Vielleicht haben Sie schon einmal von dem Begriff „Split Brain“ gehört. Was es ist? Wie wirkt es sich auf Ihre Cluster aus? In diesem Blogbeitrag werden wir besprechen, was genau das ist, welche Gefahr es für Ihre Datenbank darstellen kann, wie wir es verhindern können und wie Sie es wiederherstellen können, wenn alles schief geht.
Längst vorbei sind die Zeiten von Einzelinstanzen, heutzutage laufen fast alle Datenbanken in Replikationsgruppen oder Clustern. Dies ist großartig für hohe Verfügbarkeit und Skalierbarkeit, aber eine verteilte Datenbank bringt neue Gefahren und Einschränkungen mit sich. Ein Fall, der tödlich sein kann, ist eine Netzwerkaufspaltung. Stellen Sie sich einen Cluster aus mehreren Knoten vor, der aufgrund von Netzwerkproblemen in zwei Teile geteilt wurde. Aus offensichtlichen Gründen (Datenkonsistenz) sollten beide Teile den Datenverkehr nicht gleichzeitig verarbeiten, da sie voneinander isoliert sind und Daten nicht zwischen ihnen übertragen werden können. Es ist auch aus Anwendungssicht falsch - selbst wenn es schließlich eine Möglichkeit gäbe, die Daten zu synchronisieren (obwohl der Abgleich von 2 Datensätzen nicht trivial ist). Für eine Weile würde ein Teil der Anwendung die Änderungen nicht bemerken, die von anderen Anwendungshosts vorgenommen werden, die auf den anderen Teil des Datenbankclusters zugreifen. Dies kann zu ernsthaften Problemen führen.
Der Zustand, in dem der Cluster in zwei oder mehr Teile geteilt wurde, die bereit sind, Schreibvorgänge zu akzeptieren, wird als „Split Brain“ bezeichnet.
Das größte Problem mit Split Brain ist die Datendrift, da Schreibvorgänge auf beiden Teilen des Clusters stattfinden. Keine der MySQL-Varianten bietet automatisierte Mittel zum Zusammenführen von Datensätzen, die voneinander abweichen. Sie werden eine solche Funktion nicht in der MySQL-Replikation, Gruppenreplikation oder Galera finden. Sobald die Daten divergieren, besteht die einzige Option darin, entweder einen der Teile des Clusters als Quelle der Wahrheit zu verwenden und Änderungen zu verwerfen, die auf dem anderen Teil vorgenommen wurden – es sei denn, wir können einen manuellen Prozess befolgen, um die Daten zusammenzuführen.
Aus diesem Grund werden wir damit beginnen, wie man Split Brain verhindern kann. Das ist so viel einfacher, als Datenabweichungen beheben zu müssen.
Wie man Split Brain vorbeugt
Die genaue Lösung hängt vom Typ der Datenbank und der Einrichtung der Umgebung ab. Wir werden uns einige der häufigsten Fälle für Galera-Cluster und MySQL-Replikation ansehen.
Galera-Cluster
Galera hat einen eingebauten „Circuit Breaker“, um mit Split Brain umzugehen:Es stützt sich auf einen Quorum-Mechanismus. Wenn eine Mehrheit (50 % + 1) der Knoten im Cluster verfügbar ist, wird Galera normal funktionieren. Wenn es keine Mehrheit gibt, stellt Galera die Bereitstellung des Verkehrs ein und wechselt in den sogenannten „Nicht-Primär“-Zustand. Das ist so ziemlich alles, was Sie brauchen, um mit einer Split-Brain-Situation umzugehen, während Sie Galera verwenden. Sicher, es gibt manuelle Methoden, um Galera in den „Primär“-Zustand zu zwingen, auch wenn es keine Mehrheit gibt. Die Sache ist die, wenn Sie das nicht tun, sollten Sie sicher sein.
