Fehler beim Datenbankdesign
von Troy Blake | Senior DBA-Blog | 11. Juli 2015
Der Artikel von Troy Blake ist eine weitere gute Ressource, obwohl ich diesen Artikel vielleicht in „Häufige SQL Server-Designfehler“ umbenannt hätte.
Wir haben zum Beispiel den Kommentar:„Gespeicherte Prozeduren sind Ihr bester Freund, wenn es darum geht, SQL Server effektiv zu nutzen“. Das ist in Ordnung, aber ist dies ein häufiger allgemeiner Fehler oder eher spezifisch für SQL Server? Ich müsste mich dafür entscheiden, dass dies ein bisschen SQL Server-spezifisch ist, da die Verwendung gespeicherter Prozeduren Nachteile hat, wie zum Beispiel herstellerspezifische gespeicherte Prozeduren und damit eine Herstellerbindung. Daher bin ich kein Fan davon, „keine gespeicherten Prozeduren verwenden“ in diese Liste aufzunehmen.
Auf der positiven Seite denke ich jedoch, dass der Autor einige sehr häufige Fehler identifiziert hat, wie schlechte Planung, schäbiges Systemdesign, begrenzte Dokumentation, schwache Benennungsstandards und fehlende Tests.
Daher würde ich dies als sehr nützliche Referenz für SQL Server-Anwender und als nützliche Referenz für andere einstufen.
Sieben Datenmodellierungsfehler
von Kurt Cagle | LinkedIn | 12. Juni 2015
Ich habe es wirklich genossen, Mr. Cagles Liste der Fehler bei der Datenbankmodellierung zu lesen. Diese stammen aus der Sicht eines Datenbankarchitekten; er identifiziert eindeutig übergeordnete Modellierungsfehler, die vermieden werden sollten. Mit dieser Gesamtbildansicht können Sie einem möglichen Modellierungschaos ein Ende bereiten.
Einige der im Artikel erwähnten Typen sind anderswo zu finden, aber einige davon sind einzigartig:Sie werden zu früh abstrakt oder mischen konzeptionelle, logische und physikalische Modelle. Diese werden von anderen Autoren nicht oft erwähnt, wahrscheinlich weil sie sich eher auf den Datenmodellierungsprozess als auf die umfassendere Systemansicht konzentrieren.
Insbesondere das Beispiel „Zu früh zu abstrakt werden“ beschreibt einen interessanten Denkprozess, bei dem einige Beispiel-„Geschichten“ erstellt und getestet werden, welche Beziehungen in diesem Bereich wichtig sind. Dies konzentriert das Denken auf die Beziehungen zwischen den zu modellierenden Objekten. Daraus ergeben sich Fragen wie was sind die wichtigen Beziehungen in diesem Bereich ?
Basierend auf diesem Verständnis erstellen wir das Modell um Beziehungen herum, anstatt bei einzelnen Domänenelementen zu beginnen und die Beziehungen darauf aufzubauen. Während viele von uns diesen Ansatz verwenden, hat sich unter diesen Ressourcen kein anderer Autor dazu geäußert. Ich fand diese Beschreibung und die Beispiele recht interessant.
Wie man das Datenbankdesign schrecklich falsch macht
von Robert Sheldon | Einfaches Gespräch | 6. März 2015
Wenn es unter diesen Ressourcen nur einen Artikel gibt, den Sie lesen werden, sollte es dieser von Robert Sheldon sein
Was mir an diesem Artikel sehr gut gefällt, ist, dass es zu jedem der genannten Fehler Tipps gibt, wie man es richtig macht. Die meisten davon konzentrieren sich darauf, den Fehler zu vermeiden, anstatt ihn zu korrigieren, aber ich denke immer noch, dass sie sehr nützlich sind. Hier gibt es sehr wenig Theorie; meist direkte Antworten zur Vermeidung von Fehlern bei der Datenmodellierung. Es gibt ein paar spezifische SQL Server-Punkte, aber meistens wird SQL Server verwendet, um Beispiele für die Fehlervermeidung oder Auswege aus dem Scheitern zu liefern.
Der Umfang des Artikels ist auch ziemlich weit gefasst:Er behandelt Vernachlässigung der Planung, sich nicht um die Dokumentation zu kümmern, die Verwendung lausiger Namenskonventionen, Probleme bei der Normalisierung (zu viel oder zu wenig), Versagen bei Schlüsseln und Einschränkungen, nicht ordnungsgemäße Indizierung und Leistung unzureichende Tests.
