Datenbankschemata sind nicht in Stein gemeißelt. Es ist für eine bestimmte Anwendung ausgelegt, aber dann können sich die Anforderungen ändern und tun dies normalerweise auch. Neue Module und Funktionalitäten werden der Anwendung hinzugefügt, mehr Daten werden gesammelt, Code- und Datenmodell-Refactoring wird durchgeführt. Dadurch die Notwendigkeit, das Datenbankschema zu modifizieren, um sich an diese Änderungen anzupassen; Spalten hinzufügen oder ändern, neue Tabellen erstellen oder große Tabellen partitionieren. Abfragen ändern sich auch, wenn Entwickler neue Möglichkeiten für Benutzer hinzufügen, mit den Daten zu interagieren - neue Abfragen könnten neue, effizientere Indizes verwenden, also erstellen wir sie schnell, um der Anwendung die beste Datenbankleistung zu bieten.
Wie gehen wir also am besten an eine Schemaänderung heran? Welche Tools sind sinnvoll? Wie können die Auswirkungen auf eine Produktionsdatenbank minimiert werden? Was sind die häufigsten Probleme beim Schemadesign? Welche Tools können Ihnen helfen, Ihr Schema im Griff zu behalten? In diesem Blogbeitrag geben wir Ihnen einen kurzen Überblick darüber, wie Sie Schemaänderungen in MySQL und MariaDB vornehmen können. Bitte beachten Sie, dass wir Schemaänderungen im Kontext von Galera Cluster nicht diskutieren werden. Wir haben bereits in früheren Blogbeiträgen die totale Auftragsisolation, rollierende Schema-Upgrades und Tipps zur Minimierung der Auswirkungen von RSU besprochen. Wir werden auch Tipps und Tricks zum Schemadesign diskutieren und wie ClusterControl Ihnen dabei helfen kann, den Überblick über alle Schemaänderungen zu behalten.
Arten von Schemaänderungen
Das wichtigste zuerst. Bevor wir uns mit dem Thema befassen, müssen wir verstehen, wie MySQL und MariaDB Schemaänderungen durchführen. Sie sehen, eine Schemaänderung ist nicht gleich einer anderen Schemaänderung.
Sie haben vielleicht schon von Online-Änderungen, sofortigen Änderungen oder In-Place-Änderungen gehört. All dies ist das Ergebnis laufender Arbeiten zur Minimierung der Auswirkungen der Schemaänderungen auf die Produktionsdatenbank. In der Vergangenheit blockierten fast alle Schemaänderungen. Wenn Sie eine Schemaänderung ausgeführt haben, stapeln sich alle Abfragen und warten auf den Abschluss von ALTER. Offensichtlich stellte dies ernsthafte Probleme für Produktionsbereitstellungen dar. Sicher, die Leute suchen sofort nach Problemumgehungen, und wir werden sie später in diesem Blog diskutieren, da diese auch heute noch relevant sind. Aber auch die Arbeit begann, die Fähigkeit von MySQL zu verbessern, DDLs (Data Definition Language) ohne große Auswirkungen auf andere Abfragen auszuführen.
Sofortige Änderungen
Manchmal ist es nicht erforderlich, Daten im Tablespace anzufassen, da nur die Metadaten geändert werden müssen. Ein Beispiel hierfür ist das Löschen eines Indexes oder das Umbenennen einer Spalte. Solche Operationen sind schnell und effizient. Typischerweise ist ihre Wirkung begrenzt. Es ist jedoch nicht ohne Auswirkungen. Manchmal dauert es einige Sekunden, um die Änderung in den Metadaten durchzuführen, und für eine solche Änderung muss eine Metadatensperre erworben werden. Diese Sperre gilt pro Tabelle und kann andere Operationen blockieren, die auf dieser Tabelle ausgeführt werden sollen. Sie sehen dies als „Waiting for table metadata lock“-Einträge in der Prozessliste.
Ein Beispiel für eine solche Änderung kann Instant ADD COLUMN sein, das in MariaDB 10.3 und MySQL 8.0 eingeführt wurde. Es gibt die Möglichkeit, diese recht beliebte Schemaänderung ohne Verzögerung durchzuführen. Sowohl MariaDB als auch Oracle haben sich entschieden, Code von Tencent Game einzubinden, der es ermöglicht, der Tabelle sofort eine neue Spalte hinzuzufügen. Dies geschieht unter bestimmten Bedingungen; Spalte muss als letzte hinzugefügt werden, Volltextindizes können nicht in der Tabelle existieren, Zeilenformat kann nicht komprimiert werden - weitere Informationen darüber, wie Instant Add Column funktioniert, finden Sie in der MariaDB-Dokumentation. Für MySQL ist die einzige offizielle Referenz im Blog mysqlserverteam.com zu finden, obwohl ein Fehler vorhanden ist, um die offizielle Dokumentation zu aktualisieren.