Die Art und Weise, wie das Quorum berechnet wird, hat wichtige Auswirkungen – auf der Ebene eines einzelnen Rechenzentrums möchten Sie eine ungerade Anzahl von Knoten haben. Drei Knoten geben Ihnen eine Toleranz für den Ausfall eines Knotens (2 Knoten erfüllen die Anforderung, dass mehr als 50 % der Knoten im Cluster verfügbar sind). Fünf Knoten geben Ihnen eine Toleranz für den Ausfall von zwei Knoten (5 - 2 =3, was mehr als 50 % von 5 Knoten entspricht). Andererseits wird die Verwendung von vier Knoten Ihre Toleranz gegenüber Clustern mit drei Knoten nicht verbessern. Es würde immer noch nur einen Ausfall eines Knotens behandeln (4 - 1 =3, mehr als 50 % von 4), während der Ausfall von zwei Knoten den Cluster unbrauchbar macht (4 - 2 =2, nur 50 %, nicht mehr).
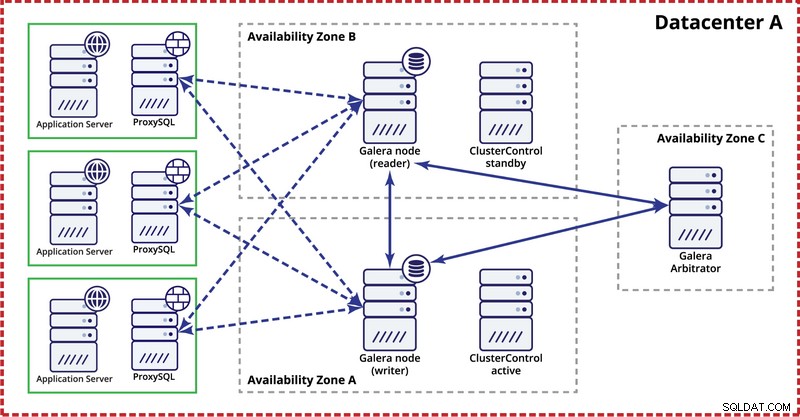
Denken Sie bei der Bereitstellung von Galera-Clustern in einem einzelnen Rechenzentrum daran, dass Sie Nodes idealerweise über mehrere Verfügbarkeitszonen (separate Stromquelle, Netzwerk usw.) verteilen möchten – sofern sie in Ihrem Rechenzentrum vorhanden sind . Eine einfache Einrichtung könnte wie folgt aussehen:
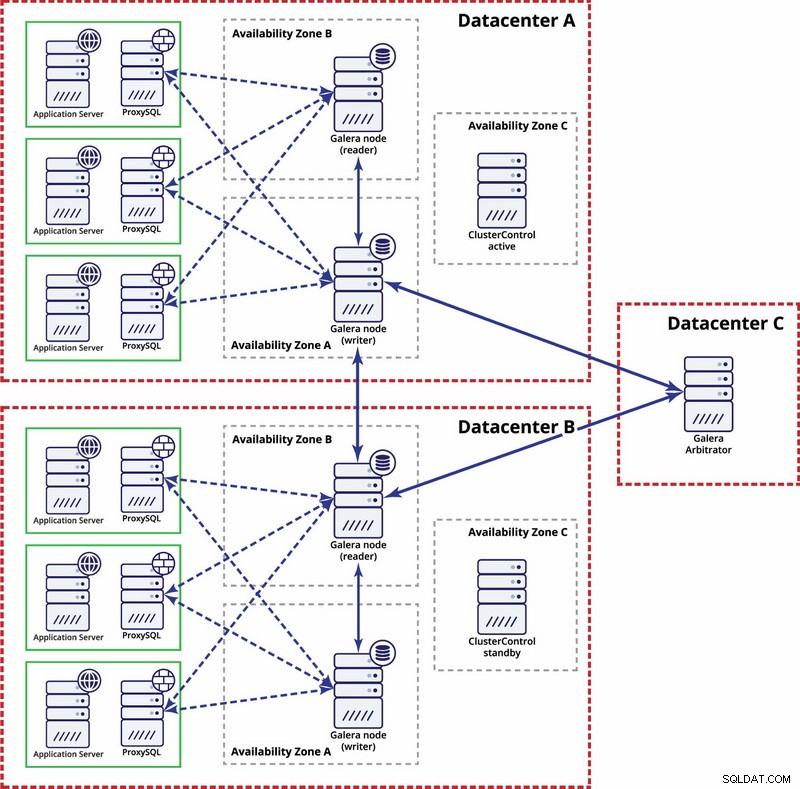
Auf der Ebene mehrerer Rechenzentren gelten diese Überlegungen ebenfalls. Wenn Sie möchten, dass der Galera-Cluster Rechenzentrumsausfälle automatisch handhabt, sollten Sie eine ungerade Anzahl von Rechenzentren verwenden. Um die Kosten zu senken, können Sie in einem von ihnen anstelle eines Datenbankknotens einen Galera-Schiedsrichter verwenden. Galera Arbitrator (garbd) ist ein Prozess, der an der Quorum-Berechnung teilnimmt, aber keine Daten enthält. Dies macht es möglich, es auch auf sehr kleinen Instanzen zu verwenden, da es nicht ressourcenintensiv ist – obwohl die Netzwerkkonnektivität gut sein muss, da es den gesamten Replikationsverkehr „sieht“. Beispiel-Setup kann wie in einem Diagramm unten aussehen:
MySQL-Replikation
Bei der MySQL-Replikation besteht das größte Problem darin, dass kein Quorum-Mechanismus eingebaut ist, wie es im Galera-Cluster der Fall ist. Daher sind weitere Schritte erforderlich, um sicherzustellen, dass Ihr Setup nicht von einem Split Brain beeinflusst wird.
Eine Methode besteht darin, automatisierte Failover zwischen Rechenzentren zu vermeiden. Sie können Ihre Failover-Lösung (über ClusterControl, MHA oder Orchestrator) so konfigurieren, dass nur ein Failover innerhalb eines einzelnen Rechenzentrums erfolgt. Wenn es zu einem vollständigen Rechenzentrumsausfall kam, wäre es Sache des Administrators, zu entscheiden, wie ein Failover durchgeführt wird und wie sichergestellt wird, dass die Server im ausgefallenen Rechenzentrum nicht verwendet werden.
Es gibt Optionen, um es stärker zu automatisieren. Sie können Consul verwenden, um Daten über die Knoten in der Replikationskonfiguration zu speichern und festzustellen, welcher von ihnen der Master ist. Dann liegt es am Administrator (oder über ein Skript), diesen Eintrag zu aktualisieren und Schreibvorgänge in das zweite Rechenzentrum zu verschieben. Sie können von einem Orchestrator/Raft-Setup profitieren, bei dem Orchestrator-Knoten über mehrere Rechenzentren verteilt und Split Brain erkannt werden können. Auf dieser Grundlage können Sie verschiedene Aktionen ausführen, wie z. B., wie bereits erwähnt, Einträge in unserem Consul oder etcd aktualisieren. Der Punkt ist, dass dies eine viel komplexere Umgebung zum Einrichten und Automatisieren ist als der Galera-Cluster. Unten finden Sie ein Beispiel für die Einrichtung mehrerer Rechenzentren für die MySQL-Replikation.
