SQL Server 2014 SP2 und höher erstellen Ausführungspläne zur Laufzeit („tatsächlich“), die die verstrichene Zeit enthalten können und CPU-Auslastung für jeden Ausführungsplanoperator (siehe KB3170113 und diesen Blogbeitrag von Pedro Lopes).
Die Interpretation dieser Zahlen ist nicht immer so einfach, wie man erwarten könnte. Es gibt wichtige Unterschiede zwischen dem Zeilenmodus und Stapelmodus Ausführung sowie knifflige Probleme mit dem Zeilenmodus Parallelität . SQL Server nimmt einige Zeitsteuerungs-Anpassungen vor parallel dazu Pläne zur Förderung der Kohärenz, die jedoch nicht perfekt umgesetzt werden. Dies kann es schwierig machen, fundierte Schlussfolgerungen zur Leistungsoptimierung zu ziehen.
Dieser Artikel soll Ihnen helfen zu verstehen, woher die Zeitangaben in jedem Fall stammen und wie sie am besten im Kontext interpretiert werden können.
Einrichtung
Die folgenden Beispiele verwenden den öffentlichen Stack Overflow 2013 Datenbank (Details herunterladen), mit einem hinzugefügten Index:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Die Testabfragen geben die Anzahl der Fragen mit einer akzeptierten Antwort zurück, gruppiert nach Monat und Jahr. Sie werden auf SQL Server 2019 CU9 ausgeführt , auf einem Laptop mit 8 Kernen und 16 GB Arbeitsspeicher, der der SQL Server 2019-Instanz zugewiesen ist. Kompatibilitätsstufe 150 wird ausschließlich verwendet.
Serielle Ausführung im Batch-Modus
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Der Ausführungsplan ist (zum Vergrößern anklicken):
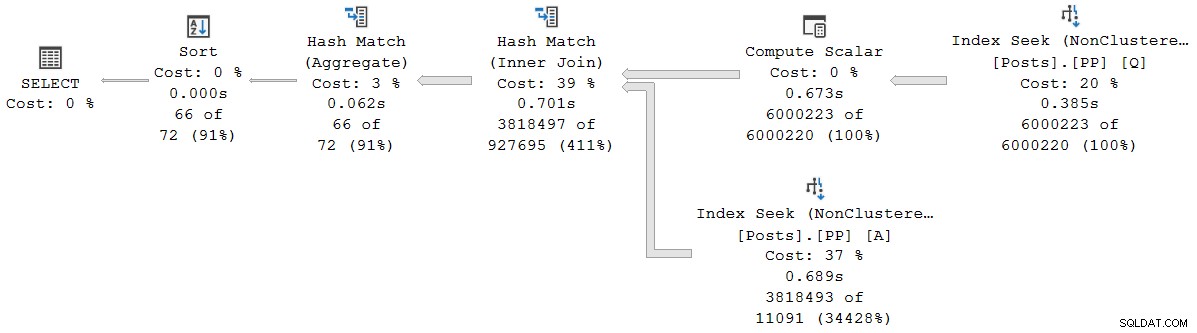
Jeder Operator in diesem Plan wird dank des Batch-Modus auf Rowstore im Batch-Modus ausgeführt Intelligente Abfrageverarbeitungsfunktion in SQL Server 2019 (kein Columnstore-Index erforderlich). Die Abfrage wird 2.523 ms ausgeführt mit 2.522 ms verwendeter CPU-Zeit, wenn sich alle benötigten Daten bereits im Pufferpool befinden.
Wie Pedro Lopes in dem zuvor verlinkten Blogbeitrag anmerkt, werden die verstrichene und die CPU-Zeit für den einzelnen Batch-Modus gemeldet Operatoren stellen die Zeit dar, die von diesem Operator allein verwendet wird .
SSMS zeigt verstrichene Zeit an in der grafischen Darstellung. Um die CPU-Zeiten zu sehen , wählen Sie einen Tarifbetreiber aus und sehen Sie dann in den Eigenschaften nach Fenster. Diese Detailansicht zeigt sowohl die verstrichene Zeit als auch die CPU-Zeit pro Operator und pro Thread.
Die Showplan-Zeiten (einschließlich der XML-Darstellung) werden abgeschnitten zu Millisekunden. Wenn Sie eine höhere Genauigkeit benötigen, verwenden Sie das query_thread_profile erweitertes Ereignis, das in Mikrosekunden gemeldet wird . Die Ausgabe dieses Ereignisses für den oben gezeigten Ausführungsplan lautet:
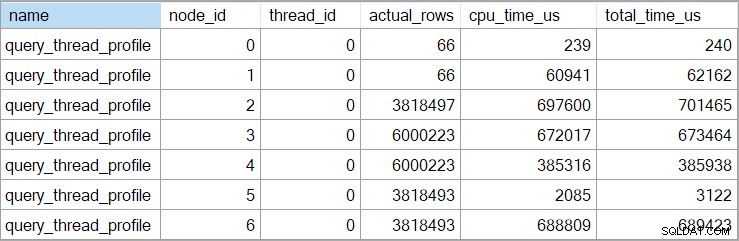
Dies zeigt, dass die verstrichene Zeit für den Join (Knoten 2) 701.465 µs beträgt (im Showplan auf 701 ms verkürzt). Das Aggregat hat eine verstrichene Zeit von 62.162 µs (62 ms). Die Indexsuche „Fragen“ wird als 385 ms lang angezeigt, während das erweiterte Ereignis zeigt, dass die wahre Zahl für Knoten 4 385.938 µs (fast 386 ms) betrug.
