Dies ist der dreizehnte und letzte Teil einer Reihe über Tabellenausdrücke. Diesen Monat setze ich die Diskussion fort, die ich letzten Monat über Inline-Tabellenwertfunktionen (iTVFs) begonnen habe.
Letzten Monat habe ich erklärt, dass SQL Server standardmäßig Parametereinbettungsoptimierung anwendet, wenn iTVFs eingebunden werden, die mit Konstanten als Eingaben abgefragt werden. Parametereinbettung bedeutet, dass SQL Server Parameterreferenzen in der Abfrage durch die literalen Konstantenwerte aus der aktuellen Ausführung ersetzt und dann der Code mit den Konstanten optimiert wird. Dieser Prozess ermöglicht Vereinfachungen, die zu optimaleren Abfrageplänen führen können. Diesen Monat gehe ich näher auf das Thema ein und behandle spezielle Fälle für solche Vereinfachungen wie konstantes Falten und dynamisches Filtern und Ordnen. Wenn Sie eine Auffrischung zur Optimierung der Parametereinbettung benötigen, lesen Sie den Artikel vom letzten Monat sowie Paul Whites ausgezeichneten Artikel Parameter Sniffing, Embedding, and the RECOMPILE Options.
In meinen Beispielen verwende ich eine Beispieldatenbank namens TSQLV5. Sie finden das Skript, das es erstellt und füllt, hier und sein ER-Diagramm hier.
Konstantes Falten
Während der frühen Phasen der Abfrageverarbeitung wertet SQL Server bestimmte Ausdrücke mit Konstanten aus und faltet diese zu den Ergebniskonstanten. Beispielsweise kann der Ausdruck 40 + 2 auf die Konstante 42 gefaltet werden. Die Regeln für faltbare und nicht faltbare Ausdrücke finden Sie hier unter „Konstante Faltung und Ausdrucksauswertung.“
Interessant in Bezug auf iTVFs ist, dass dank der Optimierung der Parametereinbettung Abfragen mit iTVFs, bei denen Sie Konstanten als Eingaben übergeben, unter den richtigen Umständen von einer konstanten Faltung profitieren können. Die Kenntnis der Regeln für faltbare und nicht faltbare Ausdrücke kann sich auf die Art und Weise auswirken, wie Sie Ihre iTVFs implementieren. In einigen Fällen können Sie durch Anwenden sehr subtiler Änderungen an Ihren Ausdrücken optimalere Pläne mit besserer Nutzung der Indizierung ermöglichen.
Betrachten Sie als Beispiel die folgende Implementierung eines iTVF namens Sales.MyOrders:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Führen Sie die folgende Abfrage mit iTVF aus (ich bezeichne dies als Abfrage 1):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Der Plan für Abfrage 1 ist in Abbildung 1 dargestellt.
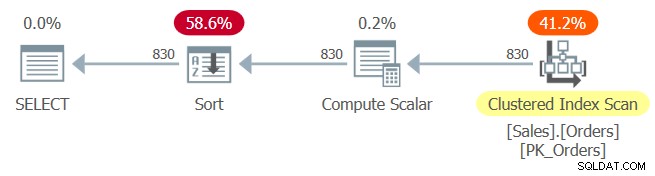 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Der Clustered-Index PK_Orders wird mit orderid als Schlüssel definiert. Hätte hier nach der Parametereinbettung eine konstante Faltung stattgefunden, wäre der Ordnungsausdruck orderid + 1 – 10248 zu orderid – 10247 gefaltet worden. Dieser Ausdruck wäre in Bezug auf orderid als ordnungserhaltender Ausdruck betrachtet worden und hätte als solcher die ermöglicht Optimierer, um sich auf die Indexreihenfolge zu verlassen. Leider ist das nicht der Fall, wie der explizite Sort-Operator im Plan zeigt. Also was ist passiert?