Inplace-Änderungen
Einige der Änderungen erfordern eine Änderung der Daten im Tablespace. Solche Änderungen können an den Daten selbst vorgenommen werden, und es ist nicht erforderlich, eine temporäre Tabelle mit einer neuen Datenstruktur zu erstellen. Solche Änderungen ermöglichen normalerweise (aber nicht immer) die Ausführung anderer Abfragen, die die Tabelle berühren, während die Schemaänderung ausgeführt wird. Ein Beispiel für eine solche Operation ist das Hinzufügen eines neuen Sekundärindex zur Tabelle. Dieser Vorgang wird einige Zeit in Anspruch nehmen, ermöglicht aber die Ausführung von DMLs.
Tabellenneuaufbau
Wenn eine Änderung nicht möglich ist, erstellt InnoDB eine temporäre Tabelle mit der neuen, gewünschten Struktur. Es kopiert dann vorhandene Daten in die neue Tabelle. Diese Operation ist die teuerste und es ist wahrscheinlich (obwohl dies nicht immer der Fall ist), dass die DMLs gesperrt werden. Daher ist es sehr schwierig, eine solche Schemaänderung auf einer großen Tabelle auf einem eigenständigen Server ohne die Hilfe externer Tools auszuführen – normalerweise können Sie es sich nicht leisten, Ihre Datenbank für lange Minuten oder sogar Stunden zu sperren. Ein Beispiel für eine solche Operation wäre das Ändern des Spaltendatentyps, beispielsweise von INT in VARCHAR.
Schemaänderungen und Replikation
Ok, wir wissen also, dass InnoDB Online-Schemaänderungen zulässt, und wenn wir die MySQL-Dokumentation konsultieren, werden wir sehen, dass die meisten Schemaänderungen (zumindest unter den häufigsten) online durchgeführt werden können. Was ist der Grund dafür, Stunden der Entwicklung zu widmen, um Online-Schemaänderungstools wie gh-ost zu erstellen? Wir können akzeptieren, dass pt-online-schema-change ein Überbleibsel der alten, schlechten Zeiten ist, aber gh-ost ist eine neue Software.
Die Antwort ist komplex. Es gibt zwei Hauptprobleme.
Zunächst einmal haben Sie keine Kontrolle mehr darüber, sobald Sie eine Schemaänderung gestartet haben. Sie können es abbrechen, aber Sie können es nicht anhalten. Du kannst es nicht drosseln. Wie Sie sich vorstellen können, ist die Neuerstellung der Tabelle ein teurer Vorgang, und selbst wenn InnoDB die Ausführung von DMLs zulässt, wirkt sich die zusätzliche E/A-Arbeitslast der DDL auf alle anderen Abfragen aus, und es gibt keine Möglichkeit, diese Auswirkungen auf ein für die akzeptables Maß zu begrenzen Anwendung.
Das zweite, noch schwerwiegendere Problem ist die Replikation. Wenn Sie eine nicht blockierende Operation ausführen, die einen Tabellenneuaufbau erfordert, werden die DMLs zwar nicht gesperrt, aber dies gilt nur für den Master. Nehmen wir an, dass eine solche DDL 30 Minuten benötigte, um abgeschlossen zu werden – die ALTER-Geschwindigkeit hängt von der Hardware ab, aber es ist ziemlich üblich, solche Ausführungszeiten auf Tabellen mit einer Größe von 20 GB zu sehen. Es wird dann auf alle Slaves repliziert, und ab dem Zeitpunkt, an dem DDL auf diesen Slaves gestartet wird, wartet die Replikation auf ihren Abschluss. Es spielt keine Rolle, ob Sie MySQL oder MariaDB verwenden oder ob Sie eine Multithread-Replikation haben. Slaves verzögern – sie warten diese 30 Minuten, bis die DDL abgeschlossen ist, bevor sie mit der Anwendung der verbleibenden Binlog-Ereignisse beginnen. Wie Sie sich vorstellen können, sind 30 Minuten Verzögerung (manchmal sind sogar 30 Sekunden nicht akzeptabel – alles hängt von der Anwendung ab) etwas, das es unmöglich macht, diese Slaves für Scale-out zu verwenden. Natürlich gibt es Problemumgehungen – Sie können Schemaänderungen von unten nach oben in der Replikationskette durchführen, aber das schränkt Ihre Optionen ernsthaft ein. Insbesondere wenn Sie die zeilenbasierte Replikation verwenden, können Sie auf diese Weise nur kompatible Schemaänderungen durchführen. Einige Beispiele für Einschränkungen der zeilenbasierten Replikation; Sie können keine Spalte löschen, die nicht die letzte ist, Sie können keine Spalte an einer anderen Position als der letzten hinzufügen. Sie können auch den Spaltentyp nicht ändern (z. B. INT -> VARCHAR).
