Primär- und Fremdschlüssel sind grundlegende Merkmale relationaler Datenbanken, wie ursprünglich in E. F. Codds 1970 veröffentlichtem Artikel „A Relational Model of Data for Large Shared Data Banks“ erwähnt. und nichts als den Schlüssel, also hilf mir, Codd."
Hintergrund:Primärschlüssel
Ein Primärschlüssel ist eine Einschränkung in SQL Server, die dazu dient, jede Zeile in einer Tabelle eindeutig zu identifizieren. Der Schlüssel kann als einzelne Nicht-NULL-Spalte oder als Kombination von Nicht-NULL-Spalten definiert werden, die einen eindeutigen Wert generiert, und wird verwendet, um die Entitätsintegrität für eine Tabelle zu erzwingen. Eine Tabelle kann nur einen Primärschlüssel haben, und wenn eine Primärschlüsseleinschränkung für eine Tabelle definiert wird, wird ein eindeutiger Index erstellt. Dieser Index ist standardmäßig ein geclusterter Index, sofern er nicht als nicht geclusterter Index angegeben wird, wenn die Primärschlüsseleinschränkung definiert wird.
Betrachten Sie den Sales.SalesOrderHeader Tabelle in AdventureWorks2012 Datenbank. Diese Tabelle enthält grundlegende Informationen zu einem Verkaufsauftrag, einschließlich Bestelldatum und Kunden-ID, und jeder Verkauf wird durch eine SalesOrderID eindeutig identifiziert , das ist der Primärschlüssel für die Tabelle. Jedes Mal, wenn der Tabelle eine neue Zeile hinzugefügt wird, wird die Primärschlüsseleinschränkung (mit dem Namen PK_SalesOrderHeader_SalesOrderID ) wird überprüft, um sicherzustellen, dass keine Zeile mit demselben Wert für SalesOrderID bereits vorhanden ist .
Fremdschlüssel
Von Primärschlüsseln getrennt, aber sehr verwandt, sind Fremdschlüssel. Ein Fremdschlüssel ist eine Spalte oder Kombination von Spalten, die mit dem Primärschlüssel identisch ist, sich jedoch in einer anderen Tabelle befindet. Fremdschlüssel werden verwendet, um eine Beziehung zu definieren und die Integrität zwischen zwei Tabellen zu erzwingen.
Um das oben genannte Beispiel weiter zu verwenden, die SalesOrderID Spalte existiert als Fremdschlüssel in Sales.SalesOrderDetail Tabelle, in der zusätzliche Informationen zum Verkauf gespeichert sind, z. B. Produkt-ID und Preis. Wenn ein neuer Verkauf zum SalesOrderHeader hinzugefügt wird Tabelle ist es nicht erforderlich, eine Zeile für diesen Verkauf zu SalesOrderDetail hinzuzufügen table Allerdings beim Hinzufügen einer Zeile zu SalesOrderDetail Tabelle, eine entsprechende Zeile für die SalesOrderID muss existieren im SalesOrderHeader Tabelle.
Umgekehrt beim Löschen von Daten eine Zeile für eine bestimmte SalesOrderID kann jederzeit aus dem SalesOrderDetail gelöscht werden Tabelle, sondern damit eine Zeile aus dem SalesOrderHeader gelöscht wird Tabelle, zugehörige Zeilen aus SalesOrderDetail müssen zuerst gelöscht werden.
Im Gegensatz zu Primärschlüsseleinschränkungen wird bei der Definition einer Fremdschlüsseleinschränkung für eine Tabelle standardmäßig kein Index von SQL Server erstellt. Es ist jedoch nicht ungewöhnlich, dass Entwickler und Datenbankadministratoren sie manuell hinzufügen. Der Fremdschlüssel kann Teil eines zusammengesetzten Primärschlüssels für die Tabelle sein, in diesem Fall würde ein gruppierter Index mit dem Fremdschlüssel als Teil des Gruppierungsschlüssels existieren. Alternativ können Abfragen einen Index erfordern, der den Fremdschlüssel und eine oder mehrere zusätzliche Spalten in der Tabelle enthält, sodass ein nicht gruppierter Index erstellt wird, um diese Abfragen zu unterstützen. Darüber hinaus können Indizes für Fremdschlüssel Leistungsvorteile für Tabellenverknüpfungen mit Primär- und Fremdschlüssel bieten und die Leistung beeinträchtigen, wenn der Primärschlüsselwert aktualisiert oder die Zeile gelöscht wird.
