Als Systemadministratoren und Entwickler verbringen wir viel Zeit in einem Terminal. Also haben wir ClusterControl mit unserem Befehlszeilenschnittstellentool namens s9s auf das Terminal gebracht. s9s bietet eine einfache Schnittstelle zur ClusterControl RPC v2 API. Sie werden es sehr nützlich finden, wenn Sie mit umfangreichen Bereitstellungen arbeiten, da die CLI es Ihnen ermöglicht, komplexere Funktionen und Arbeitsabläufe zu entwerfen.
Dieser Blogbeitrag zeigt, wie man s9s verwendet, um die Verwaltung von Galera Cluster for MySQL oder MariaDB zu automatisieren, sowie eine einfache Master-Slave-Replikationseinrichtung.
Einrichtung
Installationsanweisungen für Ihr spezielles Betriebssystem finden Sie in der Dokumentation. Wichtig zu beachten ist, dass sich bei der Verwendung der neuesten s9s-Tools von GitHub die Art und Weise, wie Sie einen Benutzer erstellen, geringfügig ändert. Der folgende Befehl wird gut funktionieren:
s9s user --create --generate-key --controller="https://localhost:9501" dbaIm Allgemeinen sind zwei Schritte erforderlich, wenn Sie CLI lokal auf dem ClusterControl-Host konfigurieren möchten. Zuerst müssen Sie einen Benutzer erstellen und dann einige Änderungen in der Konfigurationsdatei vornehmen - alle Schritte sind in der Dokumentation enthalten.
Bereitstellung
Sobald die CLI korrekt konfiguriert wurde und SSH-Zugriff auf Ihre Zieldatenbankhosts hat, können Sie den Bereitstellungsprozess starten. Zum Zeitpunkt des Schreibens können Sie die CLI verwenden, um MySQL-, MariaDB- und PostgreSQL-Cluster bereitzustellen. Beginnen wir mit einem Beispiel für die Bereitstellung von Percona XtraDB Cluster 5.7. Dazu ist ein einziger Befehl erforderlich.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitDie letzte Option „--wait“ bedeutet, dass der Befehl wartet, bis der Job abgeschlossen ist, und seinen Fortschritt anzeigt. Sie können es überspringen, wenn Sie möchten - in diesem Fall kehrt der Befehl s9s sofort zur Shell zurück, nachdem er einen neuen Job in cmon registriert hat. Dies ist völlig in Ordnung, da cmon der Prozess ist, der den Job selbst erledigt. Sie können den Fortschritt eines Jobs jederzeit separat überprüfen, indem Sie Folgendes verwenden:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Schauen wir uns ein anderes Beispiel an. Dieses Mal erstellen wir einen neuen Cluster, MySQL-Replikation:einfaches Master-Slave-Paar. Auch hier genügt ein einziger Befehl:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdWir können jetzt überprüfen, ob beide Cluster betriebsbereit sind:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2All das ist natürlich auch über die GUI sichtbar:
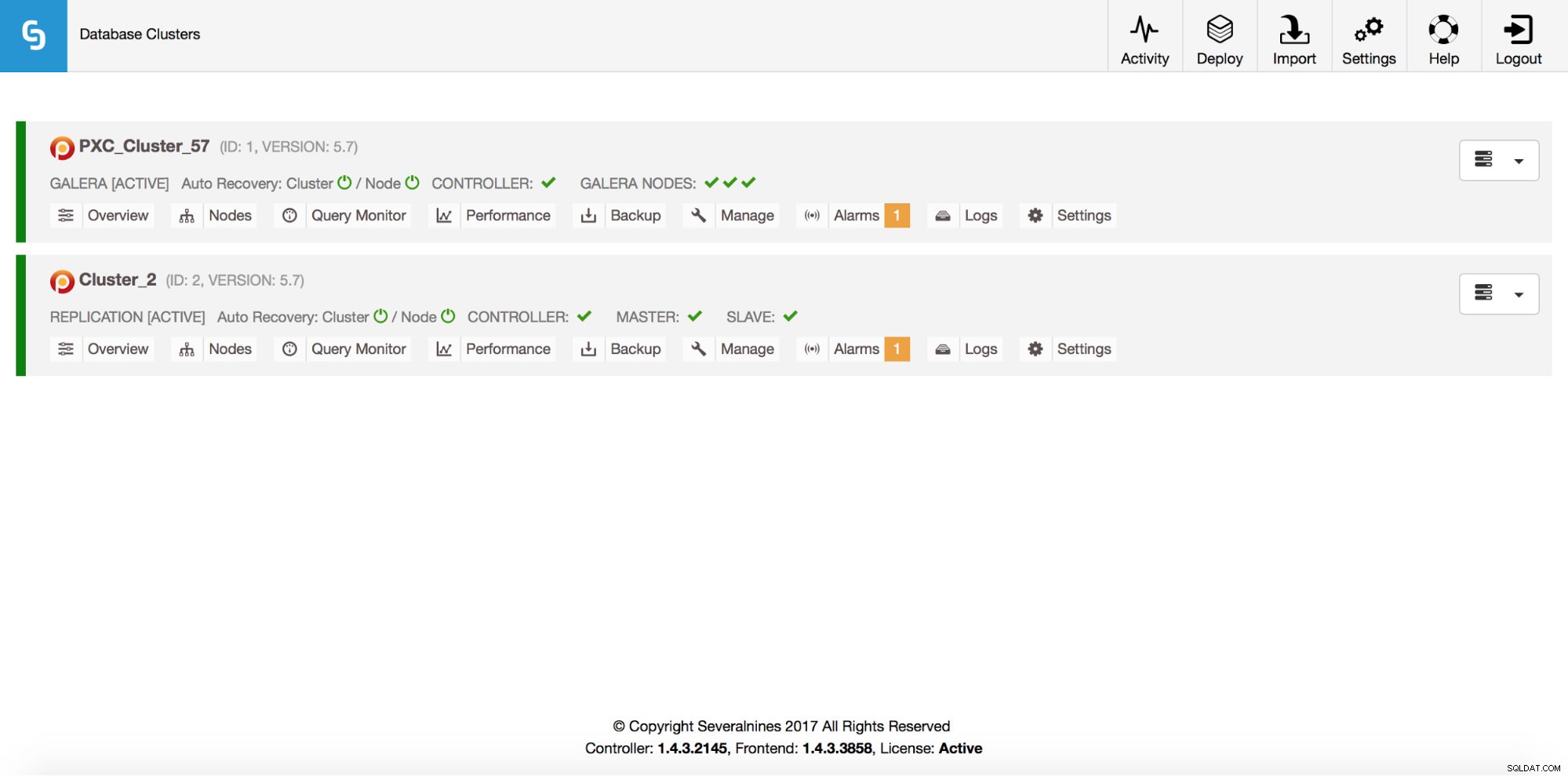
Lassen Sie uns nun einen ProxySQL-Loadbalancer hinzufügen:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Dieses Mal haben wir die Option „--wait“ nicht verwendet. Wenn wir also den Fortschritt überprüfen möchten, müssen wir dies selbst tun. Bitte beachten Sie, dass wir eine Job-ID verwenden, die vom vorherigen Befehl zurückgegeben wurde, sodass wir nur Informationen zu diesem bestimmten Job erhalten:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Scale-Out
