Zuerst eingeführt in SQL Server 2017 Enterprise Edition, ein adaptiver Join ermöglicht einen Laufzeitübergang von einem Batchmodus-Hash-Join zu einem korrelierten verschachtelten Loops-indizierten Join (Anwenden) zur Laufzeit im Zeilenmodus. Der Kürze halber beziehe ich mich auf einen „indizierten Join mit korrelierten verschachtelten Schleifen“ als Anwenden im Rest dieses Artikels. Wenn Sie eine Auffrischung zum Unterschied zwischen verschachtelten Schleifen und Anwendung benötigen, lesen Sie bitte meinen vorherigen Artikel.
Ob ein adaptiver Join von einem Hash-Join zur Laufzeit übergeht, hängt von einem Wert mit der Bezeichnung Adaptive Threshold Rows ab auf der Adaptiven Verknüpfung Ausführungsplanbetreiber. Dieser Artikel zeigt, wie ein adaptiver Join funktioniert, enthält Details zur Schwellenwertberechnung und behandelt die Auswirkungen einiger getroffener Designentscheidungen.
Einführung
Eine Sache, die Sie in diesem Artikel immer im Hinterkopf behalten sollten, ist eine adaptive Verknüpfung immer beginnt mit der Ausführung als Batch-Modus-Hash-Join. Dies gilt auch dann, wenn der Ausführungsplan angibt, dass der adaptive Join voraussichtlich im Zeilenmodus ausgeführt wird.
Wie jeder Hash-Join liest ein adaptiver Join alle Zeilen, die in seiner Build-Eingabe verfügbar sind, und kopiert die erforderlichen Daten in eine Hash-Tabelle. Die Hash-Join-Variante im Stapelmodus speichert diese Zeilen in einem optimierten Format und partitioniert sie mithilfe einer oder mehrerer Hash-Funktionen. Sobald die Build-Eingabe verbraucht wurde, ist die Hash-Tabelle vollständig ausgefüllt und partitioniert, bereit für den Hash-Join, um mit der Überprüfung der probeseitigen Zeilen auf Übereinstimmungen zu beginnen.
Dies ist der Punkt, an dem ein adaptiver Join die Entscheidung trifft, mit dem Hash-Join im Stapelmodus fortzufahren oder in einen Zeilenmodus überzugehen. Wenn die Anzahl der Zeilen in der Hash-Tabelle kleiner als der Schwellenwert ist Wert wechselt der Join zu apply; Andernfalls wird der Join als Hash-Join fortgesetzt, indem mit dem Lesen von Zeilen aus der Sondeneingabe begonnen wird.
Wenn ein Übergang zu einem Apply-Join auftritt, liest der Ausführungsplan die Zeilen nicht erneut, die zum Füllen der Hash-Tabelle verwendet werden, um den Apply-Vorgang zu steuern. Stattdessen eine interne Komponente, die als adaptiver Pufferleser bekannt ist erweitert die bereits in der Hash-Tabelle gespeicherten Zeilen und stellt sie bei Bedarf für die äußere Eingabe des Apply-Operators zur Verfügung. Der adaptive Pufferleser ist mit Kosten verbunden, die jedoch viel geringer sind als die Kosten für das vollständige Zurückspulen der Build-Eingabe.
Auswählen eines adaptiven Joins
Die Abfrageoptimierung umfasst eine oder mehrere Phasen der logischen Untersuchung und der physischen Implementierung von Alternativen. In jeder Phase, in der der Optimierer die physischen Optionen für einen logischen untersucht join, kann es sowohl Batch-Modus-Hash-Join als auch Row-Modus-Apply-Alternativen in Betracht ziehen.
Wenn eine dieser physischen Join-Optionen Teil der billigsten Lösung ist, die in der aktuellen Phase gefunden wurde – und der andere Join-Typ kann die gleichen erforderlichen logischen Eigenschaften liefern – der Optimierer markiert die logische Join-Gruppe als potenziell geeignet für eine adaptive Verbindung. Wenn nicht, endet die Berücksichtigung eines adaptiven Joins hier (und es wird kein erweitertes Ereignis für adaptive Joins ausgelöst).
Der normale Betrieb des Optimierers bedeutet, dass die billigste gefundene Lösung nur eine der physischen Join-Optionen enthält – entweder Hash oder Apply, je nachdem, was die niedrigsten geschätzten Kosten hatte. Als Nächstes erstellt der Optimierer eine neue Implementierung des Join-Typs, der keinen war als billigste ausgewählt.
