Galera Cluster verfügt über viele bemerkenswerte Funktionen, die in der standardmäßigen MySQL-Replikation (oder Gruppenreplikation) nicht verfügbar sind. automatische Knotenbereitstellung, echter Multi-Master mit Konfliktlösungen und automatischem Failover. Es gibt auch eine Reihe von Einschränkungen, die sich potenziell auf die Clusterleistung auswirken können. Glücklicherweise gibt es Problemumgehungen, wenn Sie sich dessen nicht bewusst sind. Und wenn Sie es richtig machen, können Sie die Auswirkungen dieser Einschränkungen minimieren und die Gesamtleistung verbessern.
Wir haben bereits viele Tipps und Tricks im Zusammenhang mit Galera Cluster behandelt, einschließlich der Ausführung von Galera in AWS Cloud. Dieser Blogbeitrag befasst sich deutlich mit den Leistungsaspekten und enthält Beispiele, wie Sie das Beste aus Galera herausholen können.
Replikationsnutzlast
Eine kleine Einführung – Galera repliziert Writesets während der Commit-Phase und überträgt Writesets synchron vom Ursprungsknoten zu den Empfängerknoten über das wsrep-Replikations-Plugin. Dieses Plugin zertifiziert auch Writesets auf den Empfängerknoten. Wenn der Zertifizierungsprozess bestanden wird, gibt er OK an den Client auf dem Ursprungsknoten zurück und wird zu einem späteren Zeitpunkt asynchron auf die Empfängerknoten angewendet. Andernfalls wird die Transaktion auf dem Ursprungsknoten rückgängig gemacht (Rückgabe eines Fehlers an den Client) und die Writesets, die an die Empfängerknoten übertragen wurden, werden verworfen.
Ein Writeset besteht aus Schreibvorgängen innerhalb einer Transaktion, die den Datenbankstatus ändert. Im Galera-Cluster autocommit ist standardmäßig auf 1 (aktiviert). Jede im Galera Cluster ausgeführte SQL-Anweisung wird buchstäblich als Transaktion eingeschlossen, es sei denn, Sie beginnen explizit mit BEGIN, START TRANSACTION oder SET autocommit=0. Das folgende Diagramm veranschaulicht die Kapselung einer einzelnen DML-Anweisung in einem Writeset:
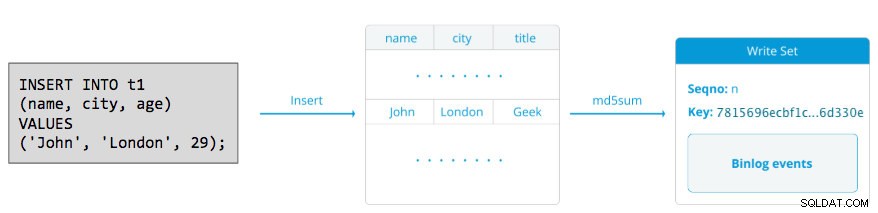
Bei DML (INSERT, UPDATE, DELETE...) besteht die Writeset-Nutzlast aus den binären Protokollereignissen für eine bestimmte Transaktion, während bei DDLs (ALTER, GRANT, CREATE...) die Writeset-Nutzlast die DDL-Anweisung selbst ist. Für DMLs muss der Writeset gegen Konflikte auf dem Empfängerknoten zertifiziert werden, während für DDLs (abhängig von wsrep_osu_method , standardmäßig TOI), führt der Cluster-Cluster die DDL-Anweisung auf allen Knoten in derselben Gesamtreihenfolge aus und blockiert andere Transaktionen am Festschreiben, während die DDL ausgeführt wird (siehe auch RSU). Mit einfachen Worten, Galera Cluster handhabt die DDL- und DML-Replikation unterschiedlich.
Round-Trip-Zeit
Im Allgemeinen bestimmen die folgenden Faktoren, wie schnell Galera einen Writeset von einem Ursprungsknoten zu allen Empfängerknoten replizieren kann:
- Umlaufzeit (RTT) zum am weitesten vom Ursprungsknoten entfernten Knoten im Cluster.
- Die Größe eines Writesets, das übertragen und auf dem Empfängerknoten für Konflikte zertifiziert werden soll.
