Gastautorin:Monica Rathbun (@SQLEspresso)
Manchmal lassen sich Probleme mit der Hardwareleistung, wie z. B. Festplatten-E/A-Latenz, eher auf nicht optimierte Arbeitslast als auf leistungsschwache Hardware zurückführen. Viele Datenbankadministratoren, mich eingeschlossen, wollen sofort den Speicher für die Langsamkeit verantwortlich machen. Bevor Sie viel Geld für neue Hardware ausgeben, sollten Sie Ihren Workload immer auf unnötige I/O untersuchen.
Untersuchbare Dinge
| Element | E/A-Auswirkung | Mögliche Lösungen |
|---|---|---|
| Unbenutzte Indizes | Zusätzliche Schreibvorgänge | Index entfernen / deaktivieren |
| Fehlende Indizes | Zusätzliche Lesevorgänge | Index hinzufügen / Indizes abdecken |
| Implizite Konvertierungen | Zusätzliche Lese- und Schreibvorgänge | Feld an der Quelle verdecken oder übertragen, bevor der Wert ausgewertet wird |
| Funktionen | Zusätzliche Lese- und Schreibvorgänge | Entfernt, konvertieren Sie die Daten vor der Auswertung |
| ETL | Zusätzliche Lese- und Schreibvorgänge | Verwenden Sie SSIS, Replikation, Änderungsdatenerfassung, Verfügbarkeitsgruppen |
| Sortieren &Gruppieren nach | Zusätzliche Lese- und Schreibvorgänge | Entfernen Sie sie nach Möglichkeit |
Nicht verwendete Indizes
Wir alle kennen die Macht eines Index. Die Verwendung der richtigen Indizes kann einen Unterschied in der Abfragegeschwindigkeit um Lichtjahre ausmachen. Doch wie viele von uns pflegen ihre Indizes kontinuierlich über den Indexneuaufbau und die Reorgs hinaus? Es ist wichtig, regelmäßig ein Indexskript auszuführen, um auszuwerten, welche Indizes tatsächlich verwendet werden. Ich persönlich verwende dafür die diagnostischen Abfragen von Glenn Berry.
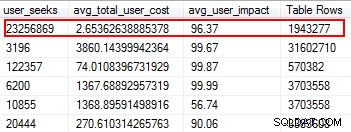
Sie werden überrascht sein, dass einige Ihrer Indizes überhaupt nicht gelesen wurden. Diese Indizes belasten die Ressourcen, insbesondere auf einer stark transaktionalen Tabelle. Achten Sie beim Betrachten der Ergebnisse auf die Indizes, die eine hohe Anzahl von Schreibvorgängen kombiniert mit einer geringen Anzahl von Lesevorgängen aufweisen. In diesem Beispiel können Sie sehen, dass ich Schreibvorgänge verschwende. Der nicht gruppierte Index wurde 11 Millionen Mal beschrieben, aber nur zweimal gelesen.

Ich beginne damit, die Indizes zu deaktivieren, die in diese Kategorie fallen, und lösche sie dann, nachdem ich bestätigt habe, dass keine Probleme aufgetreten sind. Wenn Sie diese Übung routinemäßig durchführen, können Sie unnötige E/A-Schreibvorgänge auf Ihrem System erheblich reduzieren, aber denken Sie daran, dass die Nutzungsstatistiken Ihrer Indizes nur so gut sind wie der letzte Neustart. Stellen Sie also sicher, dass Sie Daten für einen vollständigen Geschäftszyklus gesammelt haben, bevor Sie sie abschreiben ein Index als "nutzlos".
Fehlende Indizes
Fehlende Indizes sind eines der am einfachsten zu behebenden Probleme. Wenn Sie einen Ausführungsplan ausführen, wird er Ihnen schließlich mitteilen, ob Indizes nicht gefunden wurden, aber das wäre nützlich gewesen. Aber warten Sie, ich hoffe, Sie fügen basierend auf diesem Vorschlag nicht einfach willkürlich Indizes hinzu. Dadurch können doppelte Indizes und Indizes erstellt werden, die möglicherweise nur eine minimale Verwendung haben und daher E/A verschwenden. Zurück zu Glenns Skripten, er gibt uns ein großartiges Werkzeug, um die Nützlichkeit eines Index zu bewerten, indem er Benutzersuchen, Benutzerauswirkungen und die Anzahl der Zeilen bereitstellt. Achten Sie auf diejenigen mit hohen Reads und geringen Kosten und Auswirkungen. Dies ist ein guter Ausgangspunkt und hilft Ihnen, Lese-E/A zu reduzieren.