Im AdventureWorks2012 Datenbank gibt es eine Tabelle, SalesOrderDetail , mit SalesOrderID als Fremdschlüssel. Für SalesOrderDetail Tabelle, SalesOrderID und SalesOrderDetailID kombinieren, um den Primärschlüssel zu bilden, der von einem gruppierten Index unterstützt wird. Wenn das SalesOrderDetail Tabelle hatte keinen Index auf SalesOrderID Spalte, dann wenn eine Zeile aus SalesOrderHeader gelöscht wird , müsste SQL Server überprüfen, ob keine Zeilen für dieselbe SalesOrderID vorhanden sind Wert bestehen. Ohne Indizes, die die SalesOrderID enthalten -Spalte, müsste SQL Server einen vollständigen Tabellenscan von SalesOrderDetail durchführen . Wie Sie sich vorstellen können, dauert das Löschen umso länger, je größer die referenzierte Tabelle ist.
Ein Beispiel
Wir können dies im folgenden Beispiel sehen, das Kopien der oben genannten Tabellen aus AdventureWorks2012 verwendet Datenbank, die mit einem Skript erweitert wurden, das hier zu finden ist. Das Skript wurde von Jonathan Kehayias (Blog | @SQLPoolBoy) entwickelt und erstellt einen SalesOrderHeaderEnlarged Tabelle mit 1.258.600 Zeilen und einem SalesOrderDetailEnlarged Tabelle mit 4.852.680 Zeilen. Nachdem das Skript ausgeführt wurde, wurde die Fremdschlüsseleinschränkung mithilfe der folgenden Anweisungen hinzugefügt. Beachten Sie, dass die Einschränkung mit ON DELETE CASCADE erstellt wird Möglichkeit. Mit dieser Option, wenn eine Aktualisierung oder Löschung für den SalesOrderHeaderEnlarged ausgegeben wird Tabelle, Zeilen in der/den entsprechenden Tabelle(n) – in diesem Fall nur SalesOrderDetailEnlarged – aktualisiert oder gelöscht werden.
Außerdem der standardmäßige, gruppierte Index für SalesOrderDetailEnglarged wurde gelöscht und neu erstellt, um nur noch SalesOrderDetailID zu haben als Primärschlüssel, da er ein typisches Design darstellt.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Mit der Fremdschlüsseleinschränkung und keinem unterstützenden Index wurde eine einzelne Löschung für SalesOrderHeaderEnlarged ausgegeben Tabelle, was dazu führte, dass eine Zeile aus SalesOrderHeaderEnlarged entfernt wurde und 72 Zeilen aus SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Die Statistik-E/A- und Timing-Informationen zeigten Folgendes:
Analyse- und Kompilierzeit von SQL Server:CPU-Zeit =8 ms, verstrichene Zeit =8 ms.
Tabelle 'SalesOrderDetailEnlarged'. Scan-Zähler 1, logische Lesevorgänge 50647, physische Lesevorgänge 8, Read-Ahead-Lesevorgänge 50667, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Arbeitstabelle'. Scan-Anzahl 2, logische Lesevorgänge 7, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'SalesOrderHeaderEnlarged'. Scan-Anzahl 0, logische Lesevorgänge 15, physische Lesevorgänge 14, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
SQL Server-Ausführungszeiten:
CPU-Zeit =1045 ms, verstrichene Zeit =1898 ms.
Unter Verwendung von SQL Sentry Plan Explorer zeigt der Ausführungsplan einen Clustered-Index-Scan gegen SalesOrderDetailEnlarged da es keinen Index auf SalesOrderID gibt :
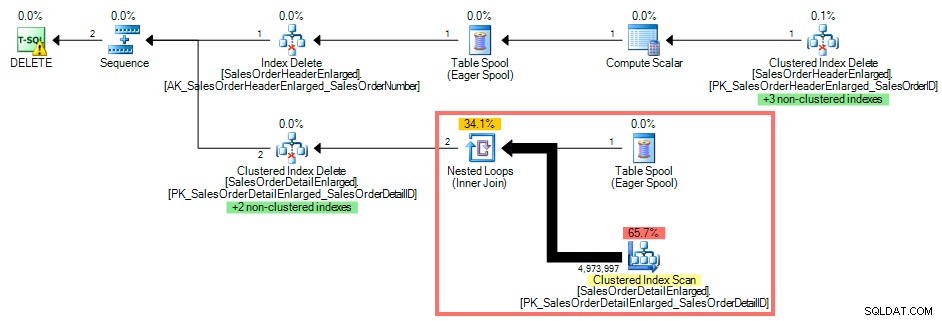
Abfrageplan ohne Index auf dem Fremdschlüssel
Der nicht gruppierte Index zur Unterstützung von SalesOrderDetailEnlarged wurde dann mit der folgenden Anweisung erstellt:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Für eine SalesOrderID wurde ein weiterer Löschvorgang ausgeführt die eine Zeile in SalesOrderHeaderEnlarged betraf und 72 Zeilen in SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Die statistischen E/A- und Timing-Informationen zeigten eine dramatische Verbesserung:
Analyse- und Kompilierzeit von SQL Server:CPU-Zeit =0 ms, verstrichene Zeit =7 ms.