Da die aktuelle Optimierungsphase bereits mit einer gefundenen günstigsten Lösung beendet ist, wird für den adaptiven Join eine spezielle Einzelgruppen-Explorations- und Implementierungsrunde durchgeführt. Schließlich berechnet der Optimierer den adaptiven Schwellenwert .
Wenn eine der vorherigen Arbeiten nicht erfolgreich ist, wird das erweiterte Ereignis adaptive_join_skipped mit einem Grund ausgelöst.
Wenn die adaptive Join-Verarbeitung erfolgreich ist, wird ein Concat Der Operator wird dem internen Plan über dem Hash hinzugefügt und wendet Alternativen mit dem adaptiven Pufferleser und allen erforderlichen Batch-/Zeilenmodusadaptern an. Denken Sie daran, dass nur eine der Join-Alternativen zur Laufzeit ausgeführt wird, abhängig von der Anzahl der tatsächlich gefundenen Zeilen im Vergleich zum adaptiven Schwellenwert.
Das Concat Operator und individuelle Hash/Apply-Alternativen werden normalerweise nicht im endgültigen Ausführungsplan angezeigt. Stattdessen wird uns ein einzelner Adaptive Join angezeigt Operator. Dies ist nur eine Präsentationsentscheidung – der Concat und Joins sind immer noch im Code vorhanden, der von der SQL Server-Ausführungsengine ausgeführt wird. Weitere Einzelheiten dazu finden Sie im Anhang und in den Abschnitten zum Thema "Weiterführende Literatur" dieses Artikels.
Der adaptive Schwellenwert
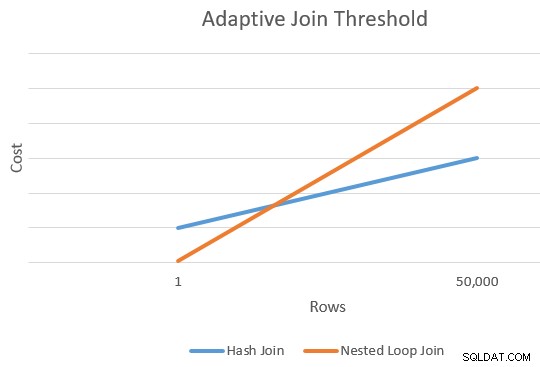
Ein Anwenden ist im Allgemeinen billiger als ein Hash-Join für eine kleinere Anzahl von Fahrzeilen. Der Hash-Join hat zusätzliche Startkosten zum Erstellen seiner Hash-Tabelle, aber niedrigere Kosten pro Zeile, wenn er beginnt, nach Übereinstimmungen zu suchen.
Es gibt im Allgemeinen einen Punkt, an dem die geschätzten Kosten für eine Anwendung und einen Hash-Join gleich sind. Diese Idee wurde von Joe Sack in seinem Artikel Introducing Batch Mode Adaptive Joins:
schön veranschaulicht
Schwellenwert berechnen
An diesem Punkt hat der Optimierer eine einzige Schätzung für die Anzahl der Zeilen, die in die Build-Eingabe des Hash-Joins eingehen, und wendet Alternativen an. Es hat auch die geschätzten Kosten des Hash und wendet die Operatoren als Ganzes an.
Dies gibt uns einen einzigen Punkt am äußersten rechten Rand der orangefarbenen und blauen Linien im obigen Diagramm. Der Optimierer benötigt für jeden Join-Typ einen anderen Bezugspunkt, damit er „die Linien zeichnen“ und den Schnittpunkt finden kann (er zeichnet nicht buchstäblich Linien, aber Sie verstehen die Idee).
Um einen zweiten Punkt für die Linien zu finden, fordert der Optimierer die beiden Joins auf, eine neue Kostenschätzung basierend auf einer anderen (und hypothetischen) Eingabekardinalität zu erstellen. Wenn die erste Kardinalitätsschätzung mehr als 100 Zeilen umfasste, werden die Joins aufgefordert, neue Kosten für eine Zeile zu schätzen. Wenn die ursprüngliche Kardinalität kleiner oder gleich 100 Zeilen war, basiert der zweite Punkt auf einer Eingabekardinalität von 10.000 Zeilen (also gibt es einen ausreichenden Bereich zum Extrapolieren).
In jedem Fall sind das Ergebnis zwei unterschiedliche Kosten und Zeilenzahlen für jeden Join-Typ, sodass die Linien „gezeichnet“ werden können.