Implizite Konvertierungen
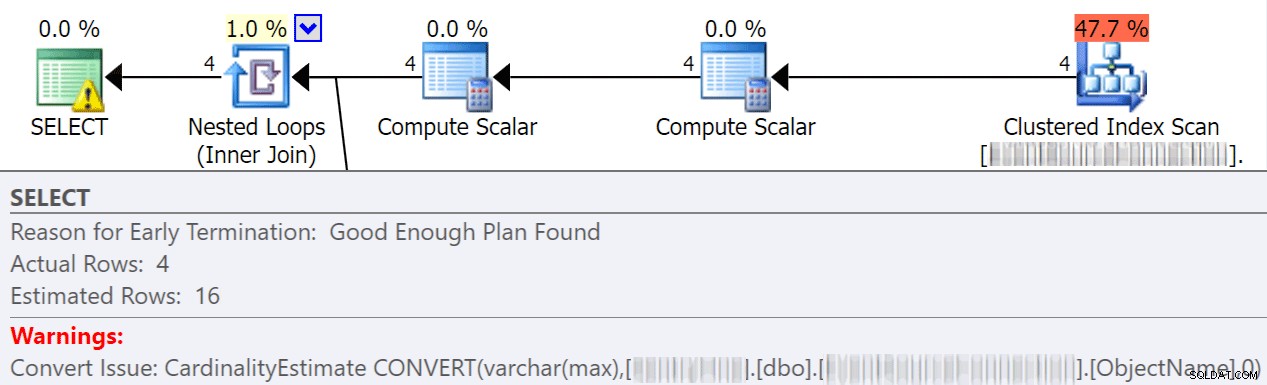
Implizite Konvertierungen finden häufig statt, wenn eine Abfrage zwei oder mehr Spalten mit unterschiedlichen Datentypen vergleicht. Im folgenden Beispiel muss das System zusätzliche E/A ausführen, um eine varchar(max)-Spalte mit einer nvarchar(4000)-Spalte zu vergleichen, was zu einer impliziten Konvertierung und letztendlich zu einem Scan anstelle einer Suche führt. Indem Sie die Tabellen so fixieren, dass sie übereinstimmende Datentypen haben, oder einfach diesen Wert vor der Auswertung konvertieren, können Sie die E/A erheblich reduzieren und die Kardinalität verbessern (die geschätzten Zeilen, die der Optimierer erwarten sollte).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias geht in diesem großartigen Beitrag noch viel detaillierter darauf ein:"Wie teuer sind spaltenseitige implizite Conversions?"
Funktionen
Eines der vermeidbarsten und am einfachsten zu behebenden Dinge, die mir begegnet sind und die I/O-Kosten sparen, ist das Entfernen von Funktionen aus where-Klauseln. Ein perfektes Beispiel ist ein Datumsvergleich, wie unten gezeigt.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Unabhängig davon, ob es sich um eine JOIN-Anweisung oder eine WHERE-Klausel handelt, wird jede Spalte konvertiert, bevor sie ausgewertet wird. Indem Sie diese Spalten vor der Auswertung einfach in eine temporäre Tabelle konvertieren, können Sie eine Menge unnötiger I/Os eliminieren.
Oder, noch besser, führen Sie überhaupt keine Konvertierungen durch (für diesen speziellen Fall spricht Aaron Bertrand hier über das Vermeiden von Funktionen in der where-Klausel, und beachten Sie, dass dies immer noch schlecht sein kann, obwohl convert to date sargable ist).