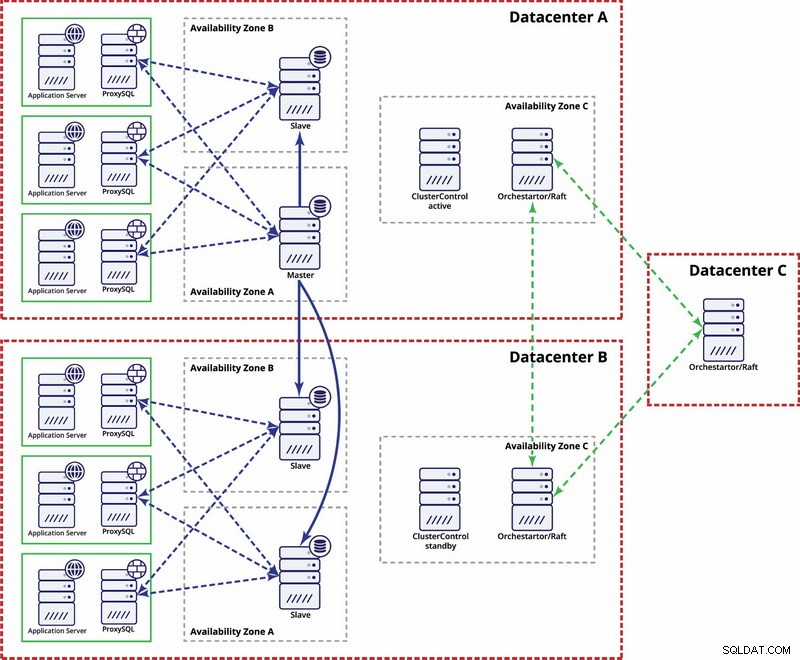
Bitte denken Sie daran, dass Sie noch Skripte erstellen müssen, damit es funktioniert, d. h. Orchestrator-Knoten auf ein Split Brain überwachen und die erforderlichen Maßnahmen ergreifen, um STONITH zu implementieren und sicherzustellen, dass der Master in Rechenzentrum A nicht verwendet wird, sobald das Netzwerk konvergiert und die Konnektivität wird wiederhergestellt werden.
Split Brain passiert – was als nächstes zu tun?
Das Worst-Case-Szenario ist eingetreten und wir haben eine Datendrift. Wir werden versuchen, Ihnen einige Hinweise zu geben, was hier getan werden kann. Leider hängen die genauen Schritte hauptsächlich von Ihrem Schemadesign ab, sodass es nicht möglich sein wird, eine genaue Anleitung zu schreiben.
Was Sie beachten müssen, ist, dass das ultimative Ziel darin besteht, Daten von einem Master auf den anderen zu kopieren und alle Beziehungen zwischen Tabellen neu zu erstellen.
Zunächst müssen Sie festlegen, welcher Knoten weiterhin als Master Daten bereitstellen wird. Dies ist ein Datensatz, mit dem Sie Daten zusammenführen, die auf der anderen „Master“-Instanz gespeichert sind. Sobald dies erledigt ist, müssen Sie Daten aus dem alten Master identifizieren, die auf dem aktuellen Master fehlen. Das wird Handarbeit sein. Wenn Sie Zeitstempel in Ihren Tabellen haben, können Sie diese nutzen, um die fehlenden Daten zu lokalisieren. Letztendlich enthalten Binärprotokolle alle Datenänderungen, sodass Sie sich darauf verlassen können. Möglicherweise müssen Sie sich auch auf Ihr Wissen über die Datenstruktur und die Beziehungen zwischen Tabellen verlassen. Wenn Ihre Daten normalisiert sind, könnte ein Datensatz in einer Tabelle mit Datensätzen in anderen Tabellen verknüpft sein. Beispielsweise kann Ihre Anwendung Daten in die „Benutzer“-Tabelle einfügen, die mit der „Adresse“-Tabelle unter Verwendung von user_id verknüpft ist. Sie müssen alle zugehörigen Zeilen finden und extrahieren.
