Dies ist der dritte Teil einer Serie über Lösungen für die Herausforderung des Zahlenreihengenerators. In Teil 1 habe ich Lösungen behandelt, die die Zeilen im laufenden Betrieb generieren. In Teil 2 habe ich Lösungen behandelt, die eine physische Basistabelle abfragen, die Sie vorab mit Zeilen füllen. Diesen Monat werde ich mich auf eine faszinierende Technik konzentrieren, die zur Bewältigung unserer Herausforderung eingesetzt werden kann, aber auch weit darüber hinaus interessante Anwendungen hat. Mir ist kein offizieller Name für diese Technik bekannt, aber sie ähnelt im Konzept der horizontalen Partitionseliminierung, daher werde ich sie informell als horizontale Einheiteneliminierung bezeichnen Technik. Die Technik kann interessante positive Leistungsvorteile haben, aber es gibt auch Vorbehalte, die Sie beachten müssen, wo sie unter bestimmten Bedingungen zu Leistungseinbußen führen kann.
Nochmals vielen Dank an Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea und Paul White für das Teilen Ihrer Ideen und Kommentare. P>
Ich werde meine Tests in tempdb durchführen und Zeitstatistiken aktivieren:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Frühere Ideen
Die horizontale Einheiteneliminierungstechnik kann als Alternative zur Spalteneliminierungslogik oder zur vertikalen Einheiteneliminierung verwendet werden Technik, auf die ich mich bei mehreren der zuvor behandelten Lösungen verlassen habe. Über die Grundlagen der Spalteneliminierungslogik mit Tabellenausdrücken können Sie in Grundlagen zu Tabellenausdrücken, Teil 3 – Abgeleitete Tabellen, Optimierungsüberlegungen unter „Spaltenprojektion und ein Wort zu SELECT *.“
nachlesenDie Grundidee der Eliminierungstechnik für vertikale Einheiten besteht darin, dass, wenn Sie einen verschachtelten Tabellenausdruck haben, der die Spalten x und y zurückgibt, und Ihre äußere Abfrage nur auf Spalte x verweist, der Abfragekompilierungsprozess y aus der ursprünglichen Abfragestruktur und damit aus dem Plan eliminiert braucht man nicht zu bewerten. Dies hat mehrere positive Auswirkungen auf die Optimierung, z. B. das Erreichen der Indexabdeckung mit x allein, und wenn y das Ergebnis einer Berechnung ist, muss der zugrunde liegende Ausdruck von y überhaupt nicht ausgewertet werden. Diese Idee stand im Mittelpunkt der Lösung von Alan Burstein. Ich habe mich auch in mehreren der anderen Lösungen, die ich behandelt habe, darauf verlassen, z. B. bei der Funktion dbo.GetNumsAlanCharlieItzikBatch (aus Teil 1), den Funktionen dbo.GetNumsJohn2DaveObbishAlanCharlieItzik und dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 (aus Teil 2) und anderen. Als Beispiel verwende ich dbo.GetNumsAlanCharlieItzikBatch als Basislösung mit der vertikalen Eliminierungslogik.
Zur Erinnerung:Diese Lösung verwendet einen Join mit einer Dummy-Tabelle, die über einen Columnstore-Index verfügt, um eine Stapelverarbeitung zu erhalten. Hier ist der Code zum Erstellen der Dummy-Tabelle:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Und hier ist der Code mit der Definition der Funktion dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Ich habe den folgenden Code verwendet, um die Leistung der Funktion mit 100 Millionen Zeilen zu testen und die berechnete Ergebnisspalte n (Manipulation des Ergebnisses der ROW_NUMBER-Funktion) zurückzugeben, sortiert nach n:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Hier sind die Zeitstatistiken, die ich für diesen Test erhalten habe:
CPU-Zeit =9328 ms, verstrichene Zeit =9330 ms.Ich habe den folgenden Code verwendet, um die Leistung der Funktion mit 100 Millionen Zeilen zu testen und die Spalte rn (direkt, nicht manipuliert, Ergebnis der ROW_NUMBER-Funktion) zurückzugeben, sortiert nach rn:
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Hier sind die Zeitstatistiken, die ich für diesen Test erhalten habe:
CPU-Zeit =7296 ms, verstrichene Zeit =7291 ms.Sehen wir uns die wichtigen Ideen an, die in diese Lösung eingebettet sind.
Alan stützte sich auf die Spalteneliminierungslogik und kam auf die Idee, nicht nur eine Spalte mit der Zahlenreihe zurückzugeben, sondern drei:
- Spaltern stellt ein nicht manipuliertes Ergebnis der ROW_NUMBER-Funktion dar, die mit 1 beginnt. Es ist billig zu berechnen. Es ist die Beibehaltung der Reihenfolge, sowohl wenn Sie Konstanten als auch Nichtkonstanten (Variablen, Spalten) als Eingaben für die Funktion bereitstellen. Das bedeutet, dass Sie keinen Sort-Operator im Plan erhalten, wenn Ihre äußere Abfrage ORDER BY rn verwendet.