Wie Sie sehen können, erhöht die Replikation die Komplexität bei der Durchführung von Schemaänderungen. Operationen, die auf dem eigenständigen Host nicht blockieren, werden blockierend, wenn sie auf Slaves ausgeführt werden. Sehen wir uns einige Methoden an, mit denen Sie die Auswirkungen von Schemaänderungen minimieren können.
Online-Schemaänderungstools
Wie bereits erwähnt, gibt es Tools, die Schemaänderungen durchführen sollen. Die beliebtesten sind pt-online-schema-change, erstellt von Percona, und gh-ost, erstellt von GitHub. In einer Reihe von Blogbeiträgen haben wir sie verglichen und diskutiert, wie gh-ost verwendet werden kann, um Schemaänderungen durchzuführen, und wie Sie eine laufende Migration drosseln und neu konfigurieren können. Wir gehen hier nicht ins Detail, möchten aber dennoch einige der wichtigsten Aspekte bei der Nutzung dieser Tools erwähnen. Zunächst einmal wird eine Schemaänderung, die über pt-osc oder gh-ost ausgeführt wird, auf allen Datenbankknoten gleichzeitig durchgeführt. Es gibt keinerlei Verzögerung hinsichtlich des Zeitpunkts der Änderung. Dadurch können diese Tools auch für Schemaänderungen verwendet werden, die mit der zeilenbasierten Replikation nicht kompatibel sind. Die genauen Mechanismen, wie diese Tools Änderungen in der Tabelle nachverfolgen, sind unterschiedlich (Trigger in pt-osc vs. binlog-Parsing in gh-ost), aber die Grundidee ist die gleiche – eine neue Tabelle wird mit dem gewünschten Schema und vorhandenen Daten erstellt aus der alten Tabelle kopiert. In der Zwischenzeit werden DMLs verfolgt (auf die eine oder andere Weise) und auf die neue Tabelle angewendet. Sobald alle Daten migriert sind, werden die Tabellen umbenannt und die neue Tabelle ersetzt die alte. Dies ist eine atomare Operation, sodass sie für die Anwendung nicht sichtbar ist. Beide Tools haben die Möglichkeit, die Last zu drosseln und den Betrieb anzuhalten. Ghost kann die gesamte Aktivität stoppen, pt-osc kann nur den Vorgang des Kopierens von Daten zwischen alter und neuer Tabelle stoppen - Trigger bleiben aktiv und duplizieren weiterhin Daten, was zusätzlichen Overhead verursacht. Aufgrund der Umbenennungstabelle haben beide Tools einige Einschränkungen in Bezug auf Fremdschlüssel - nicht unterstützt von gh-ost, teilweise unterstützt von pt-osc entweder durch reguläres ALTER, was zu Replikationsverzögerungen führen kann (nicht machbar, wenn die untergeordnete Tabelle groß ist) oder durch Löschen der alten Tabelle vor dem Umbenennen der neuen - es ist gefährlich, da es keine Möglichkeit gibt, ein Rollback durchzuführen, wenn Daten aus irgendeinem Grund nicht korrekt in die neue Tabelle kopiert wurden. Trigger sind auch schwierig zu unterstützen.
Sie werden in gh-ost nicht unterstützt, pt-osc in MySQL 5.7 und neuer hat eine eingeschränkte Unterstützung für Tabellen mit vorhandenen Triggern. Eine weitere wichtige Einschränkung für Online-Schemaänderungstools besteht darin, dass in der Tabelle eindeutige oder Primärschlüssel vorhanden sein müssen. Es wird verwendet, um Zeilen zu identifizieren, die zwischen alten und neuen Tabellen kopiert werden sollen. Diese Tools sind auch viel langsamer als direktes ALTER - eine Änderung, die Stunden dauert, während ALTER ausgeführt wird, kann Tage dauern, wenn sie mit pt-osc oder g-ost ausgeführt wird.