ETL
Nehmen Sie sich die Zeit, um zu prüfen, wie Ihre Daten geladen werden. Schneiden Sie Tabellen ab und laden Sie sie neu? Können Sie stattdessen die Replikation, ein schreibgeschütztes AG-Replikat oder den Protokollversand implementieren? Werden alle Tabellen, in die geschrieben wird, tatsächlich gelesen? Wie lädst du die Daten? Ist es durch gespeicherte Prozeduren oder SSIS? Die Untersuchung solcher Dinge kann die E/A drastisch reduzieren.
In meiner Umgebung habe ich festgestellt, dass wir jeden Morgen 48 Tabellen mit über 120 Millionen Zeilen abschneiden. Darüber hinaus haben wir stündlich 9,6 Millionen Zeilen geladen. Sie können sich vorstellen, wie viele unnötige E/A dadurch entstanden sind. In meinem Fall war die Implementierung der Transaktionsreplikation die Lösung meiner Wahl. Nach der Implementierung hatten wir weitaus weniger Benutzerbeschwerden über Verlangsamungen während unserer Ladezeiten, die ursprünglich auf die langsame Speicherung zurückgeführt wurden.
Ordnen nach &Gruppieren nach
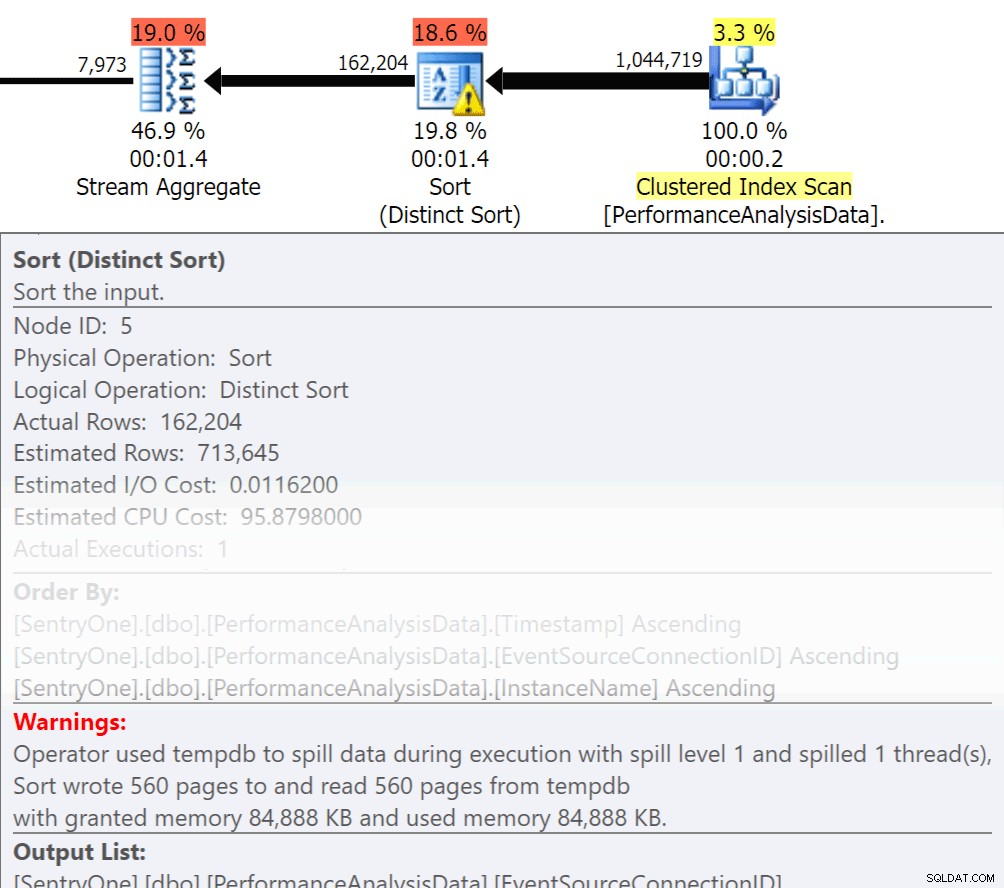 Fragen Sie sich, müssen diese Daten der Reihe nach zurückgegeben werden? Müssen wir wirklich im Verfahren gruppieren oder können wir das in einem Bericht oder Antrag erledigen? Order By- und Group By-Operationen können dazu führen, dass Lesevorgänge auf die Festplatte übertragen werden, was zusätzliche Festplatten-E/A verursacht. Wenn diese Aktionen gerechtfertigt sind, stellen Sie sicher, dass Sie über unterstützende Indizes und aktuelle Statistiken zu den zu sortierenden oder gruppierenden Spalten verfügen. Dies hilft dem Optimierer bei der Planerstellung. Da wir manchmal Order By und Group By in temporären Tabellen verwenden. Stellen Sie sicher, dass Sie Statistik automatisch erstellen für TEMPDB sowie Ihre Benutzerdatenbanken aktiviert haben. Je aktueller die Statistiken sind, desto bessere Kardinalitäten kann der Optimierer erreichen, was zu besseren Plänen, weniger Spillover und weniger I/O führt.