SQL Server verwendet die hohe Genauigkeit QueryPerformanceCounter API zum Erfassen von Zeitdaten. Dies verwendet Hardware, typischerweise einen Kristalloszillator, der Ticks mit einer sehr hohen konstanten Rate erzeugt, unabhängig von der Prozessorgeschwindigkeit, den Energieeinstellungen oder irgendetwas in dieser Art. Die Uhr läuft auch im Schlaf im gleichen Takt weiter. Sehen Sie sich den verlinkten sehr ausführlichen Artikel an, wenn Sie an all den feineren Details interessiert sind. Die kurze Zusammenfassung ist, dass Sie sich darauf verlassen können, dass die Mikrosekunden-Zahlen genau sind.
In diesem reinen Batch-Modus-Plan ist die Gesamtausführungszeit sehr nahe an der Summe der verstrichenen Zeiten der einzelnen Operatoren. Der Unterschied ist größtenteils auf Post-Statement-Arbeiten zurückzuführen, die nicht mit Planbetreibern verbunden sind (die bis dahin alle geschlossen wurden), obwohl die Kürzung von Millisekunden auch eine Rolle spielt.
Bei Plänen im reinen Stapelmodus müssen Sie die aktuellen Zeiten und die Zeiten untergeordneter Operatoren manuell summieren, um die kumulierte zu erhalten verstrichene Zeit an einem bestimmten Knoten.
Parallele Ausführung im Batch-Modus
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Der Ausführungsplan ist:
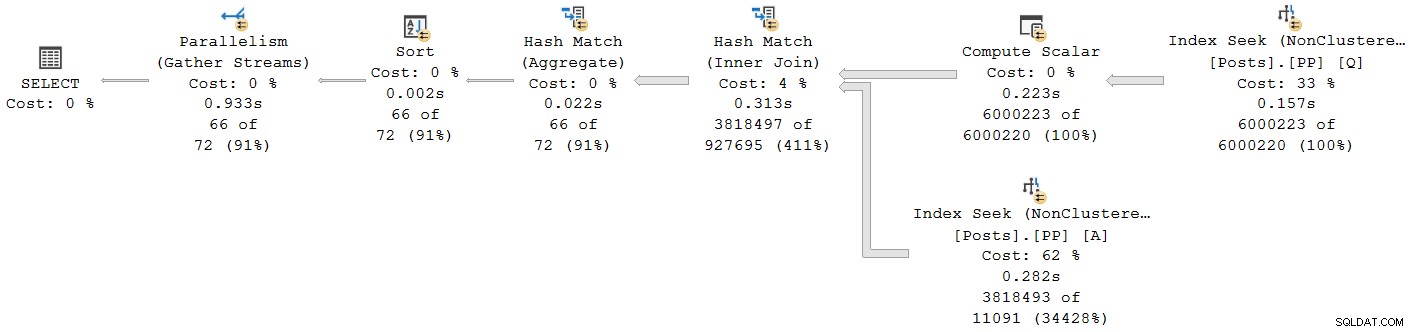
Alle Operatoren außer dem Final Gather Stream Exchange laufen im Batch-Modus. Die verstrichene Gesamtzeit beträgt 933 ms mit 6.673 ms CPU-Zeit mit einem warmen Cache.
Wählen Sie den Hash-Join aus und sehen Sie sich die Eigenschaften von SSMS an sehen wir die verstrichene und CPU-Zeit pro Thread für diesen Operator:
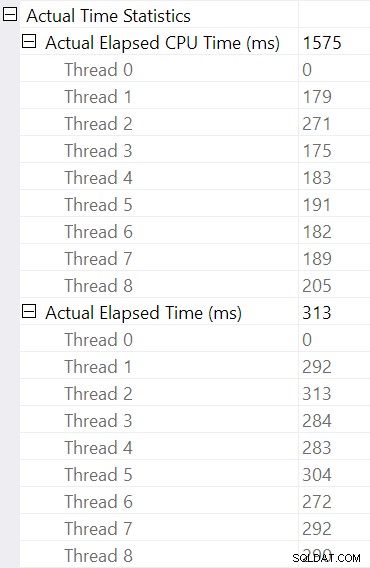
Die CPU-Zeit für den Betreiber gemeldet wird, ist die Summe der einzelnen Thread-CPU-Zeiten. Die gemeldete verstrichene Zeit des Operators ist das Maximum der pro Thread verstrichenen Zeiten. Beide Berechnungen werden über die pro Thread abgeschnittenen Millisekundenwerte durchgeführt. Wie zuvor ist die Gesamtausführungszeit sehr nahe an der Summe der verstrichenen Zeiten der einzelnen Operatoren.
Parallele Pläne im Stapelmodus verwenden keine Austauschvorgänge, um die Arbeit zwischen Threads zu verteilen. Batch-Operatoren werden implementiert, damit mehrere Threads effizient an einer einzigen gemeinsam genutzten Struktur arbeiten können (zB Hash-Tabelle). Eine gewisse Synchronisierung zwischen Threads ist in parallelen Plänen im Stapelmodus immer noch erforderlich, aber Synchronisierungspunkte und andere Details sind in der Showplan-Ausgabe nicht sichtbar.
