[ Teil 1 | Teil 2 | Teil 3 ]
In Teil 1 dieser Serie habe ich einige Möglichkeiten ausprobiert, eine 1-TB-Tabelle zu komprimieren. Während ich bei meinem ersten Versuch anständige Ergebnisse erzielte, wollte ich sehen, ob ich die Leistung in Teil 2 verbessern könnte. Dort skizzierte ich einige der Dinge, die meiner Meinung nach Leistungsprobleme sein könnten, und legte dar, wie ich die Zieltabelle besser partitionieren könnte für optimale Columnstore-Komprimierung. Ich habe bereits:
- partitionierte die Tabelle in 8 Partitionen (eine pro Kern);
- Speichern Sie die Datendatei jeder Partition in einer eigenen Dateigruppe; und,
- Archivkomprimierung auf allen außer der "aktiven" Partition einstellen.
Ich muss es noch so machen, dass jeder Scheduler ausschließlich auf seine eigene Partition schreibt.
Zuerst muss ich Änderungen an der von mir erstellten Stapeltabelle vornehmen. Ich brauche eine Spalte, um die Anzahl der Zeilen zu speichern, die pro Stapel hinzugefügt werden (eine Art Selbstüberprüfung der Plausibilitätsprüfung), und Start-/Endzeiten, um den Fortschritt zu messen.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Als Nächstes muss ich eine Tabelle erstellen, um Affinität bereitzustellen – wir wollen nie, dass mehr als ein Prozess auf einem Scheduler läuft, selbst wenn das bedeutet, dass wir etwas Zeit verlieren, um die Logik erneut zu versuchen. Wir brauchen also eine Tabelle, die jede Sitzung auf einem bestimmten Planer verfolgt und ein Stapeln verhindert:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Die Idee ist, dass ich acht Instanzen einer Anwendung (SQLQueryStress) haben würde, die jeweils auf einem dedizierten Planer ausgeführt würden und nur die Daten verarbeiten, die für eine bestimmte Partition / Dateigruppe / Datendatei bestimmt sind, ~ 100 Millionen Zeilen gleichzeitig (zum Vergrößern klicken). :
