Dieser Artikel ist der siebte Teil einer Serie über benannte Tabellenausdrücke. In Teil 5 und Teil 6 habe ich die konzeptionellen Aspekte von Common Table Expressions (CTEs) behandelt. In diesem und im nächsten Monat liegt mein Fokus auf Überlegungen zur Optimierung von CTEs.
Ich beginne damit, das Konzept der Entschachtelung benannter Tabellenausdrücke schnell noch einmal zu betrachten und seine Anwendbarkeit auf CTEs zu demonstrieren. Ich werde mich dann auf Persistenzüberlegungen konzentrieren. Ich werde über Persistenzaspekte rekursiver und nichtrekursiver CTEs sprechen. Ich werde erklären, wann es sinnvoll ist, sich an CTEs zu halten und wann es tatsächlich sinnvoller ist, mit temporären Tabellen zu arbeiten.
In meinen Beispielen verwende ich weiterhin die Beispieldatenbanken TSQLV5 und PerformanceV5. Das Skript, das TSQLV5 erstellt und füllt, finden Sie hier und sein ER-Diagramm hier. Das Skript, das PerformanceV5 erstellt und füllt, finden Sie hier.
Ersetzung/Entschachtelung
In Teil 4 der Serie, der sich auf die Optimierung abgeleiteter Tabellen konzentrierte, habe ich einen Prozess der Entschachtelung/Ersetzung von Tabellenausdrücken beschrieben. Ich habe erklärt, dass SQL Server, wenn es eine Abfrage mit abgeleiteten Tabellen optimiert, Transformationsregeln auf den anfänglichen Baum logischer Operatoren anwendet, der vom Parser erzeugt wird, wodurch möglicherweise Dinge über die ursprünglichen Grenzen von Tabellenausdrücken hinweg verschoben werden. Dies geschieht so weit, dass beim Vergleich eines Plans für eine Abfrage mit abgeleiteten Tabellen mit einem Plan für eine Abfrage, die direkt mit den zugrunde liegenden Basistabellen übereinstimmt, auf die Sie selbst die Entschachtelungslogik angewendet haben, sie gleich aussehen. Ich habe auch eine Technik beschrieben, um das Aufheben der Verschachtelung mithilfe des TOP-Filters mit einer sehr großen Anzahl von Zeilen als Eingabe zu verhindern. Ich habe ein paar Fälle demonstriert, in denen diese Technik recht praktisch war – einen, bei dem das Ziel darin bestand, Fehler zu vermeiden, und einen anderen aus Optimierungsgründen.
Die TL;DR-Version des Ersetzens/Entschachtelns von CTEs ist, dass der Prozess derselbe ist wie bei abgeleiteten Tabellen. Wenn Sie mit dieser Aussage zufrieden sind, können Sie diesen Abschnitt gerne überspringen und direkt zum nächsten Abschnitt über Persistenz springen. Sie werden nichts Wichtiges verpassen, das Sie nicht schon einmal gelesen haben. Wenn Sie jedoch wie ich sind, möchten Sie wahrscheinlich einen Beweis dafür, dass dies tatsächlich der Fall ist. Dann möchten Sie wahrscheinlich diesen Abschnitt weiterlesen und den Code testen, den ich verwende, während ich wichtige Beispiele zum Aufheben der Verschachtelung, die ich zuvor mit abgeleiteten Tabellen demonstriert habe, noch einmal durchsuche und sie für die Verwendung von CTEs umwandle.
In Teil 4 habe ich die folgende Abfrage demonstriert (wir nennen sie Abfrage 1):
USE TSQLV5;
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Die Abfrage umfasst drei Verschachtelungsebenen abgeleiteter Tabellen sowie eine äußere Abfrage. Jede Ebene filtert einen anderen Bereich von Bestelldaten. Der Plan für Abfrage 1 ist in Abbildung 1 dargestellt.
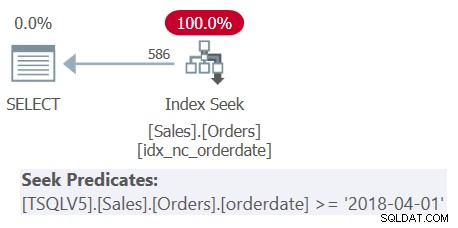 Abbildung 1:Ausführungsplan für Abfrage 1
Abbildung 1:Ausführungsplan für Abfrage 1
Der Plan in Abbildung 1 zeigt deutlich, dass die Entschachtelung der abgeleiteten Tabellen stattgefunden hat, da alle Filterprädikate zu einem einzigen umfassenden Filterprädikat zusammengeführt wurden.