Serielle Ausführung im Zeilenmodus
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Der Ausführungsplan ist optisch derselbe wie der Serienplan im Stapelmodus, aber jeder Operator wird jetzt im Zeilenmodus ausgeführt:
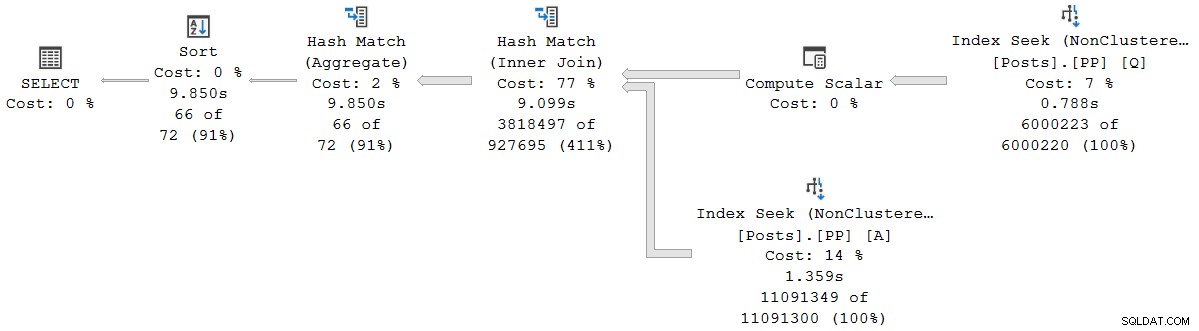
Die Abfrage wird 9.850 ms ausgeführt mit 9.845 ms CPU-Zeit. Dies ist erwartungsgemäß viel langsamer als die Abfrage im seriellen Stapelmodus (2523 ms/2522 ms). Noch wichtiger für die vorliegende Diskussion ist der Reihenmodus Operator verstrichen und CPU-Zeiten stellen die Zeit dar, die vom aktuellen Operator und allen seinen untergeordneten Elementen verwendet wird .
Das erweiterte Ereignis zeigt auch die kumulative CPU und die verstrichene Zeit an jedem Knoten (in Mikrosekunden):
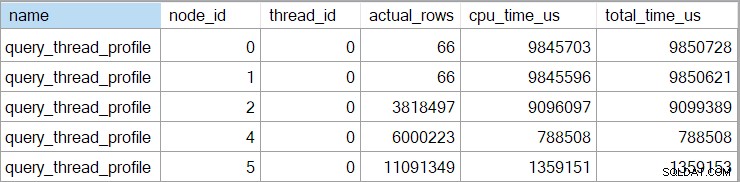
Es gibt keine Daten für den skalaren Berechnungsoperator (Knoten 3), da die Ausführung im Zeilenmodus aufschieben werden kann die meisten Ausdrucksberechnungen an den Operator, der das Ergebnis verarbeitet. Dies ist derzeit nicht für die Batch-Modus-Ausführung implementiert.
Der gemeldete kumulativ verstrichene Zeit für Operatoren im Zeilenmodus bedeutet, dass die Zeit, die für den endgültigen Sortieroperator angezeigt wird, der Gesamtausführungszeit für die Abfrage (jedenfalls mit einer Auflösung von Millisekunden) sehr nahe kommt. Die verstrichene Zeit für den Hash-Join umfasst ebenfalls Beiträge von den beiden darunter liegenden Indexsuchen sowie seine eigene Zeit. Zur Berechnung der verstrichenen Zeit Für den Hash-Join im Zeilenmodus allein müssten wir beide Suchzeiten davon abziehen.
Beide Darstellungen haben Vor- und Nachteile (kumulativ für Zeilenmodus, Einzeloperator nur für Stapelmodus). Was auch immer Sie bevorzugen, es ist wichtig, sich der Unterschiede bewusst zu sein.
Gemischte Ausführungsmoduspläne
Im Allgemeinen können moderne Ausführungspläne eine beliebige Mischung aus Zeilenmodus- und Stapelmodusoperatoren enthalten. Die Batch-Modus-Operatoren werden die Zeiten nur für sich selbst melden. Die Zeilenmodus-Operatoren werden eine kumulierte Summe bis zu diesem Punkt in den Plan aufnehmen, einschließlich all untergeordnete Operatoren. Um es klar zu sagen:Die kumulativen Zeiten eines Zeilenmodus-Operators enthalten alle untergeordneten Operatoren im Stapelmodus.
Wir haben dies zuvor im parallelen Stapelmodusplan gesehen:Der letzte (Zeilenmodus) Gathering-Streams-Operator hatte eine angezeigte (kumulative) verstrichene Zeit von 0,933 Sekunden – einschließlich aller seiner untergeordneten Stapelmodusoperatoren. Die anderen Operatoren arbeiteten alle im Batch-Modus und meldeten daher Zeiten nur für den einzelnen Operator.
Diese Situation, in der einige Planbetreiber im selben Plan sind kumulierte Zeiten haben und andere nicht, wird zweifellos als verwirrend angesehen von vielen Leuten.
Parallele Ausführung im Zeilenmodus
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Der Ausführungsplan ist:

Jeder Operator ist Zeilenmodus. Die Abfrage wird 4.677 ms ausgeführt mit 23.311ms CPU-Zeit (Summe aller Threads).
Da es sich ausschließlich um einen Plan im Zeilenmodus handelt, würden wir erwarten, dass alle Zeiten kumulativ sind . Beim Übergang vom Kind zum Elternteil (von rechts nach links) sollten die Zeiten in dieser Richtung zunehmen.
