[ Teil 1 | Teil 2 | Teil 3 ]
In Teil 1 habe ich gezeigt, wie sowohl Seiten- als auch Columnstore-Komprimierung die Größe einer 1-TB-Tabelle um 80 % oder mehr reduzieren können. Ich war zwar beeindruckt, dass ich eine Tabelle von 1 TB auf 50 GB verkleinern konnte, aber ich war nicht sehr zufrieden mit der dafür benötigten Zeit (zwischen 2 und 14 Stunden). Mit einigen Tipps, die mir freundlicherweise von Leuten wie Joe Obbish, Lonny Niederstadt, Niko Neugebauer und anderen ausgeliehen wurden, werde ich in diesem Beitrag versuchen, einige Änderungen an meinem ursprünglichen Versuch vorzunehmen, eine bessere Ladeleistung zu erzielen. Da der reguläre Columnstore-Index bei diesem Datensatz nicht besser komprimiert wurde als die Seitenkomprimierung , und es dauerte 13 Stunden länger, um dorthin zu gelangen, konzentriere ich mich ausschließlich auf die fortgeschrittenere Lösung mit COLUMNSTORE_ARCHIVE Komprimierung.
Zu den Problemen, die meiner Meinung nach die Leistung beeinträchtigt haben, gehören die folgenden:
- Schlechte Dateilayoutauswahl – Ich habe 8 Dateien in einer Dateigruppe abgelegt, mit Parallelität, aber keiner (oder suboptimalen) Partitionierung, und I/Os mit rücksichtsloser Hingabe über mehrere Dateien gesprüht. Um dies zu beheben, werde ich:
- partitionieren Sie die Tabelle in 8 Partitionen (eine pro Kern)
- Speichern Sie die Datendatei jeder Partition in einer eigenen Dateigruppe
- verwenden Sie 8 separate Prozesse, um sich mit jeder Partition zu verbinden
- Archivkomprimierung auf allen außer der "aktiven" Partition verwenden
- zu viele kleine Batches und suboptimale Zeilengruppenbelegung – Durch die gleichzeitige Verarbeitung von 10 Millionen Zeilen habe ich neun Zeilengruppen mit netten 1.048.576 Zeilen gefüllt, und dann würden die verbleibenden 562.816 Zeilen in einer anderen kleineren Zeilengruppe landen. Und alle ungleichmäßigen Verteilungen, die einen Rest <102.400 Zeilen hinterlassen, würden Einfügungen in die weniger effiziente Delta-Speicherstruktur einsickern lassen. Um Zeilen gleichmäßiger zu verteilen und Deltaspeicher zu vermeiden, werde ich:
- so viele Daten wie möglich in genauen Vielfachen von 1.048.576 Zeilen verarbeiten
- Verteilen Sie diese so gleichmäßig wie möglich auf 8 Partitionen
- Verwenden Sie eine Stapelgröße, die näher am 10-fachen -> 100 Millionen Zeilen liegt
- Scheduler-Stacking – Obwohl ich dies nicht überprüft habe, ist es möglich, dass ein Teil der Verlangsamung dadurch verursacht wurde, dass ein Scheduler zu viel Arbeit und ein anderer Scheduler nicht genug Arbeit aufnahm, aufgrund von Scheduler Round-Robining. Jetzt, da ich die Daten absichtlich mit 8 maxdop 1-Prozessen statt mit einem maxdop 8-Prozess laden werde, um alle Planer gleichmäßig zu beschäftigen, werde ich:
- Verwenden Sie eine gespeicherte Prozedur, die versucht, einen gleichmäßigen Ausgleich zwischen Planern zu schaffen (siehe Seiten 189-191 in SQLCAT's Guide to:Relational Engine für die Inspiration hinter dieser Idee).
- Aktivieren Sie die globalen Trace-Flags 2467 und 2469, wie in der Dokumentation gewarnt wird
- Columnstore-Komprimierungsaufgabe im Hintergrund – es war verschwenderisch, dies während des Befüllens laufen zu lassen, da ich sowieso vorhatte, am Ende neu zu bauen. Diesmal werde ich:
- Deaktivieren Sie diese Aufgabe mit dem globalen Trace-Flag 634
Ich habe die ursprüngliche Partitionsfunktion und das Schema verworfen und eine neue erstellt, die auf einer gleichmäßigeren Verteilung der Daten basiert. Ich möchte, dass 8 Partitionen der Anzahl der Kerne und der Anzahl der Datendateien entsprechen, um die "Parallelität des armen Mannes", die ich verwenden möchte, zu maximieren.