Wenn wir beispielsweise einen Galera-Cluster mit drei Knoten haben und sich einer der Knoten 10 Millisekunden (0,01 Sekunden) entfernt befindet, ist es sehr unwahrscheinlich, dass Sie mehr als 100 Mal pro Sekunde ohne Konflikte in dieselbe Zeile schreiben können. Es gibt ein beliebtes Zitat von Mark Callaghan, das dieses Verhalten ziemlich gut beschreibt:
"[In einem Galera-Cluster] kann eine bestimmte Zeile nicht mehr als einmal pro RTT geändert werden"
Um den RTT-Wert zu messen, führen Sie einfach einen Ping auf dem Ursprungsknoten zum entferntesten Knoten im Cluster durch:
$ ping 192.168.55.173 # the farthest nodeWarten Sie einige Sekunden (oder Minuten) und beenden Sie den Befehl. Die letzte Zeile des Ping-Statistikabschnitts ist das, wonach wir suchen:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msDas Maximum Wert ist 1,340 ms (0,00134 s) und wir sollten diesen Wert nehmen, wenn wir das Minimum schätzen Transaktionen pro Sekunde (tps) für diesen Cluster. Der Durchschnitt Wert ist 0,431 ms (0,000431 s) und wir können ihn verwenden, um den Durchschnitt zu schätzen tps während min Wert ist 0,111 ms (0,000111 s), den wir verwenden können, um das Maximum zu schätzen tp. Der mdev bedeutet, wie die RTT-Samples vom Durchschnitt verteilt waren. Ein niedrigerer Wert bedeutet eine stabilere RTT.
Daher können Transaktionen pro Sekunde geschätzt werden, indem RTT (in Sekunden) durch 1 Sekunde geteilt wird:

Ergebnis,
- Mindest-tps:1 / 0,00134 (max. RTT) =746,26 ~ 746 tps
- Durchschnittliche tps:1 / 0,000431 (durchschnittliche RTT) =2320,19 ~ 2320 tps
- Maximale tps:1 / 0,000111 (min. RTT) =9009,01 ~ 9009 tps
Beachten Sie, dass dies nur eine Schätzung zur Vorhersage der Replikationsleistung ist. Es gibt nicht viel, was wir tun können, um dies auf der Datenbankseite zu verbessern, sobald wir alles bereitgestellt und ausgeführt haben. Außer, wenn Sie die Datenbankserver näher zueinander verschieben oder migrieren, um die RTT zwischen den Knoten zu verbessern, oder wenn Sie die Netzwerkperipheriegeräte oder die Infrastruktur aktualisieren. Dies würde ein Wartungsfenster und eine angemessene Planung erfordern.
Große Transaktionen aufteilen
Ein weiterer Faktor ist die Transaktionsgröße. Nachdem das Writeset übertragen wurde, findet ein Zertifizierungsprozess statt. Die Zertifizierung ist ein Prozess, um festzustellen, ob der Knoten den Schreibsatz anwenden kann oder nicht. Galera generiert MD5-Prüfsummen-Pseudoschlüssel aus jeder vollen Zeile. Die Zertifizierungskosten hängen von der Größe des Writesets ab, was zu einer Reihe eindeutiger Schlüsselsuchen im Zertifizierungsindex (einer Hash-Tabelle) führt. Wenn Sie beispielsweise 500.000 Zeilen in einer einzigen Transaktion aktualisieren:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Das Obige generiert ein einzelnes Writeset mit 500.000 Binärprotokollereignissen darin. Dieser riesige Writeset überschreitet nicht wsrep_max_ws_size (standardmäßig 2 GB), sodass es vom Galera-Replikations-Plugin an alle Knoten im Cluster übertragen wird, wodurch diese 500.000 Zeilen auf den Empfängerknoten für alle widersprüchlichen Transaktionen zertifiziert werden, die sich noch in der Slave-Warteschlange befinden. Schließlich wird der Zertifizierungsstatus an das Gruppenreplikations-Plugin zurückgegeben. Je größer die Transaktionsgröße, desto höher ist das Risiko, dass es zu Konflikten mit anderen Transaktionen kommt, die von einem anderen Master stammen. Widersprüchliche Transaktionen verschwenden Serverressourcen und verursachen einen enormen Rollback zum Ursprungsknoten. Beachten Sie, dass eine Rollback-Operation in MySQL viel langsamer und weniger optimiert ist als eine Commit-Operation.