- Spalte n stellt eine Berechnung dar, die auf @low, einer Konstante, und rownum (Ergebnis der ROW_NUMBER-Funktion) basiert. Es ist die Beibehaltung der Reihenfolge in Bezug auf rownum, wenn Sie Konstanten als Eingaben für die Funktion bereitstellen. Das ist Charlies Einsicht in Bezug auf das konstante Falten zu verdanken (siehe Teil 1 für Details). Es ist jedoch nicht ordnungserhaltend, wenn Sie Nichtkonstanten als Eingaben bereitstellen, da Sie keine konstante Faltung erhalten. Ich werde dies später im Abschnitt über Vorbehalte demonstrieren.
- Spalte op stellt n in umgekehrter Reihenfolge dar. Es ist das Ergebnis einer Berechnung und nicht ordnungserhaltend.
Wenn Sie sich auf die Spalteneliminierungslogik verlassen und eine Zahlenreihe zurückgeben müssen, die mit 1 beginnt, fragen Sie die Spalte rn ab, was billiger ist als die Abfrage von n. Wenn Sie eine Zahlenreihe benötigen, die mit einem anderen Wert als 1 beginnt, fragen Sie n ab und zahlen die zusätzlichen Kosten. Wenn Sie das Ergebnis nach der Zahlenspalte geordnet benötigen, können Sie mit Konstanten als Eingaben entweder ORDER BY rn oder ORDER BY n verwenden. Bei Nichtkonstanten als Eingaben sollten Sie jedoch sicherstellen, dass Sie ORDER BY rn verwenden. Es könnte eine gute Idee sein, sich einfach immer an die Verwendung von ORDER BY rn zu halten, wenn das Ergebnis bestellt werden muss, um auf der sicheren Seite zu sein.
Die Idee der Eliminierung horizontaler Einheiten ähnelt der Idee der vertikalen Einheitseliminierung, nur dass sie auf Gruppen von Zeilen statt auf Gruppen von Spalten angewendet wird. Tatsächlich hat sich Joe Obbish in seiner Funktion dbo.GetNumsObbish (aus Teil 2) auf diese Idee verlassen, und wir werden noch einen Schritt weiter gehen. In seiner Lösung vereinheitlichte Joe mehrere Abfragen, die disjunkte Unterbereiche von Zahlen darstellen, und verwendete einen Filter in der WHERE-Klausel jeder Abfrage, um die Anwendbarkeit des Unterbereichs zu definieren. Wenn Sie die Funktion aufrufen und konstante Eingaben übergeben, die die Trennzeichen Ihres gewünschten Bereichs darstellen, eliminiert SQL Server die unzutreffenden Abfragen zur Kompilierzeit, sodass der Plan sie nicht einmal widerspiegelt.
Eliminierung horizontaler Einheiten, Kompilierzeit versus Laufzeit
Vielleicht wäre es eine gute Idee, zunächst das Konzept der horizontalen Einheiteneliminierung in einem allgemeineren Fall zu demonstrieren und auch einen wichtigen Unterschied zwischen Kompilierzeit- und Laufzeit-Eliminierung zu diskutieren. Dann können wir diskutieren, wie wir die Idee auf unsere Nummernserien-Challenge anwenden können.
In meinem Beispiel verwende ich drei Tabellen namens dbo.T1, dbo.T2 und dbo.T3. Verwenden Sie den folgenden DDL- und DML-Code, um diese Tabellen zu erstellen und zu füllen:
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Angenommen, Sie möchten eine Inline-TVF namens dbo.OneTable implementieren, die einen der drei oben genannten Tabellennamen als Eingabe akzeptiert und die Daten aus der angeforderten Tabelle zurückgibt. Basierend auf dem Konzept der horizontalen Einheiteneliminierung könnten Sie die Funktion folgendermaßen implementieren:
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
Denken Sie daran, dass ein Inline-TVF die Parametereinbettung anwendet. Wenn Sie also eine Konstante wie N'dbo.T2' als Eingabe übergeben, ersetzt der Inlining-Prozess alle Verweise auf @WhichTable vor der Optimierung durch die Konstante . Der Eliminierungsprozess kann dann die Verweise auf T1 und T3 aus dem anfänglichen Abfragebaum entfernen, und somit führt die Abfrageoptimierung zu einem Plan, der nur auf T2 verweist. Lassen Sie uns diese Idee mit der folgenden Abfrage testen:
SELECT * FROM dbo.OneTable(N'dbo.T2');
Der Plan für diese Abfrage ist in Abbildung 1 dargestellt.