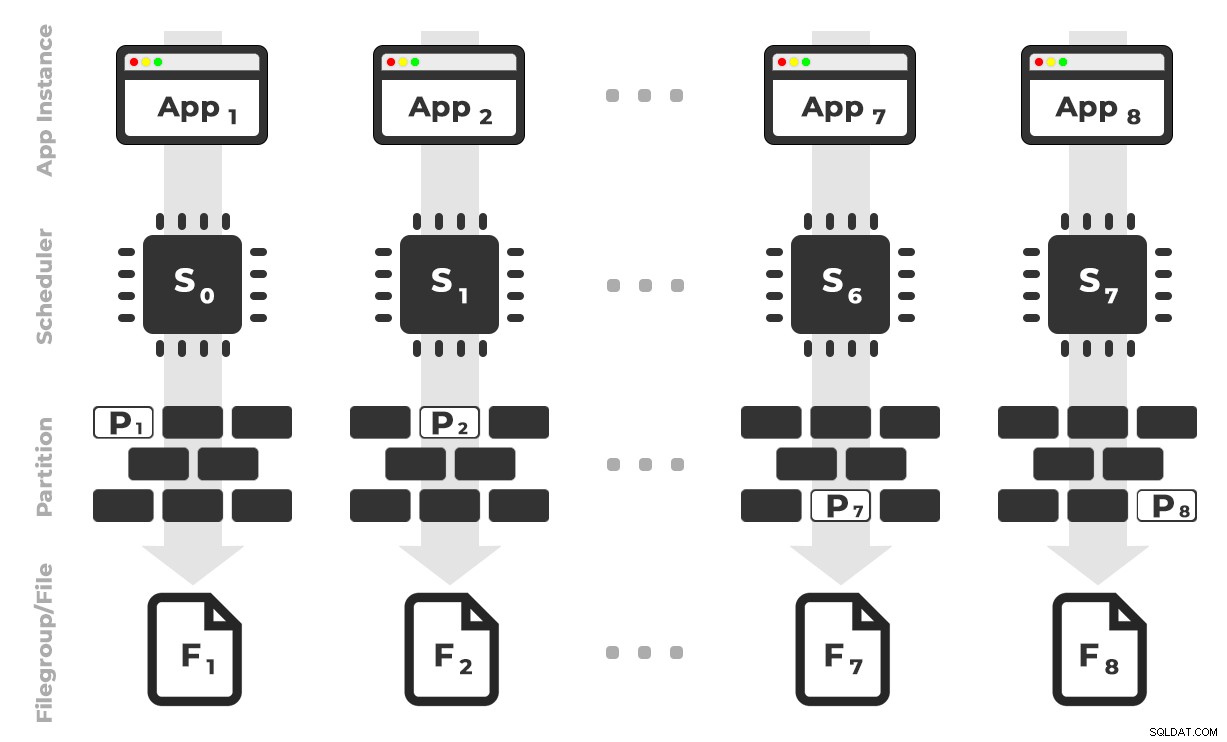 App 1 ruft Planer 0 ab und schreibt in Partition 1 in Dateigruppe 1 und so weiter …
App 1 ruft Planer 0 ab und schreibt in Partition 1 in Dateigruppe 1 und so weiter …
Als Nächstes benötigen wir eine gespeicherte Prozedur, die es jeder Instanz der Anwendung ermöglicht, Zeit für einen einzelnen Planer zu reservieren. Wie ich in einem früheren Beitrag erwähnt habe, ist dies nicht meine ursprüngliche Idee (und ich hätte sie in diesem Leitfaden nie gefunden, wenn es nicht Joe Obbish gegeben hätte). Hier ist die Prozedur, die ich in Utility erstellt habe :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Einfach, oder? Starten Sie 8 Instanzen von SQLQueryStress und fügen Sie diesen Batch in jede ein:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
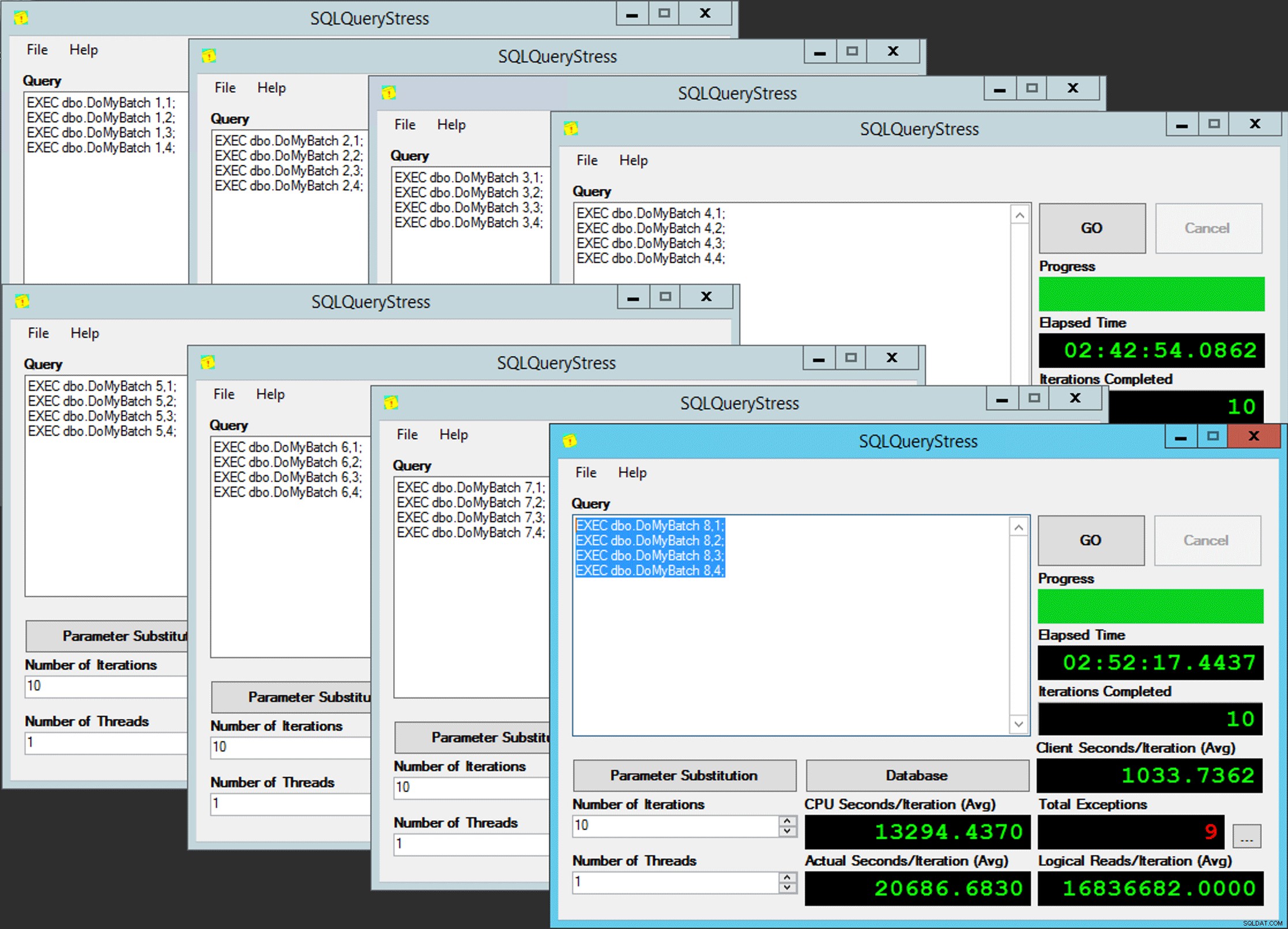 Parallelität des armen Mannes
Parallelität des armen Mannes
Nur ist es nicht so einfach, da die Scheduler-Zuweisung wie eine Schachtel Pralinen ist. Es hat viele Versuche gedauert, jede Instanz der App in den erwarteten Planer zu bekommen; Ich würde die Ausnahmen auf jeder gegebenen Instanz der App untersuchen und die PartitionID ändern passen. Aus diesem Grund habe ich mehr als eine Iteration verwendet (aber ich wollte immer noch nur einen Thread pro Instanz). Beispielsweise erwartete diese Instanz der App, dass sie sich auf Scheduler 3 befindet, aber sie erhielt Scheduler 4:
