Dieser Artikel ist der dritte Teil einer Serie über NULL-Komplexitäten. In Teil 1 habe ich die Bedeutung des NULL-Markers behandelt und wie er sich in Vergleichen verhält. In Teil 2 habe ich die Inkonsistenzen der NULL-Behandlung in verschiedenen Sprachelementen beschrieben. Diesen Monat beschreibe ich leistungsstarke Standard-NULL-Handhabungsfunktionen, die es noch nicht bis zu T-SQL schaffen, und die Problemumgehungen, die derzeit verwendet werden.
Ich werde in einigen meiner Beispiele weiterhin die Beispieldatenbank TSQLV5 wie im letzten Monat verwenden. Das Skript, das diese Datenbank erstellt und füllt, finden Sie hier und ihr ER-Diagramm hier.
DISTINCT-Prädikat
In Teil 1 der Serie habe ich erklärt, wie sich NULL-Werte bei Vergleichen verhalten, und die Komplexität der dreiwertigen Prädikatenlogik, die SQL und T-SQL verwenden. Betrachten Sie das folgende Prädikat:
X =YWenn ein Prädikat NULL ist – auch wenn beide NULL sind – ist das Ergebnis dieses Prädikats der logische Wert UNKNOWN. Mit Ausnahme der Operatoren IS NULL und IS NOT NULL gilt dasselbe für alle anderen Operatoren, einschließlich anders als (<>):
X<>YIn der Praxis möchten Sie häufig, dass sich NULL-Werte zu Vergleichszwecken wie Nicht-NULL-Werte verhalten. Das ist besonders dann der Fall, wenn Sie sie verwenden, um fehlend, aber nicht anwendbar darzustellen Werte. Der Standard hat eine Lösung für diesen Bedarf in Form eines Merkmals namens DISTINCT-Prädikat, das die folgende Form verwendet:
Anstatt Gleichheits- oder Ungleichheitssemantik zu verwenden, verwendet dieses Prädikat beim Vergleich von Prädikaden eine auf Unterscheidbarkeit basierende Semantik. Als Alternative zu einem Gleichheitsoperator (=) würden Sie die folgende Form verwenden, um ein TRUE zu erhalten, wenn die beiden Prädikaden gleich sind, einschließlich, wenn beide NULL sind, und ein FALSE, wenn sie es nicht sind, einschließlich, wenn einer NULL ist und der andere nicht:
X UNTERSCHEIDET SICH NICHT VON YAls Alternative zu einem anders als Operator (<>) verwenden, würden Sie die folgende Form verwenden, um ein TRUE zu erhalten, wenn die beiden Prädikaden unterschiedlich sind, einschließlich, wenn einer NULL ist und der andere nicht, und ein FALSE, wenn sie gleich sind, einschließlich, wenn beide NULL sind:
X UNTERSCHEIDET SICH VON YWenden wir das Prädikat DISTINCT auf die Beispiele an, die wir in Teil 1 der Serie verwendet haben. Denken Sie daran, dass Sie eine Abfrage schreiben mussten, die bei einem Eingabeparameter @dt Bestellungen zurückgibt, die am Eingabedatum versendet wurden, wenn es nicht NULL ist, oder die überhaupt nicht versendet wurden, wenn die Eingabe NULL ist. Gemäß dem Standard würden Sie den folgenden Code mit dem Prädikat DISTINCT verwenden, um diese Anforderung zu erfüllen:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Erinnern Sie sich zunächst an Teil 1, dass Sie eine Kombination aus dem EXISTS-Prädikat und dem INTERSECT-Operator als SARGable-Workaround in T-SQL verwenden können, etwa so:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Um Bestellungen zurückzugeben, die an einem anderen Datum als dem Eingabedatum @dt versandt wurden, würden Sie die folgende Abfrage verwenden:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
Die Problemumgehung, die in T-SQL funktioniert, verwendet eine Kombination aus dem EXISTS-Prädikat und dem EXCEPT-Operator, etwa so:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
In Teil 1 habe ich auch Szenarien besprochen, in denen Sie Tabellen verknüpfen und unterscheidbarkeitsbasierte Semantik im Join-Prädikat anwenden müssen. In meinen Beispielen habe ich Tabellen namens T1 und T2 verwendet, mit NULLable Join-Spalten namens k1, k2 und k3 auf beiden Seiten. Gemäß dem Standard würden Sie den folgenden Code verwenden, um einen solchen Join zu handhaben:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Im Moment können Sie, ähnlich wie bei den vorherigen Filteraufgaben, eine Kombination aus dem EXISTS-Prädikat und dem INTERSECT-Operator in der ON-Klausel des Joins verwenden, um das Distinct-Prädikat wie folgt in T-SQL zu emulieren:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Wenn es in einem Filter verwendet wird, ist dieses Formular SARG-fähig, und wenn es in Joins verwendet wird, kann sich dieses Formular potenziell auf die Indexreihenfolge stützen.