Andererseits können Sie, wie bereits erwähnt, alle Schemaänderungen mit einem der Tools ausführen, solange die Anforderungen erfüllt sind und keine Einschränkungen auftreten. Alles geschieht gleichzeitig auf allen Hosts, sodass Sie sich keine Gedanken über die Kompatibilität machen müssen. Sie haben auch ein gewisses Maß an Kontrolle darüber, wie der Prozess ausgeführt wird (weniger in pt-osc, viel mehr in gh-ost).
Sie können die Auswirkungen der Schemaänderung verringern, Sie können sie anhalten und nur unter Aufsicht ausführen lassen, Sie können die Änderung testen, bevor Sie sie tatsächlich durchführen. Sie können sie die Replikationsverzögerung verfolgen und pausieren lassen, falls eine Auswirkung erkannt wird. Dies macht diese Tools zu einer wirklich großartigen Ergänzung des DBA-Arsenals bei der Arbeit mit der MySQL-Replikation.
Laufende Schemaänderungen
In der Regel verwendet ein DBA eines der Online-Schemaänderungstools. Aber wie wir bereits besprochen haben, können sie unter bestimmten Umständen nicht verwendet werden, und eine direkte Alteration ist die einzig praktikable Option. Wenn wir über eigenständiges MySQL sprechen, haben Sie keine Wahl – wenn die Änderung nicht blockierend ist, ist das gut. Wenn nicht, dann kannst du nichts dagegen tun. Aber nicht viele Leute führen MySQL als einzelne Instanzen aus, oder? Wie wäre es mit Replikation? Wie wir bereits besprochen haben, ist eine direkte Änderung auf dem Master nicht möglich - in den meisten Fällen führt dies zu Verzögerungen auf dem Slave, was möglicherweise nicht akzeptabel ist. Was jedoch getan werden kann, ist, die Änderung in einer rollierenden Weise durchzuführen. Sie können mit Slaves beginnen und, sobald die Änderung auf alle angewendet wurde, einen der Slaves zum neuen Master befördern, den alten Master zu einem Slave degradieren und die Änderung an ihm durchführen. Sicher, die Änderung muss kompatibel sein, aber um die Wahrheit zu sagen, die häufigsten Fälle, in denen Sie Online-Schemaänderungen nicht verwenden können, sind das Fehlen eines Primärschlüssels oder eines eindeutigen Schlüssels. Für alle anderen Fälle gibt es eine Art Problemumgehung, insbesondere bei pt-online-schema-change, da gh-ost strengere Einschränkungen hat. Es ist eine Problemumgehung, die Sie als „so lala“ oder „alles andere als ideal“ bezeichnen würden, aber sie wird die Arbeit erledigen, wenn Sie keine andere Option zur Auswahl haben. Was auch wichtig ist, die meisten Einschränkungen können vermieden werden, wenn Sie Ihr Schema überwachen und die Probleme erkennen, bevor die Tabelle wächst. Selbst wenn jemand eine Tabelle ohne Primärschlüssel erstellt, ist es kein Problem, eine direkte Änderung auszuführen, die eine halbe Sekunde oder weniger dauert, da die Tabelle fast leer ist.
Wenn es wächst, wird dies zu einem ernsthaften Problem, aber es liegt am DBA, diese Art von Problemen zu erkennen, bevor sie tatsächlich Probleme verursachen. Wir werden einige Tipps und Tricks behandeln, wie Sie sicherstellen können, dass Sie solche Probleme rechtzeitig erkennen. Wir werden auch allgemeine Tipps zum Entwerfen Ihrer Schemas geben.