Tabelle 'SalesOrderDetailEnlarged'. Scan-Zähler 1, logische Lesevorgänge 48, physische Lesevorgänge 13, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Worktable'. Scan-Anzahl 2, logische Lesevorgänge 7, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'SalesOrderHeaderEnlarged'. Scan-Anzahl 0, logische Lesevorgänge 15, physische Lesevorgänge 15, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
SQL Server-Ausführungszeiten:
CPU-Zeit =0 ms, verstrichene Zeit =27 ms.
Und der Abfrageplan zeigte eine Indexsuche des Nonclustered-Index auf SalesOrderID , wie erwartet:
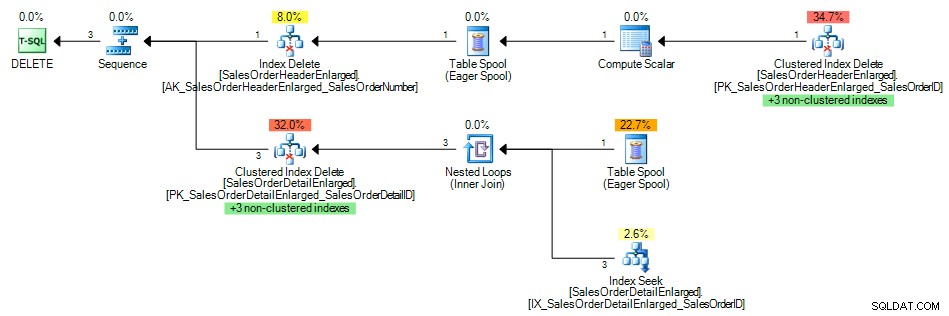
Abfrageplan mit Index auf dem Fremdschlüssel
Die Ausführungszeit der Abfrage sank von 1898 ms auf 27 ms – eine Reduzierung um 98,58 %, und gilt für SalesOrderDetailEnlarged Tabelle von 50647 auf 48 gesunken – eine Verbesserung von 99,9 %. Abgesehen von den Prozentzahlen, betrachten Sie allein die E/A, die durch das Löschen generiert werden. Das SalesOrderDetailEnlarged Tabelle ist in diesem Beispiel nur 500 MB groß, und für ein System mit 256 GB verfügbarem Speicher scheint eine Tabelle, die 500 MB im Puffercache belegt, keine schreckliche Situation zu sein. Aber eine Tabelle mit 5 Millionen Zeilen ist relativ klein; Die meisten großen OLTP-Systeme haben Tabellen mit Hunderten von Millionen Zeilen. Darüber hinaus ist es nicht ungewöhnlich, dass mehrere Fremdschlüsselreferenzen für einen Primärschlüssel vorhanden sind, wobei ein Löschen des Primärschlüssels das Löschen aus mehreren verknüpften Tabellen erfordert. In diesem Fall ist es möglich, längere Dauern für Löschungen zu sehen, was nicht nur ein Leistungsproblem, sondern je nach Isolationsstufe auch ein Blockierungsproblem darstellt.
Schlussfolgerung
Es wird allgemein empfohlen, einen Index zu erstellen, der zu den Fremdschlüsselspalten führt, um nicht nur Verknüpfungen zwischen Primär- und Fremdschlüsseln, sondern auch Aktualisierungen und Löschungen zu unterstützen. Beachten Sie, dass dies eine allgemeine Empfehlung ist, da es Grenzfälle gibt, in denen der zusätzliche Index für den Fremdschlüssel aufgrund einer extrem kleinen Tabellengröße nicht verwendet wurde und die zusätzlichen Indexaktualisierungen die Leistung tatsächlich negativ beeinflussten. Wie alle Schemaänderungen sollten Indexergänzungen nach der Implementierung getestet und überwacht werden. Es ist wichtig sicherzustellen, dass die zusätzlichen Indizes die gewünschten Effekte erzielen und sich nicht negativ auf die Leistung der Lösung auswirken. Beachtenswert ist auch, wie viel zusätzlichen Platz die Indizes für die Fremdschlüssel benötigen. Dies ist vor dem Erstellen der Indizes unbedingt zu berücksichtigen, und wenn sie einen Vorteil bieten, muss dies für die zukünftige Kapazitätsplanung berücksichtigt werden.