Ich habe erklärt, dass Sie den Entschachtelungsprozess verhindern können, indem Sie einen sinnvollen TOP-Filter (im Gegensatz zu TOP 100 PERCENT) mit einer sehr großen Anzahl von Zeilen als Eingabe verwenden, wie die folgende Abfrage zeigt (wir nennen sie Abfrage 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Der Plan für Abfrage 2 ist in Abbildung 2 dargestellt.
 Abbildung 2:Ausführungsplan für Abfrage 2
Abbildung 2:Ausführungsplan für Abfrage 2
Der Plan zeigt deutlich, dass keine Entschachtelung stattgefunden hat, da Sie die abgeleiteten Tabellengrenzen effektiv sehen können.
Versuchen wir die gleichen Beispiele mit CTEs. Hier ist Abfrage 1, die zur Verwendung von CTEs konvertiert wurde:
WITH C1 AS
(
SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; Sie erhalten genau denselben Plan, der zuvor in Abbildung 1 gezeigt wurde, wo Sie sehen können, dass die Verschachtelung aufgehoben wurde.
Hier ist Abfrage 2, die zur Verwendung von CTEs konvertiert wurde:
WITH C1 AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT TOP (9223372036854775807) *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT TOP (9223372036854775807) *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; Sie erhalten denselben Plan wie zuvor in Abbildung 2 gezeigt, wo Sie sehen können, dass keine Entschachtelung stattgefunden hat.
Sehen wir uns als Nächstes die beiden Beispiele an, die ich verwendet habe, um die praktische Anwendbarkeit der Technik zur Verhinderung des Aufhebens der Verschachtelung zu demonstrieren – nur dieses Mal mit CTEs.
Beginnen wir mit der fehlerhaften Abfrage. Die folgende Abfrage versucht, Bestellpositionen mit einem Rabatt zurückzugeben, der größer als der Mindestrabatt ist und bei dem der Kehrwert des Rabatts größer als 10 ist:
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Der Mindestrabatt kann nicht negativ sein, sondern ist entweder null oder höher. Sie denken also wahrscheinlich, dass, wenn eine Zeile einen Rabatt von null hat, das erste Prädikat als falsch ausgewertet werden sollte und dass ein Kurzschluss den Versuch verhindern sollte, das zweite Prädikat auszuwerten, wodurch ein Fehler vermieden wird. Wenn Sie diesen Code ausführen, erhalten Sie jedoch einen Division-durch-Null-Fehler:
Msg 8134, Level 16, State 1, Line 99 Divide by zero error encountered.
Das Problem ist, dass, obwohl SQL Server ein Kurzschlusskonzept auf der physischen Verarbeitungsebene unterstützt, es keine Gewissheit gibt, dass es die Filterprädikate in schriftlicher Reihenfolge von links nach rechts auswertet. Ein gängiger Versuch, solche Fehler zu vermeiden, besteht darin, einen benannten Tabellenausdruck zu verwenden, der den Teil der Filterlogik verarbeitet, der zuerst ausgewertet werden soll, und die äußere Abfrage die Filterlogik verarbeiten zu lassen, die als zweites ausgewertet werden soll. Hier ist der Lösungsversuch mit einem CTE:
WITH C AS
(
SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; Leider führt das Aufheben der Verschachtelung des Tabellenausdrucks zu einem logischen Äquivalent zur ursprünglichen Lösungsabfrage, und wenn Sie versuchen, diesen Code auszuführen, erhalten Sie erneut einen Division-durch-Null-Fehler:
Msg 8134, Level 16, State 1, Line 108 Divide by zero error encountered.
Mit unserem Trick mit dem TOP-Filter in der inneren Abfrage verhindern Sie das Entschachteln des Tabellenausdrucks, etwa so:
WITH C AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; Diesmal läuft der Code erfolgreich ohne Fehler.
Fahren wir mit dem Beispiel fort, in dem Sie die Technik verwenden, um das Aufheben der Verschachtelung aus Optimierungsgründen zu verhindern. Der folgende Code gibt nur Versender zurück, deren maximales Bestelldatum am oder nach dem 1. Januar 2018 liegt:
USE PerformanceV5;
WITH C AS
(
SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; Wenn Sie sich fragen, warum Sie nicht eine viel einfachere Lösung mit einer gruppierten Abfrage und einem HAVING-Filter verwenden sollten, hat dies mit der Dichte der shipperid-Spalte zu tun. Die Orders-Tabelle enthält 1.000.000 Bestellungen, und die Sendungen dieser Bestellungen wurden von fünf Versendern abgewickelt, was bedeutet, dass jeder Versender im Durchschnitt 20 % der Bestellungen abgewickelt hat. Der Plan für eine gruppierte Abfrage, die das maximale Bestelldatum pro Versender berechnet, würde alle 1.000.000 Zeilen scannen, was zu Tausenden von Seitenlesevorgängen führen würde. Wenn Sie nur die innere Abfrage des CTE hervorheben (wir nennen sie Abfrage 3), die das maximale Bestelldatum pro Versender berechnet, und ihren Ausführungsplan überprüfen, erhalten Sie den in Abbildung 3 gezeigten Plan.