Die obige SQL-Anweisung kann mit Hilfe einer einfachen Schleife in eine Galera-freundlichere Anweisung umgeschrieben werden, wie im folgenden Beispiel:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneDer obige Shell-Befehl würde 1000 Zeilen pro Transaktion 500 Mal aktualisieren und zwischen den Ausführungen 2 Sekunden warten. Sie können auch eine gespeicherte Prozedur oder andere Mittel verwenden, um ein ähnliches Ergebnis zu erzielen. Wenn das Umschreiben der SQL-Abfrage keine Option ist, weisen Sie die Anwendung einfach an, die große Transaktion während eines Wartungsfensters auszuführen, um das Risiko von Konflikten zu verringern.
Ziehen Sie für große Löschvorgänge die Verwendung von pt-archiver aus dem Percona Toolkit in Betracht – ein Low-Impact-Forward-Only-Job, um alte Daten aus der Tabelle zu knabbern, ohne die OLTP-Abfragen stark zu beeinträchtigen.
Parallele Slave-Threads
In Galera ist der Applikator ein Multithread-Prozess. Applier ist ein Thread, der innerhalb von Galera läuft, um die eingehenden Write-Sets von einem anderen Knoten anzuwenden. Das bedeutet, dass alle Empfänger mehrere DML-Operationen gleichzeitig ausführen können, die direkt vom Ursprungsknoten (Master-Knoten) kommen. Die parallele Replikation von Galera wird nur dann auf Transaktionen angewendet, wenn dies sicher ist. Es verbessert die Wahrscheinlichkeit, dass sich der Knoten mit dem Ursprungsknoten synchronisiert. Die Replikationsgeschwindigkeit ist jedoch immer noch auf RTT und Writeset-Größe beschränkt.
Um das Beste daraus zu machen, müssen wir zwei Dinge wissen:
- Die Anzahl der Kerne des Servers.
- Der Wert von wsrep_cert_deps_distance Status.
Der Status wsrep_cert_deps_distance sagt uns den möglichen Grad der Parallelisierung. Es ist der Wert des durchschnittlichen Abstands zwischen höchsten und niedrigsten Seqno-Werten, die möglicherweise parallel angewendet werden können. Sie können die wsrep_cert_deps_distance verwenden Statusvariable, um die maximal mögliche Anzahl von Slave-Threads zu bestimmen. Beachten Sie, dass dies ein Durchschnittswert über die Zeit ist. Um einen guten Wert zu erhalten, müssen Sie daher den Cluster mit Schreibvorgängen durch Test-Workload oder Benchmark treffen, bis Sie einen stabilen Wert sehen.
Um die Anzahl der Kerne zu erhalten, können Sie einfach den folgenden Befehl verwenden:
$ grep -c processor /proc/cpuinfo
4Idealerweise sind 2, 3 oder 4 Threads von Slave-Applikatoren pro CPU-Kern ein guter Anfang. Daher sollte der Mindestwert für die Slave-Threads 4 x Anzahl der CPU-Kerne betragen und darf die wsrep_cert_deps_distance nicht überschreiten Wert:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Sie können die Anzahl der Slave-Applier-Threads mit wsrep_slave_thread steuern Variable. Auch wenn es sich um eine dynamische Variable handelt, würde nur eine Erhöhung der Zahl eine sofortige Wirkung haben. Wenn Sie den Wert dynamisch reduzieren, würde es einige Zeit dauern, bis der Anwendungsthread beendet wird, nachdem er die Anwendung abgeschlossen hat. Ein empfohlener Wert liegt zwischen 16 und 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Beachten Sie, dass, damit parallele Slave-Threads funktionieren, Folgendes eingestellt sein muss (was normalerweise für Galera Cluster vorkonfiguriert ist):
innodb_autoinc_lock_mode=2Galera-Cache (gcache)
Galera verwendet eine vorab zugewiesene Datei mit einer bestimmten Größe namens gcache, in der ein Galera-Knoten eine Kopie von Writesets im Stil eines Ringpuffers speichert. Standardmäßig beträgt die Größe 128 MB, was ziemlich klein ist. Incremental State Transfer (IST) ist eine Methode, um einen Joiner vorzubereiten, indem nur die fehlenden Writesets gesendet werden, die im gcache des Spenders verfügbar sind. IST ist schneller als State Snapshot Transfer (SST), blockiert nicht und hat keine signifikanten Auswirkungen auf die Leistung des Spenders. Dies sollte nach Möglichkeit die bevorzugte Option sein.