Der nächste Schritt besteht darin, diese Daten in den neuen Master zu laden. Hier kommt der knifflige Teil – wenn Sie Ihre Setups vorher vorbereitet haben, könnte dies einfach eine Frage der Ausführung einiger Inserts sein. Wenn nicht, kann dies ziemlich komplex sein. Es dreht sich alles um Primärschlüssel und eindeutige Indexwerte. Wenn Ihre Primärschlüsselwerte auf jedem Server mit einer Art UUID-Generator oder mit den Einstellungen auto_increment_increment und auto_increment_offset in MySQL als eindeutig generiert werden, können Sie sicher sein, dass die Daten aus dem alten Master, die Sie einfügen müssen, keinen Primärschlüssel oder Unique verursachen Schlüssel kollidiert mit Daten auf dem neuen Master. Andernfalls müssen Sie möglicherweise Daten aus dem alten Master manuell ändern, um sicherzustellen, dass sie korrekt eingefügt werden können. Es klingt komplex, also schauen wir uns ein Beispiel an.
Stellen wir uns vor, wir fügen Zeilen mit auto_increment auf Knoten A ein, der ein Master ist. Der Einfachheit halber konzentrieren wir uns nur auf eine einzelne Zeile. Es gibt die Spalten „id“ und „value“.
Wenn wir es ohne besondere Einrichtung einfügen, sehen wir Einträge wie unten:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Diese werden auf den Slave (B) repliziert. Wenn das Split Brain auftritt und Schreibvorgänge sowohl auf dem alten als auch auf dem neuen Master ausgeführt werden, werden wir mit der folgenden Situation enden:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Wie Sie sehen können, gibt es keine Möglichkeit, Datensätze mit den IDs 1004, 1005 und 1006 einfach von Knoten A auszugeben und auf Knoten B zu speichern, da wir am Ende doppelte Primärschlüsseleinträge erhalten. Was getan werden muss, ist, die Werte der id-Spalte in den Zeilen, die eingefügt werden, auf einen Wert zu ändern, der größer ist als der maximale Wert der id-Spalte aus der Tabelle. Das ist alles, was für einzelne Reihen benötigt wird. Bei komplexeren Beziehungen, bei denen mehrere Tabellen beteiligt sind, müssen Sie die Änderungen möglicherweise an mehreren Stellen vornehmen.
Wenn wir andererseits dieses potenzielle Problem vorhergesehen und unsere Knoten so konfiguriert hätten, dass sie ungerade IDs auf Knoten A und gerade IDs auf Knoten B speichern, wäre das Problem so viel einfacher zu lösen gewesen.
Knoten A wurde mit auto_increment_offset =1 und auto_increment_increment =2
konfiguriertKnoten B wurde mit auto_increment_offset =2 und auto_increment_increment =2
konfiguriertSo würden die Daten auf Knoten A vor dem Split Brain aussehen:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Wenn Split Brain passiert ist, sieht es wie folgt aus.
Knoten A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Knoten B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Jetzt können wir fehlende Daten einfach von Knoten A kopieren:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Und laden Sie es in Knoten B und erhalten Sie folgenden Datensatz:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Sicher, Zeilen sind nicht in der ursprünglichen Reihenfolge, aber das sollte in Ordnung sein. Im schlimmsten Fall müssen Sie in Abfragen nach der Spalte „Wert“ sortieren und möglicherweise einen Index hinzufügen, um die Sortierung zu beschleunigen.
Stellen Sie sich nun Hunderte oder Tausende von Zeilen und eine stark normalisierte Tabellenstruktur vor - um eine Zeile wiederherzustellen, müssen Sie möglicherweise mehrere davon in zusätzlichen Tabellen wiederherstellen. Da die IDs in allen zugehörigen Zeilen geändert werden müssen (weil Sie keine Schutzeinstellungen vorgenommen haben) und dies alles manuelle Arbeit ist, können Sie sich vorstellen, dass dies nicht die beste Situation ist. Es braucht Zeit, um sich zu erholen und es ist ein fehleranfälliger Prozess. Glücklicherweise gibt es, wie wir eingangs besprochen haben, Mittel, um die Wahrscheinlichkeit zu minimieren, dass Split Brain Ihr System beeinträchtigt, oder um die Arbeit zu reduzieren, die getan werden muss, um Ihre Knoten zurückzusynchronisieren. Stellen Sie sicher, dass Sie sie verwenden, und bleiben Sie vorbereitet.