Die Schnittpunktformel
Das Finden des Schnittpunkts zweier Linien basierend auf zwei Punkten für jede Linie ist ein Problem bei mehreren wohlbekannten Lösungen. SQL Server verwendet eine auf Determinanten basierende wie auf Wikipedia beschrieben:
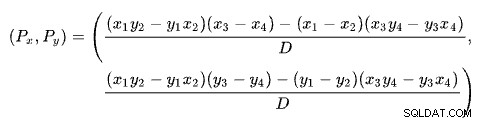
wo:
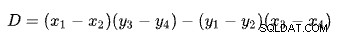
Die erste Linie wird durch die Punkte (x1 , y1 ) und (x2 , y2 ). Die zweite Linie wird durch die Punkte (x3 , y3 ) und (x4 , y4 ). Der Schnittpunkt ist bei (Px , Py ).
Unser Schema hat die Anzahl der Zeilen auf der x-Achse und die geschätzten Kosten auf der y-Achse. Uns interessiert die Anzahl der Zeilen, in denen sich die Linien schneiden. Dies ergibt sich aus der Formel für Px . Wenn wir die geschätzten Kosten an der Kreuzung wissen wollten, wäre dies Py .
Für Px Zeilen, wären die geschätzten Kosten der Apply- und Hash-Join-Lösungen gleich. Das ist der adaptive Schwellenwert, den wir brauchen.
Ein funktionierendes Beispiel
Hier ist ein Beispiel, bei dem die AdventureWorks 2017-Beispieldatenbank und der folgende Indexierungstrick von Itzik Ben-Gan verwendet werden, um eine bedingungslose Berücksichtigung der Batchmodus-Ausführung zu erhalten:
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
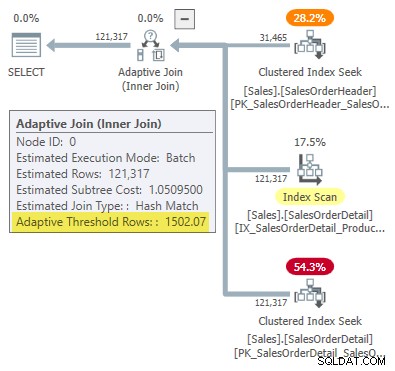
WHERE SOH.SalesOrderID <= 75123; Der Ausführungsplan zeigt einen adaptiven Join mit einem Schwellenwert von 1502,07 Zeilen:
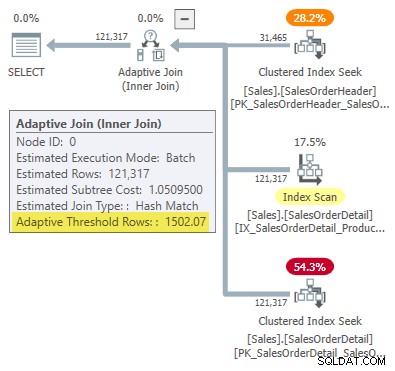
Die geschätzte Anzahl der Zeilen, die den adaptiven Join steuern, beträgt 31.465 .
Beitrittskosten
In diesem vereinfachten Fall können wir geschätzte Teilbaumkosten für den Hash finden und mithilfe von Hinweisen Join-Alternativen anwenden:
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
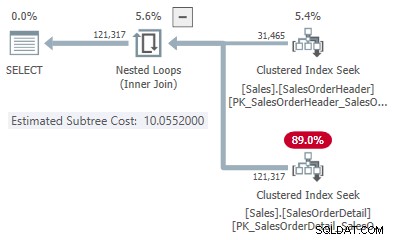
Dies gibt uns einen Punkt auf der Linie für jeden Join-Typ:
- 31.465 Zeilen
- Hash-Kosten 1,05083
- Bewerbungskosten 10,0552
Der zweite Punkt auf der Linie
Da die geschätzte Anzahl von Zeilen mehr als 100 beträgt, stammen die zweiten Referenzpunkte aus speziellen internen Schätzungen, die auf einer Join-Eingabezeile basieren. Leider gibt es keine einfache Möglichkeit, die genauen Kostenzahlen für diese interne Berechnung zu erhalten (darüber werde ich in Kürze mehr sprechen).
Im Moment zeige ich Ihnen nur die Kostenzahlen (unter Verwendung der vollen internen Genauigkeit und nicht der sechs signifikanten Zahlen in Ausführungsplänen):
- Eine Zeile (interne Berechnung)
- Hash-Kosten 0,999027422729
- Anwendbare Kosten 0,547927305023
- 31.465 Zeilen
- Hash-Kosten 1,05082787359
- Anwendbare Kosten 10.0552890166
Wie erwartet ist der Apply-Join für eine kleine Eingabekardinalität billiger als der Hash, aber viel teurer für die erwartete Kardinalität von 31.465 Zeilen.