Tipps und Tricks
Schemadesign
Wie wir in diesem Beitrag gezeigt haben, sind Online-Schemaänderungstools sehr wichtig, wenn Sie mit einem Replikationssetup arbeiten. Daher ist es sehr wichtig sicherzustellen, dass Ihr Schema so konzipiert ist, dass es Ihre Optionen zum Durchführen von Schemaänderungen nicht einschränkt. Es gibt drei wichtige Aspekte. Zuerst muss ein Primärschlüssel oder eindeutiger Schlüssel vorhanden sein – Sie müssen sicherstellen, dass es keine Tabellen ohne Primärschlüssel in Ihrer Datenbank gibt. Sie sollten dies regelmäßig überwachen, da es sonst in Zukunft zu einem ernsthaften Problem werden kann. Zweitens sollten Sie ernsthaft überlegen, ob die Verwendung von Fremdschlüsseln eine gute Idee ist. Sicher, sie haben ihren Nutzen, aber sie erhöhen auch den Aufwand für Ihre Datenbank und können die Verwendung von Online-Schemaänderungstools problematisch machen. Beziehungen können durch die Anwendung erzwungen werden. Auch wenn dies mehr Arbeit bedeutet, ist es möglicherweise immer noch eine bessere Idee, als mit der Verwendung von Fremdschlüsseln zu beginnen und sich stark darauf zu beschränken, welche Arten von Schemaänderungen durchgeführt werden können. Drittens Trigger. Gleiche Geschichte wie bei Fremdschlüsseln. Sie sind ein nettes Feature, aber sie können zu einer Belastung werden. Sie müssen ernsthaft überlegen, ob die Vorteile aus der Verwendung die Einschränkungen überwiegen, die sie mit sich bringen.
Verfolgen von Schemaänderungen
Beim Schemaänderungsmanagement geht es nicht nur um die Ausführung von Schemaänderungen. Sie müssen auch Ihre Schemastruktur im Auge behalten, besonders wenn Sie nicht der einzige sind, der die Änderungen vornimmt.