Wenn Sie möchten, dass das Prädikat DISTINCT zu T-SQL hinzugefügt wird, können Sie hier dafür stimmen.
Wenn Sie sich nach der Lektüre dieses Abschnitts immer noch ein wenig unbehaglich wegen des Prädikats DISTINCT fühlen, sind Sie nicht allein. Vielleicht ist dieses Prädikat viel besser als jede bestehende Problemumgehung, die wir derzeit in T-SQL haben, aber es ist ein bisschen ausführlich und ein bisschen verwirrend. Es verwendet eine negative Form, um einen in unseren Augen positiven Vergleich anzuwenden, und umgekehrt. Nun, niemand hat gesagt, dass alle Standardvorschläge perfekt sind. Wie Charlie in einem seiner Kommentare zu Teil 1 bemerkte, würde die folgende vereinfachte Form besser funktionieren:
Es ist prägnanter und viel intuitiver. Anstelle von X UNTERSCHEIDET SICH NICHT VON Y, würden Sie Folgendes verwenden:
X IST YUnd anstelle von X IST UNTERSCHIEDLICH VON Y, würden Sie verwenden:
X IST NICHT YDieser vorgeschlagene Operator ist tatsächlich an den bereits vorhandenen IS NULL- und IS NOT NULL-Operatoren ausgerichtet.
Angewendet auf unsere Abfrageaufgabe würden Sie den folgenden Code verwenden, um Bestellungen zurückzugeben, die am Eingabedatum versandt wurden (oder die nicht versandt wurden, wenn die Eingabe NULL ist):
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
Um Bestellungen zurückzugeben, die an einem anderen Datum als dem Eingabedatum versandt wurden, würden Sie den folgenden Code verwenden:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Sollte sich Microsoft jemals entscheiden, das Distinct-Prädikat hinzuzufügen, wäre es gut, wenn sie sowohl die standardmäßige ausführliche Form als auch diese nicht standardmäßige, aber prägnantere und intuitivere Form unterstützen würden. Seltsamerweise unterstützt der Abfrageprozessor von SQL Server bereits einen internen Vergleichsoperator IS, der dieselbe Semantik verwendet wie der gewünschte IS-Operator, den ich hier beschrieben habe. Details zu diesem Operator finden Sie in Paul Whites Artikel Undocumented Query Plans:Equality Comparisons (Lookup „IS statt EQ“). Was fehlt, ist die externe Offenlegung als Teil von T-SQL.
NULL-Behandlungsklausel (IGNORE NULLS | RESPECT NULLS)
Wenn Sie die Offset-Fensterfunktionen LAG, LEAD, FIRST_VALUE und LAST_VALUE verwenden, müssen Sie manchmal das NULL-Behandlungsverhalten steuern. Standardmäßig geben diese Funktionen das Ergebnis des angeforderten Ausdrucks an der angeforderten Position zurück, unabhängig davon, ob das Ergebnis des Ausdrucks ein tatsächlicher Wert oder NULL ist. Manchmal möchten Sie sich jedoch weiter in die relevante Richtung bewegen (rückwärts für LAG und LAST_VALUE, vorwärts für LEAD und FIRST_VALUE) und den ersten Nicht-NULL-Wert zurückgeben, falls vorhanden, und andernfalls NULL. Der Standard gibt Ihnen die Kontrolle über dieses Verhalten mit einer NULL-Behandlungsklausel mit der folgenden Syntax:
offset_function(Der Standardwert für den Fall, dass die NULL-Behandlungsklausel nicht angegeben ist, ist die Option RESPECT NULLS, was bedeutet, dass alles zurückgegeben wird, was an der angeforderten Position vorhanden ist, selbst wenn NULL. Leider ist diese Klausel noch nicht in T-SQL verfügbar. Ich werde Beispiele für die Standardsyntax mit den Funktionen LAG und FIRST_VALUE sowie Problemumgehungen bereitstellen, die in T-SQL funktionieren. Sie können ähnliche Techniken verwenden, wenn Sie eine solche Funktionalität mit LEAD und LAST_VALUE benötigen.