Schauen wir uns nur den Abschnitt ganz rechts des Plans an:
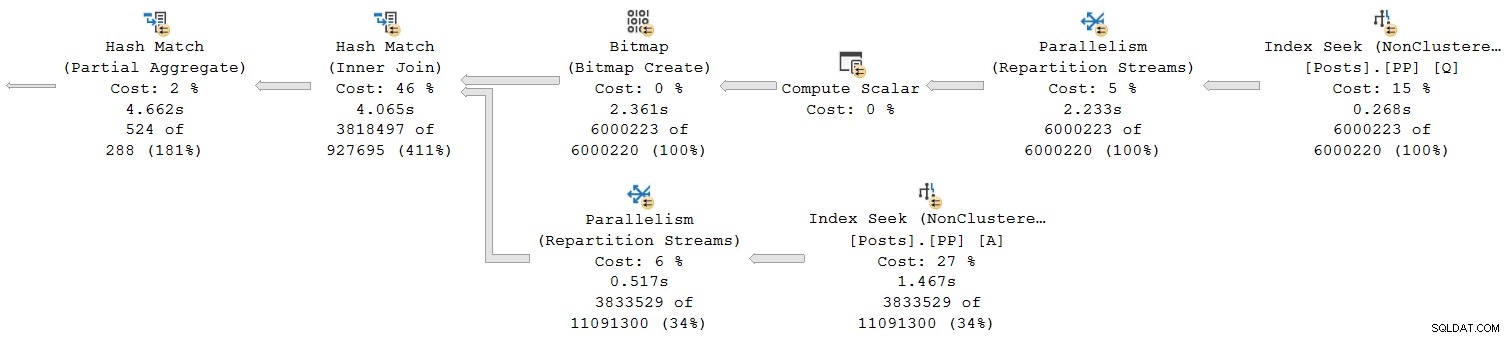
Wenn Sie in der obersten Reihe von rechts nach links arbeiten, scheinen kumulierte Zeiten sicherlich der Fall zu sein. Aber es gibt eine Ausnahme auf der unteren Eingabe für den Hash-Join:Die Indexsuche hat eine verstrichene Zeit von 1,467 s , während sein Elternteil Repartition Streams hat eine verstrichene Zeit von nur 0,517 s .
Wie kann ein Elternteil Bediener für weniger Zeit ausgeführt als sein Kind wenn verstrichene Zeiten in Reihenmodusplänen kumulativ sind?
Inkonsistente Zeiten
Die Lösung dieses Rätsels besteht aus mehreren Teilen. Gehen wir es Stück für Stück an, denn es ist ziemlich komplex:
Denken Sie zunächst daran, dass ein Austausch (Parallelitätsoperator) aus zwei Teilen besteht. Die linke Hand (Verbraucher )-Seite ist mit einem Satz von Threads verbunden, die Operatoren im parallelen Zweig auf der linken Seite ausführen. Die rechte Hand (Produzent )-Seite des Austauschs ist mit einem anderen Satz von Threads verbunden, die Operatoren im parallelen Zweig auf der rechten Seite ausführen.
Zeilen von der Herstellerseite werden zu Paketen zusammengesetzt und dann auf die Verbraucherseite übertragen. Dies bietet ein gewisses Maß an Pufferung und Flusskontrolle zwischen den beiden Sätzen verbundener Threads. (Wenn Sie eine Auffrischung zu Börsen und Zweigen paralleler Pläne benötigen, lesen Sie bitte meinen Artikel Parallele Ausführungspläne – Zweige und Threads.)
Der Umfang der kumulativen Zeiten
Betrachten Sie den parallelen Zweig auf dem Produzenten Seite des Austauschs:
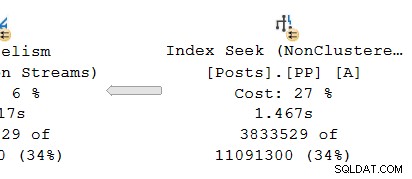
Wie üblich führen DOP (Grad of Parallelism) zusätzliche Worker-Threads eine unabhängige Serielle aus Kopie der Planbetreiber in dieser Branche. Bei DOP 8 gibt es also 8 unabhängige serielle Indexsuchen, die zusammenarbeiten, um den Bereichsabtastteil der gesamten (parallelen) Indexsuchoperation durchzuführen. Jede Singlethread-Suche ist mit einem anderen Eingang (Port) auf der Erzeugerseite des Single Shared verbunden Börsenbetreiber.
Eine ähnliche Situation besteht beim Verbraucher Seite der Börse. Bei DOP 8 gibt es 8 separate Singlethread-Kopien dieses Zweigs, die alle unabhängig voneinander laufen:
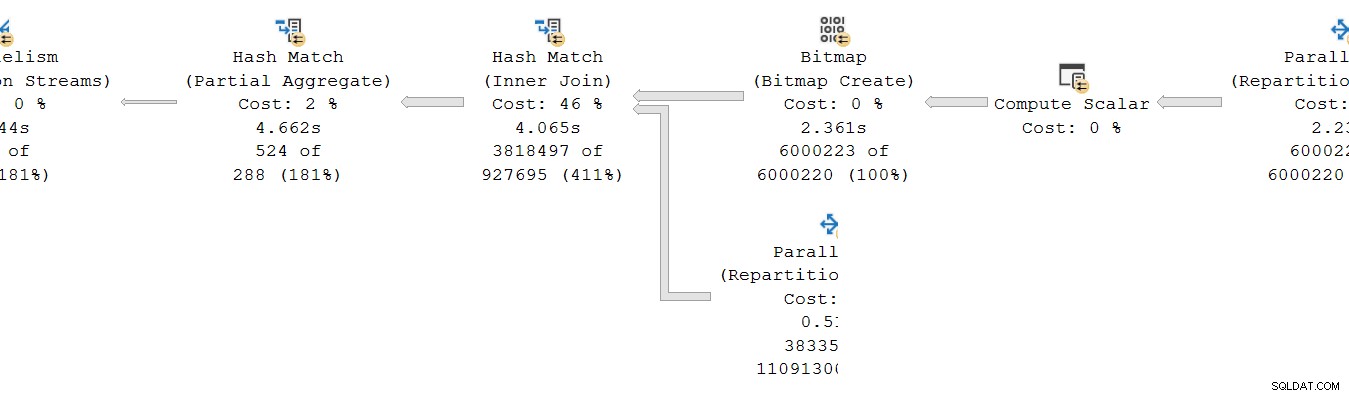
Jeder dieser Einzelthread-Teilpläne wird auf die übliche Weise ausgeführt, wobei jeder Operator die verstrichene und die CPU-Zeitsummen an jedem Knoten akkumuliert. Da es sich um Zeilenmodus-Operatoren handelt, stellt jede Summe die Zeit dar, die die kumulierte Summe für den aktuellen Knoten und jeden seiner untergeordneten Knoten aufgewendet hat.