Konstante Zollstöcke sind heikel. Der Ausdruck Spalte1 + Konstante1 – Konstante2 wird für konstante Faltungszwecke von links nach rechts ausgewertet. Der erste Teil, Spalte1 + Konstante1, wird nicht gefaltet. Nennen wir diesen Ausdruck1. Der nächste ausgewertete Teil wird als Ausdruck1 – Konstante2 behandelt, der ebenfalls nicht gefaltet wird. Ohne Faltung wird ein Ausdruck in der Form Spalte1 + Konstante1 – Konstante2 nicht als ordnungserhaltend in Bezug auf Spalte1 angesehen und kann sich daher nicht auf die Indexreihenfolge verlassen, selbst wenn Sie einen unterstützenden Index für Spalte1 haben. Ebenso ist der Ausdruck Konstante1 + Spalte1 – Konstante2 nicht konstant faltbar. Der Ausdruck Konstante1 – Konstante2 + Spalte1 ist jedoch faltbar. Genauer gesagt wird der erste Teil Konstante1 – Konstante2 zu einer einzigen Konstante gefaltet (nennen wir sie Konstante3), was zu dem Ausdruck Konstante3 + Spalte1 führt. Dieser Ausdruck wird in Bezug auf Spalte1 als ordnungserhaltender Ausdruck betrachtet. Solange Sie also sicherstellen, dass Sie Ihren Ausdruck in der letzten Form schreiben, können Sie dem Optimierer ermöglichen, sich auf die Indexreihenfolge zu verlassen.
Betrachten Sie die folgenden Abfragen (ich bezeichne sie als Abfrage 2, Abfrage 3 und Abfrage 4), und sehen Sie, bevor Sie sich die Abfragepläne ansehen, ob Sie erkennen können, welche eine explizite Sortierung im Plan beinhalten und welche nicht:
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
Untersuchen Sie nun die Pläne für diese Abfragen, wie in Abbildung 2 gezeigt.
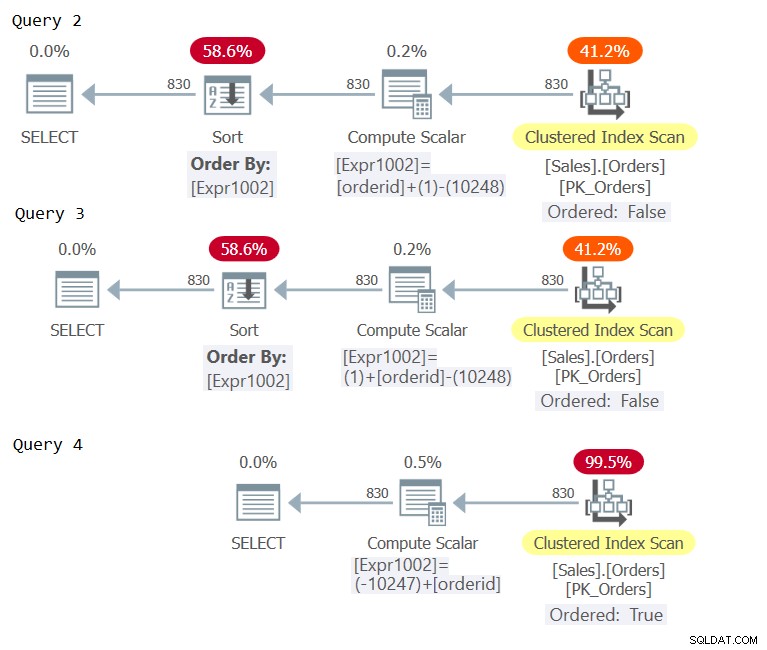 Abbildung 2:Pläne für Abfrage 2, Abfrage 3 und Abfrage 4
Abbildung 2:Pläne für Abfrage 2, Abfrage 3 und Abfrage 4
Untersuchen Sie die Compute Scalar-Operatoren in den drei Plänen. Nur der Plan für Abfrage 4 erforderte eine konstante Faltung, was zu einem Sortierungsausdruck führte, der in Bezug auf orderid als reihenfolgeerhaltend angesehen wird und eine explizite Sortierung vermeidet.
Wenn Sie diesen Aspekt der konstanten Faltung verstehen, können Sie das iTVF leicht reparieren, indem Sie den Ausdruck orderid + @add – @subtract in @add – @subtract + orderid ändern, etwa so:
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Fragen Sie die Funktion erneut ab (ich bezeichne dies als Abfrage 5):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Der Plan für diese Abfrage ist in Abbildung 3 dargestellt.