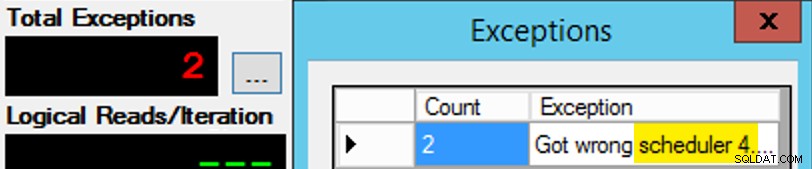 Wenn es Ihnen zunächst nicht gelingt…
Wenn es Ihnen zunächst nicht gelingt…
Ich habe die 3s im Abfragefenster in 4s geändert und es erneut versucht. Wenn ich schnell war, war die Scheduler-Zuweisung so "klebrig", dass sie sofort aufgegriffen und weggetuckert wurde. Aber ich war nicht immer schnell genug, also war es wie ein Schlag auf den Maulwurf, um loszulegen. Ich hätte wahrscheinlich eine bessere Wiederholungs-/Schleifenroutine entwickeln können, um die Arbeit hier weniger manuell zu machen, und die Verzögerung verkürzt, sodass ich sofort wusste, ob es funktioniert oder nicht, aber das war gut genug für meine Bedürfnisse. Es führte auch zu einer unbeabsichtigten Staffelung der Startzeiten für jeden Prozess, ein weiterer Ratschlag von Mr. Obbish.
Überwachung
Während die affinisierte Kopie ausgeführt wird, kann ich mit den folgenden zwei Abfragen einen Hinweis auf den aktuellen Status erhalten:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Wenn ich alles richtig gemacht hätte, würden beide Abfragen 8 Zeilen zurückgeben und inkrementierende logische Lesevorgänge und Dauer anzeigen. Wartetypen wechseln zwischen PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , und gelegentlich RESERVED_MEMORY_ALLOCATION_EXT. Wenn ein Stapel fertig war (ich könnte diese überprüfen, indem ich -- AND EndTime IS NULL auskommentiere , würde ich bestätigen, dass RowsAdded = RowsInRange .
Nachdem alle 8 Instanzen von SQLQueryStress abgeschlossen waren, konnte ich einfach ein SELECT INTO <newtable> FROM dbo.BatchQueue ausführen um die endgültigen Ergebnisse für eine spätere Analyse zu protokollieren.