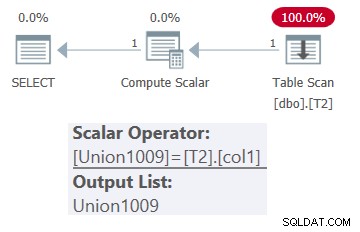 Abbildung 1:Plan für dbo.OneTable mit konstanter Eingabe
Abbildung 1:Plan für dbo.OneTable mit konstanter Eingabe
Wie Sie sehen können, erscheint nur Tabelle T2 im Plan.
Die Dinge sind etwas kniffliger, wenn Sie eine Nichtkonstante als Eingabe übergeben. Dies kann der Fall sein, wenn eine Variable, ein Prozedurparameter oder eine Spalte über APPLY übergeben wird. Der Eingabewert ist entweder zum Zeitpunkt der Kompilierung unbekannt, oder das Wiederverwendungspotenzial des parametrisierten Plans muss berücksichtigt werden.
Der Optimierer kann keine der Tabellen aus dem Plan entfernen, aber er hat immer noch einen Trick. Es kann Startfilteroperatoren über den Teilbäumen verwenden, die auf die Tabellen zugreifen, und nur den relevanten Teilbaum basierend auf dem Laufzeitwert von @WhichTable ausführen. Verwenden Sie den folgenden Code, um diese Strategie zu testen:
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
Der Plan für diese Ausführung ist in Abbildung 2 dargestellt:
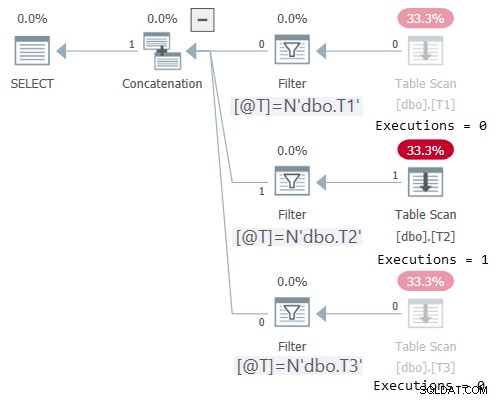 Abbildung 2:Plan für dbo.OneTable mit nicht konstanter Eingabe
Abbildung 2:Plan für dbo.OneTable mit nicht konstanter Eingabe
Der Plan-Explorer macht auf wunderbare Weise deutlich, dass nur der zutreffende Teilbaum ausgeführt wurde (Ausführungen =1), und graut die Teilbäume aus, die nicht ausgeführt wurden (Ausführungen =0). Außerdem zeigt STATISTICS IO E/A-Informationen nur für die Tabelle, auf die zugegriffen wurde:
Tabelle 'T2'. Scan-Anzahl 1, logische Lesevorgänge 1, physische Lesevorgänge 0, Page-Server-Lesungen 0, Read-Ahead-Lesungen 0, Page-Server-Read-Ahead-Lesungen 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Page-Server-Lesungen 0, Lob-Read- Ahead liest 0, Read-Ahead des Lob-Page-Servers liest 0.Anwenden der Eliminierungslogik für horizontale Einheiten auf die Zahlenreihenherausforderung
Wie bereits erwähnt, können Sie das Konzept der horizontalen Einheiteneliminierung anwenden, indem Sie eine der früheren Lösungen ändern, die derzeit die vertikale Eliminierungslogik verwenden. Als Ausgangspunkt für mein Beispiel verwende ich die Funktion dbo.GetNumsAlanCharlieItzikBatch.
Erinnern Sie sich, dass Joe Obbish die horizontale Einheiteneliminierung verwendet hat, um die relevanten disjunkten Teilbereiche der Zahlenreihe zu extrahieren. Wir werden das Konzept verwenden, um die weniger aufwendige Berechnung (rn) mit @low =1 von der teureren Berechnung (n) mit @low <> 1.
horizontal zu trennenWenn wir schon dabei sind, können wir experimentieren, indem wir Jeff Modens Idee in seine fnTally-Funktion einfügen, wo er eine Sentinel-Zeile mit dem Wert 0 für Fälle verwendet, in denen der Bereich mit @low =0 beginnt.
Wir haben also vier horizontale Einheiten:
- Sentinel-Zeile mit 0, wobei @low =0, mit n =0
- TOP (@high) Zeilen, wobei @low =0, mit billig n =rownum und op =@high – rownum
- TOP (@high) Zeilen, wobei @low =1, mit billig n =rownum und op =@high + 1 – rownum
- TOP(@high – @low + 1) Zeilen, wobei @low <> 0 AND @low <> 1, mit teurer n =@low – 1 + rownum, und op =@high + 1 – rownum
Diese Lösung kombiniert Ideen von Alan, Charlie, Joe, Jeff und mir, daher nennen wir die Batch-Modus-Version der Funktion dbo.GetNumsAlanCharlieJoeJeffItzikBatch.