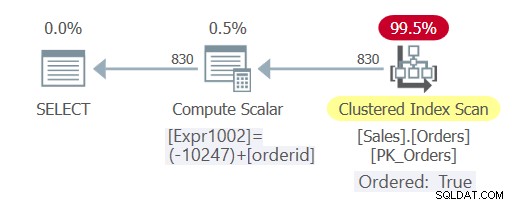 Abbildung 3:Plan für Abfrage 5
Abbildung 3:Plan für Abfrage 5
Wie Sie sehen, erfuhr die Abfrage dieses Mal eine konstante Faltung, und der Optimierer konnte sich auf die Indexreihenfolge verlassen und eine explizite Sortierung vermeiden.
Ich habe ein einfaches Beispiel verwendet, um diese Optimierungstechnik zu demonstrieren, und daher mag es ein wenig gekünstelt erscheinen. Eine praktische Anwendung dieser Technik finden Sie im Artikel Nummernserien-Generator-Challenge-Lösungen – Teil 1.
Dynamisches Filtern/Ordnen
Letzten Monat habe ich den Unterschied zwischen der Art und Weise behandelt, wie SQL Server eine Abfrage in einem iTVF im Vergleich zu derselben Abfrage in einer gespeicherten Prozedur optimiert. SQL Server wendet in der Regel standardmäßig Parametereinbettungsoptimierung für eine Abfrage an, die ein iTVF mit Konstanten als Eingaben umfasst, optimiert jedoch die parametrisierte Form einer Abfrage in einer gespeicherten Prozedur. Wenn Sie jedoch OPTION(RECOMPILE) zur Abfrage in der gespeicherten Prozedur hinzufügen, wendet SQL Server in diesem Fall in der Regel auch die Parametereinbettungsoptimierung an. Zu den Vorteilen im iTVF-Fall gehört die Tatsache, dass Sie es in eine Abfrage einbeziehen können, und solange Sie sich wiederholende konstante Eingaben übergeben, besteht die Möglichkeit, einen zuvor zwischengespeicherten Plan wiederzuverwenden. Mit einer gespeicherten Prozedur können Sie sie nicht in eine Abfrage einbeziehen, und wenn Sie OPTION(RECOMPILE) hinzufügen, um eine Optimierung der Parametereinbettung zu erhalten, gibt es keine Möglichkeit zur Wiederverwendung des Plans. Die gespeicherte Prozedur ermöglicht viel mehr Flexibilität in Bezug auf die Codeelemente, die Sie verwenden können.
Sehen wir uns an, wie sich all dies in einer klassischen Aufgabe zum Einbetten und Ordnen von Parametern auswirkt. Es folgt eine vereinfachte gespeicherte Prozedur, die eine dynamische Filterung und Sortierung anwendet, ähnlich der, die Paul in seinem Artikel verwendet hat:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
Beachten Sie, dass die aktuelle Implementierung der gespeicherten Prozedur OPTION(RECOMPILE) nicht in die Abfrage einschließt.
Betrachten Sie die folgende Ausführung der gespeicherten Prozedur:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Der Plan für diese Ausführung ist in Abbildung 4 dargestellt.
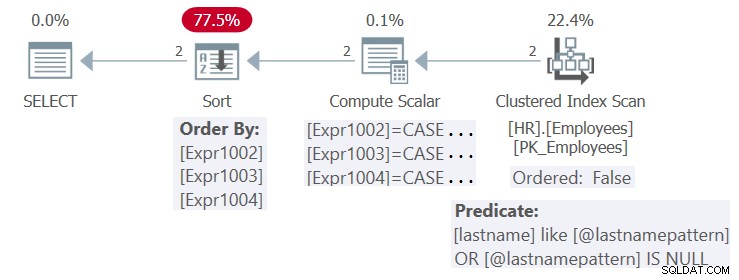 Abbildung 4:Plan für Prozedur HR.GetEmpsP
Abbildung 4:Plan für Prozedur HR.GetEmpsP
Für die Spalte „Nachname“ ist ein Index definiert. Theoretisch könnte der Index mit den aktuellen Eingaben sowohl für die Filterung (mit einer Suche) als auch für die Sortierung (mit einem geordneten:True-Range-Scan) der Abfrage von Vorteil sein. Da SQL Server jedoch standardmäßig die parametrisierte Form der Abfrage optimiert und keine Parametereinbettung anwendet, wendet es nicht die Vereinfachungen an, die erforderlich sind, um den Index sowohl für Filter- als auch für Sortierzwecke nutzen zu können. Der Plan ist also wiederverwendbar, aber nicht optimal.