Besonders gefallen haben mir die praktischen Ratschläge zur Datenintegrität – wann man Check Constraints verwendet und wann man Fremdschlüssel definiert. Darüber hinaus beschreibt Mr. Sheldon auch die Situation, in der Teams auf die Anwendung verzichten, um Integrität durchzusetzen. Er bringt es auf den Punkt, wenn er feststellt, dass auf eine Datenbank auf verschiedene Arten und von zahlreichen Anwendungen aus zugegriffen werden kann. Er kommt zu dem Schluss, dass „Daten dort geschützt werden sollten, wo sie gespeichert sind:in der Datenbank“. Dies ist so wahr, dass es Entwicklungsteams und Managern wiederholt werden kann, um die Bedeutung der Implementierung von Integritätsprüfungen im Datenmodell zu erklären.
Dies ist meine Art von Artikel, und Sie können anhand der zahlreichen Kommentare, die ihn befürworten, erkennen, dass andere dem zustimmen. Also, Bestnoten hier; es ist eine sehr wertvolle Ressource.
Zehn häufige Fehler beim Datenbankdesign
von Louis Davidson | Einfaches Gespräch | 26. Februar 2007
Ich fand diesen Artikel ziemlich gut, da er viele häufige Designfehler behandelte. Es gab sinnvolle Analogien, Beispiele, Modelle und sogar einige klassische Zitate von William Shakespeare und J.R.R. Tolkien.
Ein paar der Fehler wurden detaillierter erklärt als andere, mit langen Beispielen und SQL-Auszügen, die ich etwas umständlich fand. Aber das ist Geschmackssache.
Auch hier haben wir einige Themen speziell für SQL Server. Beispielsweise ist der Punkt, keine gespeicherten Prozeduren für den Zugriff auf Daten zu verwenden, gut für SQL, aber SPs sind nicht immer eine gute Idee, wenn das Ziel die Unterstützung mehrerer DBMS ist. Außerdem wird davor gewarnt, zu versuchen, generische T-SQL-Objekte zu codieren. Da ich selten mit SQL Server oder Sybase arbeite, fand ich diesen Tipp nicht relevant.
Die Liste ist der von Robert Sheldon ziemlich ähnlich, aber wenn Sie hauptsächlich mit SQL Server arbeiten, werden Sie einige zusätzliche Informationen finden.
Fünf einfache Fehler beim Datenbankdesign, die Sie vermeiden sollten
von Anith Sen Larson | Einfaches Gespräch | 16. Oktober 2009
Dieser Artikel enthält einige aussagekräftige Beispiele für jeden der behandelten einfachen Designfehler. Andererseits konzentriert es sich eher auf ähnliche Arten von Fehlern:gemeinsame Nachschlagetabellen, Entitätsattributwerttabellen und Attributaufteilung.
Die Beobachtungen sind in Ordnung, und der Artikel enthält sogar Referenzen, die eher selten sind. Dennoch würde ich gerne allgemeinere Datenbankentwurfsfehler sehen. Diese Fehler schienen ziemlich spezifisch zu sein, aber wie ich bereits geschrieben habe, sind die Fehler, über die wir schreiben, im Allgemeinen diejenigen, mit denen wir persönliche Erfahrungen gemacht haben.
Ein Punkt, der mir gefiel, war eine bestimmte Faustregel für die Entscheidung, wann eine Check-Einschränkung oder eine separate Tabelle mit einer Fremdschlüssel-Einschränkung verwendet werden sollte. Mehrere Autoren geben ähnliche Empfehlungen, aber Herr Larson unterteilt sie in „muss“, „erwägt“ und „starke Argumente“ – mit dem Eingeständnis, dass „Design eine Mischung aus Kunst und Wissenschaft ist und daher Kompromisse beinhaltet“. Ich finde das sehr wahr.
Die zehn häufigsten Fehler beim Design physischer Datenbanken
von Craig Mullins | Daten und Technologie heute | 5. August 2013
Wie der Name schon sagt, orientiert sich „Top Ten Most Common Physical Database Design Mistakes“ eher am physischen Design als am logischen und konzeptionellen Design. Keiner der vom Autor Craig Mullins erwähnten Fehler sticht wirklich heraus oder ist einzigartig, daher würde ich diese Informationen Leuten empfehlen, die auf der physischen DBA-Seite arbeiten.