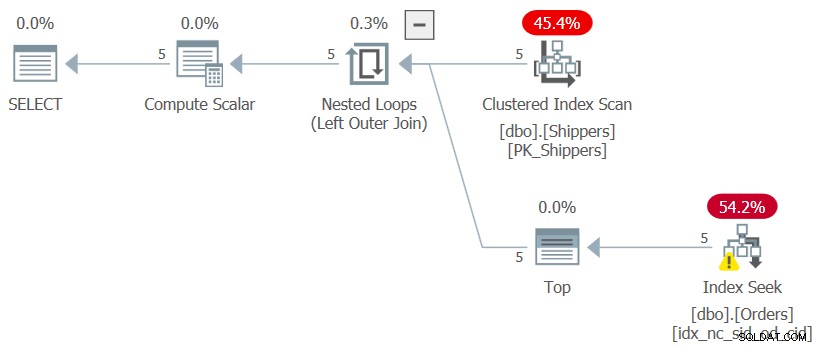 Abbildung 3:Ausführungsplan für Abfrage 3
Abbildung 3:Ausführungsplan für Abfrage 3
Der Plan scannt fünf Zeilen im gruppierten Index für Versender. Pro Versender wendet der Plan eine Suche auf einen abdeckenden Index für Bestellungen an, wobei (shipperid, orderdate) die indexführenden Schlüssel sind, und geht direkt zur letzten Zeile in jedem Versenderabschnitt auf Blattebene, um das maximale Bestelldatum für den aktuellen abzurufen Absender. Da wir nur fünf Versender haben, gibt es nur fünf Indexsuchoperationen, was zu einem sehr effizienten Plan führt. Hier sind die Leistungsmessungen, die ich erhalten habe, als ich die innere Abfrage des CTE ausgeführt habe:
duration: 0 ms, CPU: 0 ms, reads: 15
Wenn Sie jedoch die vollständige Lösung ausführen (wir nennen sie Abfrage 4), erhalten Sie einen völlig anderen Plan, wie in Abbildung 4 gezeigt.
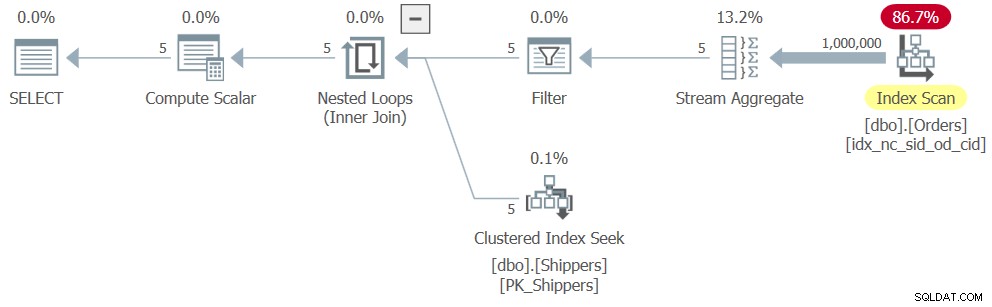 Abbildung 4:Ausführungsplan für Abfrage 4
Abbildung 4:Ausführungsplan für Abfrage 4
Was geschah, war, dass SQL Server den Tabellenausdruck entschachtelte und die Lösung in ein logisches Äquivalent einer gruppierten Abfrage konvertierte, was zu einem vollständigen Scan des Indexes für Bestellungen führte. Hier sind die Leistungszahlen, die ich für diese Lösung erhalten habe:
duration: 316 ms, CPU: 281 ms, reads: 3854
Was wir hier brauchen, ist, zu verhindern, dass die Verschachtelung des Tabellenausdrucks stattfindet, sodass die innere Abfrage mit Suchvorgängen gegen den Index für Bestellungen optimiert wird und die äußere Abfrage nur zu einer Hinzufügung eines Filteroperators in der führt planen. Sie erreichen dies mit unserem Trick, indem Sie der inneren Abfrage einen TOP-Filter hinzufügen, etwa so (wir nennen diese Lösung Abfrage 5):
WITH C AS
(
SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; Der Plan für diese Lösung ist in Abbildung 5 dargestellt.