Um zu sehen, wie sich die Dinge mit der Optimierung der Parametereinbettung ändern, ändern Sie die Abfrage der gespeicherten Prozedur, indem Sie OPTION(RECOMPILE) wie folgt hinzufügen:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
Führen Sie die gespeicherte Prozedur erneut mit denselben Eingaben aus, die Sie zuvor verwendet haben:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Der Plan für diese Ausführung ist in Abbildung 5 dargestellt.
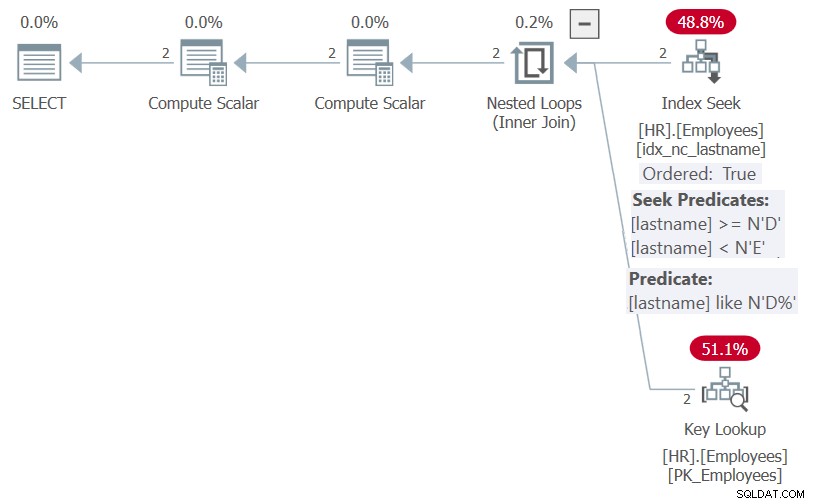 Abbildung 5:Plan für Prozedur HR.GetEmpsP mit OPTION(RECOMPILE)
Abbildung 5:Plan für Prozedur HR.GetEmpsP mit OPTION(RECOMPILE)
Wie Sie sehen können, war SQL Server dank der Optimierung der Parametereinbettung in der Lage, das Filterprädikat auf das sargbare Prädikat lastname LIKE N'D%' und die Sortierliste auf NULL, NULL, lastname zu vereinfachen. Beide Elemente könnten vom Index auf lastname profitieren, daher zeigt der Plan eine Suche im Index und keine explizite Sortierung.
Theoretisch erwarten Sie eine ähnliche Vereinfachung, wenn Sie die Abfrage in einem iTVF implementieren, und damit ähnliche Optimierungsvorteile, aber mit der Möglichkeit, zwischengespeicherte Pläne wiederzuverwenden, wenn dieselben Eingabewerte wiederverwendet werden. Versuchen wir es also...
Hier ist ein Versuch, dieselbe Abfrage in einem iTVF zu implementieren (diesen Code noch nicht ausführen):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO Können Sie ein Problem mit dieser Implementierung erkennen, bevor Sie versuchen, diesen Code auszuführen? Denken Sie daran, dass ich zu Beginn dieser Serie erklärt habe, dass ein Tabellenausdruck eine Tabelle ist. Der Körper einer Tabelle ist eine Menge (oder Multimenge) von Zeilen und hat als solche keine Reihenfolge. Daher kann eine als Tabellenausdruck verwendete Abfrage normalerweise keine ORDER BY-Klausel haben. Wenn Sie versuchen, diesen Code auszuführen, erhalten Sie tatsächlich die folgende Fehlermeldung:
Msg 1033, Level 15, State 1, Procedure GetEmps, Line 16 [Batch Start Line 128]Die ORDER BY-Klausel ist in Ansichten, Inline-Funktionen, abgeleiteten Tabellen, Unterabfragen und allgemeinen Tabellenausdrücken ungültig, außer TOP, OFFSET oder FOR XML ist ebenfalls angegeben.