Der entscheidende Punkt ist, dass die kumulierten Summen schließen Sie nur Operatoren im gleichen Thread ein und nur innerhalb des aktuellen Zweigs . Hoffentlich ergibt das einen intuitiven Sinn, denn jeder Thread hat keine Ahnung, was woanders vor sich geht.
Wie Zeilenmodusmetriken erfasst werden
Der zweite Teil des Puzzles bezieht sich auf die Art und Weise, wie die Zeilenanzahl und die Timing-Metriken in Zeilenmodusplänen erfasst werden. Wenn Laufzeit- („tatsächliche“) Planinformationen erforderlich sind, fügt die Ausführungs-Engine ein unsichtbares hinzu Profiling-Operator unmittelbar links (übergeordnet) jedes Operators im Plan, der zur Laufzeit ausgeführt wird.
Dieser Bediener kann (unter anderem) die Differenz zwischen dem Zeitpunkt, zu dem er die Kontrolle an seinen untergeordneten Bediener übergeben hat, und dem Zeitpunkt, zu dem die Kontrolle zurückgegeben wurde, aufzeichnen. Dieser Zeitunterschied stellt die verstrichene Zeit für den überwachten Operator und alle seine Kinder dar , da das Kind pro Zeile sein eigenes Kind aufruft und so weiter. Ein Operator kann viele Male aufgerufen werden (zum Initialisieren, dann einmal pro Zeile, schließlich zum Schließen), sodass die vom Profiling-Operator gesammelte Zeit eine Akkumulation ist über potenziell viele Iterationen pro Zeile.
Weitere Einzelheiten zu den Profildaten Informationen, die mit unterschiedlichen Erfassungsmethoden gesammelt wurden, finden Sie in der Produktdokumentation zur Infrastruktur für die Abfrageprofilerstellung. Für diejenigen, die sich für solche Dinge interessieren, der Name des unsichtbaren Profiling-Operators, der von der Standardinfrastruktur verwendet wird, lautet sqlmin!CQScanProfileNew . Wie alle Zeilenmodus-Iteratoren hat er Open , GetRow , und Close Methoden u.a. Jede Methode enthält Aufrufe an den QueryPerformanceCounter von Windows API zum Erfassen des aktuellen hochauflösenden Timerwerts.
Da der Profiling-Operator links ist des Zielbetreibers misst es nur den Verbraucher Seite der Börse. Es gibt kein Profiling-Operator für den Produzenten Seite der Börse (leider). Wenn dies der Fall wäre, würde es der bei der Indexsuche angezeigten verstrichenen Zeit entsprechen oder diese überschreiten, da die Indexsuche und die Erzeugerseite denselben Satz von Threads ausführen und die Erzeugerseite des Austauschs der übergeordnete Operator der Indexsuche ist.
Timing revisited

Trotz alledem haben Sie möglicherweise immer noch Probleme mit den oben gezeigten Timings. Wie kann eine Indexsuche 1,467 s dauern? um Zeilen an die Erzeugerseite eines Austauschs zu übergeben, aber die Verbraucherseite benötigt nur 0,517 s sie zu empfangen? Unabhängig von separaten Threads, Pufferung und so weiter, sicherlich der Austausch soll (Ende-zu-Ende) länger laufen als die Suche?
Ja, das tut es, aber das ist eine andere Messung von verstrichener oder CPU-Zeit. Lassen Sie uns genau sagen, was wir hier messen.
Für den Zeilenmodus verstrichene Zeit , stellen Sie sich eine Stoppuhr pro Thread vor bei jedem Betreiber. Die Stoppuhr startet wenn SQL Server den Code für einen Operator von seinem übergeordneten Element eingibt und stoppt (wird aber nicht zurückgesetzt), wenn dieser Code den Bediener verlässt, um die Kontrolle wieder an den Elternteil (nicht an ein Kind) zurückzugeben. Verstrichene Zeit enthält keine Wartezeiten oder Verzögerungen bei der Planung – nichts davon hält die Uhr an.
Für den Zeilenmodus CPU-Zeit , stellen Sie sich dieselbe Stoppuhr mit denselben Eigenschaften vor, außer dass sie während Wartezeiten und Planungsverzögerungen stoppt. Es sammelt nur Zeit an, wenn der Operator oder eines seiner Kinder aktiv auf einem Scheduler (CPU) ausgeführt wird. Die Gesamtzeit auf einer Stoppuhr pro Thread pro Operator setzt sich aus einem Start-Stopp-Zyklus für jede Reihe zusammen.
Wenden wir das auf die aktuelle Situation mit der Verbraucherseite der Börse und der Indexsuche an:
Denken Sie daran, dass sich die Verbraucherseite des Austauschs und die Indexsuche in separaten Zweigen befinden, sodass sie in separaten Threads ausgeführt werden . Die Verbraucherseite hat keine untergeordneten Elemente im selben Thread. Die Indexsuche hat die Producer-Seite der Börse als übergeordnetes Element im selben Thread, aber wir haben dort keine Stoppuhr.
Jeder Consumer-Thread startet seine Überwachung, wenn sein übergeordneter Operator (die Sondenseite des Hash-Joins) die Kontrolle übergibt (z. B. um eine Zeile abzurufen). Die Uhr läuft weiter, während der Verbraucher eine Zeile aus dem aktuellen Austauschpaket abruft. Die Uhr stoppt wenn die Steuerung den Verbraucher verlässt und zur Seite der Hash-Join-Sonde zurückkehrt. Weitere Eltern (das partielle Aggregat und seine übergeordnete Börse) werden ebenfalls an dieser Zeile arbeiten (und möglicherweise warten), bevor die Kontrolle an die Verbraucherseite unserer Börse zurückgegeben wird, um die nächste Zeile abzurufen. An diesem Punkt beginnt die Verbraucherseite unseres Austauschs erneut, verstrichene Zeit und CPU-Zeit zu akkumulieren.