Die Schnittpunktberechnung
Wenn Sie diese Kardinalitäts- und Kostenzahlen in die Linienschnittpunktformel einsetzen, erhalten Sie Folgendes:
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 Auf sechs signifikante Stellen gerundet entspricht dieses Ergebnis dem 1502,07 Zeilen, die im Ausführungsplan für adaptive Joins angezeigt werden:
Fehler oder Design?
Denken Sie daran, dass SQL Server vier Punkte benötigt, um die Zeilenanzahl im Vergleich zu den Kostenlinien zu „zeichnen“, um den adaptiven Join-Schwellenwert zu finden. Im vorliegenden Fall bedeutet dies, Kostenschätzungen für die einzeilige und die 31.465-zeilige Kardinalität sowohl für die Anwendungs- als auch für die Hash-Join-Implementierung zu finden.
Der Optimierer ruft eine Routine namens sqllang!CuNewJoinEstimate auf um diese vier Kosten für einen adaptiven Join zu berechnen. Leider gibt es keine Trace-Flags oder erweiterte Ereignisse, die einen praktischen Überblick über diese Aktivität bieten. Die normalen Trace-Flags, die verwendet werden, um das Verhalten des Optimierers zu untersuchen und Kosten anzuzeigen, funktionieren hier nicht (siehe Anhang, wenn Sie an weiteren Details interessiert sind).
Die einzige Möglichkeit, die einzeiligen Kostenschätzungen zu erhalten, besteht darin, einen Debugger anzufügen und nach dem vierten Aufruf von CuNewJoinEstimate einen Haltepunkt festzulegen im Code für sqllang!CardSolveForSwitch . Ich habe WinDbg verwendet, um diese Aufrufliste auf SQL Server 2019 CU12 abzurufen:

An diesem Punkt im Code werden Gleitkommakosten mit doppelter Genauigkeit in vier Speicherorten gespeichert, auf die durch Adressen bei rsp+b0 verwiesen wird , rsp+d0 , rsp+30 , und rsp+28 (wobei rsp ist ein CPU-Register und Offsets sind hexadezimal):

Die angezeigten Kostenzahlen des Operator-Teilbaums stimmen mit denen überein, die in der Berechnungsformel für den adaptiven Join-Schwellenwert verwendet werden.
Über diese einzeiligen Kostenschätzungen
Sie haben vielleicht bemerkt, dass die geschätzten Teilbaumkosten für die einzeiligen Joins für den Arbeitsaufwand, der mit dem Verbinden einer Zeile verbunden ist, recht hoch erscheinen:
- Eine Zeile
- Hash-Kosten 0,999027422729
- Anwendbare Kosten 0,547927305023
Wenn Sie versuchen, einzeilige Eingabeausführungspläne für den Hash-Join zu erstellen und Beispiele anzuwenden, werden Sie viel sehen niedrigere geschätzte Teilbaumkosten an der Verbindung als die oben gezeigten. Ebenso führt die Ausführung der ursprünglichen Abfrage mit einem Zeilenziel von 1 (oder der Anzahl der Join-Ausgabezeilen, die für eine Eingabe von einer Zeile erwartet werden) auch zu geschätzten Weg-Kosten niedriger als angezeigt.
Der Grund ist die CuNewJoinEstimate Routine schätzt die Einzeile Fall in einer Weise, die die meisten Menschen meiner Meinung nach nicht intuitiv finden würden.
Die endgültigen Kosten setzen sich aus drei Hauptkomponenten zusammen:
- Die Build-Input-Subtree-Kosten
- Die lokalen Kosten des Joins
- Die Kosten für den Teilbaum der Sondeneingabe
Die Punkte 2 und 3 hängen von der Art der Verbindung ab. Bei einem Hash-Join berücksichtigen sie die Kosten für das Lesen aller Zeilen aus der Sondeneingabe, das Abgleichen (oder nicht) mit der einen Zeile in der Hash-Tabelle und das Weitergeben der Ergebnisse an den nächsten Operator. Bei einer Anwendung decken die Kosten eine Suche in der unteren Eingabe für den Join, die internen Kosten des Joins selbst und die Rückgabe der übereinstimmenden Zeilen an den übergeordneten Operator ab.
Nichts davon ist ungewöhnlich oder überraschend.
Die Kostenüberraschung
Die Überraschung kommt auf der Build-Seite des Joins (Element 1 in der Liste). Man könnte erwarten, dass der Optimierer eine ausgefallene Berechnung durchführt, um die bereits berechneten Teilbaumkosten für 31.465 Zeilen auf eine durchschnittliche Zeile herunterzuskalieren, oder so ähnlich.