Denken Sie zunächst daran, sicherzustellen, dass die Dummy-Tabelle dbo.BatchMe noch vorhanden ist, um die Stapelverarbeitung in unserer Lösung zu erhalten, oder verwenden Sie den folgenden Code, wenn dies nicht der Fall ist:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Hier ist der Code mit der Definition der Funktion dbo.GetNumsAlanCharlieJoeJeffItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Wichtig:Das Konzept der horizontalen Einheitseliminierung ist zweifellos komplexer zu implementieren als das vertikale, also warum sich die Mühe machen? Weil es dem Benutzer die Verantwortung nimmt, die richtige Spalte auszuwählen. Der Benutzer muss sich nur um die Abfrage einer Spalte namens n kümmern, anstatt sich daran zu erinnern, rn zu verwenden, wenn der Bereich mit 1 beginnt, und sonst n.
Beginnen wir damit, die Lösung mit den konstanten Eingaben 1 und 100.000.000 zu testen und nach dem zu ordnenden Ergebnis zu fragen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Der Plan für diese Ausführung ist in Abbildung 3 dargestellt.
 Abbildung 3:Plan für dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Abbildung 3:Plan für dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Beachten Sie, dass die einzige zurückgegebene Spalte auf dem direkten, nicht manipulierten Ausdruck ROW_NUMBER (Expr1313) basiert. Beachten Sie auch, dass der Plan nicht sortiert werden muss.
Ich habe die folgende Zeitstatistik für diese Ausführung:
CPU-Zeit =7359 ms, verstrichene Zeit =7354 ms.Die Laufzeit spiegelt die Tatsache angemessen wider, dass der Plan den Stapelmodus, den nicht manipulierten ROW_NUMBER-Ausdruck und keine Sortierung verwendet.
Als nächstes testen Sie die Funktion mit dem Konstantenbereich 0 bis 99.999.999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Der Plan für diese Ausführung ist in Abbildung 4 dargestellt.
 Abbildung 4:Plan für dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Abbildung 4:Plan für dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Der Plan verwendet einen Merge Join (Concatenation)-Operator, um die Sentinel-Zeile mit dem Wert 0 und dem Rest zusammenzuführen. Obwohl der zweite Teil so effizient wie zuvor ist, nimmt die Zusammenführungslogik einen ziemlich großen Tribut von etwa 26 % der Laufzeit in Anspruch, was zu den folgenden Zeitstatistiken führt:
CPU-Zeit =9265 ms, verstrichene Zeit =9298 ms.Testen wir die Funktion mit dem konstanten Bereich 2 bis 100.000.001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Der Plan für diese Ausführung ist in Abbildung 5 dargestellt.
 Abbildung 5:Plan für dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Abbildung 5:Plan für dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Diesmal gibt es keine teure Zusammenführungslogik, da der Sentinel-Zeilenteil irrelevant ist. Beachten Sie jedoch, dass die zurückgegebene Spalte der manipulierte Ausdruck @low – 1 + rownum ist, der nach dem Einbetten/Inlining von Parametern und dem konstanten Falten zu 1 + rownum wurde.
Hier sind die Zeitstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU-Zeit =9000 ms, verstrichene Zeit =9015 ms.Dies ist erwartungsgemäß nicht so schnell wie bei einem Bereich, der mit 1 beginnt, aber interessanterweise schneller als bei einem Bereich, der mit 0 beginnt.
Entfernen der 0-Sentinel-Zeile
Angesichts der Tatsache, dass die Technik mit der Sentinel-Zeile mit dem Wert 0 langsamer zu sein scheint als die Manipulation von rownum, ist es sinnvoll, sie einfach zu vermeiden. Dies bringt uns zu einer vereinfachten horizontalen Eliminierungslösung, die die Ideen von Alan, Charlie, Joe und mir vermischt. Ich nenne die Funktion mit dieser Lösung dbo.GetNumsAlanCharlieJoeItzikBatch. Hier ist die Definition der Funktion:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO Testen wir es mit dem Bereich 1 bis 100 M:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Der Plan ist wie erwartet derselbe wie der zuvor in Abbildung 3 gezeigte.
Dementsprechend habe ich die folgenden Zeitstatistiken erhalten:
CPU-Zeit =7219 ms, verstrichene Zeit =7243 ms.Testen Sie es mit dem Bereich 0 bis 99.999.999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Dieses Mal erhalten Sie denselben Plan wie zuvor in Abbildung 5 – nicht Abbildung 4.
Hier sind die Zeitstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU-Zeit =9313 ms, verstrichene Zeit =9334 ms.Testen Sie es mit dem Bereich 2 bis 100.000.001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Auch hier erhalten Sie denselben Plan wie zuvor in Abbildung 5.