ClusterControl stellt Benutzern Tools zur Verfügung, mit denen sie einige der häufigsten Schemaentwurfsprobleme verfolgen können. Es kann Ihnen helfen, Tabellen zu verfolgen, die keine Primärschlüssel haben:
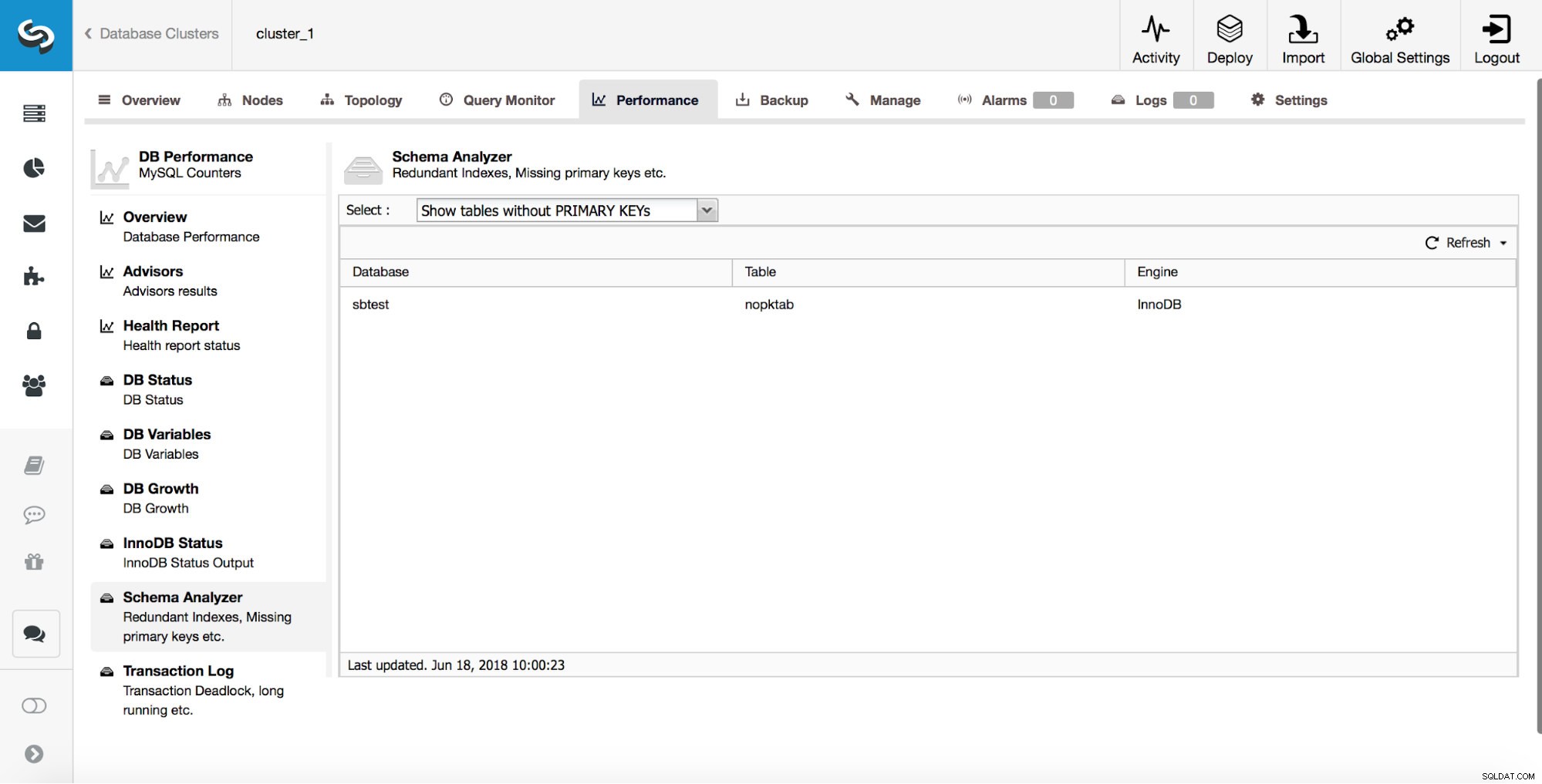
Wie wir bereits besprochen haben, ist es sehr wichtig, solche Tabellen frühzeitig abzufangen, da Primärschlüssel mit direkter Änderung hinzugefügt werden müssen.
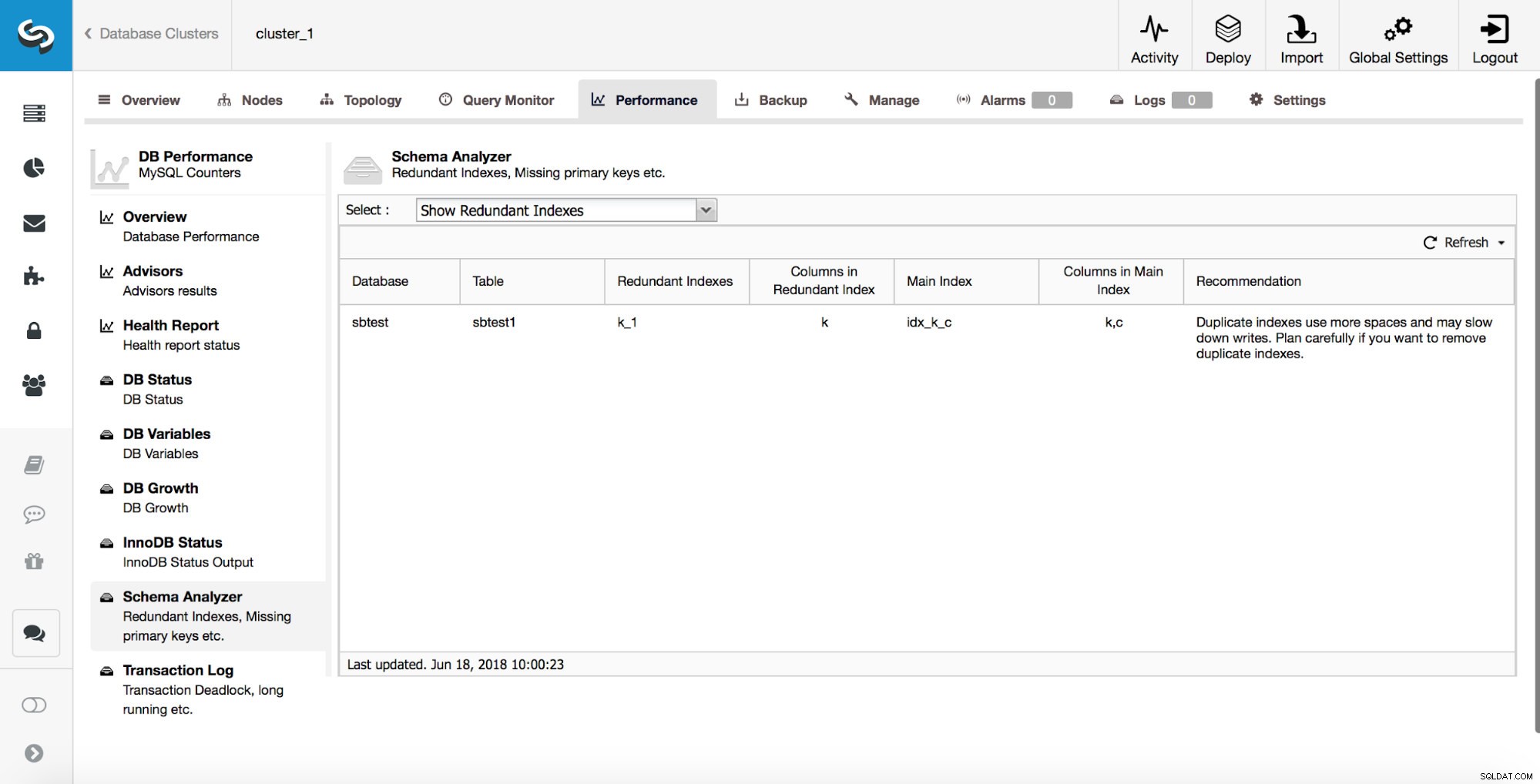
ClusterControl kann Ihnen auch dabei helfen, doppelte Indizes zu verfolgen. Normalerweise möchten Sie nicht mehrere Indizes haben, die redundant sind. Im obigen Beispiel sehen Sie, dass es einen Index für (k, c) und auch einen Index für (k) gibt. Jede Abfrage, die einen in Spalte „k“ erstellten Index verwenden kann, kann auch einen zusammengesetzten Index verwenden, der in den Spalten (k, c) erstellt wurde. Es gibt Fälle, in denen es vorteilhaft ist, redundante Indizes zu führen, aber Sie müssen dies von Fall zu Fall angehen. Ab MySQL 8.0 ist es möglich, schnell zu testen, ob ein Index wirklich benötigt wird oder nicht. Sie können einen redundanten Index „unsichtbar“ machen, indem Sie Folgendes ausführen:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;Dadurch ignoriert MySQL diesen Index und Sie können durch Überwachung überprüfen, ob es negative Auswirkungen auf die Leistung der Datenbank gab. Wenn für einige Zeit (ein paar Tage oder sogar Wochen) alles wie geplant funktioniert, können Sie planen, den redundanten Index zu entfernen. Falls Sie feststellen, dass etwas nicht stimmt, können Sie diesen