Wenn Ihre IT-Infrastruktur auf AWS läuft, haben Sie wahrscheinlich schon von Amazon Relational Database Service (RDS) gehört, einer einfachen Möglichkeit, eine relationale Datenbank in der Cloud einzurichten, zu betreiben und zu skalieren. Es bietet kostengünstige und anpassbare Kapazität und automatisiert gleichzeitig zeitaufwändige Verwaltungsaufgaben wie Hardwarebereitstellung, Datenbankeinrichtung, Patching und Backups. Es gibt eine Reihe von Datenbank-Engine-Angeboten für RDS wie MySQL, MariaDB, PostgreSQL, Microsoft SQL Server und Oracle Server.
ClusterControl 1.7.3 verhält sich ähnlich wie RDS, da es die Bereitstellung, Verwaltung, Überwachung und Skalierung von Datenbankclustern auf der AWS-Plattform unterstützt. Es unterstützt auch eine Reihe anderer Cloud-Plattformen wie Google Cloud Platform und Microsoft Azure. ClusterControl versteht die Datenbanktopologie und ist in der Lage, automatische Wiederherstellung, Topologieverwaltung und viele weitere erweiterte Funktionen durchzuführen, um die Kontrolle über Ihre Datenbank zu übernehmen.
In diesem Blog-Beitrag vergleichen wir die automatischen Failover-Zeiten für Amazon Aurora, Amazon RDS für MySQL und ein von ClusterControl bereitgestelltes und verwaltetes MySQL-Replikations-Setup. Die Art von Failover, die wir durchführen werden, ist Slave-Promotion für den Fall, dass der Master ausfällt. Hier übernimmt der aktuellste Slave die Master-Rolle im Cluster, um den Datenbankdienst wieder aufzunehmen.
Unser Failover-Test
Um die Failover-Zeit zu messen, führen wir einen einfachen MySQL-Connect-Update-Test mit einer Schleife durch, um den Status der SQL-Anweisungen zu zählen, die eine Verbindung zu einem einzelnen Datenbankendpunkt herstellen. Das Skript sieht folgendermaßen aus:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Das obige Bash-Skript stellt einfach eine Verbindung zu einem MySQL-Host her und führt eine Aktualisierung einer einzelnen Zeile mit einem Timeout von 1 Sekunde sowohl bei Bash- als auch bei mysql-Client-Befehlen durch. Die Timeout-bezogenen Parameter sind erforderlich, damit wir die Ausfallzeit in Sekunden korrekt messen können, da der MySQL-Client standardmäßig immer wieder eine Verbindung herstellt, bis er das MySQL-wait_timeout erreicht. Wir haben vorher einen Testdatensatz mit folgendem Befehl gefüllt:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareDas Skript meldet, ob die obige Abfrage erfolgreich war (OK) oder fehlgeschlagen ist (Fail). Beispielausgaben werden weiter unten gezeigt.
Failover mit Amazon RDS für MySQL
In unserem Test verwenden wir das niedrigste RDS-Angebot mit den folgenden Spezifikationen:
- MySQL-Version:5.7.22
- vCPU:4
- Arbeitsspeicher:16 GB
- Speichertyp:Bereitgestellte IOPS (SSD)
- IOPS:1000
- Speicher:100 GB
- Multi-AZ-Replikation:Ja
Nachdem Amazon RDS Ihre DB-Instance bereitgestellt hat, können Sie jede standardmäßige MySQL-Client-Anwendung oder jedes Dienstprogramm verwenden, um eine Verbindung zur Instance herzustellen. In der Verbindungszeichenfolge geben Sie die DNS-Adresse des DB-Instance-Endpunkts als Hostparameter und die Portnummer des DB-Instance-Endpunkts als Portparameter an.
Laut Amazon RDS-Dokumentationsseite wechselt Amazon RDS im Falle eines geplanten oder ungeplanten Ausfalls Ihrer DB-Instance automatisch zu einer Standby-Replik in einer anderen Availability Zone, wenn Sie Multi-AZ aktiviert haben. Die Zeit, die für den Abschluss des Failovers benötigt wird, hängt von der Datenbankaktivität und anderen Bedingungen ab, als die primäre DB-Instance nicht mehr verfügbar war. Failover-Zeiten betragen in der Regel 60–120 Sekunden.