Tatsächlich verwenden sowohl Hash- als auch Apply-Join-Schätzungen für eine Zeile einfach die gesamten Teilbaumkosten für das Original Kardinalitätsschätzung von 31.465 Zeilen. In unserem laufenden Beispiel ist dieser „Unterbaum“ die 0,54456 Kosten der Clustered-Index-Suche im Stapelmodus in der Header-Tabelle:
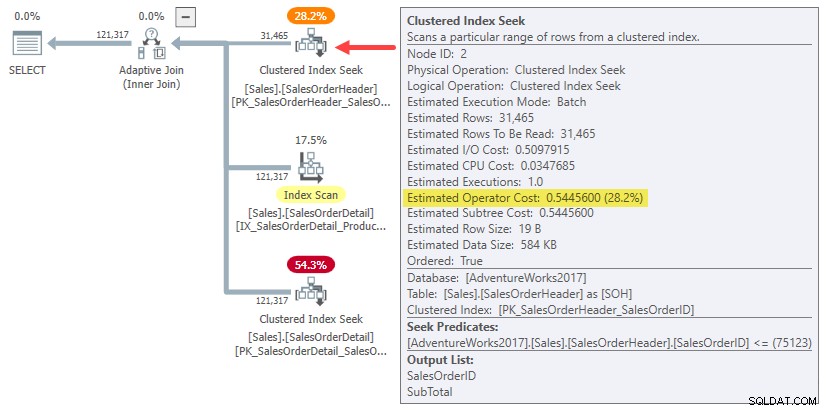
Um es klar zu sagen:Die geschätzten Kosten auf der Erstellungsseite für die einzeiligen Join-Alternativen verwenden Eingabekosten, die für 31.465 Zeilen berechnet wurden. Das sollte Ihnen etwas seltsam vorkommen.
Zur Erinnerung:Die von CuNewJoinEstimate berechneten Kosten für eine Zeile waren wie folgt:
- Eine Zeile
- Hash-Kosten 0,999027422729
- Anwendbare Kosten 0,547927305023
Sie können sehen, dass die Gesamtanwendungskosten (~0,54793) von 0,54456 dominiert werden Build-seitige Teilbaumkosten, mit einem winzigen zusätzlichen Betrag für die einzelne Suche auf der inneren Seite, die Verarbeitung der kleinen Anzahl der resultierenden Zeilen innerhalb des Joins und deren Weitergabe an den übergeordneten Operator.
Die geschätzten Kosten für einen Hash-Join für eine Zeile sind höher, da die Sondenseite des Plans aus einem vollständigen Indexscan besteht, bei dem alle resultierenden Zeilen den Join durchlaufen müssen. Die Gesamtkosten für den Hash-Join mit einer Zeile sind etwas niedriger als die ursprünglichen Kosten von 1,05095 für das Beispiel mit 31.465 Zeilen, da es jetzt nur noch eine Zeile in der Hash-Tabelle gibt.
Auswirkungen
Man würde erwarten, dass eine Join-Schätzung für eine Zeile teilweise auf den Kosten für die Lieferung einer Zeile an die treibende Join-Eingabe basiert. Wie wir gesehen haben, ist dies bei einem adaptiven Join nicht der Fall:Sowohl Apply- als auch Hash-Alternativen werden mit den vollen geschätzten Kosten für 31.465 Zeilen belastet. Der Rest des Joins kostet ungefähr so viel, wie man es für eine einzeilige Build-Eingabe erwarten würde.
Aufgrund dieser intuitiv seltsamen Anordnung ist es schwierig (möglicherweise unmöglich), einen Ausführungsplan zu zeigen, der die berechneten Kosten widerspiegelt. Wir müssten einen Plan erstellen, der 31.465 Zeilen an die obere Join-Eingabe liefert, aber den Join selbst und seine innere Eingabe so kostet, als ob nur eine Zeile vorhanden wäre. Eine schwierige Frage.
Der Effekt all dessen besteht darin, den Punkt ganz links in unserem Schnittliniendiagramm auf der y-Achse nach oben zu heben. Dies wirkt sich auf die Steigung der Geraden und damit auf den Schnittpunkt aus.
Ein weiterer praktischer Effekt besteht darin, dass der berechnete adaptive Join-Schwellenwert jetzt von der ursprünglichen Kardinalitätsschätzung bei der Hash-Build-Eingabe abhängt, wie von Joe Obbish in seinem Blogbeitrag von 2017 angemerkt. Zum Beispiel, wenn wir das WHERE ändern -Klausel in der Testabfrage zu SOH.SalesOrderID <= 55000 , wird der adaptive Schwellenwert reduziert von 1502.07 auf 1259.8, ohne den Abfrageplan-Hash zu ändern. Gleicher Plan, anderer Schwellenwert.