Andere Tests
Zusätzlich zum Kopieren der Daten in den bereits vorhandenen partitionierten gruppierten Columnstore-Index unter Verwendung von Affinität wollte ich noch ein paar andere Dinge ausprobieren:
- Kopieren der Daten in die neue Tabelle, ohne zu versuchen, die Affinität zu kontrollieren. Ich habe die Affinitätslogik aus dem Verfahren herausgenommen und die ganze "Hoffe-du-bekommst-den-richtigen-Scheduler"-Sache einfach dem Zufall überlassen. Das hat länger gedauert, weil das Planer-Stacking tatsächlich es tat geschehen. Zum Beispiel führte Planer 3 an diesem bestimmten Punkt zwei Prozesse aus, während Planer 0 eine Mittagspause machte:
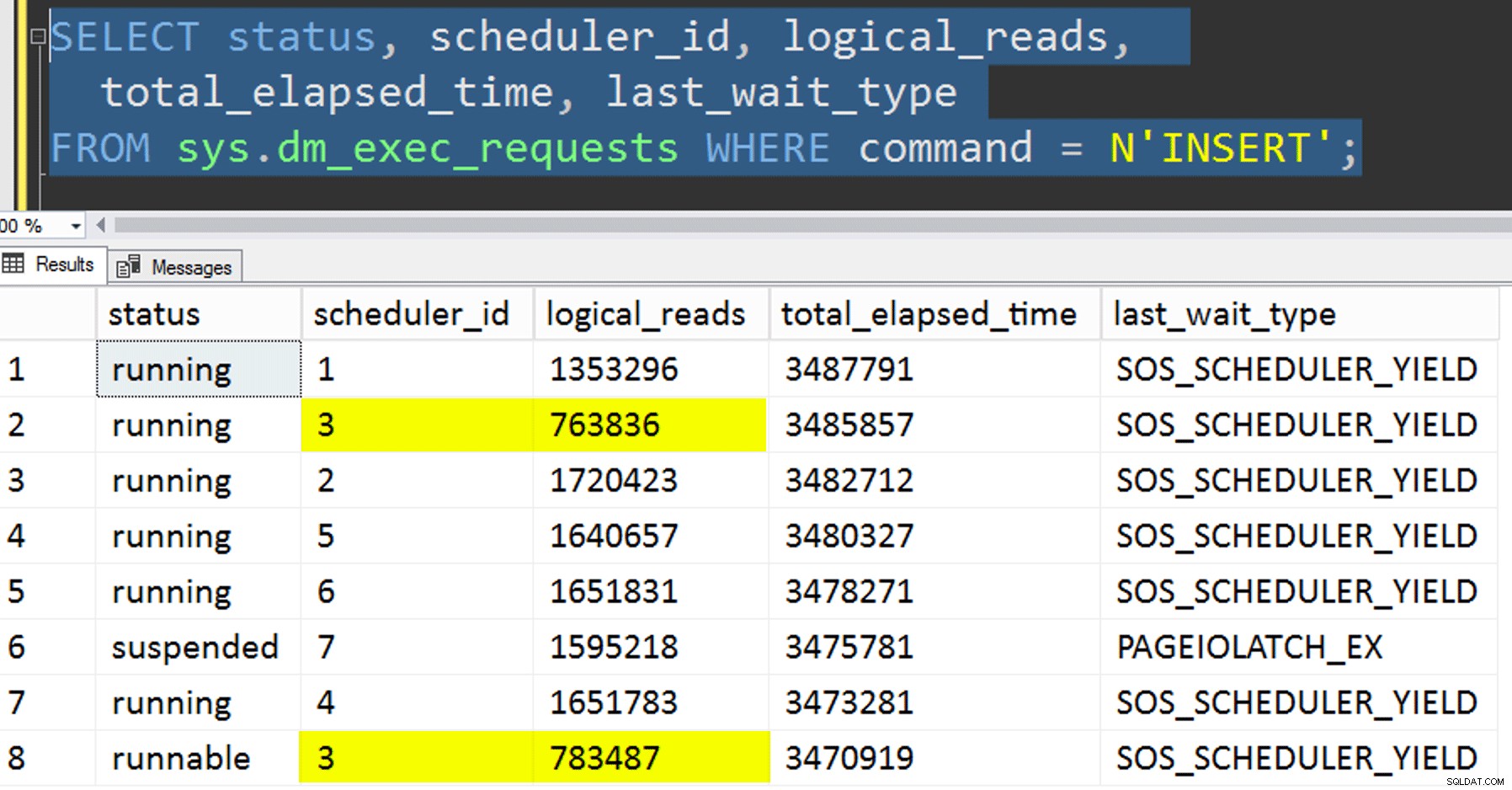 Wo bist du, Planer Nummer 0?