Ich habe die folgenden Zeitstatistiken für diese Ausführung:
CPU-Zeit =9125 ms, verstrichene Zeit =9148 ms.Warnhinweise bei der Verwendung nicht konstanter Eingaben
Sowohl mit der vertikalen als auch mit der horizontalen Einheitseliminierungstechnik funktioniert alles ideal, solange Sie Konstanten als Eingaben übergeben. Sie müssen sich jedoch der Einschränkungen bewusst sein, die zu Leistungseinbußen führen können, wenn Sie nicht konstante Eingaben übergeben. Die Eliminierungstechnik für vertikale Einheiten hat weniger Probleme, und die Probleme, die es gibt, sind leichter zu bewältigen, also fangen wir damit an.
Denken Sie daran, dass wir in diesem Artikel die Funktion dbo.GetNumsAlanCharlieItzikBatch als unser Beispiel verwendet haben, das auf dem Eliminierungskonzept für vertikale Einheiten beruht. Lassen Sie uns eine Reihe von Tests mit nicht konstanten Eingaben wie Variablen ausführen.
Als ersten Test geben wir rn zurück und fragen nach den von rn geordneten Daten:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Denken Sie daran, dass rn den nicht manipulierten ROW_NUMBER-Ausdruck darstellt, sodass die Tatsache, dass wir nicht konstante Eingaben verwenden, in diesem Fall keine besondere Bedeutung hat. Eine explizite Sortierung im Plan ist nicht erforderlich.
Ich habe die folgenden Zeitstatistiken für diese Hinrichtung:
CPU-Zeit =7390 ms, verstrichene Zeit =7386 ms.Diese Zahlen stellen den Idealfall dar.
Ordnen Sie im nächsten Test die Ergebniszeilen nach n:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Der Plan für diese Ausführung ist in Abbildung 6 dargestellt.
 Abbildung 6:Plan für dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) Sortieren nach n
Abbildung 6:Plan für dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) Sortieren nach n
Sehen Sie das Problem? Nach dem Inlining wurde @low durch @mylow ersetzt – nicht durch den Wert in @mylow, der 1 ist. Folglich fand keine konstante Faltung statt, und daher ist n nicht ordnungserhaltend in Bezug auf rownum. Dies führte zu einer expliziten Sortierung im Plan.
Hier sind die Zeitstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU-Zeit =25141 ms, verstrichene Zeit =25628 ms.Die Ausführungszeit hat sich im Vergleich zu einer Zeit, in der keine explizite Sortierung erforderlich war, fast verdreifacht.
Eine einfache Problemumgehung besteht darin, die ursprüngliche Idee von Alan Burstein zu verwenden, immer nach rn zu sortieren, wenn Sie das sortierte Ergebnis benötigen, sowohl bei der Rückgabe von rn als auch bei der Rückgabe von n, wie folgt:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Diesmal gibt es keine explizite Sortierung im Plan.
Ich habe die folgenden Zeitstatistiken für diese Ausführung:
CPU-Zeit =9156 ms, verstrichene Zeit =9184 ms.Die Zahlen spiegeln angemessen wider, dass Sie den manipulierten Ausdruck zurückgeben, aber keine explizite Sortierung vornehmen.
Bei Lösungen, die auf der horizontalen Einheiteneliminierungstechnik basieren, wie z. B. unserer Funktion dbo.GetNumsAlanCharlieJoeItzikBatch, ist die Situation komplizierter, wenn nicht konstante Eingaben verwendet werden.
Testen wir die Funktion zunächst mit einem sehr kleinen Bereich von 10 Zahlen:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Der Plan für diese Ausführung ist in Abbildung 7 dargestellt.