Zuerst müssen wir einen neuen Satz von Dateigruppen erstellen, jede mit ihrer eigenen Datei:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Als nächstes habe ich mir die Anzahl der Zeilen in der Tabelle angesehen:3.754.965.954. Um diese genau zu verteilen gleichmäßig über 8 Partitionen verteilt wären das 469.370.744,25 Zeilen pro Partition. Damit es gut funktioniert, passen wir die Partitionsgrenzen an nächste an Vielfaches von 1.048.576 Zeilen. Das ist 1,048,576 x 448 = 469,762,048 – das wäre die Anzahl der Zeilen, die wir in den ersten 7 Partitionen anstreben, wobei 466.631.618 Zeilen in der letzten Partition verbleiben. Um die aktuelle OID zu sehen Werte, die als Grenzen dienen würden, um die optimale Anzahl von Zeilen in jeder Partition zu enthalten, habe ich diese Abfrage gegen die ursprüngliche Tabelle ausgeführt (da die Ausführung 25 Minuten dauerte, habe ich schnell gelernt, diese Ergebnisse in eine separate Tabelle zu schreiben):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
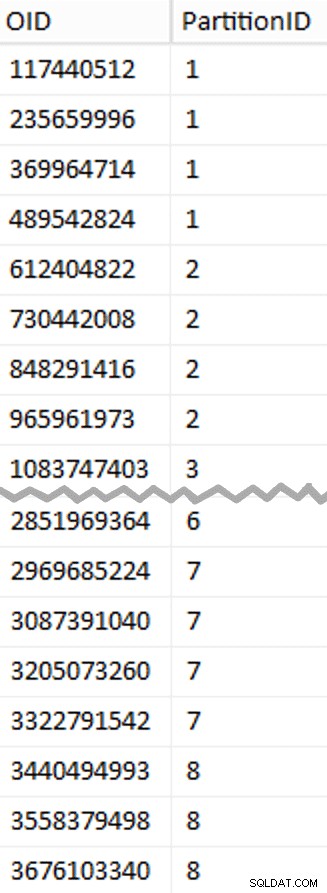 Hier gibt es mehr zu entpacken, als Sie vielleicht erwarten. Der CTE übernimmt die ganze Schwerarbeit, da er die gesamte 1,14-TB-Tabelle scannen und jeder Zeile eine Zeilennummer zuweisen muss . Ich möchte nur jeden
Hier gibt es mehr zu entpacken, als Sie vielleicht erwarten. Der CTE übernimmt die ganze Schwerarbeit, da er die gesamte 1,14-TB-Tabelle scannen und jeder Zeile eine Zeilennummer zuweisen muss . Ich möchte nur jeden (1048576*112)th zurückgeben Zeile, da dies meine Batch-Grenzzeilen sind, also ist dies das, was WHERE ist Klausel tut. Denken Sie daran, dass ich die Arbeit in Stapel mit jeweils näher an 100 Millionen Zeilen aufteilen möchte, aber ich möchte auch nicht wirklich 469 Millionen Zeilen auf einmal verarbeiten. Zusätzlich zur Aufteilung der Daten in 8 Partitionen möchte ich also jede dieser Partitionen in vier Stapel von 117.440.512 (1,048,576*112) aufteilen Reihen. Jeder benachbarte Satz von vier Stapeln gehört zu einer Partition, also der PartitionID Ich leite einfach eins zum Ergebnis der aktuellen Zeilennummer Integer hinzu geteilt durch (1,048,576*448) , wodurch sichergestellt wird, dass sich die Grenze immer im "linken" Satz befindet. Dann fügen wir eins zum Ergebnis hinzu, weil wir uns sonst auf eine 0-basierte Sammlung von Partitionen beziehen würden, und das will niemand.
Ok, das waren viele Worte. Rechts ist ein Bild, das den (abgekürzten) Inhalt der stage zeigt Tabelle (klicken Sie hier, um das vollständige Ergebnis anzuzeigen und die Partitionsgrenzwerte hervorzuheben).