Knoten können unserem Galera-Cluster mit einem einzigen Befehl hinzugefügt werden:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Etwas ist schief gelaufen. Wir können überprüfen, was genau passiert ist:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Richtig, diese IP wird bereits für unseren Replikationsserver verwendet. Wir hätten eine andere, freie IP verwenden sollen. Versuchen wir das:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Verwalten
Angenommen, wir möchten ein Backup unseres Replikationsmasters erstellen. Wir können das über die GUI tun, aber manchmal müssen wir es mit externen Skripten integrieren. ClusterControl CLI würde sich perfekt für einen solchen Fall eignen. Sehen wir uns an, welche Cluster wir haben:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Überprüfen wir dann die Hosts in unserem Replikationscluster mit der Cluster-ID 2:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningWie wir sehen können, kennt ClusterControl drei Hosts – zwei davon sind MySQL-Hosts (10.0.0.229 und 10.0.0.230), der dritte ist die ClusterControl-Instanz selbst. Lassen Sie uns nur die relevanten MySQL-Hosts drucken:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3In der Spalte „STAT“ sieht man dort einige Zeichen. Für weitere Informationen empfehlen wir einen Blick in die Handbuchseite für s9s-Knoten (man s9s-nodes). Hier fassen wir nur die wichtigsten Punkte zusammen. Das erste Zeichen gibt Auskunft über den Typ des Knotens:„s“ bedeutet, dass es sich um einen regulären MySQL-Knoten handelt, „c“ – ClusterControl-Controller. Das zweite Zeichen beschreibt den Zustand des Knotens:„o“ sagt uns, dass er online ist. Drittes Zeichen - Rolle des Knotens. Hier bezeichnet „M“ einen Master und „S“ einen Slave, während „C“ für Controller steht. Das letzte, vierte Zeichen sagt uns, ob sich der Knoten im Wartungsmodus befindet. „-“ bedeutet, dass keine Wartung geplant ist. Sonst würden wir hier „M“ sehen. Anhand dieser Daten können wir also sehen, dass unser Master ein Host mit der IP:10.0.0.229 ist. Lassen Sie uns eine Sicherungskopie davon erstellen und auf dem Controller speichern.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okWir können dann überprüfen, ob es tatsächlich in Ordnung abgeschlossen wurde. Bitte beachten Sie die Option „--backup-format“, mit der Sie festlegen können, welche Informationen gedruckt werden sollen:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Überwachung
Alle Datenbanken müssen überwacht werden. ClusterControl verwendet Advisors, um einige der Metriken sowohl auf MySQL als auch auf dem Betriebssystem zu überwachen. Wenn eine Bedingung erfüllt ist, wird eine Benachrichtigung gesendet. ClusterControl bietet auch eine umfangreiche Reihe von Diagrammen, sowohl Echtzeit- als auch historische Diagramme für Post-Mortem- oder Kapazitätsplanung. Manchmal wäre es großartig, Zugriff auf einige dieser Metriken zu haben, ohne die GUI durchlaufen zu müssen. ClusterControl CLI macht dies über den Befehl s9s-node möglich. Informationen dazu finden Sie in der Handbuchseite von s9s-node. Wir zeigen einige Beispiele dafür, was Sie mit CLI machen können.