Außerdem sind die Beschreibungen etwas kurz, sodass es manchmal schwer zu erkennen ist, warum ein bestimmter Fehler Probleme verursachen wird. An kurzen Beschreibungen ist grundsätzlich nichts auszusetzen, aber sie geben einem nicht viel zu denken. Und es werden keine Beispiele präsentiert.
Es wird ein interessanter Punkt in Bezug auf das Versäumnis, Daten zu teilen, angesprochen. Dieser Punkt wird gelegentlich in anderen Artikeln erwähnt, jedoch nicht als Konstruktionsfehler. Ich sehe dieses Problem jedoch ziemlich häufig, wenn Datenbanken basierend auf sehr ähnlichen Anforderungen „neu erstellt“ werden, aber von einem neuen Team oder für ein neues Produkt
.Oft kommt es vor, dass dem Produktteam später klar wird, dass es gerne Daten verwendet hätte, die bereits im „Vater“ seiner aktuellen Datenbank vorhanden waren. Eigentlich hätten sie aber den Elternteil verbessern sollen, anstatt einen neuen Nachkommen zu schaffen. Anwendungen sollen Daten teilen; Gutes Design kann eine häufigere Wiederverwendung einer Datenbank ermöglichen.
Machen Sie diese 5 Fehler beim Datenbankdesign?
von Thomas Larock | Blog von Thomas Larock | 2. Januar 2012
Vielleicht finden Sie ein paar interessante Punkte, wenn Sie die Frage von Thomas Larock beantworten:Machen Sie diese 5 Fehler beim Datenbankdesign?
Dieser Artikel ist ziemlich stark auf Schlüssel (Fremdschlüssel, Ersatzschlüssel und generierte Schlüssel) ausgerichtet. Es hat jedoch einen wichtigen Punkt:Man sollte nicht davon ausgehen, dass DBMS-Funktionen auf allen Systemen gleich sind. Ich denke, das ist ein sehr guter Punkt. Es ist auch eines, das in den meisten anderen Artikeln nicht zu finden ist, vielleicht weil sich viele Autoren auf ein einzelnes DBMS konzentrieren und überwiegend damit arbeiten.
Entwerfen einer Datenbank:7 Dinge, die Sie nicht tun möchten
von Thomas Larock | Blog von Thomas Larock | 16. Januar 2013
Herr Larock hat ein paar seiner „5 Fehler beim Datenbankdesign“ wiederverwertet, als er „7 Dinge, die Sie nicht tun wollen“ schrieb, aber hier gibt es noch andere gute Punkte.
Interessanterweise sind einige der Punkte, die Herr Larock anführt, nicht in vielen anderen Quellen zu finden. Sie erhalten ein paar ziemlich einzigartige Beobachtungen, wie „keine Leistungserwartungen haben“. Dies ist ein schwerwiegender Fehler, der meiner Erfahrung nach recht häufig vorkommt. Selbst bei der Entwicklung des Anwendungscodes beginnen die Leute oft, nachdem das Datenmodell, die Datenbank und die Anwendung selbst erstellt wurden, über die nicht-funktionalen Anforderungen nachzudenken (wenn nicht-funktionale Tests erstellt werden müssen) und beginnen, Leistungserwartungen zu definieren .
Umgekehrt gibt es ein paar Punkte, die ich nicht in meine eigene Top-Ten-Liste aufnehmen würde, wie z. B. „groß raus, nur für den Fall“. Ich verstehe den Punkt, aber er steht nicht so weit oben auf meiner Liste, wenn ich ein Datenmodell erstelle. Es gibt keine Spezifität für ein bestimmtes DBM-System, das ist also ein Bonus.
Abschließend lassen sich viele dieser Punkte unter dem Punkt „Anforderungen nicht verstanden“ zusammenfassen, der wirklich auf meiner Top-10-Fehlerliste steht.
Wie man 8 häufige Fehler bei der Datenbankentwicklung vermeidet
von Base36 | 6. Dezember 2012
Ich war sehr daran interessiert, diesen Artikel zu lesen. Allerdings war ich etwas enttäuscht. Es wird nicht viel über Vermeidung diskutiert, und der Punkt des Artikels scheint wirklich zu sein, „dies sind häufige Datenbankfehler“ und „warum sie Fehler sind“; Beschreibungen zur Vermeidung des Fehlers sind weniger prominent.