Sicher, wie der Fehler sagt, macht SQL Server eine Ausnahme, wenn Sie ein Filterelement wie TOP oder OFFSET-FETCH verwenden, das sich auf die ORDER BY-Klausel stützt, um den Sortieraspekt des Filters zu definieren. Aber selbst wenn Sie dank dieser Ausnahme eine ORDER BY-Klausel in die innere Abfrage aufnehmen, erhalten Sie immer noch keine Garantie für die Reihenfolge des Ergebnisses in einer äußeren Abfrage gegen den Tabellenausdruck, es sei denn, es gibt eine eigene ORDER BY-Klausel .
Wenn Sie die Abfrage trotzdem in einem iTVF implementieren möchten, können Sie die innere Abfrage den dynamischen Filterteil behandeln lassen, aber nicht die dynamische Reihenfolge, wie folgt:
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
Natürlich können Sie die äußere Abfrage alle spezifischen Bestellanforderungen behandeln lassen, wie im folgenden Code (ich bezeichne dies als Abfrage 6):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
Der Plan für diese Abfrage ist in Abbildung 6 dargestellt.
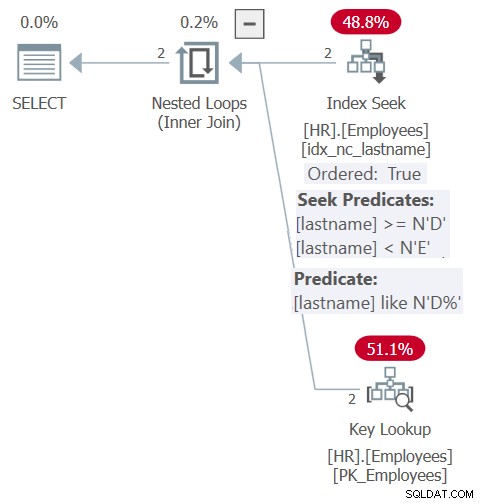 Abbildung 6:Plan für Abfrage 6
Abbildung 6:Plan für Abfrage 6
Dank Inlining und Parametereinbettung ähnelt der Plan dem, der zuvor für die Abfrage der gespeicherten Prozedur in Abbildung 5 gezeigt wurde. Der Plan stützt sich sowohl zum Filtern als auch zum Sortieren effizient auf den Index. Sie erhalten jedoch nicht die Flexibilität der dynamischen Sortiereingabe wie bei der gespeicherten Prozedur. Sie müssen die Reihenfolge in der ORDER BY-Klausel in der Abfrage für die Funktion explizit angeben.
Das folgende Beispiel hat eine Abfrage für die Funktion ohne Filter- und Sortieranforderungen (ich werde dies als Abfrage 7 bezeichnen):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
Der Plan für diese Abfrage ist in Abbildung 7 dargestellt.
 Abbildung 7:Plan für Abfrage 7
Abbildung 7:Plan für Abfrage 7
Nach dem Inlining und der Parametereinbettung wird die Abfrage vereinfacht, sodass sie kein Filterprädikat und keine Sortierung aufweist, und wird mit einem vollständigen ungeordneten Scan des Clustered-Index optimiert.
Fragen Sie schließlich die Funktion mit N'D%' als Filtermuster für den Nachnamen der Eingabe ab und sortieren Sie das Ergebnis nach der Spalte Vorname (ich bezeichne dies als Abfrage 8):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
Der Plan für diese Abfrage ist in Abbildung 8 dargestellt.
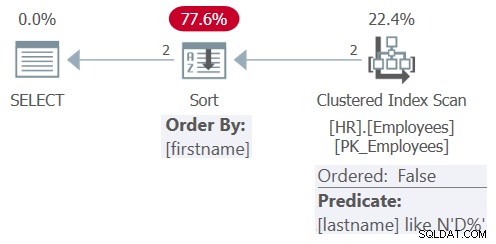 Abbildung 8:Plan für Abfrage 8
Abbildung 8:Plan für Abfrage 8
Nach der Vereinfachung umfasst die Abfrage nur das Filterprädikat lastname LIKE N'D%' und das Sortierelement firstname. Dieses Mal entscheidet sich der Optimierer für einen ungeordneten Scan des Clustered-Index mit dem Restprädikat lastname LIKE N'D%', gefolgt von einer expliziten Sortierung. Es hat sich entschieden, keine Suche im Index auf lastname anzuwenden, da der Index kein abdeckender Index ist, die Tabelle so klein ist und die Indexreihenfolge für die aktuellen Anforderungen an die Abfragereihenfolge nicht vorteilhaft ist. Außerdem ist kein Index für die firstname-Spalte definiert, daher muss ohnehin eine explizite Sortierung angewendet werden.