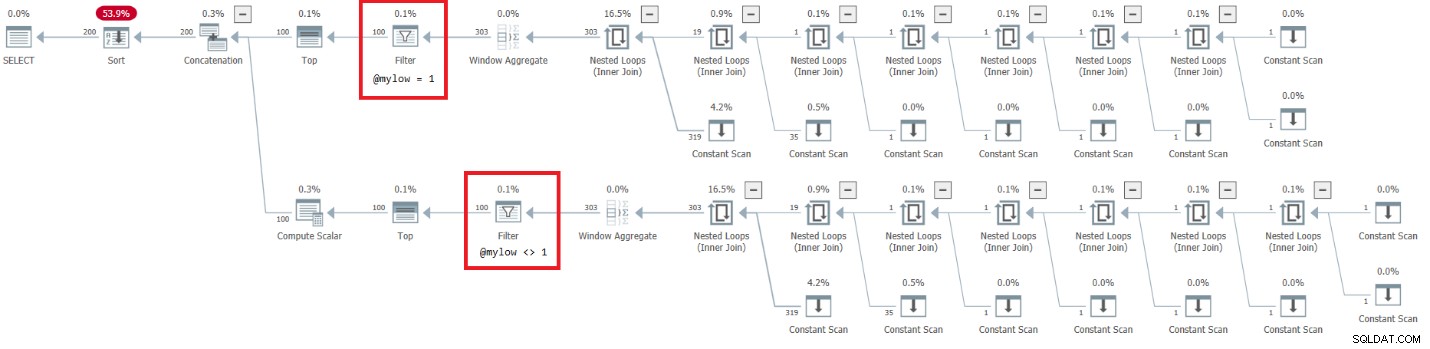 Abbildung 7:Plan für dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Abbildung 7:Plan für dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Dieser Plan hat eine sehr alarmierende Seite. Beachten Sie, dass die Filteroperatoren unten erscheinen die Top-Operatoren! Bei jedem gegebenen Aufruf der Funktion mit nicht konstanten Eingaben wird natürlich einer der Zweige unter dem Concatenation-Operator immer eine falsche Filterbedingung haben. Beide Top-Operatoren fragen jedoch nach einer Anzahl von Zeilen ungleich Null. Der Top-Operator über dem Operator mit der falschen Filterbedingung fragt also nach Zeilen und wird niemals zufrieden sein, da der Filteroperator weiterhin alle Zeilen verwirft, die er von seinem untergeordneten Knoten erhält. Die Arbeit im Unterbaum unterhalb des Filteroperators muss vollständig ausgeführt werden. In unserem Fall bedeutet dies, dass der Teilbaum die Arbeit der Generierung von 4B-Zeilen durchläuft, die der Filter-Operator verwirft. Sie fragen sich, warum sich der Filteroperator die Mühe macht, Zeilen von seinem untergeordneten Knoten anzufordern, aber es scheint, dass er derzeit so funktioniert. Mit einem statischen Plan ist dies schwer zu erkennen. Es ist einfacher, dies beispielsweise mit der Live-Abfrageausführungsoption in SentryOne Plan Explorer zu sehen, wie in Abbildung 8 gezeigt. Probieren Sie es aus.
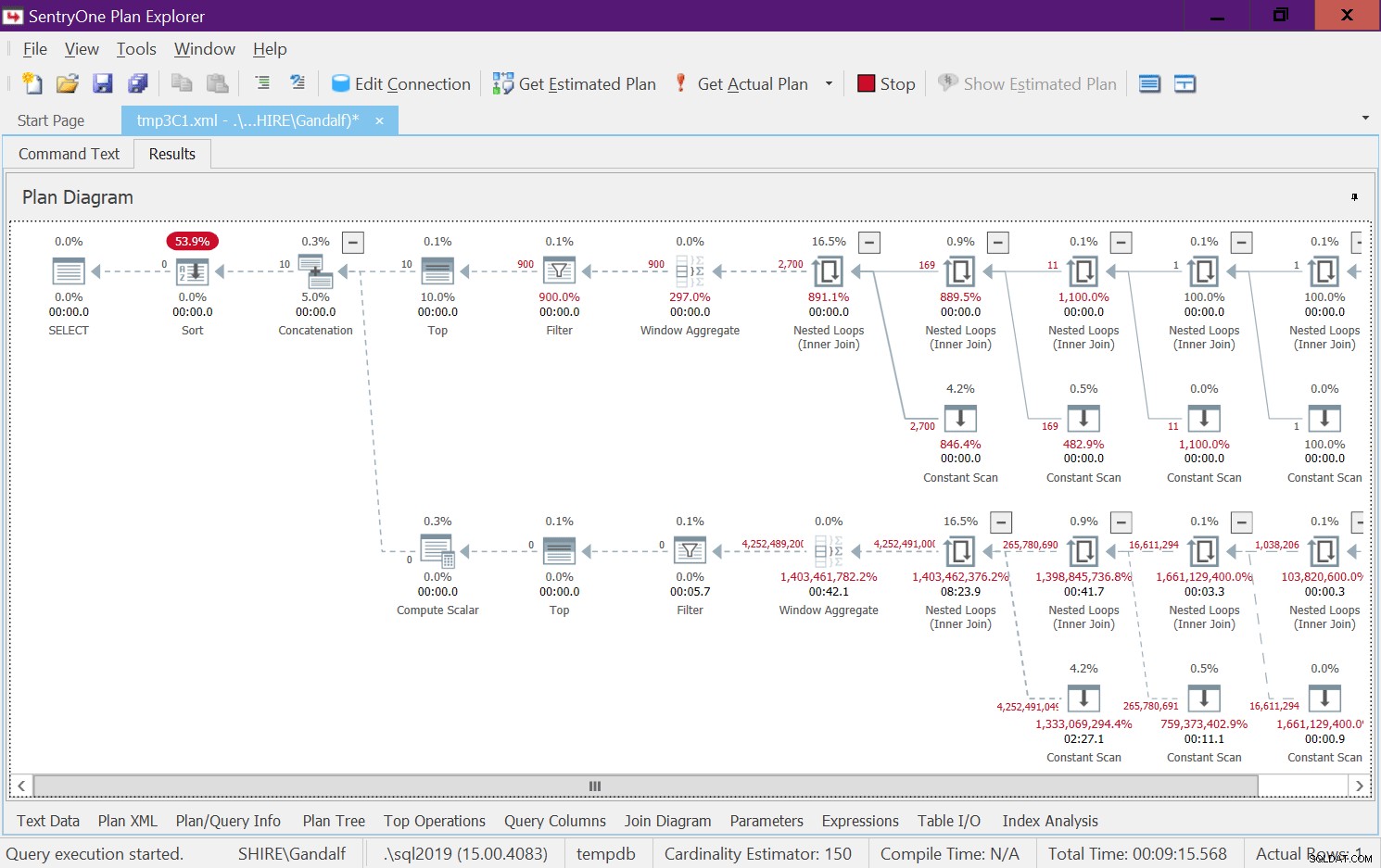 Abbildung 8:Live-Abfragestatistiken für dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Abbildung 8:Live-Abfragestatistiken für dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Es dauerte 9:15 Minuten, bis dieser Test auf meinem Computer abgeschlossen war, und denken Sie daran, dass die Anforderung darin bestand, einen Bereich von 10 Nummern zurückzugeben.