Als Beispieldaten verwende ich eine Tabelle namens T4, die Sie mit dem folgenden Code erstellen und füllen:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Es gibt eine häufige Aufgabe, bei der es darum geht, das letzte relevante zurückzugeben Wert. Ein NULL-Wert in col1 zeigt keine Änderung des Werts an, während ein Nicht-NULL-Wert einen neuen relevanten Wert anzeigt. Sie müssen den letzten Nicht-NULL-col1-Wert basierend auf der ID-Reihenfolge zurückgeben. Unter Verwendung der standardmäßigen NULL-Behandlungsklausel würden Sie die Aufgabe wie folgt behandeln:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Hier ist die erwartete Ausgabe dieser Abfrage:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Es gibt eine Problemumgehung in T-SQL, aber sie umfasst zwei Schichten von Fensterfunktionen und einen Tabellenausdruck.
Im ersten Schritt verwenden Sie die MAX-Fensterfunktion, um eine Spalte namens grp zu berechnen, die den bisherigen maximalen ID-Wert enthält, wenn col1 nicht NULL ist, etwa so:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Dieser Code generiert die folgende Ausgabe:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Wie Sie sehen können, wird immer dann ein eindeutiger grp-Wert erstellt, wenn sich der Wert von col1 ändert.
Im zweiten Schritt definieren Sie einen CTE basierend auf der Abfrage aus dem ersten Schritt. Dann geben Sie in der äußeren Abfrage den bisher maximalen col1-Wert innerhalb jeder von grp definierten Partition zurück. Das ist der letzte col1-Wert, der nicht NULL ist. Hier ist der vollständige Lösungscode:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Das ist natürlich viel mehr Code und Arbeit als einfach IGNORE_NULLS zu sagen.
Eine weitere häufige Anforderung besteht darin, den ersten relevanten Wert zurückzugeben. Nehmen Sie in unserem Fall an, dass Sie den bisher ersten col1-Wert, der nicht NULL ist, basierend auf der ID-Reihenfolge zurückgeben müssen. Unter Verwendung der standardmäßigen NULL-Behandlungsklausel würden Sie die Aufgabe mit der Funktion FIRST_VALUE und der Option IGNORE NULLS wie folgt behandeln:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Hier ist die erwartete Ausgabe dieser Abfrage:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
Die Problemumgehung in T-SQL verwendet eine ähnliche Technik wie die für den letzten Nicht-NULL-Wert, nur verwenden Sie anstelle eines Double-MAX-Ansatzes die FIRST_VALUE-Funktion über einer MIN-Funktion.
Im ersten Schritt verwenden Sie die MIN-Fensterfunktion, um eine Spalte namens grp zu berechnen, die den bisher minimalen ID-Wert enthält, wenn col1 nicht NULL ist, etwa so:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Dieser Code generiert die folgende Ausgabe:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Wenn vor dem ersten relevanten Wert NULLen vorhanden sind, erhalten Sie zwei Gruppen – die erste mit NULL als Grp-Wert und die zweite mit der ersten Nicht-NULL-ID als Grp-Wert.
Im zweiten Schritt platzieren Sie den Code des ersten Schritts in einem Tabellenausdruck. Dann verwenden Sie in der äußeren Abfrage die FIRST_VALUE-Funktion, partitioniert nach Grp, um den ersten relevanten (Nicht-NULL-) Wert zu sammeln, falls vorhanden, und NULL andernfalls, wie folgt:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Auch das ist eine Menge Code und Arbeit im Vergleich zur einfachen Verwendung der Option IGNORE_NULLS.