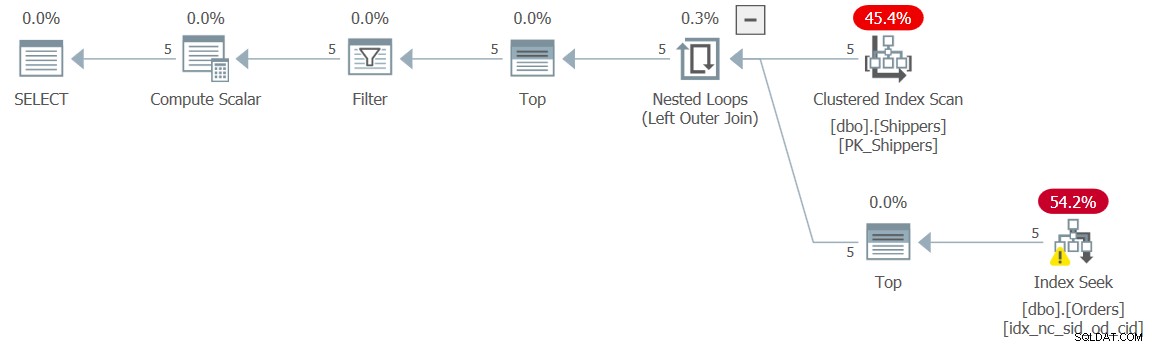 Abbildung 5:Ausführungsplan für Abfrage 5
Abbildung 5:Ausführungsplan für Abfrage 5
Der Plan zeigt, dass die gewünschte Wirkung erzielt wurde, und dementsprechend bestätigen die Leistungszahlen dies:
duration: 0 ms, CPU: 0 ms, reads: 15
Unsere Tests bestätigen also, dass SQL Server das Ersetzen/Entschachteln von CTEs genauso handhabt wie bei abgeleiteten Tabellen. Das bedeutet, dass Sie nicht aus Optimierungsgründen einen dem anderen vorziehen sollten, sondern aufgrund von konzeptionellen Unterschieden, die Ihnen wichtig sind, wie in Teil 5 erläutert.
Persistenz
Ein weit verbreitetes Missverständnis in Bezug auf CTEs und benannte Tabellenausdrücke im Allgemeinen ist, dass sie als eine Art Persistenzvehikel dienen. Einige denken, dass SQL Server die Ergebnismenge der inneren Abfrage in einer Arbeitstabelle speichert und dass die äußere Abfrage tatsächlich mit dieser Arbeitstabelle interagiert. In der Praxis werden reguläre nichtrekursive CTEs und abgeleitete Tabellen nicht beibehalten. Ich habe die Entschachtelungslogik beschrieben, die SQL Server beim Optimieren einer Abfrage mit Tabellenausdrücken anwendet, was zu einem Plan führt, der direkt mit den zugrunde liegenden Basistabellen interagiert. Beachten Sie, dass der Optimierer Arbeitstabellen verwenden kann, um Zwischenergebnissätze beizubehalten, wenn dies aus Leistungsgründen oder aus anderen Gründen sinnvoll ist, z. B. zum Schutz vor Halloween. Wenn dies der Fall ist, sehen Sie Spool- oder Index-Spool-Operatoren im Plan. Solche Auswahlmöglichkeiten haben jedoch nichts mit der Verwendung von Tabellenausdrücken in der Abfrage zu tun.
Rekursive CTEs
Es gibt ein paar Ausnahmen, in denen SQL Server die Daten des Tabellenausdrucks beibehält. Eine davon ist die Verwendung von indizierten Ansichten. Wenn Sie einen gruppierten Index für eine Ansicht erstellen, speichert SQL Server das Resultset der inneren Abfrage im gruppierten Index der Ansicht und hält es mit allen Änderungen in den zugrunde liegenden Basistabellen synchron. Die andere Ausnahme ist, wenn Sie rekursive Abfragen verwenden. SQL Server muss die Zwischenergebnismengen der Anker- und rekursiven Abfragen in einer Spule beibehalten, damit es bei jeder Ausführung des rekursiven Members auf die Ergebnismenge der letzten Runde zugreifen kann, die durch die rekursive Referenz auf den CTE-Namen dargestellt wird.
Um dies zu demonstrieren, verwende ich eine der rekursiven Abfragen aus Teil 6 der Serie.
Verwenden Sie den folgenden Code, um die Employees-Tabelle in der tempdb-Datenbank zu erstellen, sie mit Beispieldaten zu füllen und einen unterstützenden Index zu erstellen:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary);
GO Ich habe den folgenden rekursiven CTE verwendet, um alle Untergebenen eines Wurzelmanagers eines Eingabeunterbaums zurückzugeben, wobei in diesem Beispiel Mitarbeiter 3 als Eingabemanager verwendet wurde:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; Der Plan für diese Abfrage (wir nennen sie Abfrage 6) ist in Abbildung 6 dargestellt.