Lassen Sie uns überlegen, ob es eine Möglichkeit gibt, die vollständige Aktivierung des irrelevanten Teilbaums zu vermeiden. Um dies zu erreichen, möchten Sie, dass die Startfilteroperatoren oben angezeigt werden die Top-Operatoren statt darunter. Wenn Sie Grundlagen von Tabellenausdrücken, Teil 4 – Abgeleitete Tabellen, Überlegungen zur Optimierung, Fortsetzung gelesen haben, wissen Sie, dass ein TOP-Filter das Aufheben der Verschachtelung von Tabellenausdrücken verhindert. Sie müssen also nur die TOP-Abfrage in einer abgeleiteten Tabelle platzieren und den Filter in einer äußeren Abfrage auf die abgeleitete Tabelle anwenden.
Hier ist unsere modifizierte Funktion, die diesen Trick implementiert:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO Wie erwartet verhalten sich Ausführungen mit Konstanten genauso wie ohne den Trick.
Bei nicht konstanten Eingängen ist es jetzt mit kleinen Bereichen sehr schnell. Hier ist ein Test mit einem Bereich von 10 Zahlen:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Der Plan für diese Ausführung ist in Abbildung 9 dargestellt.
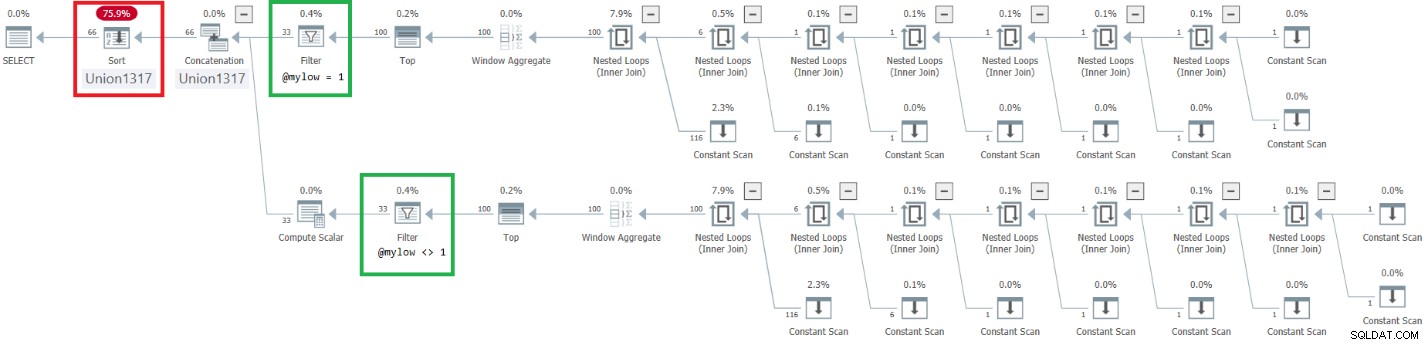 Abbildung 9:Plan für verbessertes dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Abbildung 9:Plan für verbessertes dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Beachten Sie, dass der gewünschte Effekt der Platzierung der Filter-Operatoren über den Top-Operatoren erreicht wurde. Die Sortierspalte n wird jedoch als Ergebnis einer Manipulation behandelt und daher in Bezug auf rownum nicht als reihenfolgeerhaltende Spalte betrachtet. Folglich gibt es eine explizite Sortierung im Plan.
Testen Sie die Funktion mit einem großen Bereich von 100 Millionen Nummern:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Ich habe die folgenden Zeitstatistiken:
CPU-Zeit =29907 ms, verstrichene Zeit =29909 ms.Ach wie schade; es war fast perfekt!