Darüber hinaus sind einige der Top-8-Fehler des Artikels tatsächlich umstritten. Ein Beispiel ist der Missbrauch des Primärschlüssels. Base36 teilt uns mit, dass sie vom System generiert werden müssen und nicht auf Anwendungsdaten in der Zeile basieren. Obwohl ich dem bis zu einem gewissen Punkt zustimme, bin ich nicht davon überzeugt, dass alle PKs sollten immer generiert werden; das ist ein bisschen zu kategorisch.
Andererseits ist der Fehler von „Hard Deletes“ interessant und wird an anderer Stelle nicht oft erwähnt. Vorläufige Löschungen verursachen andere Probleme, aber es ist wahr, dass das einfache Markieren einer Zeile als inaktiv seine Vorteile hat, wenn Sie versuchen herauszufinden, wohin die Daten gegangen sind, die gestern im System waren. Das Durchsuchen von Transaktionsprotokollen ist nicht meine Vorstellung von einer angenehmen Art, einen Tag zu verbringen.
Sieben Todsünden des Datenbankdesigns
von Jason Tiret | Zeitschrift für Unternehmenssysteme | 16. Februar 2010
Ich war ziemlich hoffnungsvoll, als ich anfing, Jason Tirets Artikel „Sieben Todsünden des Datenbankdesigns“ zu lesen. Daher war ich froh, dass es nicht nur Fehler recycelt, die in zahlreichen anderen Artikeln zu finden sind. Im Gegenteil, es bot eine „Sünde“, die ich in anderen Listen nicht gefunden hatte:Der Versuch, das gesamte Datenbankdesign „im Voraus“ durchzuführen und das Modell nicht zu aktualisieren, nachdem die Datenbank in Produktion ist, wenn Änderungen an der Datenbank vorgenommen werden. (Oder, wie Jason es ausdrückt:„Das Datenmodell nicht wie einen lebenden, atmenden Organismus behandeln“).
Ich habe diesen Fehler oft gesehen. Die meisten Menschen erkennen ihren Fehler erst, wenn sie Aktualisierungen an einem Modell vornehmen müssen, das nicht mehr mit der tatsächlichen Datenbank übereinstimmt. Das Ergebnis ist natürlich ein nutzloses Modell. Wie es im Artikel heißt, „müssen die Änderungen ihren Weg zurück zum Modell finden.“
Andererseits sind die meisten von Jasons Listenpunkten ziemlich bekannt. Die Beschreibungen sind gut, aber es gibt nicht sehr viele Beispiele. Weitere Beispiele und Details wären hilfreich.
Die häufigsten Fehler beim Datenbankdesign
von Brian Prince | eWeek.com | 19. März 2008

Der Artikel „Die häufigsten Fehler beim Datenbankdesign“ ist eigentlich eine Reihe von Folien aus einer Präsentation. Es gibt ein paar interessante Gedanken, aber einige der einzigartigen Gegenstände sind vielleicht ein bisschen esoterisch. Ich denke dabei an Punkte wie „RAID kennenlernen“ und die Beteiligung von Interessenvertretern.
Im Allgemeinen würde ich dies nicht auf Ihre Leseliste setzen, es sei denn, Sie konzentrieren sich auf allgemeine Themen (Planung, Benennung, Normalisierung, Indizes) und physische Details.
10 häufige Designfehler
von davidm | SQL Server-Blogs – SQLTeam.com | 12. September 2005
Einige der Punkte in „Zehn häufige Designfehler“ sind interessant und relativ neu. Einige dieser Fehler sind jedoch ziemlich umstritten, wie z. B. die „Verwendung von NULLen“ und die Denormalisierung.
Ich stimme zu, dass das Erstellen aller Spalten als nullable ein Fehler ist, aber das Definieren einer Spalte als nullable kann für eine bestimmte Geschäftsfunktion erforderlich sein. Kann es daher als allgemeiner Fehler angesehen werden? Ich denke nicht.
Ein weiterer Punkt, mit dem ich mich auseinandersetze, ist die Denormalisierung. Dies ist nicht immer ein Konstruktionsfehler. Beispielsweise kann eine Denormalisierung aus Leistungsgründen erforderlich sein.
Auch diesem Artikel fehlen weitgehend Details und Beispiele. Die Gespräche zwischen DBA und Programmierer oder Manager sind amüsant, aber ich hätte mir konkretere Beispiele und ausführlichere Begründungen für diese häufigen Fehler gewünscht.