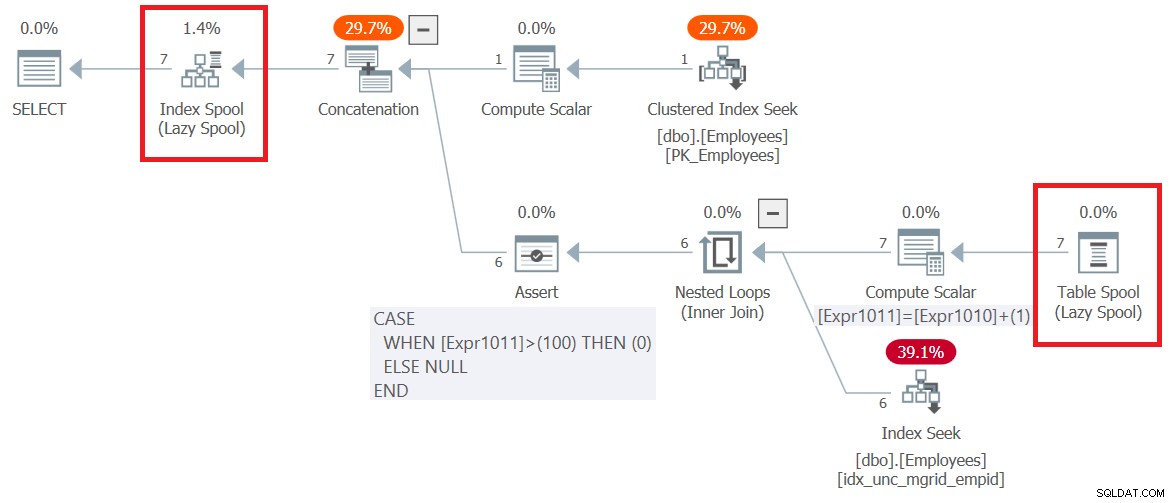 Abbildung 6:Ausführungsplan für Abfrage 6
Abbildung 6:Ausführungsplan für Abfrage 6
Beachten Sie, dass das Allererste, was im Plan passiert, rechts vom Root-SELECT-Knoten, die Erstellung einer B-Baum-basierten Arbeitstabelle ist, die durch den Index-Spool-Operator dargestellt wird. Der obere Teil des Plans behandelt die Logik des Ankermitglieds. Es zieht die Eingabemitarbeiterzeilen aus dem gruppierten Index für Mitarbeiter und schreibt sie in die Spule. Der untere Teil des Plans repräsentiert die Logik des rekursiven Members. Es wird wiederholt ausgeführt, bis es eine leere Ergebnismenge zurückgibt. Die äußere Eingabe für den Nested-Loops-Operator erhält die Manager aus der vorherigen Runde aus der Spule (Table Spool-Operator). Die innere Eingabe verwendet einen Index Seek-Operator für einen nicht gruppierten Index, der auf Employees (mgrid, empid) erstellt wurde, um die direkten Untergebenen der Manager aus der vorherigen Runde abzurufen. Die Ergebnismenge jeder Ausführung des unteren Teils des Plans wird ebenfalls in die Indexspule geschrieben. Beachten Sie, dass insgesamt 7 Zeilen in die Spule geschrieben wurden. Einer wird vom Anker-Member zurückgegeben und 6 weitere werden von allen Ausführungen des rekursiven Members zurückgegeben.
Abgesehen davon ist es interessant festzustellen, wie der Plan mit dem standardmäßigen maxrecursion-Limit von 100 umgeht. Beachten Sie, dass der untere Compute Scalar-Operator einen internen Zähler mit dem Namen „Expr1011“ bei jeder Ausführung des rekursiven Members um 1 erhöht. Dann setzt der Assert-Operator ein Flag auf Null, wenn dieser Zähler 100 überschreitet. Wenn dies geschieht, stoppt SQL Server die Ausführung der Abfrage und generiert einen Fehler.
Wann nicht bestehen bleiben
Zurück zu nichtrekursiven CTEs, die normalerweise nicht persistiert werden, müssen Sie aus Optimierungssicht herausfinden, wann es besser ist, sie im Vergleich zu tatsächlichen Persistenztools wie temporären Tabellen und Tabellenvariablen zu verwenden. Ich werde ein paar Beispiele durchgehen, um zu zeigen, wann welcher Ansatz optimaler ist.