Dies liegt daran, dass, wie wir gesehen haben, die interne einzeilige Kostenschätzung von den Build-Eingabekosten abhängt für die ursprüngliche Kardinalitätsschätzung. Dies bedeutet, dass unterschiedliche anfängliche bauseitige Schätzungen der einzeiligen Schätzung einen unterschiedlichen „Boost“ auf der y-Achse verleihen. Die Linie hat wiederum eine andere Steigung und einen anderen Schnittpunkt.
Intuition würde vorschlagen, dass die einzeilige Schätzung für denselben Join immer den gleichen Wert ergeben sollte, unabhängig von der anderen Kardinalitätsschätzung auf der Linie (vorausgesetzt, der exakt gleiche Join mit denselben Eigenschaften und Zeilengrößen hat eine nahezu lineare Beziehung zwischen Driving Zeilen und Kosten). Dies ist bei einem adaptiven Join nicht der Fall.
Gewollt?
Ich kann Ihnen mit einiger Zuversicht sagen, was SQL Server macht bei der Berechnung des adaptiven Join-Schwellenwerts. Ich habe keine besonderen Erkenntnisse darüber, warum es macht es so.
Dennoch gibt es einige Gründe zu der Annahme, dass diese Anordnung beabsichtigt ist und nach reiflicher Überlegung und Rückmeldungen aus Tests zustande gekommen ist. Der Rest dieses Abschnitts behandelt einige meiner Gedanken zu diesem Aspekt.
Ein adaptiver Join ist keine direkte Wahl zwischen einem normalen Apply- und einem Hash-Join im Batch-Modus. Ein adaptiver Join beginnt immer mit dem vollständigen Auffüllen der Hash-Tabelle. Erst wenn diese Arbeit abgeschlossen ist, wird entschieden, ob auf eine Apply-Implementierung umgestellt wird oder nicht.
Zu diesem Zeitpunkt sind uns bereits potenziell erhebliche Kosten durch das Auffüllen und Partitionieren des Hash-Joins im Speicher entstanden. Dies spielt für den einzeiligen Fall möglicherweise keine große Rolle, wird jedoch mit zunehmender Kardinalität zunehmend wichtiger. Der unerwartete „Boost“ kann eine Möglichkeit sein, diese Realitäten in die Berechnung einzubeziehen und dabei einen angemessenen Rechenaufwand beizubehalten.
Das SQL Server-Kostenmodell war lange Zeit ein wenig voreingenommen gegenüber Joins mit verschachtelten Schleifen, wohl mit einer gewissen Berechtigung. Selbst der ideale indizierte Anwendungsfall kann in der Praxis langsam sein, wenn sich die benötigten Daten nicht bereits im Speicher befinden und das E/A-Subsystem nicht Flash ist, insbesondere bei einem etwas wahlfreien Zugriffsmuster. Begrenzte Speicherkapazitäten und langsame E/A-Vorgänge sind beispielsweise Benutzern von Cloud-basierten Datenbank-Engines der unteren Preisklasse nicht völlig unbekannt.
Es ist möglich, dass praktische Tests in solchen Umgebungen gezeigt haben, dass ein intuitiv berechneter adaptiver Join zu schnell für den Übergang zu einer Anwendung war. Theorie ist manchmal nur in der Theorie großartig.
Dennoch ist die aktuelle Situation nicht ideal; Das Zwischenspeichern eines Plans auf der Grundlage einer ungewöhnlich niedrigen Kardinalitätsschätzung führt dazu, dass ein adaptiver Join viel zögerlicher zu einer Anwendung wechselt, als dies bei einer größeren anfänglichen Schätzung der Fall gewesen wäre. Dies ist eine Variante des Problems der Parameterempfindlichkeit, aber für viele von uns wird es eine neue Überlegung dieser Art sein.
Jetzt ist es auch möglich Die Verwendung der Kosten des vollständigen Erstellungseingabe-Teilbaums für den am weitesten links liegenden Punkt der sich schneidenden Kostenlinien ist einfach ein nicht korrigierter Fehler oder ein Versehen. Mein Gefühl ist, dass die aktuelle Implementierung wahrscheinlich ein bewusster praktischer Kompromiss ist, aber Sie brauchen jemanden mit Zugang zu den Designdokumenten und dem Quellcode, um es sicher zu wissen.