Index jederzeit wieder aktivieren, indem Sie Folgendes ausführen:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Diese Operationen sind sofortig und der Index ist die ganze Zeit da und wird immer noch gepflegt – nur wird er vom Optimierer nicht berücksichtigt. Dank dieser Option ist das Entfernen von Indizes in MySQL 8.0 viel sicherer. In früheren Versionen konnte das erneute Hinzufügen eines fälschlicherweise entfernten Indexes bei großen Tabellen Stunden, wenn nicht sogar Tage dauern.
ClusterControl kann Sie auch über MyISAM-Tabellen informieren.
Während MyISAM immer noch seinen Nutzen haben kann, müssen Sie bedenken, dass es sich nicht um eine Transaktionsspeicher-Engine handelt. Als solches kann es leicht zu Dateninkonsistenzen zwischen Knoten in einer Replikationskonfiguration kommen.
Eine weitere sehr nützliche Funktion von ClusterControl ist einer der Betriebsberichte - ein Schema Change Report.
In einer idealen Welt überprüft, genehmigt und implementiert ein DBA alle Schemaänderungen. Leider ist dies nicht immer der Fall. Ein solcher Überprüfungsprozess passt einfach nicht gut zur agilen Entwicklung. Darüber hinaus ist das Entwickler-zu-DBA-Verhältnis in der Regel ziemlich hoch, was ebenfalls zu einem Problem werden kann, da DBAs Schwierigkeiten haben würden, kein Engpass zu werden. Aus diesem Grund ist es nicht ungewöhnlich, dass Schemaänderungen außerhalb des Wissens des DBA durchgeführt werden. Dennoch ist der DBA normalerweise derjenige, der für die Leistung und Stabilität der Datenbank verantwortlich ist. Dank des Schemaänderungsberichts können sie nun die Schemaänderungen nachverfolgen.