Beginnen wir mit einem Beispiel, bei dem CTEs besser abschneiden als temporäre Tabellen. Das ist oft der Fall, wenn Sie nicht mehrere Auswertungen desselben CTE haben, sondern vielleicht nur eine modulare Lösung, bei der jeder CTE nur einmal ausgewertet wird. Der folgende Code (wir nennen ihn Abfrage 7) fragt die Orders-Tabelle in der Performance-Datenbank ab, die 1.000.000 Zeilen enthält, um Bestelljahre zurückzugeben, in denen mehr als 70 verschiedene Kunden Bestellungen aufgegeben haben:
USE PerformanceV5;
WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM dbo.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70; Diese Abfrage generiert die folgende Ausgabe:
orderyear numcusts ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000
Ich habe diesen Code mit SQL Server 2019 Developer Edition ausgeführt und den in Abbildung 7 gezeigten Plan erhalten.
 Abbildung 7:Ausführungsplan für Abfrage 7
Abbildung 7:Ausführungsplan für Abfrage 7
Beachten Sie, dass das Aufheben der Verschachtelung des CTE zu einem Plan führte, der die Daten aus einem Index in der Orders-Tabelle abruft und kein Spooling des inneren Abfrageergebnissatzes des CTE beinhaltet. Beim Ausführen dieser Abfrage auf meinem Computer habe ich die folgenden Leistungszahlen erhalten:
duration: 265 ms, CPU: 828 ms, reads: 3970, writes: 0
Lassen Sie uns nun eine Lösung ausprobieren, die temporäre Tabellen anstelle von CTEs verwendet (wir nennen sie Lösung 8), etwa so:
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT orderyear, COUNT(DISTINCT custid) AS numcusts INTO #T2 FROM #T1 GROUP BY orderyear; SELECT orderyear, numcusts FROM #T2 WHERE numcusts > 70; DROP TABLE #T1, #T2;
Die Pläne für diese Lösung sind in Abbildung 8 dargestellt.
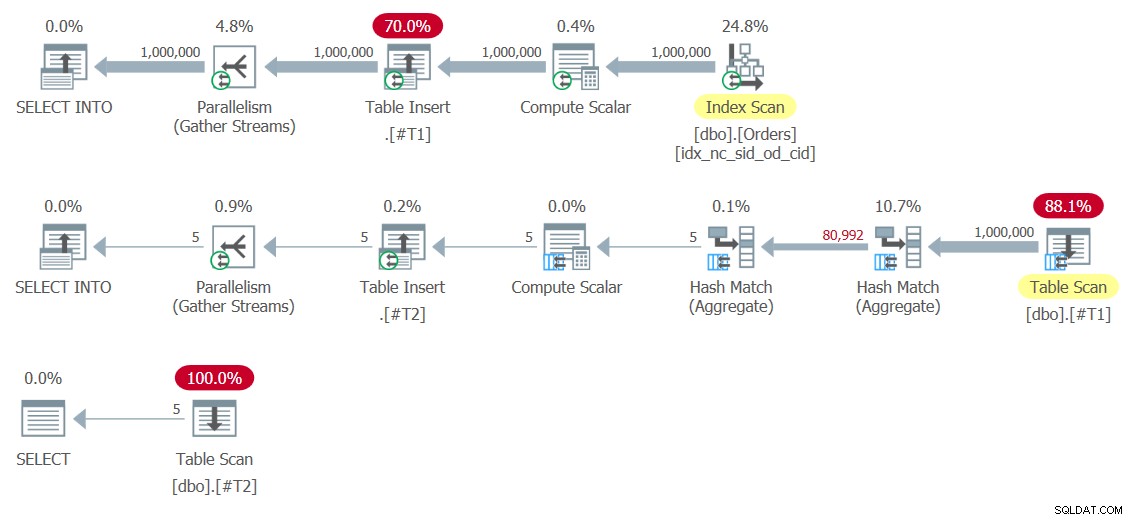 Abbildung 8:Pläne für Lösung 8
Abbildung 8:Pläne für Lösung 8
Beachten Sie, dass die Operatoren zum Einfügen von Tabellen die Ergebnismengen in die temporären Tabellen #T1 und #T2 schreiben. Der erste ist besonders teuer, da er 1.000.000 Zeilen in #T1 schreibt. Hier sind die Leistungszahlen, die ich für diese Hinrichtung erhalten habe:
duration: 454 ms, CPU: 1517 ms, reads: 14359, writes: 359
Wie Sie sehen, ist die Lösung mit den CTEs viel optimaler.