Wir können dann eine weitere Abfrage aus dieser Staging-Tabelle ableiten, die uns die Mindest- und Höchstwerte für jeden Stapel innerhalb jeder Partition sowie den nicht berücksichtigten zusätzlichen Stapel anzeigt (die Zeilen in der ursprünglichen Tabelle mit OID größer als der höchste Grenzwert):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Diese Werte sehen folgendermaßen aus:
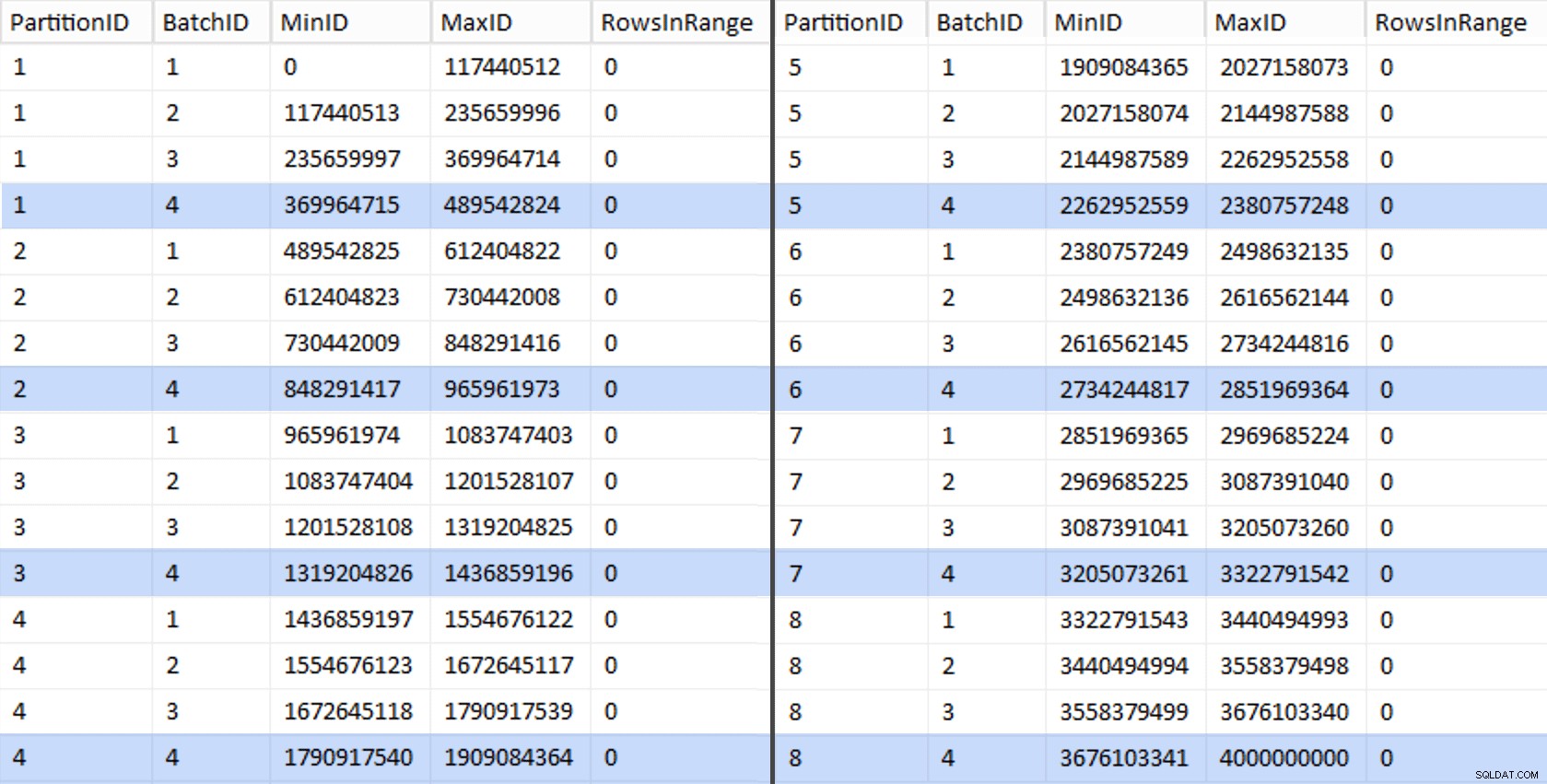
Um unsere Arbeit zu testen, können wir daraus eine Reihe von Abfragen ableiten, die BatchQueue mit tatsächlichen Zeilenzahlen aus der Tabelle.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Dies dauerte etwa 6 Minuten auf meinem System. Dann können Sie die folgende Abfrage ausführen, um zu zeigen, dass jeder Stapel außer dem allerletzten in der Lage ist, Zeilengruppen vollständig zu füllen und keinen Rest für eine potenzielle Deltaspeichernutzung zu hinterlassen:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Jetzt sieht die Tabelle so aus:
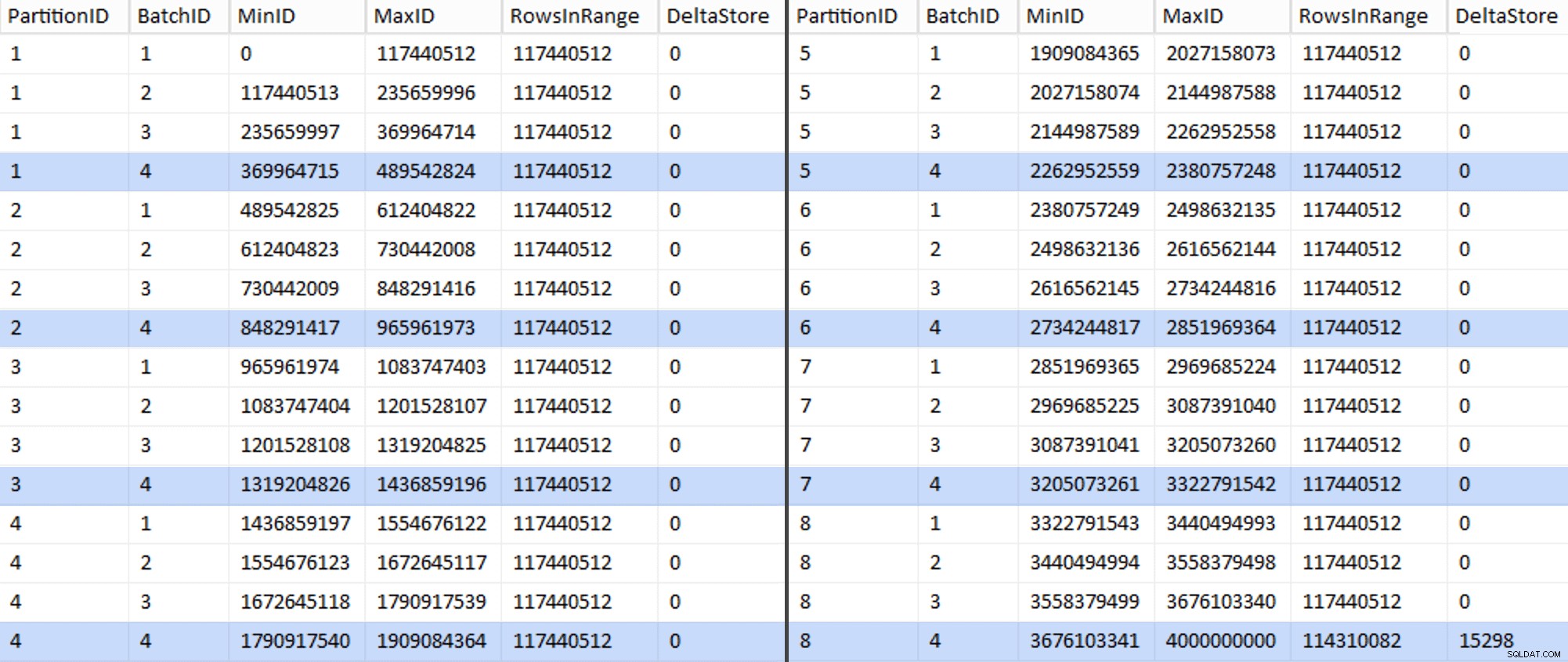
Sicher genug, jeder Stapel hat die berechneten 117.440.512 Millionen Zeilen, mit Ausnahme des letzten, der zumindest idealerweise unseren einzigen unkomprimierten Deltaspeicher enthalten wird. Wir können dies wahrscheinlich auch verhindern, indem wir die Stapelgröße nur geringfügig für diese Partition ändern so dass alle vier Chargen mit der gleichen Größe laufen, oder indem die Anzahl der