Schlussfolgerung
Die Standardparameter-Einbettungsoptimierung von iTVFs kann auch zu einer konstanten Faltung führen, was optimalere Pläne ermöglicht. Sie müssen jedoch die konstanten Faltregeln beachten, um zu bestimmen, wie Sie Ihre Ausdrücke am besten formulieren.
Das Implementieren von Logik in einem iTVF hat Vor- und Nachteile im Vergleich zum Implementieren von Logik in einer gespeicherten Prozedur. Wenn Sie nicht an Parametereinbettungsoptimierung interessiert sind, kann die standardmäßig parametrisierte Abfrageoptimierung gespeicherter Prozeduren zu einem optimaleren Plan-Caching und Wiederverwendungsverhalten führen. In Fällen, in denen Sie an Parameter-Embedding-Optimierung interessiert sind, erhalten Sie diese normalerweise standardmäßig mit iTVFs. Um diese Optimierung mit gespeicherten Prozeduren zu erhalten, müssen Sie die RECOMPILE-Abfrageoption hinzufügen, aber dann erhalten Sie keine Wiederverwendung des Plans. Zumindest mit iTVFs können Sie Pläne wiederverwenden, sofern dieselben Parameterwerte wiederholt werden. Andererseits haben Sie weniger Flexibilität bei den Abfrageelementen, die Sie in einem iTVF verwenden können. Sie dürfen beispielsweise keine ORDER BY-Klausel für Präsentationen haben.
Zurück zur gesamten Serie über Tabellenausdrücke:Ich finde das Thema für Datenbankpraktiker super wichtig. Die vollständigere Reihe umfasst die Unterreihe des Zahlenreihengenerators, der als iTVF implementiert ist. Insgesamt umfasst die Serie die folgenden 19 Teile:
- Grundlagen von Tabellenausdrücken, Teil 1
- Grundlagen von Tabellenausdrücken, Teil 2 – Abgeleitete Tabellen, logische Überlegungen
- Grundlagen von Tabellenausdrücken, Teil 3 – Abgeleitete Tabellen, Überlegungen zur Optimierung
- Grundlagen von Tabellenausdrücken, Teil 4 – Abgeleitete Tabellen, Überlegungen zur Optimierung, Fortsetzung
- Grundlagen von Tabellenausdrücken, Teil 5 – CTEs, logische Überlegungen
- Grundlagen von Tabellenausdrücken, Teil 6 – Rekursive CTEs
- Grundlagen von Tabellenausdrücken, Teil 7 – CTEs, Überlegungen zur Optimierung
- Grundlagen von Tabellenausdrücken, Teil 8 – CTEs, Optimierungsüberlegungen fortgesetzt
- Grundlagen von Tabellenausdrücken, Teil 9 – Ansichten im Vergleich zu abgeleiteten Tabellen und CTEs
- Grundlagen von Tabellenausdrücken, Teil 10 – Ansichten, SELECT * und DDL-Änderungen
- Grundlagen von Tabellenausdrücken, Teil 11 – Ansichten, Modifikationsüberlegungen
- Grundlagen von Tabellenausdrücken, Teil 12 – Inline-Tabellenwertfunktionen
- Grundlagen von Tabellenausdrücken, Teil 13 – Inline-Tabellenwertfunktionen, Fortsetzung
- Die Herausforderung ist eröffnet! Community-Aufruf zur Erstellung des schnellsten Zahlenreihengenerators
- Lösungen für Herausforderungen beim Zahlenreihengenerator – Teil 1
- Lösungen für Herausforderungen beim Zahlenreihengenerator – Teil 2
- Lösungen für Herausforderungen beim Zahlenreihengenerator – Teil 3
- Lösungen für Herausforderungen beim Zahlenreihengenerator – Teil 4
- Lösungen für Herausforderungen beim Zahlenreihengenerator – Teil 5