Wann bestehen bleiben
Ist also eine modulare Lösung mit nur einer Auswertung jedes CTE immer einer temporären Tabelle vorzuziehen? Nicht unbedingt. Bei CTE-basierten Lösungen, die viele Schritte umfassen und zu ausgefeilten Plänen führen, bei denen der Optimierer viele Kardinalitätsschätzungen an vielen verschiedenen Punkten im Plan anwenden muss, könnten Sie mit akkumulierten Ungenauigkeiten enden, die zu suboptimalen Entscheidungen führen. Eine der Techniken, um zu versuchen, solche Fälle anzugehen, besteht darin, einige Zwischenergebnissätze selbst in temporären Tabellen zu speichern und bei Bedarf sogar Indizes dafür zu erstellen, was dem Optimierer einen Neuanfang mit neuen Statistiken ermöglicht und die Wahrscheinlichkeit für Kardinalitätsschätzungen von besserer Qualität erhöht hoffentlich zu optimaleren Entscheidungen führen. Ob dies besser ist als eine Lösung, die keine temporären Tabellen verwendet, müssen Sie testen. Manchmal lohnt es sich, zusätzliche Kosten für die Beibehaltung von Zwischenergebnissen zugunsten besserer Kardinalitätsschätzungen in Kauf zu nehmen.
Ein weiterer typischer Fall, in dem die Verwendung temporärer Tabellen der bevorzugte Ansatz ist, ist, wenn die CTE-basierte Lösung mehrere Auswertungen desselben CTE hat und die innere Abfrage des CTE ziemlich teuer ist. Betrachten Sie die folgende CTE-basierte Lösung (wir nennen sie Abfrage 9), die jedem Bestelljahr und -monat ein anderes Bestelljahr und einen anderen Bestellmonat mit der engsten Bestellanzahl zuordnet:
WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate)
)
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2; Diese Abfrage generiert die folgende Ausgabe:
orderyear ordermonth numorders orderyear2 ordermonth2 numorders2 ----------- ----------- ----------- ----------- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2016 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rows affected)
Der Plan für Abfrage 9 ist in Abbildung 9 dargestellt.
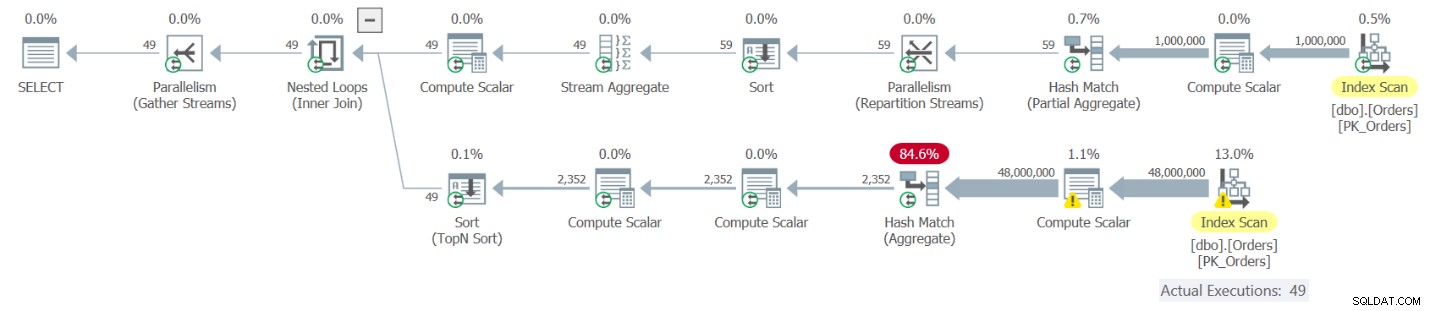 Abbildung 9:Ausführungsplan für Abfrage 9
Abbildung 9:Ausführungsplan für Abfrage 9
Der obere Teil des Plans entspricht der Instanz des OrdCount-CTE mit dem Alias O1. Diese Referenz führt zu einer Auswertung des CTE OrdCount. Dieser Teil des Plans ruft die Zeilen aus einem Index der Orders-Tabelle ab, gruppiert sie nach Jahr und Monat und aggregiert die Anzahl der Bestellungen pro Gruppe, was zu 49 Zeilen führt. Der untere Teil des Plans entspricht der korrelierten abgeleiteten Tabelle O2, die pro Zeile von O1 angewendet wird, also 49 Mal ausgeführt wird. Jede Ausführung fragt den OrdCount CTE ab und führt daher zu einer separaten Auswertung der inneren Abfrage des CTE. Sie können sehen, dass der untere Teil des Plans alle Zeilen aus dem Index auf Bestellungen durchsucht, gruppiert und aggregiert. Sie erhalten im Grunde insgesamt 50 Auswertungen des CTE, was dazu führt, dass die 1.000.000 Zeilen von Bestellungen 50 Mal gescannt, gruppiert und aggregiert werden. Das klingt nicht nach einer sehr effizienten Lösung. Hier sind die Leistungsmessungen, die ich beim Ausführen dieser Lösung auf meinem Computer erhalten habe:
duration: 16 seconds, CPU: 56 seconds, reads: 130404, writes: 0
Angesichts der Tatsache, dass nur ein paar Dutzend Monate involviert sind, wäre es viel effizienter, eine temporäre Tabelle zu verwenden, um das Ergebnis einer einzelnen Aktivität zu speichern, die die Zeilen von Orders gruppiert und aggregiert, und dann sowohl die äußeren als auch die inneren Eingaben davon zu haben der APPLY-Operator interagiert mit der temporären Tabelle. Hier ist die Lösung (wir nennen sie Lösung 10) mit einer temporären Tabelle anstelle des CTE:
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
INTO #OrdCount
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate);
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM #OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM #OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2;
DROP TABLE #OrdCount; Hier macht es wenig Sinn, die temporäre Tabelle zu indizieren, da der TOP-Filter in seiner Ordnungsangabe auf einer Berechnung basiert und somit eine Sortierung unumgänglich ist. Es kann aber durchaus sein, dass es in anderen Fällen, bei anderen Lösungen, auch für Sie relevant wäre, eine Indexierung Ihrer temporären Tabellen in Erwägung zu ziehen. Jedenfalls ist der Plan für diese Lösung in Abbildung 10 dargestellt.