Um ein Multi-AZ-Failover in RDS zu initiieren, haben wir einen Neustart durchgeführt, bei dem „Reboot with Failover“ aktiviert war, wie im folgenden Screenshot gezeigt:
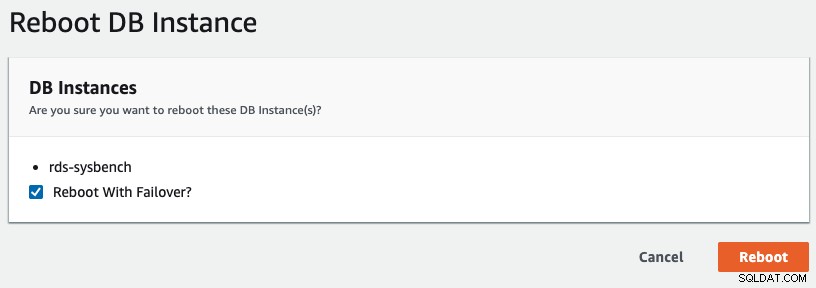
Folgendes wird von unserer Anwendung beobachtet:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Die MySQL-Ausfallzeit aus Sicht der Anwendungsseite wurde von 03:41:09 bis 03:41:36 gestartet, was insgesamt etwa 27 Sekunden entspricht. Anhand der RDS-Ereignisse können wir sehen, dass das Multi-AZ-Failover nur 15 Sekunden nach der tatsächlichen Ausfallzeit stattfand:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Nach dem Neustart der neuen Datenbankinstanz gegen 03:41:33 Uhr war der MySQL-Dienst dann etwa 3 Sekunden später verfügbar.
Failover mit Amazon Aurora für MySQL
Amazon Aurora kann als überlegene Version von RDS angesehen werden, mit vielen bemerkenswerten Funktionen wie schnellerer Replikation mit gemeinsam genutztem Speicher, keinem Datenverlust während eines Failover und bis zu 64 TB Speicherlimit. Amazon Aurora für MySQL basiert auf der Open-Source-MySQL-Edition, ist jedoch selbst keine Open-Source-Lösung. es ist eine proprietäre Closed-Source-Datenbank. Es funktioniert ähnlich mit der MySQL-Replikation (ein und nur ein Master mit mehreren Slaves) und Failover wird automatisch von Amazon Aurora gehandhabt.
Wenn Sie eine Amazon Aurora-Replik in derselben oder einer anderen Availability Zone haben, dreht Aurora laut Amazon Aurora FAQs beim Failover den kanonischen Namensdatensatz (CNAME) für Ihre DB-Instance um, um auf die fehlerfreie Replik zu verweisen, die sich darin befindet wird wiederum zum neuen Primary befördert. Das Failover ist von Anfang bis Ende in der Regel innerhalb von 30 Sekunden abgeschlossen.
Wenn Sie keine Amazon Aurora Replica (d. h. eine einzelne Instance) haben, versucht Aurora zunächst, eine neue DB-Instance in derselben Availability Zone wie die ursprüngliche Instance zu erstellen. Wenn dies nicht möglich ist, versucht Aurora, eine neue DB-Instance in einer anderen Availability Zone zu erstellen. Von Anfang bis Ende ist ein Failover in der Regel in weniger als 15 Minuten abgeschlossen.
Ihre Anwendung sollte Datenbankverbindungen im Falle eines Verbindungsverlusts erneut versuchen.
Nachdem Amazon Aurora Ihre DB-Instance bereitgestellt hat, erhalten Sie zwei Endpunkte, einen für den Writer und einen für den Reader. Der Reader-Endpunkt bietet Lastenausgleichsunterstützung für schreibgeschützte Verbindungen zum DB-Cluster. Die folgenden Endpunkte stammen aus unserem Testaufbau:
- Autor - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- Reader - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
In unserem Test haben wir die folgenden Aurora-Spezifikationen verwendet:
- Instanztyp:db.r5.large
- MySQL-Version:5.7.12
- vCPU:2
- Arbeitsspeicher:16 GB
- Multi-AZ-Replikation:Ja
Um ein Failover auszulösen, wählen Sie einfach die Writer-Instanz -> Aktionen -> Failover, wie im folgenden Screenshot gezeigt:
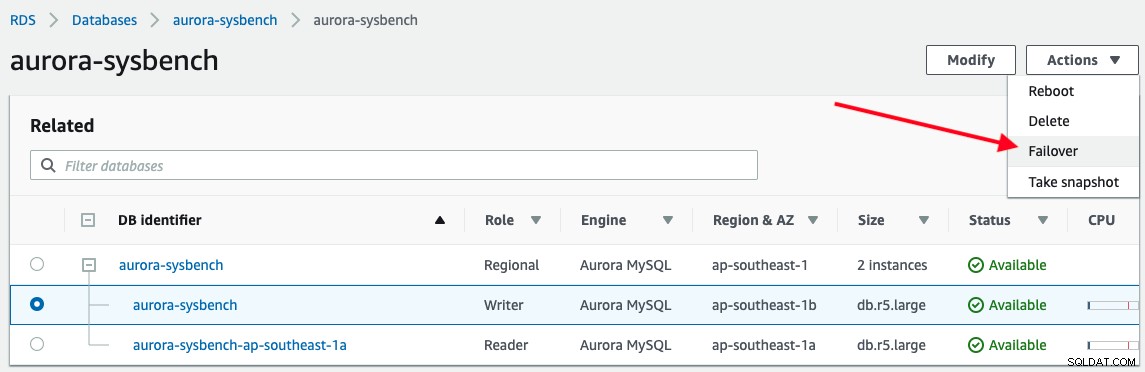
Die folgende Ausgabe wird von unserer Anwendung beim Herstellen einer Verbindung mit dem Aurora-Writer-Endpunkt gemeldet :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Die Datenbank-Downtime wurde von 12:35:49 bis 12:35:56 mit einer Gesamtdauer von 7 Sekunden gestartet. Das ist ziemlich beeindruckend.