Zusammenfassung
Eine adaptive Verknüpfung ermöglicht SQL Server den Übergang von einer Hash-Verknüpfung im Stapelmodus zu einer Anwendung, nachdem die Hash-Tabelle vollständig aufgefüllt wurde. Diese Entscheidung wird getroffen, indem die Anzahl der Zeilen in der Hash-Tabelle mit einem vorberechneten adaptiven Schwellenwert verglichen wird.
Der Schwellenwert wird berechnet, indem vorhergesagt wird, wo die Anwendbarkeit und die Hash-Join-Kosten gleich sind. Um diesen Punkt zu finden, erstellt SQL Server eine zweite interne Join-Kostenschätzung für eine andere Build-Eingabekardinalität – normalerweise eine Zeile.
Überraschenderweise enthalten die geschätzten Kosten für die einzeilige Schätzung die vollständigen aufbauseitigen Teilbaumkosten für die ursprüngliche Kardinalitätsschätzung (nicht auf eine Zeile skaliert). Das bedeutet, dass der Schwellenwert von der ursprünglichen Kardinalitätsschätzung an der Build-Eingabe abhängt.
Folglich kann ein adaptiver Join einen unerwartet niedrigen Schwellenwert haben, was bedeutet, dass der adaptive Join viel weniger wahrscheinlich von einem Hash-Join abweicht. Es ist unklar, ob dieses Verhalten beabsichtigt ist.
Verwandte Lektüre
- Einführung von Adaptive Joins im Stapelmodus von Joe Sack
- Adaptive Joins verstehen in der Produktdokumentation
- Adaptive Join Internals von Dima Pilugin
- Wie funktionieren adaptive Verknüpfungen im Stapelmodus? auf Database Administrators Stack Exchange von Erik Darling
- An Adaptive Join Regression von Joe Obbish
- Wenn Sie adaptive Verknüpfungen wünschen, benötigen Sie breitere Indizes und ist größer besser? von Erik Darling
- Parameter Sniffing:Adaptive Joins von Brent Ozar
- Fragen und Antworten zur intelligenten Abfrageverarbeitung von Joe Sack
Anhang
Dieser Abschnitt behandelt einige Aspekte der adaptiven Verknüpfung, die auf natürliche Weise nur schwer in den Haupttext aufgenommen werden konnten.
Der erweiterte adaptive Plan
Sie können versuchen, sich eine visuelle Darstellung des internen Plans mit dem undokumentierten Trace-Flag 9415 anzusehen, wie von Dima Pilugin in seinem oben verlinkten hervorragenden Artikel über adaptive Join-Interna bereitgestellt. Wenn dieses Flag aktiv ist, sieht der adaptive Join-Plan für unser laufendes Beispiel wie folgt aus:
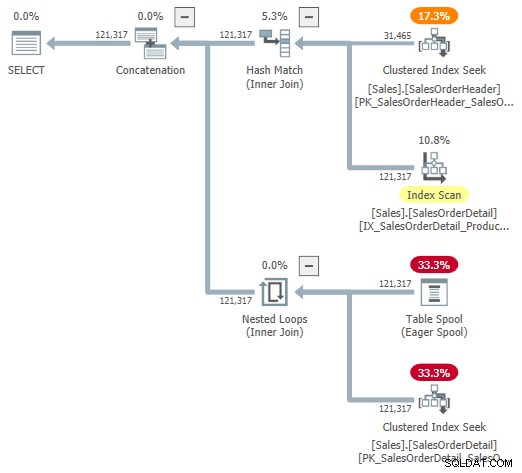
Dies ist eine nützliche Darstellung, um das Verständnis zu unterstützen, aber sie ist nicht ganz genau, vollständig oder konsistent. Beispielsweise existiert der Tabellen-Spool nicht – er ist eine Standarddarstellung für den adaptiven Pufferleser Lesen von Zeilen direkt aus der Batch-Modus-Hash-Tabelle.
Die Operatoreigenschaften und Kardinalitätsschätzungen sind auch ein bisschen überall. Die Ausgabe des adaptiven Pufferlesers („Spool“) sollte 31.465 Zeilen umfassen, nicht 121.317. Die Unterbaumkosten der Anwendung werden fälschlicherweise durch die Kosten des übergeordneten Operators begrenzt. Dies ist für Showplan normal, aber in einem adaptiven Join-Kontext macht es keinen Sinn.
Es gibt auch andere Inkonsistenzen – zu viele, um sie sinnvoll aufzulisten –, aber das kann bei nicht dokumentierten Trace-Flags passieren. Der oben gezeigte erweiterte Plan ist nicht für die Verwendung durch Endbenutzer gedacht, daher ist er vielleicht nicht ganz überraschend. Die Botschaft hier ist, sich nicht zu sehr auf die Zahlen und Eigenschaften zu verlassen, die in dieser undokumentierten Form angezeigt werden.