Schauen wir uns zunächst die Option „--node-format“ für den Befehl „s9s node“ an. Wie Sie sehen, gibt es viele Möglichkeiten, interessante Inhalte zu drucken.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningMit dem, was wir hier gezeigt haben, können Sie sich wahrscheinlich einige Fälle für die Automatisierung vorstellen. Sie können beispielsweise die CPU-Auslastung der Knoten beobachten und, wenn sie einen Schwellenwert erreicht, einen weiteren s9s-Job ausführen, um einen neuen Knoten im Galera-Cluster hochzufahren. Sie können beispielsweise auch die Speicherauslastung überwachen und Warnungen senden, wenn ein Schwellenwert überschritten wird.
Die CLI kann mehr als das. Zunächst einmal ist es möglich, die Diagramme von der Befehlszeile aus zu überprüfen. Natürlich sind diese nicht so funktionsreich wie Diagramme in der GUI, aber manchmal reicht es aus, nur ein Diagramm zu sehen, um ein unerwartetes Muster zu finden und zu entscheiden, ob es einer weiteren Untersuchung wert ist.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231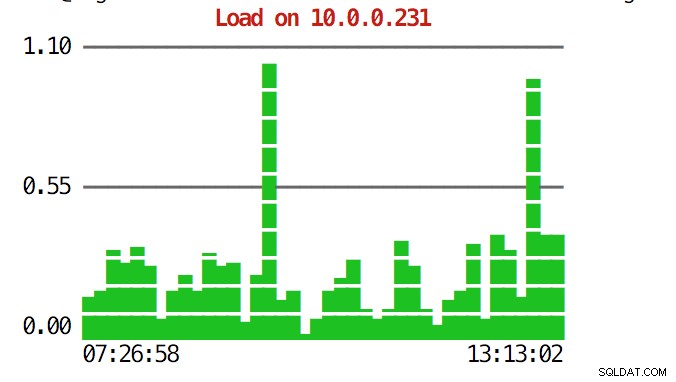
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231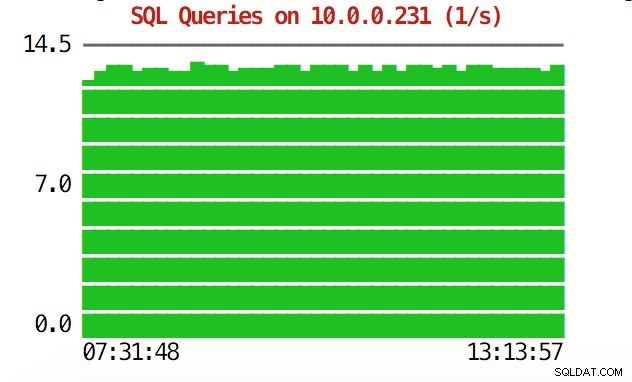
In Notfallsituationen möchten Sie möglicherweise die Ressourcenauslastung im gesamten Cluster überprüfen. Sie können eine Top-ähnliche Ausgabe erstellen, die Daten von allen Cluster-Knoten kombiniert:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HOben sehen Sie CPU- und Speicherstatistiken, die über den gesamten Cluster aggregiert sind.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,Unten finden Sie die Liste der Prozesse von allen Knoten im Cluster.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldDies kann äußerst nützlich sein, wenn Sie herausfinden müssen, was die Last verursacht und welcher Knoten am stärksten betroffen ist.
Hoffentlich erleichtert Ihnen das CLI-Tool die Integration von ClusterControl mit externen Skripts und Infrastruktur-Orchestrierungstools. Wir hoffen, dass Ihnen die Verwendung dieses Tools Spaß macht, und wenn Sie Feedback zur Verbesserung haben, können Sie uns dies gerne mitteilen.