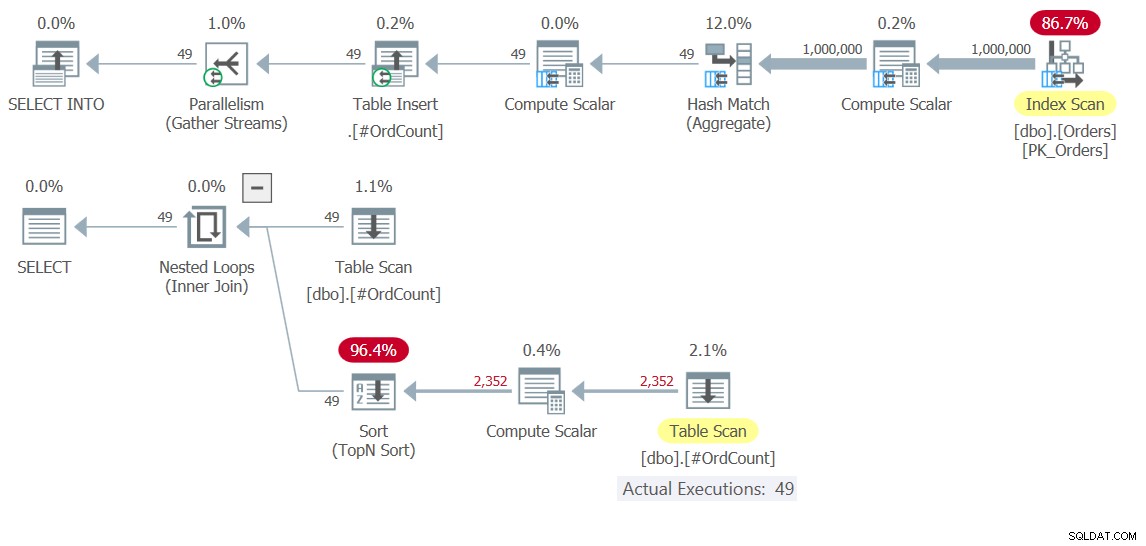 Abbildung 10:Ausführungspläne für Lösung 10
Abbildung 10:Ausführungspläne für Lösung 10
Beobachten Sie im oberen Plan, wie das schwere Heben, das das Scannen von 1.000.000 Zeilen, deren Gruppierung und Aggregation umfasst, nur einmal erfolgt. 49 Zeilen werden in die temporäre Tabelle #OrdCount geschrieben, und dann interagiert der untere Plan mit der temporären Tabelle für die äußeren und inneren Eingaben des Nested Loops-Operators, der die Logik des APPLY-Operators handhabt.
Hier sind die Leistungszahlen, die ich für die Ausführung dieser Lösung erhalten habe:
duration: 0.392 seconds, CPU: 0.5 seconds, reads: 3636, writes: 3
Es ist um Größenordnungen schneller als die CTE-basierte Lösung.
Was kommt als nächstes?
In diesem Artikel habe ich mit der Behandlung von Optimierungsüberlegungen im Zusammenhang mit CTEs begonnen. Ich habe gezeigt, dass der Entschachtelungs-/Substitutionsprozess, der bei abgeleiteten Tabellen stattfindet, bei CTEs genauso funktioniert. Ich habe auch die Tatsache besprochen, dass nichtrekursive CTEs nicht persistiert werden, und erklärt, dass Sie, wenn Persistenz ein wichtiger Faktor für die Leistung Ihrer Lösung ist, selbst damit umgehen müssen, indem Sie Tools wie temporäre Tabellen und Tabellenvariablen verwenden. Nächsten Monat werde ich die Diskussion fortsetzen, indem ich zusätzliche Aspekte der CTE-Optimierung behandle.