Leistungszusammenfassung und Einblicke
Abbildung 10 enthält eine Zusammenfassung der Zeitstatistiken für die verschiedenen Lösungen.
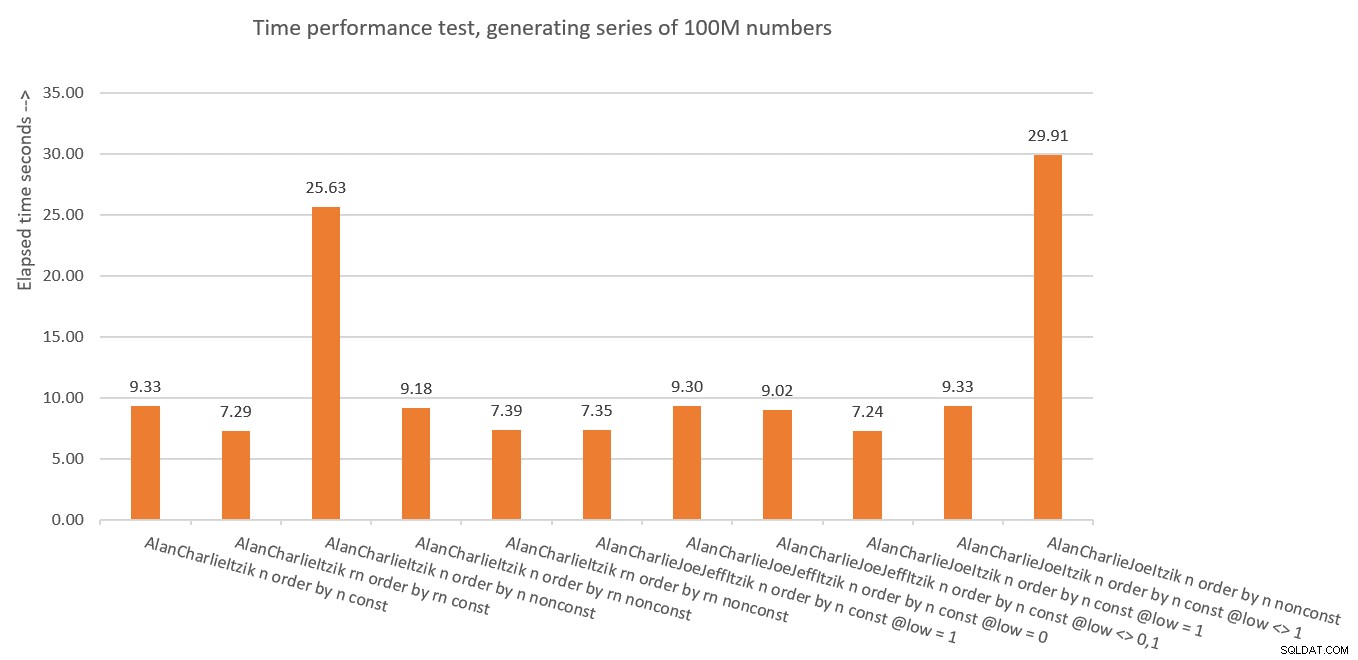 Abbildung 10:Zusammenfassung der Zeitleistung von Lösungen
Abbildung 10:Zusammenfassung der Zeitleistung von Lösungen
Was haben wir also aus all dem gelernt? Ich schätze, es nicht noch einmal zu tun! Ich mache nur Spaß. Wir haben gelernt, dass es sicherer ist, das vertikale Eliminierungskonzept wie in dbo.GetNumsAlanCharlieItzikBatch zu verwenden, das sowohl das nicht manipulierte ROW_NUMBER-Ergebnis (rn) als auch das manipulierte (n) verfügbar macht. Stellen Sie nur sicher, dass Sie, wenn Sie das Ergebnis geordnet zurückgeben müssen, immer nach rn sortieren, egal ob Sie rn oder n zurückgeben.
Wenn Sie absolut sicher sind, dass Ihre Lösung immer mit Konstanten als Eingaben verwendet wird, können Sie das Konzept der horizontalen Einheiteneliminierung verwenden. Dies führt zu einer intuitiveren Lösung für den Benutzer, da er mit einer Spalte für die aufsteigenden Werte interagiert. Ich würde trotzdem vorschlagen, den Trick mit den abgeleiteten Tabellen zu verwenden, um ein Aufheben der Verschachtelung zu verhindern, und die Filteroperatoren über den Top-Operatoren zu platzieren, wenn die Funktion jemals mit nicht konstanten Eingaben verwendet wird, nur um auf der sicheren Seite zu sein.
Wir sind immer noch nicht fertig. Nächsten Monat werde ich weiter nach weiteren Lösungen suchen.