IST kann nur erreicht werden, wenn alle vom Joiner verpassten Änderungen noch in der gcache-Datei des Spenders sind. Die empfohlene Einstellung dafür ist so groß wie der gesamte MySQL-Datensatz. Wenn der Speicherplatz begrenzt oder teuer ist, ist die Bestimmung der richtigen Größe des gcaches von entscheidender Bedeutung, da dies die Datensynchronisierungsleistung zwischen Galera-Knoten beeinflussen kann.
Die folgende Erklärung gibt uns eine Vorstellung von der Menge der von Galera replizierten Daten. Führen Sie die folgende Anweisung auf einem der Galera-Knoten während der Spitzenzeiten aus (getestet auf MariaDB>10.0 und PXC>5.6, Galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Wir können schätzen, dass der Galera-Knoten etwa 16 Minuten Ausfallzeit haben kann, ohne dass SST beitreten muss (es sei denn, Galera kann den Joiner-Status nicht bestimmen). Wenn dies zu kurz ist und Sie genügend Speicherplatz auf Ihren Knoten haben, können Sie wsrep_provider_options="gcache.size=
Es wird auch empfohlen, gcache.recover=yes zu verwenden in wsrep_provider_options (Galera>3.19), wobei Galera versucht, die gcache-Datei beim Start in einen brauchbaren Zustand wiederherzustellen, anstatt sie zu löschen, wodurch die Fähigkeit erhalten bleibt, IST zu haben und SST so weit wie möglich zu vermeiden. Codership und Percona haben dies ausführlich in ihren Blogs behandelt. IST ist immer die beste Methode zum Synchronisieren, nachdem ein Knoten dem Cluster wieder beigetreten ist. Es ist 50 % schneller als xtrabackup oder mariabackup und 5x schneller als mysqldump.
Asynchroner Slave
Galera-Knoten sind eng gekoppelt, wobei die Replikationsleistung so schnell ist wie die des langsamsten Knotens. Galera verwendet einen Flusskontrollmechanismus, um den Replikationsfluss zwischen den Mitgliedern zu kontrollieren und jegliche Slave-Verzögerung zu beseitigen. Die Replikation kann auf jedem Knoten ganz schnell oder ganz langsam sein und wird automatisch von Galera angepasst. Wenn Sie mehr über Flusskontrolle erfahren möchten, lesen Sie diesen Blogbeitrag von Jay Janssen von Percona.
In den meisten Fällen sind schwere Vorgänge wie lang andauernde Analysen (leseintensiv) und Sicherungen (leseintensiv, Sperren) oft unvermeidlich, was die Clusterleistung potenziell beeinträchtigen könnte. Der beste Weg, diese Art von Abfragen auszuführen, besteht darin, sie an einen lose gekoppelten Replikatserver zu senden, beispielsweise einen asynchronen Slave.
Ein asynchroner Slave repliziert von einem Galera-Knoten unter Verwendung des standardmäßigen asynchronen MySQL-Replikationsprotokolls. Die Anzahl der Slaves, die an einen Galera-Knoten angeschlossen werden können, ist unbegrenzt, und es ist auch möglich, ihn mit einem zwischengeschalteten Master zu verketten. MySQL-Operationen, die auf diesem Server ausgeführt werden, wirken sich nicht auf die Clusterleistung aus, abgesehen von der anfänglichen Synchronisierungsphase, in der eine vollständige Sicherung auf dem Galera-Knoten erstellt werden muss, um den Slave bereitzustellen, bevor die Replikationsverbindung hergestellt wird (obwohl ClusterControl es Ihnen ermöglicht, die asynchrone Slave zuerst aus einem vorhandenen Backup, bevor Sie ihn mit dem Cluster verbinden).