OTLT und EAV:die beiden großen Designfehler, die alle Anfänger machen
von Tony Andrews | Tony Andrews über Oracle und Datenbanken | 21. Oktober 2004
Der Artikel von Herrn Andrews erinnert uns an die Fehler „One True Lookup Table“ (OTLT) und Entity-Attribute-Value (EAV), die in anderen Artikeln erwähnt werden. Ein netter Punkt an dieser Präsentation ist, dass sie sich auf diese beiden Fehler konzentriert, sodass Beschreibungen und Beispiele präzise sind. Außerdem wird eine mögliche Erklärung dafür gegeben, warum einige Designer OTLT und EAV implementieren.
Zur Erinnerung:Die OTLT-Tabelle sieht normalerweise etwa so aus, wobei Einträge aus mehreren Domänen in dieselbe Tabelle geworfen werden:
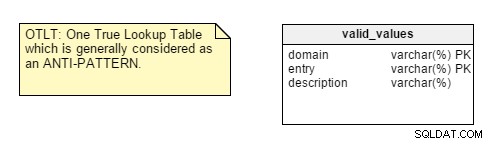
Wie üblich wird darüber diskutiert, ob OTLT eine praktikable Lösung und ein gutes Entwurfsmuster ist. Ich muss sagen, dass ich auf der Seite der Anti-OTLT-Gruppe stehe; Diese Tabellen führen zu zahlreichen Problemen. Wir könnten die Analogie verwenden, einen einzigen Enumerator zu verwenden, um alle möglichen Werte aller möglichen Konstanten darzustellen. Das habe ich bisher noch nie gesehen.
Häufige Datenbankfehler
von John Paul Ashenfelter | Dr. Dobbs | 1. Januar 2002
Der Artikel von Herrn Ashenfelter listet satte 15 häufige Datenbankfehler auf. Es gibt sogar ein paar Fehler, die in anderen Artikeln nicht häufig erwähnt werden. Leider sind die Beschreibungen relativ kurz und es gibt keine Beispiele. Der Vorteil dieses Artikels besteht darin, dass die Liste viele Bereiche abdeckt und als „Checkliste“ von Fehlern verwendet werden kann, die es zu vermeiden gilt. Auch wenn ich diese Fehler nicht zu den wichtigsten Datenbankfehlern zähle, gehören sie sicherlich zu den häufigsten.
Positiv anzumerken ist, dass dies einer der wenigen Artikel ist, der die Notwendigkeit erwähnt, die Internationalisierung von Formaten für Daten wie Datum, Währung und Adresse zu handhaben. Hier wäre ein Beispiel schön. Es könnte so einfach sein wie „Stellen Sie sicher, dass State eine Nullable-Spalte ist; in vielen Ländern gibt es keinen Staat, der mit einer Adresse verbunden ist“.
Weiter oben in diesem Artikel habe ich andere Bedenken und einige Ansätze zur Vorbereitung auf die Globalisierung Ihrer Datenbank erwähnt, wie Zeitzonen und Übersetzungen (Lokalisierung). Die Tatsache, dass kein anderer Artikel die Besorgnis über Währungs- und Datumsformate erwähnt, ist beunruhigend. Sind unsere Datenbanken für den weltweiten Einsatz unserer Anwendungen vorbereitet?
Ehrenvolle Erwähnungen
Natürlich gibt es noch andere Artikel, die häufige Fehler und Fehler beim Datenbankdesign beschreiben, aber wir wollten Ihnen einen umfassenden Überblick über verschiedene Ressourcen geben. Weitere Informationen finden Sie in Artikeln wie:
10 häufige Fehler beim Datenbankdesign | MIS-Klassen-Blog | 29. Januar 2012
10 häufige Fehler im Datenbankdesign | IDG.se | 24. Juni 2010
Online-Ressourcen:Wo anfangen? Wohin gehen?
Wie bereits erwähnt, ist diese Liste definitiv nicht als erschöpfende Untersuchung aller Online-Artikel gedacht, in denen Fehler und Fehler beim Datenbankdesign beschrieben werden. Vielmehr haben wir mehrere Quellen identifiziert, die besonders nützlich sind oder einen bestimmten Schwerpunkt haben, den Sie möglicherweise nützlich finden.
Bitte zögern Sie nicht, weitere Artikel zu empfehlen.