Unabhängig davon, was die Zweig-Threads auf der Consumer-Seite tun, wird in der Zwischenzeit index seek Threads suchen weiterhin Zeilen im Index und speisen sie in den Austausch ein. Ein Indexsuch-Thread startet seine Stoppuhr, wenn die Erzeugerseite der Börse ihn nach einer Zeile fragt. Die Stoppuhr wird angehalten, wenn die Reihe an die Börse übergeben wird. Wenn die Börse nach der nächsten Zeile fragt, wird die Stoppuhr für die Indexsuche fortgesetzt.
Beachten Sie, dass auf der Herstellerseite des Austauschs CXPACKET auftreten kann wartet, während sich die Austauschpuffer füllen, aber das wird nicht zu den bei der Indexsuche aufgezeichneten verstrichenen Zeiten addiert, da seine Stoppuhr nicht läuft, wenn das passiert. Hätten wir eine Stoppuhr für die Produzentenseite des Austauschs, würde die fehlende verstrichene Zeit dort erscheinen.
Um eine visuelle Zusammenfassung der Situation anzunähern, zeigt das folgende Diagramm, wann jeder Operator die verstrichene Zeit in den zwei parallelen Zweigen akkumuliert:
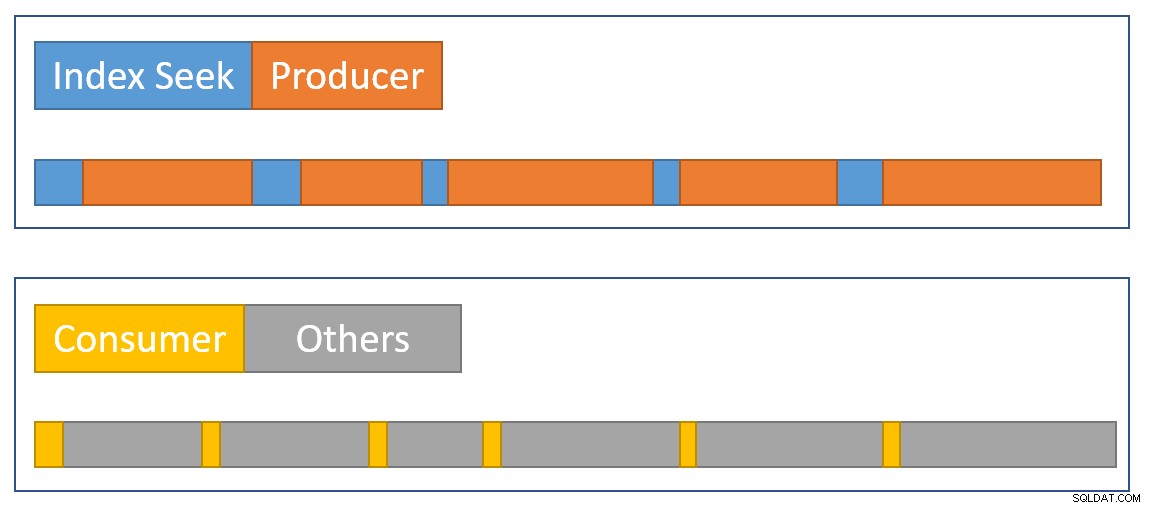
Das Blaue Indexsuchzeitbalken sind kurz, da das Abrufen einer Zeile aus einem Index schnell ist. Die Orange Producer-Zeiten können aufgrund von CXPACKET lang sein wartet. Das Gelb Die Verbraucherzeiten sind kurz, da eine Zeile schnell von der Börse abgerufen werden kann, wenn Daten verfügbar sind. Das Grau Zeitsegmente stellen die Zeit dar, die von den anderen Betreibern (Hash-Join-Sondenseite, Teilaggregat und der Erzeugerseite der übergeordneten Börse) über der Verbraucherseite der Börse verwendet wird.
Wir erwarten, dass die Austauschpakete schnell gefüllt werden durch die Indexsuche, aber langsam geleert (relativ gesehen) von den Betreibern auf der Verbraucherseite, weil sie mehr Arbeit zu erledigen haben. Dies bedeutet, dass Pakete in der Vermittlungsstelle normalerweise voll oder fast voll sind. Der Verbraucher kann eine wartende Zeile schnell abrufen, aber der Erzeuger muss möglicherweise warten, bis der Paketspeicherplatz angezeigt wird.
Es ist eine Schande, dass wir die verstrichenen Zeiten auf der Produzentenseite der Börse nicht sehen können. Ich bin seit langem der Meinung, dass eine Börse durch zwei repräsentiert werden sollte verschiedene Operatoren in Ausführungsplänen. Es würde CXPACKET erschweren /CXCONSUMER Wartezeitanalyse viel weniger notwendig und Ausführungspläne viel einfacher zu verstehen. Der Exchange-Producer-Operator würde natürlich seinen eigenen Profiling-Operator bekommen.
Alternative Designs
Es gibt viele Möglichkeiten, wie SQL Server eine konsistente kumulative erreichen kann verstrichene und CPU-Zeit über parallele Zweige im Prinzip . Anstatt Operatoren zu profilieren, könnte jede Zeile Informationen darüber enthalten, wie viel verstrichen ist und wie viel CPU-Zeit sie bisher auf ihrer Reise durch den Plan angesammelt hat. Da jeder Zeile ein Verlauf zugeordnet ist, spielt es keine Rolle, wie der Austausch die Zeilen zwischen den Threads neu verteilt und so weiter.