GTID (Global Transaction Identifier) bietet eine bessere Transaktionszuordnung über Knoten hinweg und wird in MySQL 5.6 und MariaDB 10.0 unterstützt. Mit GTID wird der Failover-Vorgang von einem Slave zu einem anderen Master (einem anderen Galera-Knoten) vereinfacht, ohne dass die genaue Protokolldatei und Position ermittelt werden müssen. Galera verfügt auch über eine eigene GTID-Implementierung, aber diese beiden sind unabhängig voneinander.
Das Aufskalieren eines asynchronen Slaves ist nur einen Klick entfernt, wenn Sie die Funktion ClusterControl -> Add Replication Slave verwenden:
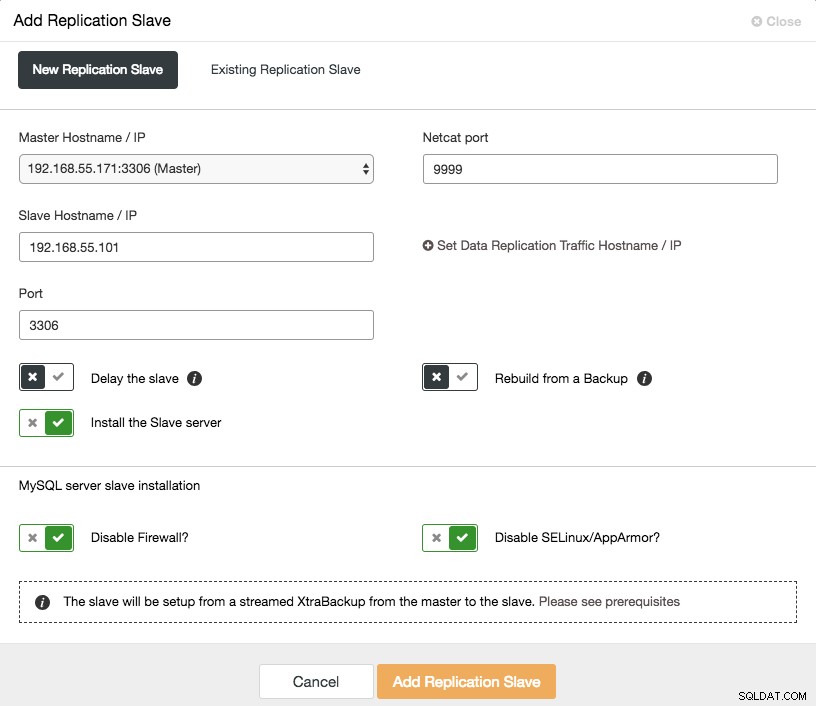
Beachten Sie, dass Binärprotokolle auf dem Master (dem ausgewählten Galera-Knoten) aktiviert sein müssen, bevor wir mit dieser Einrichtung fortfahren können. Wir haben auch den manuellen Weg in diesem vorherigen Beitrag behandelt.