Wo bist du, Planer Nummer 0? - Bewerben Seite oder Zeile Komprimierung (sowohl online/offline) zur Quelle vorher die affinisierte Kopie (offline), um zu sehen, ob das Komprimieren der Daten zuerst das Ziel beschleunigen könnte. Beachten Sie, dass die Kopie auch online erstellt werden könnte, aber wie Andy Mallons
intzubigintUmbau, es erfordert etwas Gymnastik. Beachten Sie, dass wir in diesem Fall die CPU-Affinität nicht nutzen können (obwohl wir dies könnten, wenn die Quelltabelle bereits partitioniert wäre). Ich war schlau und habe eine Sicherungskopie der ursprünglichen Quelle erstellt und eine Prozedur erstellt, um die Datenbank in ihren ursprünglichen Zustand zurückzusetzen. Viel schneller und einfacher als der Versuch, manuell zu einem bestimmten Zustand zurückzukehren.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- Und schließlich, zuerst den gruppierten Index auf dem Partitionsschema neu erstellen und dann den gruppierten Columnstore-Index darauf aufbauen. Der Nachteil von letzterem ist, dass Sie dies in SQL Server 2017 nicht online ausführen können … aber Sie werden es in 2019 können.
Hier müssen wir zuerst die PK-Einschränkung löschen; Sie können
Msg 1907, Level 16, State 1DROP_EXISTINGnicht verwenden , da die ursprüngliche eindeutige Einschränkung nicht durch den gruppierten Columnstore-Index erzwungen werden kann und Sie einen eindeutigen gruppierten Index nicht durch einen nicht eindeutigen gruppierten Index ersetzen können.
Index 'pk_tblOriginal' kann nicht neu erstellt werden. Die neue Indexdefinition stimmt nicht mit der Einschränkung überein, die vom vorhandenen Index erzwungen wird.All diese Details machen dies zu einem dreistufigen Prozess, nur der zweite Schritt ist online. Im ersten Schritt habe ich nur explizit