Chargen geändert wird, um ein anderes Vielfaches von 102.400 oder 1.048.576 aufzunehmen. Da dies erfordern würde, eine neue OID zu erhalten Werte aus der Basistabelle, was unseren Migrationsaufwand um weitere 25 Minuten und mehr verlängert, werde ich diese eine unvollkommene Partition schleifen lassen – zumal wir sowieso nicht den vollen Vorteil der Archivkomprimierung daraus ziehen.
Die BatchQueue -Tabelle zeigt Anzeichen dafür, dass sie für die Verarbeitung unserer Batches nützlich ist, um Daten in unsere neue, partitionierte, gruppierte Columnstore-Tabelle zu migrieren. Was wir schaffen müssen, jetzt wo wir die Grenzen kennen. Es gibt nur 7 Grenzen, also könntest du das sicherlich manuell machen, aber ich lasse gerne dynamisches SQL meine Arbeit für mich erledigen:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Ergebnisse:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Sobald das erstellt ist, können wir unser Partitionsschema erstellen und jede nachfolgende Partition ihrer dedizierten Datei zuweisen:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Jetzt können wir die Tabelle erstellen und für die Migration vorbereiten:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
In Teil 3 werde ich die BatchQueue weiter konfigurieren Tabelle, erstellen Sie eine Prozedur für Prozesse, um die Daten in die neue Struktur zu verschieben, und analysieren Sie die Ergebnisse.
[ Teil 1 | Teil 2 | Teil 3 ]