Ich sollte auch nebenbei erwähnen, dass der fertige standardmäßige adaptive Join-Plan-Operator nicht ganz ohne seine eigenen Konsistenzprobleme ist. Diese stammen so ziemlich ausschließlich aus den versteckten Details.
Beispielsweise stammen die angezeigten adaptiven Join-Eigenschaften aus einer Mischung der zugrunde liegenden Concat , Hash Join und Anwenden Betreiber. Sie können einen adaptiven Join sehen, der die Batchmodus-Ausführung für Joins mit verschachtelten Schleifen meldet (was unmöglich ist), und die angezeigte verstrichene Zeit wird tatsächlich aus dem verborgenen Concat kopiert , nicht der spezielle Join, der zur Laufzeit ausgeführt wurde.
Die üblichen Verdächtigen
Wir können Erhalten Sie einige nützliche Informationen von den Arten von undokumentierten Trace-Flags, die normalerweise verwendet werden, um die Ausgabe des Optimierers zu betrachten. Zum Beispiel:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); Ausgabe (aus Gründen der Lesbarkeit stark bearbeitet):
*** Ausgabebaum:***PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Cost=1.05095
- PhyOp_Concat (Stapel) Karte=121317 Kosten=1,05325
- PhyOp_HashJoinx_jtInner (Stapel) Karte=121317 Kosten=1,05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Kosten=0,54456
- PhyOp_Filter(Batch)-Karte=121317 Kosten=0,397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Kosten=0,338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Cost=10.0798
- PhyOp_Apply Card=121317 Kosten=10,0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Karte=31465 Kosten=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Kosten=0,54456 [** 3 **]
- PhyOp_Filter-Karte=3,85562 Kosten=9,00356
- PhyOp_Range Sales.SalesOrderDetail Card=3,85562 Kosten=8,94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Karte=31465 Kosten=0,544623
- PhyOp_Apply Card=121317 Kosten=10,0553
Dies gibt einen Einblick in die geschätzten Kosten für den Fall der vollen Kardinalität mit Hash und wendet Alternativen an, ohne separate Abfragen zu schreiben und Hinweise zu verwenden. Wie im Haupttext erwähnt, sind diese Trace-Flags innerhalb von CuNewJoinEstimate nicht wirksam , sodass wir die Wiederholungsberechnungen für den 31.465-Zeilen-Fall oder die Details für die einzeiligen Schätzungen auf diese Weise nicht direkt sehen können.
Join und Zeilenmodus-Hash-Join zusammenführen
Adaptive Joins bieten nur einen Übergang vom Hash-Join im Batch-Modus zum Row-Modus. Die Gründe, warum der Hash-Join im Zeilenmodus nicht unterstützt wird, finden Sie in den Fragen und Antworten zur intelligenten Abfrageverarbeitung im Abschnitt „Verwandte Literatur“. Kurz gesagt, es wird angenommen, dass Hash-Joins im Zeilenmodus zu anfällig für Leistungsregressionen sind.
Der Wechsel zu einem Merge-Join im Zeilenmodus wäre eine weitere Option, aber der Optimierer zieht dies derzeit nicht in Betracht. So wie ich es verstehe, ist es unwahrscheinlich, dass es in Zukunft in diese Richtung erweitert wird.
Einige der Überlegungen sind die gleichen wie beim Hash-Join im Zeilenmodus. Darüber hinaus sind Merge-Join-Pläne tendenziell weniger leicht mit Hash-Joins austauschbar, selbst wenn wir uns auf indizierte Merge-Joins beschränken (keine explizite Sortierung).
Es gibt auch einen viel größeren Unterschied zwischen Hash und Apply als zwischen Hash und Merge. Sowohl hash als auch merge eignen sich für größere Eingaben und apply eignet sich besser für kleinere treibende Eingaben. Merge-Join lässt sich nicht so einfach parallelisieren wie Hash-Join und skaliert nicht so gut mit zunehmender Thread-Anzahl.
Angesichts der Motivation für adaptive Verknüpfungen ist es, deutlich besser damit umzugehen variierende Eingabegrößen – und nur Hash-Join unterstützt die Batch-Modus-Verarbeitung – ist die Wahl zwischen Batch-Hash und Row-Apply die natürlichere. Schließlich würde das Vorhandensein von drei adaptiven Join-Optionen die Schwellenberechnung für einen möglicherweise geringen Gewinn erheblich verkomplizieren.