Wenn Sie der Meinung sind, dass diese Funktion für Sie nützlich sein kann, können Sie hier für ihre Aufnahme in T-SQL stimmen.
ZUERST NACH NULLEN ORDERN | NULLEN ZULETZT
Wenn Sie Daten bestellen, sei es für Präsentationszwecke, Windowing, TOP/OFFSET-FETCH-Filterung oder andere Zwecke, stellt sich die Frage, wie sich NULLen in diesem Zusammenhang verhalten sollen? Der SQL-Standard sagt, dass NULLen entweder vor oder nach Nicht-NULLs zusammensortiert werden sollten, und sie überlassen es der Implementierung, die eine oder andere Weise zu bestimmen. Was auch immer der Anbieter wählt, es muss konsistent sein. In T-SQL werden NULLen zuerst (vor Nicht-NULLen) geordnet, wenn die aufsteigende Reihenfolge verwendet wird. Betrachten Sie die folgende Abfrage als Beispiel:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Diese Abfrage generiert die folgende Ausgabe:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
Die Ausgabe zeigt, dass nicht versandte Bestellungen, die ein NULL-Versanddatum haben, vor versandten Bestellungen bestellt werden, die ein vorhandenes gültiges Versanddatum haben.
Aber was ist, wenn Sie NULLs benötigen, um bei der Verwendung von aufsteigender Reihenfolge zuletzt zu ordnen? Der ISO/IEC-SQL-Standard unterstützt eine Klausel, die Sie auf einen Sortierausdruck anwenden können, um zu steuern, ob NULL-Werte zuerst oder zuletzt sortiert werden. Die Syntax dieser Klausel lautet:
Um unseren Bedarf zu decken und die Bestellungen nach Versanddatum sortiert zurückzugeben, aufsteigend, aber mit zuletzt zurückgesendeten nicht versendeten Bestellungen, und dann als Tiebreaker nach ihren Bestell-IDs, würden Sie den folgenden Code verwenden:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Leider ist diese NULLS-Orderklausel in T-SQL nicht verfügbar.
Eine gängige Problemumgehung, die in T-SQL verwendet wird, besteht darin, dem Sortierausdruck einen CASE-Ausdruck voranzustellen, der eine Konstante mit einem niedrigeren Sortierwert für Nicht-NULL-Werte als für NULL-Werte zurückgibt, etwa so (wir nennen diese Lösung Abfrage 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Diese Abfrage generiert die gewünschte Ausgabe, wobei NULLen zuletzt angezeigt werden:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
In der Tabelle „Sales.Orders“ ist ein abdeckender Index definiert, mit der Spalte „shippeddate“ als Schlüssel. Ähnlich wie eine manipulierte Filterspalte die SARG-Fähigkeit des Filters und die Möglichkeit, einen Index zu suchen, verhindert, verhindert eine manipulierte Sortierspalte jedoch die Möglichkeit, sich auf die Indexsortierung zu verlassen, um die ORDER BY-Klausel der Abfrage zu unterstützen. Daher generiert SQL Server einen Plan für Abfrage 1 mit einem expliziten Sort-Operator, wie in Abbildung 1 gezeigt.
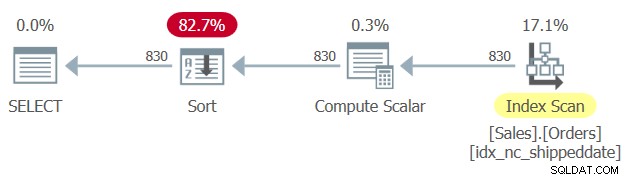 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Manchmal ist die Größe der Daten nicht so groß, dass die explizite Sortierung ein Problem darstellt. Aber manchmal ist es so. Mit der expliziten Sortierung wird die Skalierbarkeit der Abfrage extralinear (Sie zahlen mehr pro Zeile, je mehr Zeilen Sie haben), und die Antwortzeit (Zeit, die die erste Zeile benötigt, um zurückgegeben zu werden) verzögert sich.