So wurde das Produkt nicht entworfen, also haben wir das nicht (und es könnte sowieso ineffizient sein). Um fair zu sein, befasste sich das ursprüngliche Design des Zeilenmodus nur mit Dingen wie dem Sammeln der tatsächlichen Zeilenanzahl und der Anzahl der Iterationen bei jedem Operator. Das Hinzufügen der pro Bediener verstrichenen Zeit zu Plänen war eine vielgewünschte Funktion , aber es war nicht einfach, es in das bestehende Framework zu integrieren.
Als dem Produkt Batch-Modus-Verarbeitung hinzugefügt wurde, konnte ein anderer Ansatz (Timing nur für den aktuellen Bediener) als Teil der ursprünglichen Entwicklung implementiert werden, ohne etwas zu beschädigen. Auch hier im Prinzip hätten Zeilenmodusoperatoren so geändert werden können, dass sie auf die gleiche Weise wie Stapelmodusoperatoren funktionieren, aber das hätte viel Arbeit erfordert, um jeden vorhandenen Zeilenmodusoperator neu zu konstruieren. Das Hinzufügen eines neuen Datenpunkts zu den vorhandenen Zeilenmodus-Profilerstellungsoperatoren war viel einfacher. Angesichts begrenzter technischer Ressourcen und einer langen Liste gewünschter Produktverbesserungen müssen oft solche Kompromisse eingegangen werden.
Das zweite Problem
Eine weitere kumulative Timing-Inkonsistenz tritt im vorliegenden Plan auf der linken Seite auf:

Auf den ersten Blick scheint dies dasselbe Problem zu sein:Das Teilaggregat hat eine verstrichene Zeit von 4,662 Sekunden , aber der Austausch darüber läuft nur für 2,844 Sekunden . Natürlich sind die gleichen grundlegenden Mechanismen wie zuvor im Spiel, aber es gibt noch einen weiteren wichtigen Faktor. Ein Hinweis liegt in den verdächtig gleichen Zeiten, die für den Stream-Aggregations-, Sortierungs- und Neupartitionierungsaustausch gemeldet wurden.
Erinnern Sie sich an die „Timing-Anpassungen“, die ich in der Einleitung erwähnt habe? Hier kommen diese ins Spiel. Schauen wir uns die einzelnen verstrichenen Zeiten für Threads auf der Verbraucherseite des Repartition Streams Exchange an:
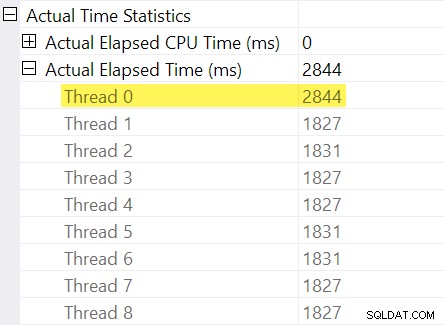
Denken Sie daran, dass Pläne die verstrichene Zeit für einen parallelen Operator als Maximum anzeigen der Per-Thread-Zeiten. Alle 8 Threads hatten eine verstrichene Zeit von etwa 1.830 ms, aber es gibt einen zusätzlichen Eintrag für „Thread 0“ mit 2.844 ms. In der Tat jeder Betreiber in diesem parallelen Zweig (der Austauschkonsument, die Sortierung und das Stromaggregat) haben dasselbe 2.844 ms Beitrag von „Thread 0“.
Thread Null (auch bekannt als übergeordnete Aufgabe oder Koordinator) führt nur direkt Operatoren links vom Final Gather Streams-Operator aus. Warum wird ihr hier in einem parallelen Zweig Arbeit zugewiesen?
Erklärung
Dieses Problem kann auftreten, wenn im parallelen Zweig unten ein blockierender Operator vorhanden ist (rechts neben) dem aktuellen. Ohne diese Anpassung würden Operatoren in der aktuellen Branche die verstrichene Zeit zu niedrig melden nach der Zeit, die zum Öffnen des untergeordneten Zweigs benötigt wird (es gibt komplizierte architektonische Gründe dafür).
SQL Server versucht, dies zu berücksichtigen, indem die Verzögerung des untergeordneten Zweigs an der Vermittlungsstelle im unsichtbaren Profiling-Operator aufgezeichnet wird. Der Zeitwert wird gegen die übergeordnete Aufgabe aufgezeichnet („Thread 0“) in der Differenz zwischen seinem ersten aktiven und zuletzt aktiv mal. (Es mag seltsam erscheinen, die Nummer auf diese Weise aufzuzeichnen, aber zu dem Zeitpunkt, an dem die Nummer aufgezeichnet werden muss, wurden die zusätzlichen parallelen Worker-Threads noch nicht erstellt).
Im aktuellen Fall die 2.844 ms-Anpassung entsteht hauptsächlich aufgrund der Zeit, die der Hash-Join benötigt, um seine Hash-Tabelle zu erstellen. (Beachten Sie, dass sich diese Zeit von der Gesamtzeit unterscheidet Ausführungszeit des Hash-Joins, einschließlich der Zeit, die zum Verarbeiten der Sondenseite des Joins benötigt wird).
Die Notwendigkeit einer Anpassung ergibt sich, weil ein Hash-Join seine Build-Eingabe blockiert. (Interessanterweise ist der Hash Teilaggregat im Plan wird in diesem Zusammenhang nicht als blockierend betrachtet, da ihm nur eine minimale Menge an Speicher zugewiesen wird und niemals auf tempdb überläuft , und stoppt einfach die Aggregation, wenn der Speicher ausgeht (wodurch in einen Streaming-Modus zurückgekehrt wird). Craig Freedman erklärt dies in seinem Beitrag Partial Aggregation).