Fragen Sie sich, müssen diese Daten der Reihe nach zurückgegeben werden? Müssen wir wirklich im Verfahren gruppieren oder können wir das in einem Bericht oder Antrag erledigen? Order By- und Group By-Operationen können dazu führen, dass Lesevorgänge auf die Festplatte übertragen werden, was zusätzliche Festplatten-E/A verursacht. Wenn diese Aktionen gerechtfertigt sind, stellen Sie sicher, dass Sie über unterstützende Indizes und aktuelle Statistiken zu den zu sortierenden oder gruppierenden Spalten verfügen. Dies hilft dem Optimierer bei der Planerstellung. Da wir manchmal Order By und Group By in temporären Tabellen verwenden. Stellen Sie sicher, dass Sie Statistik automatisch erstellen für TEMPDB sowie Ihre Benutzerdatenbanken aktiviert haben. Je aktueller die Statistiken sind, desto bessere Kardinalitäten kann der Optimierer erreichen, was zu besseren Plänen, weniger Spillover und weniger I/O führt.
Jetzt hat Group By definitiv seinen Platz, wenn es darum geht, Daten zu aggregieren, anstatt eine Menge Zeilen zurückzugeben. Aber der Schlüssel hier ist, I/O zu reduzieren, das Hinzufügen der Aggregation fügt I/O hinzu.
Zusammenfassung
Dies ist nur die Spitze des Eisbergs, aber ein großartiger Ausgangspunkt, um I/O zu reduzieren. Bevor Sie Hardware für Ihre Latenzprobleme verantwortlich machen, sehen Sie sich an, was Sie tun können, um den Festplattendruck zu minimieren.
Über den Autor
 Monica Rathbun ist derzeit Beraterin bei Denny Cherry &Associates Consulting und Microsoft Data Platform MVP. Sie ist seit 15 Jahren Einzel-DBA und arbeitet mit allen Aspekten von SQL Server und Oracle. Sie ist auf Reisen und spricht bei SQLSaturdays, um anderen Lone DBAs mit Techniken zu helfen, wie man die Aufgaben vieler erledigen kann. Monica ist die Leiterin der Hampton Roads SQL Server User Group und eine regionale Mentorin für Mid-Atlantic Pass. Sie finden Monica immer auf Twitter (@SQLEspresso), wo sie hilfreiche Tipps und Tricks an ihre Follower weitergibt. Wenn sie nicht mit der Arbeit beschäftigt ist, spielt sie Taxifahrerin für ihre beiden Töchter hin und her zum Tanzunterricht.
Monica Rathbun ist derzeit Beraterin bei Denny Cherry &Associates Consulting und Microsoft Data Platform MVP. Sie ist seit 15 Jahren Einzel-DBA und arbeitet mit allen Aspekten von SQL Server und Oracle. Sie ist auf Reisen und spricht bei SQLSaturdays, um anderen Lone DBAs mit Techniken zu helfen, wie man die Aufgaben vieler erledigen kann. Monica ist die Leiterin der Hampton Roads SQL Server User Group und eine regionale Mentorin für Mid-Atlantic Pass. Sie finden Monica immer auf Twitter (@SQLEspresso), wo sie hilfreiche Tipps und Tricks an ihre Follower weitergibt. Wenn sie nicht mit der Arbeit beschäftigt ist, spielt sie Taxifahrerin für ihre beiden Töchter hin und her zum Tanzunterricht.