OFFLINEgetestet; das lief in drei minuten, dabeiONLINEIch habe nach 15 Minuten aufgehört. Eines dieser Dinge, die vielleicht in keinem Fall eine Operation mit der Größe der Daten sein sollten, aber ich werde das für einen anderen Tag aufheben.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Ergebnisse
Timings und Komprimierungsraten:
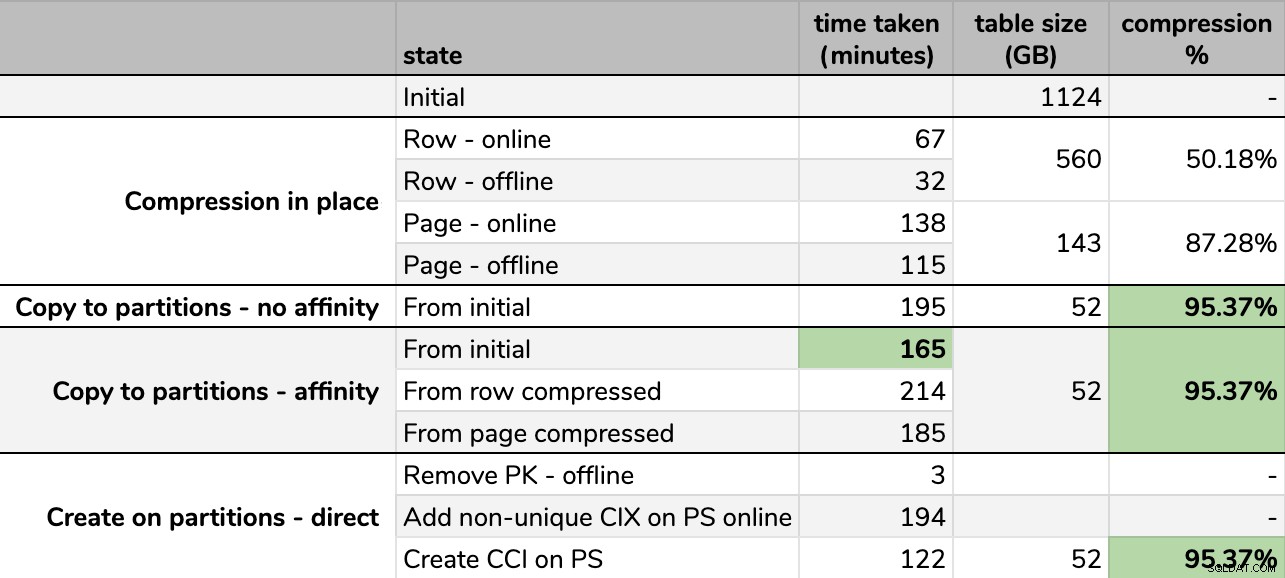 Einige Optionen sind besser als andere
Einige Optionen sind besser als andere
Beachten Sie, dass ich auf GB gerundet habe, da es nach jedem Lauf geringfügige Unterschiede in der endgültigen Größe geben würde, selbst wenn dieselbe Technik verwendet wird. Auch die Zeiten für die Affinitätsmethoden basierten auf dem Durchschnitt individuelle Scheduler/Batch-Laufzeit, da einige Scheduler schneller fertig sind als andere.
Es ist schwer, sich ein genaues Bild aus der Tabelle wie gezeigt vorzustellen, da einige Aufgaben Abhängigkeiten haben, also werde ich versuchen, die Informationen als Zeitleiste anzuzeigen und zu zeigen, wie viel Komprimierung Sie im Vergleich zur aufgewendeten Zeit erhalten:
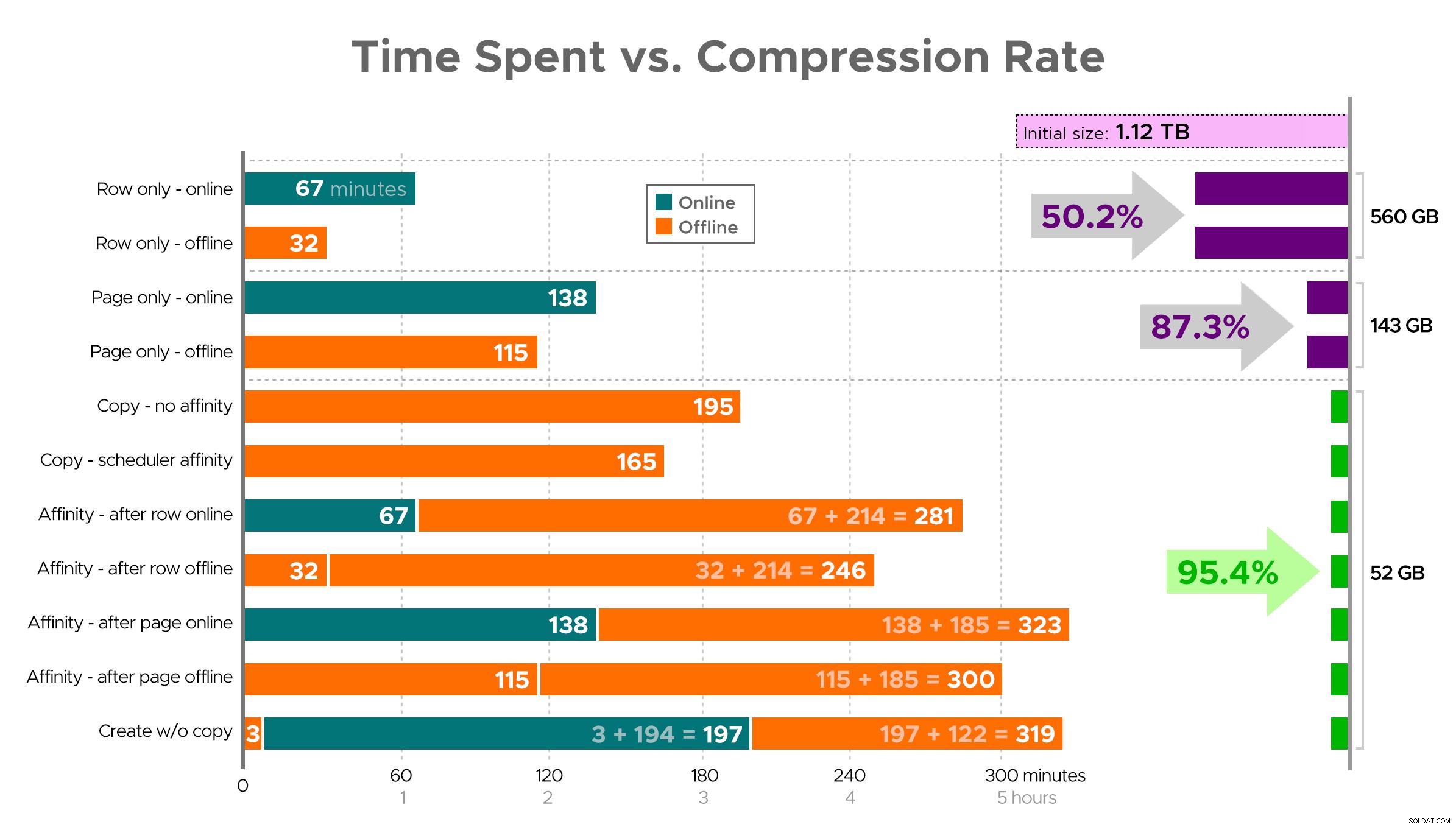 Aufgewendete Zeit (Minuten) im Vergleich zur Komprimierungsrate
Aufgewendete Zeit (Minuten) im Vergleich zur Komprimierungsrate
Einige Beobachtungen aus den Ergebnissen, mit dem Vorbehalt, dass Ihre Daten möglicherweise anders komprimiert werden (und dass Online-Vorgänge nur für Sie gelten, wenn Sie die Enterprise Edition verwenden):
- Wenn es Ihre Priorität ist, so schnell wie möglich Speicherplatz zu sparen , ist es am besten, die Zeilenkomprimierung an Ort und Stelle anzuwenden. Wenn Sie Unterbrechungen minimieren möchten, verwenden Sie online; wenn Sie die Geschwindigkeit optimieren möchten, verwenden Sie offline.