Zunächst ist etwas Konfiguration erforderlich. In einer Konfigurationsdatei für einen bestimmten Cluster (/etc/cmon.d/cmon_X.cnf) müssen Sie festlegen, auf welchem Host ClusterControl die Änderungen verfolgen und welche Schemas überprüft werden sollen.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestSobald dies erledigt ist, können Sie einen Bericht planen, der regelmäßig ausgeführt wird. Eine Beispielausgabe könnte wie folgt aussehen:
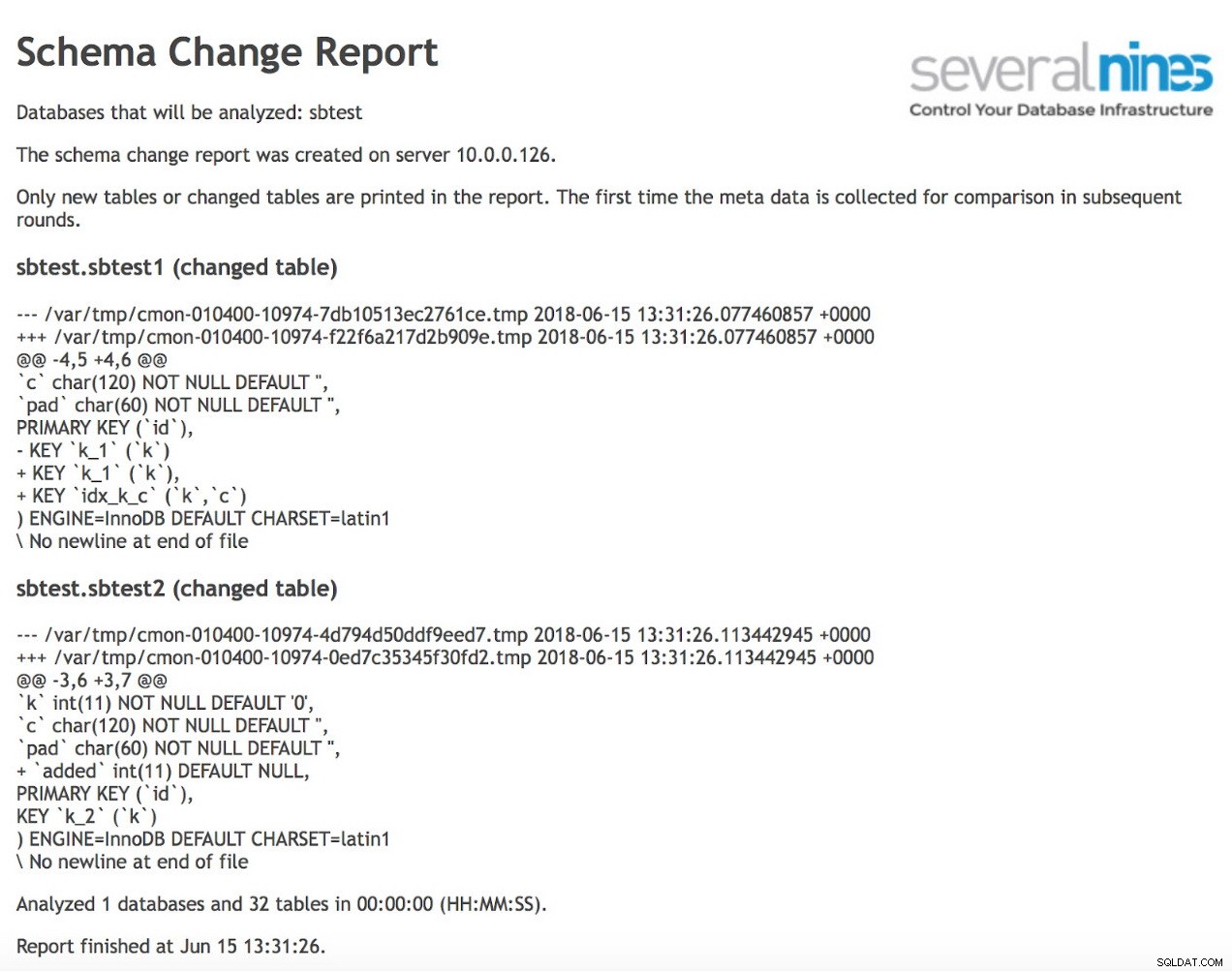
Wie Sie sehen können, haben sich seit der letzten Ausführung des Berichts zwei Tabellen geändert. Im ersten wurde ein neuer zusammengesetzter Index für die Spalten (k, c) erstellt. In der zweiten Tabelle wurde eine Spalte hinzugefügt.
Im anschließenden Durchlauf erhielten wir Informationen über eine neue Tabelle, die ohne Index oder Primärschlüssel erstellt wurde. Mit dieser Art von Informationen können wir bei Bedarf einfach handeln und die Probleme lösen, bevor sie tatsächlich zu Blockaden werden.