Betrachtet man das Datenbankereignis der Aurora-Verwaltungskonsole, sind nur diese beiden Ereignisse eingetreten:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedEs dauert nicht lange, bis Aurora einen Sklaven zum Meister befördert und den Meister zum Sklaven degradiert. Beachten Sie, dass alle Aurora-Replikate dasselbe zugrunde liegende Volume mit der primären Instanz teilen und dies bedeutet, dass die Replikation in Millisekunden durchgeführt werden kann, da von der primären Instanz vorgenommene Aktualisierungen sofort für alle Aurora-Replikate verfügbar sind. Daher hat es eine minimale Replikationsverzögerung (Amazon behauptete, 100 Millisekunden und weniger zu sein). Dadurch wird die Zeit für die Zustandsprüfung erheblich verkürzt und die Wiederherstellungszeit erheblich verbessert.
Failover mit ClusterControl
In diesem Beispiel imitieren wir ein ähnliches Setup mit Amazon RDS unter Verwendung von m5.xlarge-Instances, mit einem ProxySQL dazwischen, um das Failover von der Anwendung zu automatisieren, indem ein einzelner Endpunktzugriff wie bei RDS verwendet wird. Das folgende Diagramm veranschaulicht unsere Architektur:
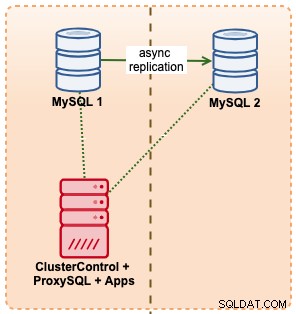
Da wir direkten Zugriff auf die Datenbankinstanzen haben, würden wir ein automatisches Failover auslösen, indem wir einfach den MySQL-Prozess auf dem aktiven Master beenden:
$ kill -9 $(pidof mysqld)Der obige Befehl löste eine automatische Wiederherstellung innerhalb von ClusterControl aus:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Aus Sicht unserer Testanwendung trat die Ausfallzeit während der Verbindung zum ProxySQL-Hostport 6033 zu folgendem Zeitpunkt auf:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Wenn man sich sowohl die Ereignisse des Wiederherstellungsjobs als auch die Ausgabe unserer Anwendung ansieht, war der MySQL-Datenbankknoten 4 Sekunden vor Beginn des Cluster-Wiederherstellungsjobs von 11:08:28 bis 11:08:39 inaktiv, mit einer gesamten MySQL-Ausfallzeit von 11 Sekunden . Eines der beeindruckendsten Dinge an ClusterControl ist, dass Sie den Wiederherstellungsfortschritt verfolgen können, welche Aktionen von ClusterControl während des Failovers ergriffen und durchgeführt werden. Es bietet ein Maß an Transparenz, das Sie mit keinem Datenbankangebot von Cloud-Anbietern erreichen können.
Für die MySQL/MariaDB/PostgreSQL-Replikation ermöglicht Ihnen ClusterControl eine feinkörnigere Gegenüberstellung Ihrer Datenbanken mit Unterstützung der folgenden erweiterten Konfiguration und Parameter:
- Verwaltung der Master-Master-Replikationstopologie
- Management der Kettenreplikationstopologie
- Topologie-Viewer
- Whitelist/Blacklist-Slaves, die als Master befördert werden sollen
- Fehlerhafter Transaktionsprüfer
- Pre/Post, Erfolgs-/Fehler-Failover/Switchover-Ereignisse Hook mit externem Skript
- Automatischer Wiederaufbau des Slaves bei Fehler
- Skalieren Sie den Slave aus dem vorhandenen Backup heraus
Zusammenfassung der Ausfallzeit
In Bezug auf die Failover-Zeit ist Amazon RDS Aurora für MySQL mit 7 Sekunden der klare Gewinner , gefolgt von ClusterControl 11 Sekunden und Amazon RDS für MySQL mit 27 Sekunden .
Beachten Sie, dass dies nur ein einfacher Test mit einem Client und einer Transaktion pro Sekunde ist, um die schnellste Wiederherstellungszeit zu messen. Große Transaktionen oder ein langwieriger Wiederherstellungsprozess können die Failover-Zeit verlängern, z. B. kann das Zurücksetzen lang laufender Transaktionen beim Herunterfahren von MySQL lange dauern.