- Wenn Sie die Komprimierung ohne Unterbrechung maximieren möchten , können Sie sich einer Speicherreduzierung von 90 % ohne jegliche Unterbrechung nähern, indem Sie die Seitenkomprimierung online verwenden.
- Wenn Sie Komprimierung und Unterbrechung maximieren möchten, ist das in Ordnung , kopieren Sie die Daten in eine neue, partitionierte Version der Tabelle mit einem gruppierten Columnstore-Index und verwenden Sie den oben beschriebenen Affinitätsprozess, um die Daten zu migrieren. (Und noch einmal, Sie können diese Unterbrechung beseitigen, wenn Sie ein besserer Planer sind als ich.)
Die letzte Option hat für mein Szenario am besten funktioniert, obwohl wir bei den Arbeitslasten (ja, Plural) immer noch die Reifen treten müssen. Beachten Sie auch, dass diese Technik in SQL Server 2019 möglicherweise nicht so gut funktioniert, Sie dort jedoch gruppierte Columnstore-Indizes online erstellen können, sodass dies möglicherweise nicht so wichtig ist.
Einige dieser Ansätze können für Sie mehr oder weniger akzeptabel sein, da Sie möglicherweise „verfügbar bleiben“ gegenüber „so schnell wie möglich fertigstellen“ oder „Festplattennutzung minimieren“ gegenüber „verfügbar bleiben“ bevorzugen oder einfach nur die Leseleistung und den Schreibaufwand ausgleichen .
Wenn Sie weitere Einzelheiten zu einem Aspekt wünschen, fragen Sie einfach. Ich habe einen Teil des Fetts gekürzt, um Details mit der Verdaulichkeit in Einklang zu bringen, und ich habe mich in Bezug auf dieses Gleichgewicht schon früher geirrt. Ein Abschiedsgedanke ist, dass ich neugierig bin, wie linear das ist – wir haben eine andere Tabelle mit einer ähnlichen Struktur, die über 25 TB groß ist, und ich bin gespannt, ob wir dort eine ähnliche Wirkung erzielen können. Bis dahin viel Spaß beim Komprimieren!
[ Teil 1 | Teil 2 | Teil 3 ]