Der folgende Screenshot von ClusterControl zeigt die Cluster-Topologie, er veranschaulicht unsere Galera-Cluster-Architektur mit einem asynchronen Slave:
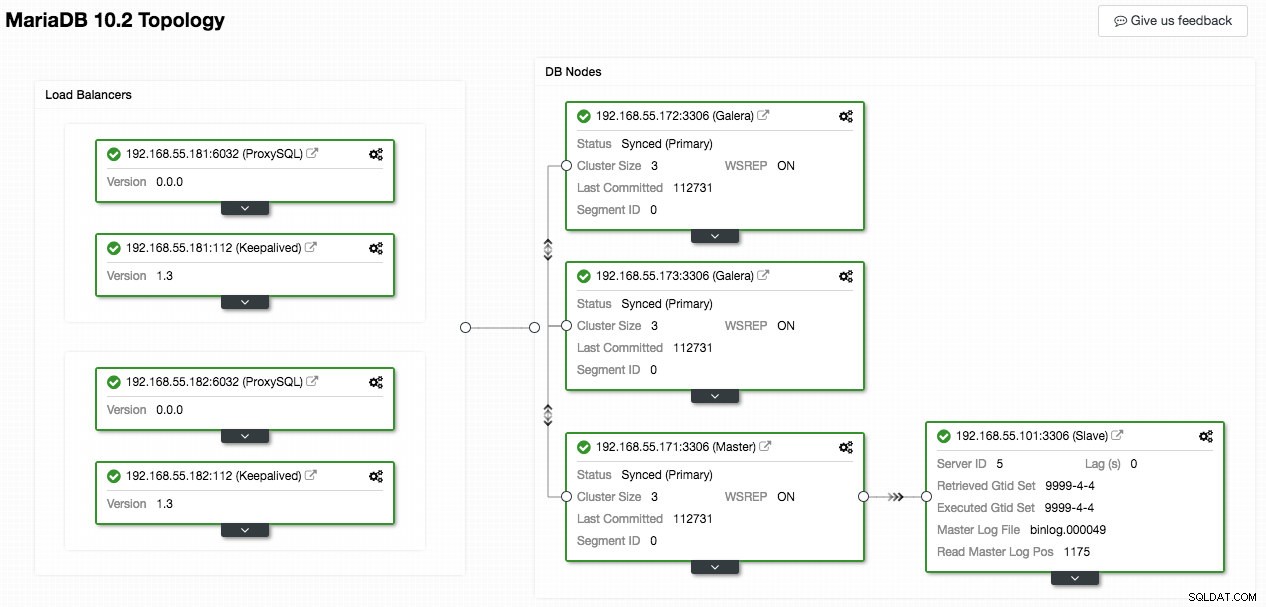
ClusterControl erkennt automatisch die Topologie und generiert das super coole Diagramm wie oben. Sie können Verwaltungsaufgaben auch direkt von dieser Seite aus ausführen, indem Sie auf das Zahnradsymbol oben rechts in jedem Feld klicken.
SQL-fähiger Reverse Proxy
ProxySQL und MariaDB MaxScale sind intelligente Reverse-Proxys, die das MySQL-Protokoll verstehen und als Gateway, Router, Load Balancer und Firewall vor Ihren Galera-Knoten fungieren können. Mit Hilfe von Anbietern virtueller IP-Adressen wie LVS oder Keepalived und der Kombination mit der Multi-Master-Replikationstechnologie von Galera können wir einen hochverfügbaren Datenbankdienst haben, der alle möglichen Single-Point-of-Failures (SPOF) vom Anwendungspunkt aus eliminiert -Aussicht. Dies wird sicherlich die Verfügbarkeit und Zuverlässigkeit der gesamten Architektur verbessern.
Ein weiterer Vorteil dieses Ansatzes besteht darin, dass Sie die eingehenden SQL-Abfragen basierend auf einer Reihe von Regeln überwachen, umschreiben oder umleiten können, bevor sie den eigentlichen Datenbankserver erreichen, wodurch die Änderungen auf der Anwendungs- oder Clientseite minimiert und Abfragen an weitergeleitet werden ein besser geeigneter Knoten für optimale Leistung. Riskante Abfragen für Galera wie LOCK TABLES und FLUSH TABLES WITH READ LOCK können weit im Voraus verhindert werden, bevor sie Chaos im System anrichten würden, während sich dies auf Abfragen wie "Hotspot"-Abfragen (eine Zeile, auf die verschiedene Abfragen gleichzeitig zugreifen möchten) auswirken kann umgeschrieben oder auf einen einzelnen Galera-Knoten umgeleitet werden, um das Risiko von Transaktionskonflikten zu verringern. Für umfangreiche schreibgeschützte Abfragen wie OLAP oder Backup können Sie diese an einen asynchronen Slave weiterleiten, falls vorhanden.