Es gibt einen Trick, den Sie verwenden können, um in einem solchen Fall eine explizite Sortierung mit einer Lösung zu vermeiden, die mit einem reihenfolgeerhaltenden Merge Join Concatenation-Operator optimiert wird. Eine ausführliche Beschreibung dieser Technik, die in verschiedenen Szenarien verwendet wird, finden Sie in SQL Server:Vermeiden einer Sortierung mit Merge-Join-Verkettung. Der erste Schritt in der Lösung vereint die Ergebnisse von zwei Abfragen:eine Abfrage, die die Zeilen zurückgibt, in denen die Sortierspalte nicht NULL ist, mit einer Ergebnisspalte (wir nennen sie sortcol), die auf einer Konstante mit einem Sortierwert basiert, sagen wir 0, und eine andere Abfrage, die die Zeilen mit den NULLen zurückgibt, wobei sortcol auf eine Konstante mit einem höheren Ordnungswert als in der ersten Abfrage gesetzt ist, sagen wir 1. Im zweiten Schritt definieren Sie dann einen Tabellenausdruck basierend auf dem Code aus dem ersten Schritt, und dann In der äußeren Abfrage ordnen Sie die Zeilen aus dem Tabellenausdruck zuerst nach sortcol und dann nach den verbleibenden Sortierelementen. Hier ist der Code der vollständigen Lösung, der diese Technik implementiert (wir nennen diese Lösung Abfrage 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
Der Plan für diese Abfrage ist in Abbildung 2 dargestellt.
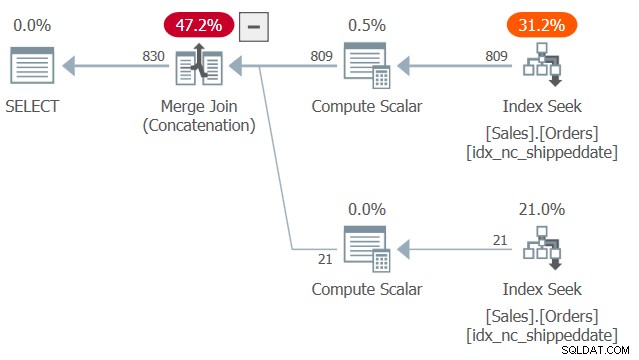 Abbildung 2:Plan für Abfrage 2
Abbildung 2:Plan für Abfrage 2
Beachten Sie zwei Suchvorgänge und geordnete Bereichsscans im abdeckenden Index idx_nc_shippeddate – einer ruft die Zeilen ab, in denen „shippeddateis“ nicht NULL ist, und ein anderer zieht Zeilen, in denen „shippeddate“ NULL ist. Dann vereinheitlicht der Merge Join (Concatenation)-Algorithmus, ähnlich wie der Merge Join-Algorithmus in einem Join, die Zeilen von den beiden geordneten Seiten auf eine reißverschlussartige Weise und behält die aufgenommene Reihenfolge bei, um die Anforderungen der Präsentationsreihenfolge der Abfrage zu unterstützen. Ich sage nicht, dass diese Technik immer schneller ist als die typischere Lösung mit dem CASE-Ausdruck, der eine explizite Sortierung verwendet. Ersteres hat jedoch eine lineare Skalierung und Letzteres hat eine n log n-Skalierung. Ersteres funktioniert also tendenziell besser mit einer großen Anzahl von Zeilen und letzteres mit einer kleinen Anzahl.
Natürlich ist es gut, eine Lösung für diesen häufigen Bedarf zu haben, aber es wird viel besser sein, wenn T-SQL in Zukunft Unterstützung für die standardmäßige NULL-Bestellklausel hinzufügt.
Schlussfolgerung
Der ISO/IEC-SQL-Standard hat ziemlich viele Funktionen zur NULL-Behandlung, die es noch nicht bis zu T-SQL schaffen müssen. In diesem Artikel habe ich einige davon behandelt:das DISTINCT-Prädikat, die NULL-Behandlungsklausel und die Steuerung, ob NULL-Werte an erster oder letzter Stelle angeordnet werden. Ich habe auch Problemumgehungen für diese Funktionen bereitgestellt, die in T-SQL unterstützt werden, aber sie sind offensichtlich umständlich. Nächsten Monat setze ich die Diskussion fort, indem ich die standardmäßige Eindeutigkeitsbeschränkung behandle, wie sie sich von der T-SQL-Implementierung unterscheidet und die Problemumgehungen, die in T-SQL implementiert werden können.