Da die Anpassung der verstrichenen Zeit eine Initialisierungsverzögerung im untergeordneten Zweig darstellt, sollte SQL Server um den „Thread 0“-Wert als Offset zu behandeln für die gemessene pro Thread verstrichene Zeit innerhalb des aktuellen Zweigs. Das Maximum nehmen aller Threads, da die verstrichene Zeit im Allgemeinen angemessen ist, da Threads dazu neigen, zur gleichen Zeit zu starten. Das tut es nicht macht Sinn, wenn einer der Thread-Werte ein Offset für alle anderen Werte ist!
Wir können die korrekte Offset-Berechnung durchführen manuell anhand der im Plan verfügbaren Daten. Auf der Verbraucherseite der Börse haben wir:
Die maximal verstrichene Zeit zwischen den zusätzlichen Worker-Threads beträgt 1.831 ms (ohne den in „Gewinde 0“ gespeicherten Versatzwert). Hinzufügen des Offsets von 2.844 ms ergibt insgesamt 4.675 ms .
In jedem Plan, in dem die Zeiten pro Thread weniger sind als der Offset, wird der Operator falsch Zeigen Sie den Offset als die verstrichene Gesamtzeit an. Dies tritt wahrscheinlich auf, wenn der frühere Blockierungsoperator langsam ist (vielleicht eine Sortierung oder ein globales Aggregat über einen großen Datensatz) und die späteren Verzweigungsoperatoren weniger zeitaufwändig sind.
Überdenken Sie diesen Teil des Plans:
Ersetzen des 2.844 ms-Offsets, das fälschlicherweise den Repartition-Streams, Sortier- und Streamaggregatoperatoren zugewiesen wurde, durch unsere berechneten 4.675 ms -Wert platziert ihre kumulierten verstrichenen Zeiten sauber zwischen den 4.662 ms beim Teilaggregat und den 4.676 ms bei den Final Gather Streams. (Die Sortierung und die Aggregation arbeiten mit einer winzigen Anzahl von Zeilen, sodass ihre Berechnungen der verstrichenen Zeit dieselben Ergebnisse wie die Sortierung ergeben, aber im Allgemeinen würden sie sich oft unterscheiden):

Alle Operatoren im obigen Planfragment haben über alle Threads hinweg eine verstrichene CPU-Zeit von 0 ms (abgesehen von dem Teilaggregat, das 14.891 ms hat). Der Plan mit unseren berechneten Zahlen macht daher viel mehr Sinn als der angezeigte:
- 4.675 ms – 4.662 ms =13 ms Elapsed ist eine viel vernünftigere Zahl für die Zeit, die von den Repartition-Streams allein verbraucht wird . Dieser Operator verbraucht keine CPU-Zeit und verarbeitet nur 524 Zeilen.
- 0ms verstrichen (Auflösung im Millisekundenbereich) ist für das winzige Sort- und Stream-Aggregat angemessen (wieder ohne ihre Kinder).
- 4.676 ms – 4.675 ms =1 ms scheint gut für die Final Gather-Streams zu sein, um 66 Zeilen im übergeordneten Task-Thread zur Rückgabe an den Client zu sammeln.
Abgesehen von der offensichtlichen Inkonsistenz im gegebenen Plan zwischen dem partiellen Aggregat (4.662 ms) und den Repartition-Streams (2.844 ms), ist es unvernünftig zu glauben, dass die Final Gather-Streams von 66 Zeilen für 4.676 ms – 2.844 ms = verantwortlich sein könnten 1.832 ms der verstrichenen Zeit. Die korrigierte Zahl (1 ms) ist viel genauer und führt Abfragetuner nicht in die Irre.
Nun, selbst wenn diese Offset-Berechnung korrekt durchgeführt würde, könnten parallele Zeilenmoduspläne nicht sein zeigen aus den zuvor diskutierten Gründen in allen Fällen konsistente kumulative Zeiten. Das Erreichen vollständiger Konsistenz kann ohne größere Änderungen an der Architektur schwierig oder sogar unmöglich sein.
Um eine Frage vorwegzunehmen, die an dieser Stelle aufkommen könnte:Nein, die frühere Börsen- und Indexsuchanalyse beinhaltete keinen „Thread 0“-Offset-Berechnungsfehler. Es gibt keinen blockierenden Operator unterhalb dieses Austauschs, sodass keine Initialisierungsverzögerung auftritt.
Ein letztes Beispiel
Diese nächste Beispielabfrage verwendet dieselbe Datenbank und denselben Index wie zuvor. Ich werde es nicht zu sehr ins Detail gehen, weil es nur dazu dient, die Punkte, die ich bereits gemacht habe, für den interessierten Leser zu erweitern.
Die Features dieser Demo sind:
- Ohne eine
ORDER GROUPHinweis, es zeigt, wie ein partielles Aggregat nicht als blockierender Operator betrachtet wird, sodass keine „Thread 0“-Anpassung beim Repartition-Streams-Austausch entsteht. Die verstrichenen Zeiten sind konsistent. - Mit dem Hinweis werden anstelle eines Hash-Teilaggregats blockierende Sortierungen eingeführt. Zwei verschiedene „Thread 0“-Anpassungen erscheinen an den beiden Neupartitionierungsbörsen. Die verstrichenen Zeiten sind auf beiden Zweigen auf unterschiedliche Weise inkonsistent.
Abfrage:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Ausführungsplan ohne ORDER GROUP (keine Anpassung, konsistente Zeiten):

Ausführungsplan mit ORDER GROUP (zwei unterschiedliche Einstellungen, uneinheitliche Zeiten):

Zusammenfassung und Schlussfolgerungen
Planoperatoren im Zeilenmodus melden kumulativ times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.