Reverse-Proxy überwacht auch den Datenbankstatus, Abfragen und Variablen, um die Topologieänderungen zu verstehen und eine genaue Routing-Entscheidung zu den Backend-Servern zu treffen. Indirekt zentralisiert es die Überwachung der Knoten und die Cluster-Übersicht, ohne dass jeder einzelne Galera-Knoten regelmäßig überprüft werden muss. Der folgende Screenshot zeigt das ProxySQL-Monitoring-Dashboard in ClusterControl:
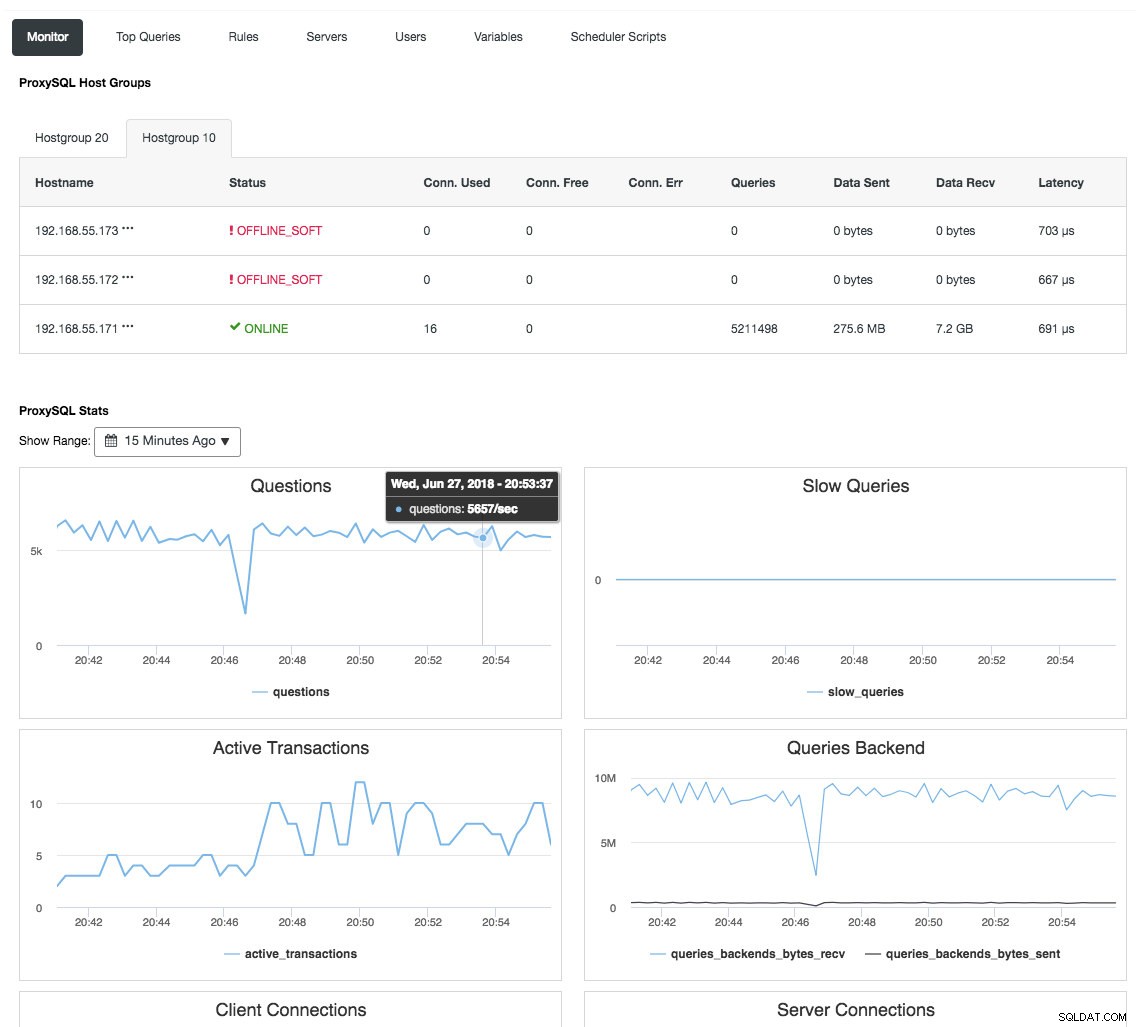
Es gibt auch viele andere Vorteile, die ein Load Balancer bringen kann, um Galera Cluster erheblich zu verbessern, wie ausführlich in diesem Blog-Beitrag Become a ClusterControl DBA:Making your DB components HA via Load Balancers behandelt wird.
Abschließende Gedanken
Mit einem guten Verständnis dafür, wie Galera Cluster intern funktioniert, können wir einige der Einschränkungen umgehen und den Datenbankdienst verbessern. Viel Spaß beim Clustern!